Pytorch实现基于深度学习的面部表情识别(最新,非常详细)
目录
- 一、项目背景
- 二、数据预处理
-
- 1、标签与特征分离
- 2、数据可视化
- 3、分割训练集和测试集
- 三、搭建模型
- 四、训练模型
- 五、训练结果
- 附录
一、项目背景
基于深度学习的面部表情识别
(Facial-expression Recognition)
数据集cnn_train.csv包含人类面部表情的图片的label和feature。
在这里,面部表情识别相当于一个分类问题,共有7个类别。
其中label包括7种类型表情:

一共有28709个label,即包含28709张表情包。
每一行就是一张表情包4848=2304个像素,相当于4848个灰度值(intensity)(0为黑, 255为白)
本项目同时支持GPU与CPU上运行。
二、数据预处理
1、标签与特征分离
对原数据进行处理,分离后分别保存为cnn_label.csv和cnn_data.csv
# cnn_feature_label.py
# ###一、将原始数据的label和feature(像素)数据分离
import pandas as pd
# 源数据路径
path = '../datasets/originalData/cnn_train.csv'
# 读取数据
df = pd.read_csv(path)
# 提取feature(像素)数据 和 label数据
df_x = df[['feature']]
df_y = df[['label']]
# 将feature和label数据分别写入两个数据集
df_x.to_csv('../datasets/cnn_data.csv', index=False, header=False)
df_y.to_csv('../datasets/cnn_label.csv', index=False, header=False)

2、数据可视化
对特征进一步处理,也就是将每个数据行的2304个像素值合成每张48*48的表情图,最后做成24000张表情包。
# face_view.py
# ###二、数据可视化,将每个数据行的2304个像素值合成每张48*48的表情图。
import cv2
import numpy as np
# 放图片的路径
path = '../images'
# 读取像素数据
data = np.loadtxt('../datasets/cnn_data.csv')
# 按行取数据并写图
for i in range(data.shape[0]):
face_array = data[i, :].reshape((48, 48)) # reshape
cv2.imwrite(path + '//' + '{}.jpg'.format(i), face_array) # 写图片
3、分割训练集和测试集
Step1:划分一下训练集和验证集。一共有28709张图片,我取前24000张图片作为训练集,其他图片作为验证集。新建文件夹cnn_train和cnn_val,将0.jpg到23999.jpg放进文件夹cnn_train,将其他图片放进文件夹cnn_val.
# cnn_picture_label.py
# ###三、表情图片和类别标注,
# 1.取前24000张图片作为训练集放入cnn_train,其他图片作为验证集放入cnn_val
# 2.对每张图片标记属于哪一个类别,存放在dataset.csv中,分别在刚刚训练集和测试集执行标记任务。
# #因为cpu训练太慢,我只取前2000张做训练,400张做测试!!,手动删除两个文件夹重dataset.csv的多余行数据
import os
import pandas as pd
def data_label(path):
# 读取label文件
df_label = pd.read_csv('../datasets/cnn_label.csv', header=None)
# 查看该文件夹下所有文件
files_dir = os.listdir(path)
# 存放文件名和标签的列表
path_list = []
label_list = []
# 遍历所有文件,取出文件名和对应的标签分别放入path_list和label_list列表
for file_dir in files_dir:
if os.path.splitext(file_dir)[1] == '.jpg':
path_list.append(file_dir)
index = int(os.path.splitext(file_dir)[0])
label_list.append(df_label.iat[index, 0])
# 将两个列表写进dataset.csv文件
path_s = pd.Series(path_list)
label_s = pd.Series(label_list)
df = pd.DataFrame()
df['path'] = path_s
df['label'] = label_s
df.to_csv(path + '\\dataset.csv', index=False, header=False)
def main():
# 指定文件夹路径
train_path = '../datasets/cnn_train'
val_path = '../datasets/cnn_val'
data_label(train_path)
data_label(val_path)
if __name__ == '__main__':
main()

Step2:对每张图片标记属于哪一个类别,存放在dataset.csv中,分别在刚刚训练集和测试集执行标记任务。
Step3:重写Dataset类,它是Pytorch中图像数据集加载的一个基类,需要重写类来实现加载上面的图像数据集
# rewrite_dataset.py
# ###四、重写类来实现加载上面的图像数据集。
import bisect
import warnings
import cv2
import numpy as np
import pandas as pd
import torch
import torch.utils.data as data
class FaceDataset(data.Dataset):
# 初始化
def __init__(self, root):
super(FaceDataset, self).__init__()
self.root = root
df_path = pd.read_csv(root + '\\dataset.csv', header=None, usecols=[0])
df_label = pd.read_csv(root + '\\dataset.csv', header=None, usecols=[1])
self.path = np.array(df_path)[:, 0]
self.label = np.array(df_label)[:, 0]
# 读取某幅图片,item为索引号
def __getitem__(self, item):
# 图像数据用于训练,需为tensor类型,label用numpy或list均可
face = cv2.imread(self.root + '\\' + self.path[item])
# 读取单通道灰度图
face_gray = cv2.cvtColor(face, cv2.COLOR_BGR2GRAY)
# 直方图均衡化
face_hist = cv2.equalizeHist(face_gray)
"""
像素值标准化
读出的数据是48X48的,而后续卷积神经网络中nn.Conv2d()
API所接受的数据格式是(batch_size, channel, width, height),
本次图片通道为1,因此我们要将48X48 reshape为1X48X48。
"""
face_normalized = face_hist.reshape(1, 48, 48) / 255.0
face_tensor = torch.from_numpy(face_normalized)
face_tensor = face_tensor.type('torch.FloatTensor')
# face_tensor = face_tensor.type('torch.cuda.FloatTensor')
label = self.label[item]
return face_tensor, label
# 获取数据集样本个数
def __len__(self):
return self.path.shape[0]
三、搭建模型
卷积神经网络模型如下:
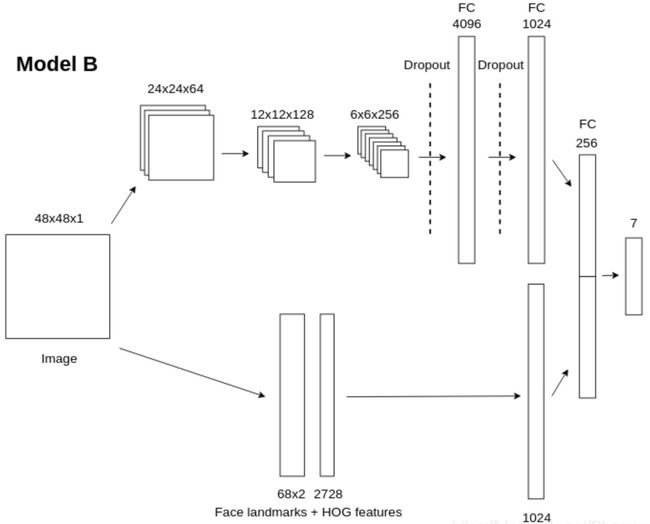
# CNN_face.py
# 定义一个CNN模型
"""
inputs(48*48*1) ->
conv(24*24*64) -> conv(12*12*128) -> conv(6*6*256) ->
Dropout -> fc(4096) -> Dropout -> fc(1024) ->
outputs(7)
"""
import torch.nn as nn
# 参数初始化
def gaussian_weights_init(m):
classname = m.__class__.__name__
# 字符串查找find,找不到返回-1,不等-1即字符串中含有该字符
if classname.find('Conv') != -1:
m.weight.data.normal_(0.0, 0.04)
class FaceCNN(nn.Module):
# 初始化网络结构
def __init__(self):
super(FaceCNN, self).__init__()
# layer1(conv + relu + pool)
# input:(bitch_size, 1, 48, 48), output(bitch_size, 64, 24, 24)
self.conv1 = nn.Sequential(
nn.Conv2d(1, 64, 3, 1, 1),
nn.BatchNorm2d(num_features=64),
nn.RReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2)
)
# layer2(conv + relu + pool)
# input:(bitch_size, 64, 24, 24), output(bitch_size, 128, 12, 12)
self.conv2 = nn.Sequential(
nn.Conv2d(64, 128, 3, 1, 1),
nn.BatchNorm2d(num_features=128),
nn.RReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2)
)
# layer3(conv + relu + pool)
# input: (bitch_size, 128, 12, 12), output: (bitch_size, 256, 6, 6)
self.conv3 = nn.Sequential(
nn.Conv2d(128, 256, 3, 1, 1),
nn.BatchNorm2d(num_features=256),
nn.RReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2)
)
# 参数初始化
self.conv1.apply(gaussian_weights_init)
self.conv2.apply(gaussian_weights_init)
self.conv3.apply(gaussian_weights_init)
# 全连接层
self.fc = nn.Sequential(
nn.Dropout(p=0.2),
nn.Linear(256*6*6, 4096),
nn.RReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(4096, 1024),
nn.RReLU(inplace=True),
nn.Linear(1024, 256),
nn.RReLU(inplace=True),
nn.Linear(256, 7)
)
# 向前传播
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = x.view(x.shape[0], -1) # 数据扁平化
y = self.fc(x)
return y
四、训练模型
损失函数使用交叉熵,优化器是随机梯度下降SGD,其中weight_decay为正则项系数,每轮训练打印损失值,每10轮训练打印准确率。
# train.py
# 定义训练轮
import torch
import torch.utils.data as data
import torch.nn as nn
import numpy as np
from torch import optim
from models import CNN_face
from dataloader import rewrite_dataset
def train(train_dataset, val_dataset, batch_size, epochs, learning_rate, wt_decay, print_cost=True, isPlot=True):
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 加载数据集并分割batch
train_loader = data.DataLoader(train_dataset, batch_size)
# 构建模型
model = CNN_face.FaceCNN()
model.to(device)
# 损失函数和优化器
compute_loss = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=learning_rate, weight_decay=wt_decay)
# 学习率衰减
# scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.8)
for epoch in range(epochs):
loss = 0
model.train()
for images, labels in train_loader:
optimizer.zero_grad()
outputs = model.forward(images)
loss = compute_loss(outputs, labels)
loss.backward()
optimizer.step()
# 打印损失值
if print_cost:
print('epoch{}: train_loss:'.format(epoch + 1), loss.item())
# 评估模型准确率
if epoch % 10 == 9:
model.eval()
acc_train = validate(model, train_dataset, batch_size)
acc_val = validate(model, val_dataset, batch_size)
print('acc_train: %.1f %%' % (acc_train * 100))
print('acc_val: %.1f %%' % (acc_val * 100))
return model
# 验证模型在验证集上的正确率
def validate(model, dataset, batch_size):
val_loader = data.DataLoader(dataset, batch_size)
result, total = 0.0, 0
for images, labels in val_loader:
pred = model.forward(images)
pred_tmp = pred.cuda().data.cpu().numpy()
pred = np.argmax(pred_tmp.data.numpy(), axis=1)
labels = labels.data.numpy()
result += np.sum((pred == labels))
total += len(images)
acc = result / total
return acc
def main():
train_dataset = rewrite_dataset.FaceDataset(root=r'D:\01 Desktop\JUST_YAN\05 DeepLearning\Facial-expression_Reg\datasets\cnn_train')
val_dataset = rewrite_dataset.FaceDataset(root=r'D:\01 Desktop\JUST_YAN\05 DeepLearning\Facial-expression_Reg\datasets\cnn_val')
model = train(train_dataset, val_dataset, batch_size=128, epochs=100, learning_rate=0.01,
wt_decay=0, print_cost=True, isPlot=True)
torch.save(model, 'model_net.pkl') # 保存模型
if __name__ == '__main__':
main()
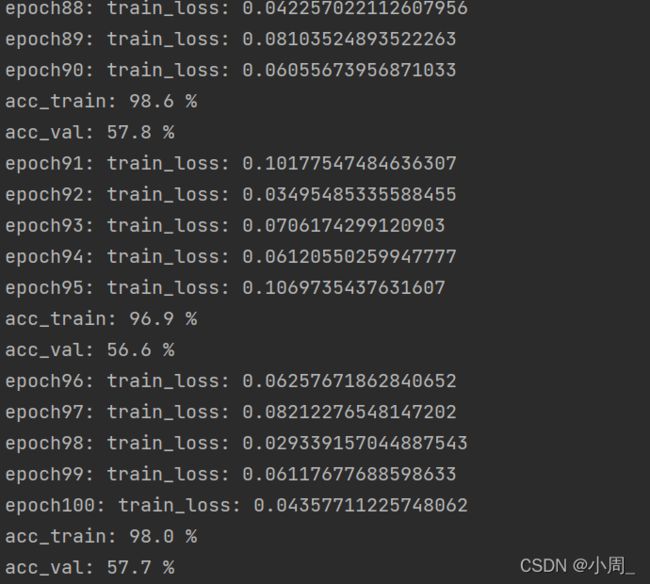
五、训练结果
在超参数为:batch_size=128, epochs=100, learning_rate=0.01, wt_decay=0,的情况下跑得最终结果如下:
附录
代码已托管到GitHub和Gitee:
GitHub:https://github.com/HaoliangZhou/FERNet
Gitee: https://gitee.com/zhou-zhou123c/FERNet
参考资料:
https://blog.csdn.net/Charzous/article/details/107452464/
数据集
数据集cnn_train.csv