【论文笔记】2022-CVPR-深度估计
2022-CVPR-深度估计
文章目录
- 2022-CVPR-深度估计
-
- 0. 摘要
- 1. 介绍
- 2. 相关工作
- 3. 系统
-
- 3.1 硬件
- 3.2 深度估计流程
- 3.3 单目结构光
- 3.4 立体匹配网络与融合策略
- 4. 实验
-
- 4.1 原型
- 4.2 数据集与评估指标
- 4.3 定量估计
- 4.4 定性分析
- 4.5 限制
- 5. 结论
- 题目:Depth Estimation by Combining Binocular Stereo and Monocular Structured-Light
- 地址:https://arxiv.org/pdf/2203.10493.pdf
0. 摘要
-
被动立体系统不能很好地适应弱纹理物体,而弱纹理目标在室内环境很常见
-
本文提出了一种新型立体成像系统,它由两台摄像机(一台RGB摄像机和一台红外摄像机)和一台红外散斑投影仪组成。
- RGB摄像机用于深度估计和纹理获取
- 红外相机和散斑投影仪可以组成单片结构光(Monocular Structured-Light ,MSL)子系统
- 两个摄像头可以组成双目立体子系统
-
MSL子系统生成的深度图可以为立体匹配网络提供外部依据,显著提高匹配精度(这里使用了GSM方法,即Guided stereo matching) 。
-
为了验证该系统的有效性,建立了一个原型,并在室内场景中收集了测试数据集。
-
评估结果表明,采用网络RAFT时,该系统的Bad2.0误差为被动立体系统的28.2%。
-
数据集和训练模型地址:https://github.com/yuhuaxu/monostereofusion
1. 介绍
- 一些深度获取方法:
- 单目结构光:Kinect、iPhone X,缺点,无法获得远处物体或者强光下的室外场景的深度测量,无法获得某一特定尺度的深度图;
- 双目立体视觉:测量距离比较远,可以在阳光强烈的室外环境工作,缺点,易受到物体表面纹理的影响;
- 双目结构光:Intel D435,依靠两个红外摄像机和一个红外投影仪进行深度估计,在室内和室外都有很好的适应性。要获取纹理,需要第三个摄像头(即RGB摄像头)。缺点,由于在RGB相机和IR相机之间存在基线,因此需要进行系统转换以使深度图像与RGB图像对齐。由于深度图的噪声和标定参数的误差,使得RGB图像与深度图的精确对齐变得困难。硬件方面,需要三个摄像头和一个投影仪,并不紧凑。
- TOF:对低反射率物体和远距离物体的适应能力较差,还受到多径干扰(multipath interference)的影响
- 贡献:整合单目结构光和双目立体视觉优点,提出一种结构紧凑的深度传感方案
- 提出了一种由RGB摄像机、IR摄像机和IR散斑投影仪组成的立体视觉系统。
- IR相机没有附加滤光片。同时接收红外光和环境光
- 单目主动结构光系统:IR摄像机+IR投影仪
- 双目立体系统:IR摄像机+RGB摄像机
- 优势互补:主动结构光系统对被动双目立体系统难以处理的弱纹理物体(如白墙)具有鲁棒性。通过在立体匹配网络的代价体中融合单目结构光系统获得的初始深度图,得到得到一个鲁棒的立体系统
- 搭建了原型硬件系统,并收集了一个新的立体数据集,用于将单目结构光和双目立体视觉(MonoBinoStereo)结合起来,以验证所提方法的有效性。该数据集将开放供进一步研究。
- 发现DNN可以准确地估计一对非对称立体图像的散斑图,其中一幅是被动的,另一幅是主动的(带有散斑)。
- 所提系统的特点:
- 与经典的双目立体视觉相比,在室内环境下,它对弱纹理目标和富纹理目标都具有较强的鲁棒性。
- 与现有的单目结构光系统(如Kinect)相比,它具有更大的测量距离范围和更好的室外环境性能。
- 与现有的主动式深度传感系统(如Kinect和Intel D435)相比,其输出的深度图具有更好的完整性。此外,深度图与RGB图像逐像素自然对齐。
- 在室外环境中,由于受到强烈阳光的干扰,它将退化为一种普通的被动双目立体系统。
2. 相关工作
- Zbontar等人[Computing the stereo matching cost with a convolutional neural network]首先使用卷积神经网络(CNN)比较两个图像块(如9×9或11×11)并计算它们的匹配代价。如代价聚合、视差计算和dis-parity细化,仍然是传统的方法。MC-CNN显著提高了视觉效果,但仍然难以在无纹理、反射和遮挡区域产生准确的视差结果,而且耗时较长。
- DispNetC[A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation]是第一个端到端立体匹配网络,它的效率更高,几乎是MC-CNN-Acrt的1000倍。在DispNetC中,有一个显式的相关层。在传统的立体匹配方法中,通常有一个视差细化模块。受此启发,利用残差细化层进一步提高预测精度。另外,将分割信息和边缘信息结合到立体匹配网络中,提高了匹配性能。
- Wang等人[Parallax attention for unsupervised stereo correspondence learning;Learning parallax attention for stereo image super-resolution]提出了一种通用的视差-注意机制,以捕获立体匹配相似性,而不管视差的变化。光流和校正立体匹配是密切相关的问题
- RAFT使用基于门控循环单元(GRU)的算子,使用从相关体中检索的特征迭代更新流场,RAFT具有很好的泛化能力。
- GC-Net[End-to-end learning of geometry and context for deep stereo regression]首先在4D成本体中使用三维卷积进行成本累积,并利用平滑argmin对视差进行回归。
- Duggal等人[Deeppruner: Learning efficient stereo matching via differentiable patchmatch]采用PatchMatch Stereo[Patchmatch stereo-stereo matching with slanted support windows]的思想,构建一个薄代价体来加快预测过程。基于方差的不确定性估计用于自适应调整薄代价体的视差搜索空间。
- 最近的工作[Pyramid stereo matching network, Deeppruner: Learning efficient stereo matching via differentiable patchmatch]表明,三维集合可以提高特定数据集的匹配精度。然而,三维卷积比二维卷积更耗时,难以在实时应用中应用。为了追求实时性能。
- StereoNet[Stereonet: Guided hierarchical refinement for edge-aware depth prediction]在低分辨率(例如,1/8分辨率)下执行3D卷积,然后分层地细化差异。由此产生的网络可以以60 fps的速度实时运行。然而,这种简化降低了网络的准确性。
- Xu等人[Bilateral grid learning for stereo matching networks]设计了一个基于双边网格的边缘保持代价体积上采样模块。利用上采样模块,可以从低分辨率版本中获得高分辨率的高质量代价体。上采样模块可以嵌入到现有的许多立体匹配网络中,如GCNet、PSMNet和GANet[Ga-net: Guided aggregation net for endto-end stereo matching]。所得到的网络可以在保持相当精度的情况下加快数倍。
- HITNet[Hitnet: Hierarchical iterative tile refinement network for real-time stereo matching]没有显式地建立一个体积,而是依靠快速的多分辨率初始化步骤、可微的二维几何传播和扭曲机制来推断视差假设。为了获得较高的精度,该方法推导出倾斜平面假设,从而可以准确地进行几何变换和上采样操作。
- 为了减轻计算负担,Yao等人[A decomposition model for stereo matching]提出了一种分解模型,该模型在很低的分辨率下执行密集匹配(例如20×36)并在不同的高分辨率下使用稀疏匹配来逐级恢复丢失细节的差异。
- ActiveStereoNet[Activestereonet: End-to-end self-supervised learning for active stereo systems]是第一个用于主动立体系统的深度学习解决方案。由于缺乏地真值,网络被设计成完全自我监督。
- Riegler等人[Connecting the dots: Learning representations for active monocular depth estimation]没有通过对应搜索问题来制定深度估计。他们证明了在单目结构光系统中,一个简单的卷积结构就足以得到高质量的分布估计。
- 我们的工作还涉及到图像引导的深度计算,其任务是从稀疏的深度测量中估计出稠密的深度图。
- Ma等人[Sparse-to-dense: Depth prediction from sparse depth samples and a single image]提出将稀疏深度和彩色图像的级联馈入编码器-解码器深度网络。
- Jaritz等人[Sparse and dense data with cnns: Depth completion and semantic segmentation]结合语义分割提高深度完成度。
- Cheng等人[Depth estimation via affinity learned with convolutional spatial propagation network]提出了一个卷积空间传播网络(CSPN)对深度补全结果与相邻深度值进行后处理。但是,CSPN依赖于固定局部邻域,这些邻域可能来自不相关的对象。
- Park等人[Non-local spatial propagation network for depth completion]提出了一种用于深度完成的非局部空间传播网络。该方法可以有效地避免不相关的局部噪声,并集中于相关的非局部邻居的传播。
- Qiu等人[Deeplidar: Deep surface normal guided depth prediction for outdoor scene from sparse lidar data and single color image]学习到曲面法线作为中间表示。
- Xu等人[Depth completion from sparse lidar data with depth-normal constraints] 在扩散模块中模拟了深度和表面法线之间的几何约束,并预测了稀疏激光雷达测量的置信度,以减轻噪声的影响。
- 为了解决深度涂抹问题,Imran等人[Depth completion with twin surface extrapolation at occlusion boundaries]提出了一种多假设的深度表示方法,该方法在困难的遮挡边界区域同时模拟前景和背景深度。
- 与深度补全方法相比,我们的方法可以利用单目结构光子系统的立体对和深度导引进行视差估计。当深度引导不可用时,立体对仍可用来估计目标的深度。立体图像比单幅图像能形成更强的约束。
3. 系统
3.1 硬件

如上图,提出的立体系统由两个子系统组成。
- 首先,红外摄像机和红外投影仪构成一个主动式单目结构光子系统。
- 第二,IR摄像机和RGB摄像机组成双目立体子系统。
- 单目结构光子系统对弱纹理目标具有较强的鲁棒性,而双目结构光子系统对远距离目标具有良好的重建能力,可以在室外环境下工作。
- 因此,这两个子系统具有互补的优势。
3.2 深度估计流程
如上图所示,输入包括RGB图像、IR图像和参考散斑图像。其中参考散斑图像预先存储并固定在单目结构光子系统中。
- 首先对目标当前红外图像和参考散斑图像进行匹配,生成视差图 d m d_{m} dm;
- 利用单目结构光子系统的定标参数,可以获得深度图 Z m Z_{m} Zm,并将其重新投影到RGB相机坐标系统中;
- Z m ′ Z^{'}_{m} Zm′表示与RGB图像对齐的深度图,用 d m ′ d^{'}_{m} dm′表示对应的视差图;
- 然后将RGB图像、IR图像和视差图 d m ′ d^{'}_{m} dm′送入立体匹配网络估计最终的视差图。
3.3 单目结构光
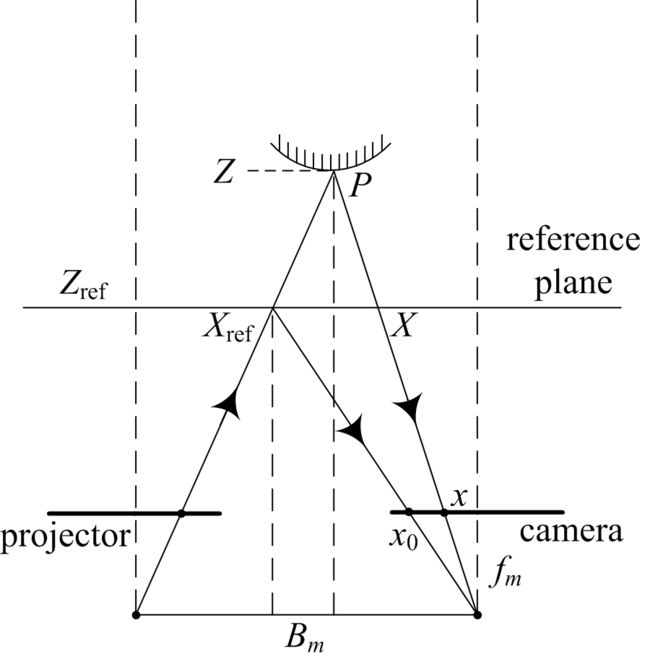
由图可知,深度的变化会带来散斑在水平方向上的移动
-
单目结构光深度估计原理(空间编码)
- 目标当前散斑图像与参考散斑图像匹配,参考散斑图像是当照相机的光轴垂直于平面目标在已知距离 Z r e f Z_{ref} Zref处时捕获的散斑图像。
- 为了消除两幅图像亮度不同的影响,我们遵循**[Depth estimation for speckle projection system using progressive reliable points growing matching]**中的方法将这些图像转换为二值图像。
- 然后,利用一种有效的块匹配算法计算两幅图像之间的对应关系,得到视差图 d m d_{m} dm。匹配窗口大小设置为21×21。
- 利用视差图,我们可以通过以下公式得到深度图 Z m Z_{m} Zm
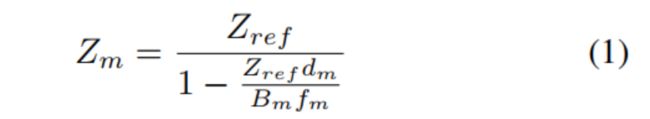
- 其中 B m B_{m} Bm是基线, f m f_{m} fm是焦距, Z r e f Z_{ref} Zref已知距离
- 根据单目结构光系统的表单参数,可以将深度图 Z m Z_{m} Zm转换到RGB相机的像面上,得到与RGB图像对齐的深度图 Z m ′ Z^{'}_{m} Zm′
- 然后通过以下公式在双目立体视差系统中获得相应的视差图:
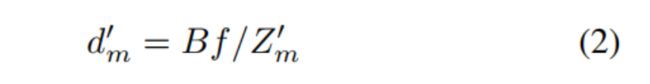
- B B B是双目系统的基线, f f f是双目系统的焦距
3.4 立体匹配网络与融合策略

红外相机可以接收红外散斑光和环境光。因此,在室内环境中,两台摄像机的图像在外观上有很大的不同,如上图所示。似乎很难匹配这类图像。幸运的是,我们发现深度神经网络(DNN)可以获得准确的匹配结果。
-
验证DNN对这类具有非对称纹理的双目图像的适应性
- 首先修改Flyingthings3D训练数据集和测试数据集,修改后,左图像保持不变,而右图像中添加了数万个随机斑点,如下图。

- 改进后的数据集中的立体图像具有不对称的特征
- 散斑的亮度随着这些点到摄像机的距离而减小,从而模拟光能的能量衰减(这样更符合实际物理规律)
- 然后,我们使用原始训练数据集和修改后的训练数据集训练了两个现有的立体匹配网络,包括PSMNet[Pyramid stereo matching network]和RAFT[Raft: Recurrent all-pairs field transforms for optical flow]
- RAFT在光流估计任务中具有很好的泛化能力,光流估计需要同时估计X和Y方向的位移。这里,我们做了一个小的修改,只估计X方向的位移
-
下图表明这些网络对这种不对称的立体图像有很好的适应能力(更多细节见4.3小节)
-
使用后缀O、M和OM分别表示用原始Flyingthings3D数据集、修改后的Flyingthings3D数据集以及这两个数据集的混合训练的模型。后缀G表示引导在网络中使用。
-
下图显示各网络定性结果
-
尽管在有源结构光系统的深度图中通常有许多无效值(如下图,黑色部分位无效值),但深度值是相对可靠的。因此,有效的深度值可以作为立体匹配网络的指导。


- 立体匹配网络中的代价体由几何和上下文信息组成,允许后续卷积回归视差概率。为了集成单目结构光系统的优点,我们根据单目结构光系统转换得到的视差图 d m ′ d^{'}_{m} dm′对代价体进行了修正,如在引导立体匹配(GSM)[Guided stereo matching]中所做的。
在GSM中,稀疏提示信息产生的假设,其相关性分数和特征激活达到峰值,同时会抑制与提示信息相关低的部分
- 部分假设与相关数学公式
- g g g:转换MSL视差图的w×h矩阵, v v v:二值掩膜,指出 g g g矩阵中有效的像素;
- 代价体
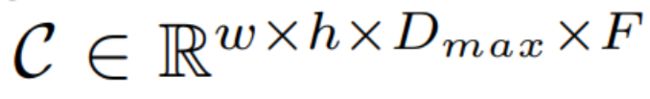 ,其中 D m a x D_{max} Dmax是最大是视差, F F F是特征数
,其中 D m a x D_{max} Dmax是最大是视差, F F F是特征数 - 令像素坐标为 ( x , y ) (x,y) (x,y),由外部是视差转换而来的视差值为 g ( x , y ) g(x,y) g(x,y),GSM应用高斯函数:
- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GSZwHDjy-1649041294716)(D:\研一文件\笔记\Markdown\论文笔记\2022-CVPR-深度估计\image-20220403165010685.png)]
- σ \sigma σ决定高斯分布的宽, λ ( λ > = 1 ) \lambda(\lambda>=1) λ(λ>=1)表示最大幅值
- GSM将上述高斯函数作用在代价体的特征 C ( x , y , z ) \mathcal{C}(x,y,z) C(x,y,z)上,从而获得一个新的代价体。
- 对于RAFT来说,为了避免收敛到负相关值,代价体的相关值(correlation values)会进行归一化处理,用下面公式实现:
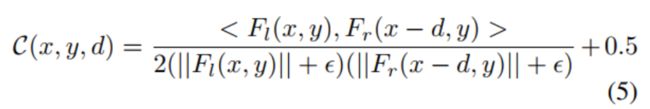
- 其中 F l F_{l} Fl和 F r F_{r} Fr是从左右图提取的特征, d d d表示视差, ϵ \epsilon ϵ表示一个小常数
- 由单目系统视差转换到RGB像面的视差图 d m ′ d_{m}^{'} dm′,作为立体匹配网络的外部指导。

4. 实验
4.1 原型
- 硬件参数:同步cmos相机×2 + IR投影仪×1
- 相机参数:焦距4mm,分辨率1280×960,最大帧率30fpsRGB相机带有红外滤除滤镜,IR相机没有滤镜
- 投影仪参数:带有DOE(diffractive optical element ,衍射光学元件)的散斑投射器
- 单目子系统:基线距离63mm,参考平面距离80cm,白墙11000个散斑点
- 双目子系统:基线距离94.14mm
4.2 数据集与评估指标
-
合成数据集:SceneFlow[A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation. ]包括,Flyingthings3D, Driving和Monkaa。
- 35454幅训练图像和4370幅测试图
- 分辨率960×540
- 有精确的视差真值
- 本文使用Flyingthings3D作为训练数据集,使用EPE作为评价指标。
EPE(Endpoint Error),是光流估计中标准的误差度量,
是预测光流向量与真实光流向量的欧氏距离在所有像素
上的均值。 -
实景数据集:收集了一个室内环境的数据集,包括办公室、起居室和卧室等不同的室内场景。
- 选择使用时空立体方法[Spacetime stereo: A unifying framework for depth from triangulation,Spacetime stereo: Shape recovery for dynamic scenes]来获得视差真值,参考[Probabilistic tof and stereo data fusion based on mixed pixels measurement models]中的做法;
- 每个场景捕获200对立体图像;
- 视差真值是通过融合所有200对立体对估计得到的;
- 应用了亚像素细化和左-右一致性检查(LRC);
- MonoBinoStereo数据集总共包括15个场景。每个场景收集两个立体声对,其中左边的图像总是被动的RGB图像,而右边相机的一个图像是被动的(关闭投影仪),另一个是主动的(打开投影仪)。下图是投影仪打开的一些立体对。

在图像获取过程中,同时投影成千上万的运动散斑,使得每个帧的散斑分布是不同的
- 缺乏真实的室内场景大型训练数据集:使用IRS数据集作为训练数据集对Monobinostereo数据集进行评估。
- 合成的IRS数据集[Irs: A large synthetic indoor robotics stereo dataset for disparity and surface normal estimation.]与真实场景相当接近。它包含超过10万对960×540分辨率立体图像(84,946个用于训练,15079个用于测试)在室内场景;
- 在补充材料中详细介绍了网络培训。
4.3 定量估计
- 首先在SceneFlow数据集上对所提出的方法进行了评估:
- 分别用原始Flyingthings3D数据集和修改后的Flyingthings3D数据集训练PSMNet和RAFT
- PSMNet-O,原始Flyingthings3D数据集;PSMNet-M,修正Flyingthings3D数据集;PSMNet-OM,原始+修正。
-
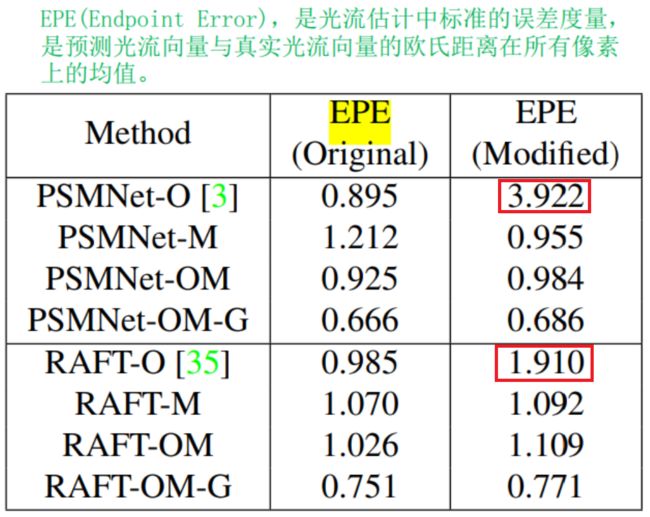 + 当用原始数据集训练模型时,修改后的测试数据集上的EPE较大; + 当使用修改后的训练数据集时,得到的模型(PSMNet-M)的EPE降低到0.955。然而,原始测试数据集的EPE从0.895增加到1.212; + 使用两个训练数据集时,生成的模型(PSMNet-OM)可以平衡两个测试数据集; + 使用**GSM**中的策略来进一步改善结果,PSMNet-OM-G。以真实深度图5%的像素作为外部指导,修正后的测试数据集的EPE由0.984降低到0.686。
+ 当用原始数据集训练模型时,修改后的测试数据集上的EPE较大; + 当使用修改后的训练数据集时,得到的模型(PSMNet-M)的EPE降低到0.955。然而,原始测试数据集的EPE从0.895增加到1.212; + 使用两个训练数据集时,生成的模型(PSMNet-OM)可以平衡两个测试数据集; + 使用**GSM**中的策略来进一步改善结果,PSMNet-OM-G。以真实深度图5%的像素作为外部指导,修正后的测试数据集的EPE由0.984降低到0.686。
上面的规律说明对称的立体对和不对称的立体对存在明显差异,但是通过综合训练两种立体对,能取得互补的效果,然后在再增加指导信息,效果之前更优。
-
在采集的实景数据集上对模型进行了评估:
-
混合**Flyingthings3D(合成数据集)和IRS数据集(接近真实场景的合成数据集)**对模型进行训练。
-

- 以RAFT为例,在DOE投影仪打开的情况下,仅使用原始数据集(Flyingthings3D和IRS)进行训练的情况下,RAFT-O的BAD2.0误差高达21.88%,添加了修改数据集后RAFT-OM模型的Bad2.0误差降低到了14.60%。
- 单目结构光子系统的深度图可以作为立体匹配网络的外部指导。我们使用 d m ′ d^{'}_{m} dm′中10%的像素作为指导。当使用此指导时,RAFT-OM-G模型的Bad2.0误差降低到3.59%。
- 上图还显示了不同模型对纯被动立体(投影仪关闭)数据集的定量结果。
-
由于代价体是在RAFT的1/8分辨率下建立的,实际上在 d m ′ d^{'}_{m} dm′中只有1/640的像素用于指导 。被动立体视觉的引导信息不可用。
- 被动测试数据集上运行模型RAFT-O。BAD2.0误差为12.71%,是RAFT-OM-G的3.5倍。结果表明,该方法能显著提高立体匹配精度。在无源数据集上,RAFT-OM-G的BAD2.0误差为10.51%(不使用外部指导),表明RAFT-OM-G可以很好地推广到无源场景中。
- 上图还显示在MonoBinoStereo数据集中,RAFT的整体性能方面优于PSMNet。
- 还在 d m ′ d^{'}_{m} dm′中以1%的像素点作为指导,在MonoBinoStereo数据集上与一种深度补全方法**MSG[A multi-scale guided cascade hourglass network for depth completion]**进行了比较。结果如上图所示。MSG的Bad2.0误差为18.57%,比RAFT-OM-G大得多。
- 下面是定性分析的一些结果

第一行显示左边的图像(在网络预测之前将RGB图像转换为灰度图像),
第二行显示了带有斑点的右图像(无源右图像未显示),
第三行是用时空立体方法生成的视差图真值,
第四行显示了用MSL子系统生成的深度图像,
第五行显示了用于无源立体图像的RAFT-O视差图,
最后一行显示了RAFT-OM-G视差图,其中左图像是无源的,右图像是带有斑点的。
在第五行和第六行中,每个视差图都显示了BAD2.0误差。相应的误差图显示在补充材料中
4.4 定性分析
在有人的动态场景和难以获得地面真实感视差图的室外场景中对所提出的系统进行了测试。对于这些场景,给出了定性比较结果。
- 所提出的系统与Kinect V1在室内和室外场景中进行了比较:
- Kinect在室内场景可以生成密集深度估计,而在室外场景中,由于投射的红外散斑受到太阳光的干扰,深度图中的空洞较多。
- 所提出的系统,在室外场景它将退化为一个被动的双目立体系统,在该系统中,立体对仍然可以用来估计场景的密集深度图
- 与Intel RealSense D435进行了比较:

D435使用两个摄像头获取深度图,第三个摄像头获取纹理,不可避免的会产生遮挡。相比之下,我们的系统只需两个摄像头就可以输出与RGB图像自然对齐的深度图。
4.5 限制
- 限制一:在单目结构光系统中,需要一个已知深度 Z r e f Z_{ref} Zref的平面目标的参考图像。在获取参考图像时,我们假设摄像机的操作轴垂直于平面目标,这在实际中是很难保证的。
- 限制二:相对于双目立体系统,单目结构光系统的标定难度更大。标定误差会导致RGB图像与 Z m Z_{m} Zm深度的对准误差,从而导致导引立体匹配网络中的导引错误。
- 限制三:在实验中,我们发现增加外部指导点的数量并不能提高精度(详见补充材料)。此外,在相同的外部指导点数下,对RAFT-OM-G的Bad0.5,Bad1.0和Bad2.0误差分别为12.94,4.94和2.00。
- 因此,在未来的研究中,将致力于单目结构光系统的精确标定方法,以进一步提高单目结构光系统的性能。
5. 结论
-
本文提出了一种新颖的立体系统。
-
该系统包括一个单目结构光子系统和一个双目立体子系统。将这两个子系统结合起来以获得鲁棒的深度估计。
-
系统是独一无二的,因为它只有两个摄像头,一个RGB摄像头和一个IR摄像头。RGB相机用于深度测量和纹理获取。得到的深度图与RGB图像逐像素自然对齐。
-
在室内场景中收集了一个真实的测试数据集。
-
定量结果表明,该系统的Bad2.0误差是经典无源立体系统的28.2%。
-
在室外强光下,所提出的系统将退化为被动立体系统。