层次聚类算法的原理及python实现
一、算法简介
主流的聚类算法可以大致分成层次化聚类算法、划分式聚类算法(图论、KMean)、基于密度(DBSCAN)和网格的聚类算法和其他聚类算法。
1.1 基本概念
-
层次聚类(Hierarchical Clustering)是一种聚类算法,通过计算不同类别数据点间的相似度来创建一棵有层次的嵌套聚类树。在聚类树中,不同类别的原始数据点是树的最低层,树的顶层是一个聚类的根节点。
-
聚类树的创建方法:自下而上的合并,自上而下的分裂。(这里介绍第一种)
1.2 层次聚类的合并算法
层次聚类的合并算法通过计算两类数据点间的相似性,对所有数据点中最为相似的两个数据点进行组合,并反复迭代这一过程。简单的说层次聚类的合并算法是通过计算每一个类别的数据点与所有数据点之间的距离来确定它们之间的相似性,距离越小,相似度越高。并将距离最近的两个数据点或类别进行组合,生成聚类树。合并过程如下:
- 我们可以获得一个的距离矩阵 X,其中
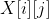 表示
表示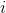 和
和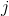 的距离,称为数据点与数据点之间的距离。记每一个数据点为
的距离,称为数据点与数据点之间的距离。记每一个数据点为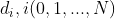 将距离最小的数据点进行合并,得到一个组合数据点,记为 G
将距离最小的数据点进行合并,得到一个组合数据点,记为 G
- 数据点与组合数据点之间的距离: 当计算G 和
 的距离时,需要计算和G中每一个点的距离。
的距离时,需要计算和G中每一个点的距离。 - 组合数据点与组合数据点之间的距离:主要有Single Linkage,Complete Linkage和Average Linkage 三种。这三种算法介绍如下,摘自:
Single Linkage
Single Linkage的计算方法是将两个组合数据点中距离最近的两个数据点间的距离作为这两个组合数据点的距离。这种方法容易受到极端值的影响。两个很相似的组合数据点可能由于其中的某个极端的数据点距离较近而组合在一起。
Complete Linkage
Complete Linkage的计算方法与Single Linkage相反,将两个组合数据点中距离最远的两个数据点间的距离作为这两个组合数据点的距离。Complete Linkage的问题也与Single Linkage相反,两个不相似的组合数据点可能由于其中的极端值距离较远而无法组合在一起。
Average Linkage
Average Linkage的计算方法是计算两个组合数据点中的每个数据点与其他所有数据点的距离。将所有距离的均值作为两个组合数据点间的距离。这种方法计算量比较大,但结果比前两种方法更合理。
二、Python实现
可以直接使用 scipy.cluster.hierarchy.linkage !!!
如下代码实现的是将一组数进行层次聚类。
# -*- coding: utf-8 -*-
import numpy as np
from scipy.cluster.hierarchy import dendrogram, linkage, fcluster
from matplotlib import pyplot as plt
def hierarchy_cluster(data, method='average', threshold=5.0):
'''层次聚类
Arguments:
data [[0, float, ...], [float, 0, ...]] -- 文档 i 和文档 j 的距离
Keyword Arguments:
method {str} -- [linkage的方式: single、complete、average、centroid、median、ward] (default: {'average'})
threshold {float} -- 聚类簇之间的距离
Return:
cluster_number int -- 聚类个数
cluster [[idx1, idx2,..], [idx3]] -- 每一类下的索引
'''
data = np.array(data)
Z = linkage(data, method=method)
cluster_assignments = fcluster(Z, threshold, criterion='distance')
print type(cluster_assignments)
num_clusters = cluster_assignments.max()
indices = get_cluster_indices(cluster_assignments)
return num_clusters, indices
def get_cluster_indices(cluster_assignments):
'''映射每一类至原数据索引
Arguments:
cluster_assignments 层次聚类后的结果
Returns:
[[idx1, idx2,..], [idx3]] -- 每一类下的索引
'''
n = cluster_assignments.max()
indices = []
for cluster_number in range(1, n + 1):
indices.append(np.where(cluster_assignments == cluster_number)[0])
return indices
if __name__ == '__main__':
arr = [[0., 21.6, 22.6, 63.9, 65.1, 17.7, 99.2],
[21.6, 0., 1., 42.3, 43.5, 3.9, 77.6],
[22.6, 1., 0, 41.3, 42.5, 4.9, 76.6],
[63.9, 42.3, 41.3, 0., 1.2, 46.2, 35.3],
[65.1, 43.5, 42.5, 1.2, 0., 47.4, 34.1],
[17.7, 3.9, 4.9, 46.2, 47.4, 0, 81.5],
[99.2, 77.6, 76.6, 35.3, 34.1, 81.5, 0.]]
arr = np.array(arr)
r, c = arr.shape
for i in xrange(r):
for j in xrange(i, c):
if arr[i][j] != arr[j][i]:
arr[i][j] = arr[j][i]
for i in xrange(r):
for j in xrange(i, c):
if arr[i][j] != arr[j][i]:
print(arr[i][j], arr[j][i])
num_clusters, indices = hierarchy_cluster(arr)
print "%d clusters" % num_clusters
for k, ind in enumerate(indices):
print "cluster", k + 1, "is", ind
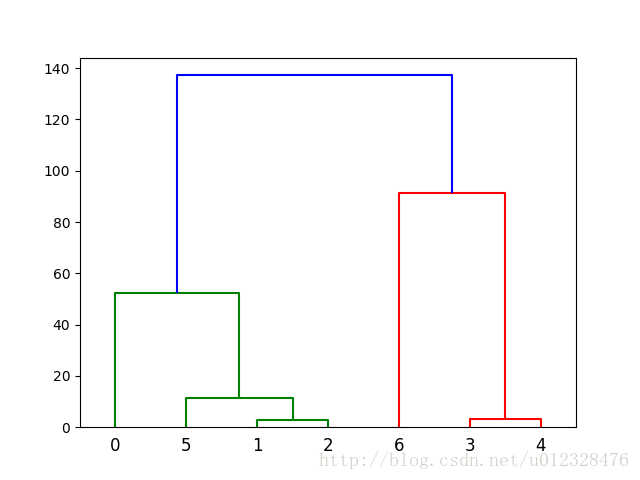
## 运行结果
5 clusters
cluster 1 is [1 2]
cluster 2 is [5]
cluster 3 is [0]
cluster 4 is [3 4]
cluster 5 is [6]
上述结果可视化: