繁凡的对抗攻击论文精读(二)CVPR 2021 元学习训练模拟器进行超高效黑盒攻击(清华)
点我轻松弄懂深度学习所有基础和各大主流研究方向入门综述!
《繁凡的深度学习笔记》,包含深度学习基础和 TensorFlow2.0,PyTorch 详解,以及 CNN,RNN,GNN,AE,GAN,Transformer,强化学习,元学习,对抗攻击防御,迁移学习等主流研究方向万字综述!
繁凡的对抗攻击论文精读(二)CVPR 2021 元学习训练模拟器进行超高效黑盒攻击(清华)
Simulating Unknown Target Models for Query-Efficient Black-box Attacks
为查询有效的黑盒攻击模拟未知目标模型
https://fanfansann.blog.csdn.net/
声明:
1)本文《繁凡的对抗攻击论文精读》是 《繁凡的论文精读》 系列对抗攻击领域的论文精读笔记。 《繁凡的论文精读》 项目 暂时包含三大板块,即:《繁凡的NLP论文精读》、 《繁凡的CV论文精读》 以及 《繁凡的对抗攻击论文精读》,项目地址:https://github.com/fanfansann/DL-papers-intensive-reading-notes-NLP-and-CV
该项目内包含精读论文的原文、精读笔记PDF、模型复现代码等论文相关资源,欢迎 Starred ⭐ \,\,\,\text{Starred}⭐ Starred⭐ o(〃^▽^〃)o
2)本人才疏学浅,整理总结的时候难免出错,还望各位前辈不吝指正,谢谢。
3)本文由我个人( CSDN 博主 「繁凡さん」(博客) , 知乎答主 「繁凡」(专栏), Github 「fanfansann」(全部源码) , 微信公众号 「繁凡的小岛来信」(文章 P D F 下载))整理创作而成,且仅发布于这四个平台,仅做交流学习使用,无任何商业用途。
4)《繁凡的论文精读》全汇总链接:《繁凡的论文精读》目录大纲 https://fanfansann.blog.csdn.net(待更)
文章目录
- Simulating Unknown Target Models for Query-Efficient Black-box Attacks [1]
- 为查询有效的黑盒攻击模拟未知目标模型
-
- Abstract
- 0x01 论文总结
-
- 2. Related Works
- 3. Method
-
- 3.1. Task Generation
- 3.2. Simulator Learning
- 3.3. Simulator Attack
- 3.4. Discussion
- 4. Experiment
-
- 4.1. Experiment Setting
- 4.2. Ablation Study
- 4.3. Comparisons with State-of-the-Art Methods
- 0x02 全文翻译
-
- 1. Introduction
- 2. Related Works
- 3. Method
-
- 3.1. Task Generation
- 3.2. Simulator Learning
- 3.3. Simulator Attack
- 3.4. Discussion
- 4. Experiment
-
- 4.1. Experiment Setting
- 4.2. Ablation Study
- 4.3. Comparisons with State-of-the-Art Methods
- 5. Conclusion
- 0x03 论文模型代码实现
- 0x04 预备知识
-
- 0x04.1 元学习
- 0x05 References
Simulating Unknown Target Models for Query-Efficient Black-box Attacks [1]
为查询有效的黑盒攻击模拟未知目标模型
Abstract
Many adversarial attacks have been proposed to invesigate the security issues of deep neural networks. In the black-box setting, current model stealing attacks train a substitute model to counterfeit the functionality of the target model. However, the training requires querying the target model. Consequently, the query complexity remains high, and such attacks can be defended easily. This study aims to train a generalized substitute model called “Simulator” which can mimic the functionality of any unknown target model. To this end, we build the training data with the form of multiple tasks by collecting query sequences generated during the attacks of various existing networks. The learning process uses a mean square error-based knowledgedistillation loss in the meta-learning to minimize the difference between the Simulator and the sampled networks The meta-gradients of this loss are then computed and ac.cumulated from multiple tasks to update the Simulator and subsequently improve generalization. When attacking a target model that is unseen in training, the trained Simulator can accurately simulate its functionality using its limited feedback. As a result, a large fraction of queries can be transferred to the Simulator thereby reducing query complexity. Results of the comprehensive experiments conducted using the CIFAR-10, CIFAR-100, and TinyImageNet datasets demonstrate that the proposed approach reduces query complexity by several orders of magnitude compared to the baseline method. The implementation source code isreleased online [2]
Translation
为了研究深度神经网络的安全问题,已经提出了许多对抗性攻击方法。在黑盒设置中,当前的模型窃取攻击训练替代模型来伪造目标模型的功能。但是,训练需要查询目标模型。因此,查询复杂度仍然很高,并且可以轻松防御此类攻击。本研究旨在训练一个称为“模拟器”的通用替代模型,该模型可以模拟任何未知目标模型的功能。为此,我们通过收集各种现有网络攻击过程中产生的查询序列,以多任务的形式构建训练数据。学习过程在元学习中使用基于均方误差的知识蒸馏损失来最小化模拟器和采样网络之间的差异。然后计算并从多个任务中累积该损失的元梯度以更新模拟器和随后改进泛化。当攻击在训练中看不见的目标模型时,经过训练的模拟器可以使用其有限的反馈准确地模拟其功能。因此,可以将大部分查询传输到模拟器,从而降低查询复杂性。使用 CIFAR-10、CIFAR-100 和 TinyImageNet 数据集进行的综合实验结果表明,与基线方法相比,所提出的方法将查询复杂度降低了几个数量级。实现源码已在线发布 [2]
Summarize
- 提出了一种名为 Simulator Attack 的新型黑盒攻击。 它侧重于训练一个广义替代模型(“Simulator”)来准确模仿任何未知目标模型,以降低攻击的查询复杂度。为此将攻击许多不同网络时产生的查询序列作为训练数据;
- 所提出的方法在元学习的内部和外部更新中使用基于 MSE 的知识蒸馏损失来学习模拟器;
- 可以在训练之后将大量查询转移到模拟器,从而降低与基线相差的几个数量级查询复杂度的攻击。
0x01 论文总结
2. Related Works
Meta-learning. 元学习在少样本分类中很有用。它训练了一个元学习器,只需几个样本就可以快速适应新环境。Ma 等人 [28] 提出 MetaAdvDet 以高精度检测新型对抗性攻击,以便在对抗性攻击领域利用元学习。 Meta Attack [12] 训练自编码器来预测目标模型的梯度以降低查询复杂度。然而,它的自编码器仅在自然图像和梯度对上进行训练,而不是在来自真实攻击的数据上进行训练。因此,它的预测精度在攻击中并不满足。然而如果图片分辨率较高,则梯度map是一个很大的矩阵,此时轻量级的自编码器就无法准确预测梯度map的梯度值。因此,Meta Attack 仅提取具有最大梯度值的 125 125 125 个元素来更新示例,导致性能不佳,在攻击高分辨率图片时仍显得心有余而力不足。此外,训练数据是黑盒攻击的查询序列。分为元训练集和元测试集。前者对应于微调迭代,后者对应于攻击中的模拟迭代。这些策略将训练和攻击无缝连接,以最大限度地提高性能。
3. Method
本文致力于降低 query-based attack 的查询复杂度,因为假若攻击单个样本仅需要两位数的查询量时,该攻击便具有现实威胁。我们发现,任何黑盒模型都可以被一个相似的代理模型(即模拟器)所替代,如果能将一部分查询转移到这个模拟器上,那么真正的目标模型的查询压力便随之降低。为了做出这种模拟器,研究者们不断探索,诞生了被称为模型窃取攻击的办法,然而,模型窃取攻击需要在训练模拟器的时候大量查询目标模型。因此,这种攻击方式仍然会造成大量的查询,而且这种查询可以轻易地被目标模型的拥有者检测和防御。模拟器攻击首次解决了这个问题,Simulator 在训练的阶段中没有与目标模型有任何交互,仅仅是攻击时花费少量的查询,可以极大地节省攻击的查询量。总结一下,模拟器攻击在训练阶段时使用大量不同的现有模型生成的训练数据,并且将知识蒸馏损失函数应用在元学习中,这样在测试的时候就可以模拟任何未知的黑盒模型。
在本研究中,我们专注于在不使用目标模型的情况下训练替代模型并产生基于分数的攻击。
3.1. Task Generation
在攻击期间,当反馈的查询彼此之间仅略有不同时,经过训练的模拟器必须准确地模拟任何未知目标模型的输出。为此,模拟器应该从真实的攻击中学习。即各种网络攻击产生的中间数据(查询序列和输出)。 为此收集了一些分类网络 N 1 … , N n N_1\dots, N_n N1…,Nn 来构建训练任务,创建一个巨大的仿真环境来提高通用仿真能力(图 2)。每个任务包含 V V V 个查询对 Q 1 , … , Q V ( Q i ∈ R D , i ∈ { 1 , … , V } ) Q_1,\dots,Q_V(Q_i\in\R^D,i\in\{1, \dots,V\}) Q1,…,QV(Qi∈RD,i∈{1,…,V}) ,其中 D D D 为图像维数。这些对是通过使用土匪攻击随机选择的网络而产生的。土匪使用的数据源可以是从互联网上下载的任何图像。在本研究中,我们使用标准数据集的训练集与测试图像的数据分布不同。每个任务被划分为两个子集,即元训练集 D mtr D_{\text{mtr}} Dmtr,它由前 t t t 个查询对 Q 1 , … Q t Q_1,\dots Q_t Q1,…Qt 和元测试集 D mte D_{\text{mte}} Dmte,以及下面的查询对 Q t + 1 , … Q V Q_{t+1},\dots Q_V Qt+1,…QV。前者用于训练的内部更新步骤,对应于攻击阶段的微调步骤。后者对应于使用模拟器作为替代的攻击迭代(图1)。这个划分无缝地连接了训练和攻击阶段。 N 1 … N n \N_1\dots \N_n N1…Nn 的 logits 输出被称为“伪标签”。所有查询序列和伪标签都缓存在硬盘中,以加速训练。
每个task中包含的数据是如下步骤生成得到:
- 随机选择一个已训网络;
- 施加 Bandits 攻击来攻击该网络产生的中间数据,数据包括攻击中产生的 query sequence 和与之对应的该网络的输出 logits 两种;
- query sequence 按照 query pair 生成对应的迭代编号被切分成两部分:meta-train set 和 meta-test set 。
3.2. Simulator Learning
Initialization. 算法 1 和图 2 给出了训练过程。在训练中,我们随机抽样 K K K 个任务形成一个小批量。在学习每个任务的开始。模拟器 M \mathbb M M 使用最后一个小批量学到的权重 θ \theta θ 重新初始化它的权重。在外部更新步骤中,保留这些权重用于计算元梯度。
Meta-train. M \mathbb M M 对元训练集 D mtr D_{\text{mtr}} Dmtr 执行梯度下降,进行多次迭代(内部更新)。这个步骤类似于在知识蒸馏中训练一个学生模型,与攻击的微调步骤相匹配。
Meta-test. 经过多次迭代, M \mathbb M M 的权值更新为 θ ′ \theta ' θ′。然后,基于 θ ′ θ′ θ′ 条件下的第 i i i 个任务的元测试集,计算损失 L i L_i Li。随后,将元梯度 ∇ θ L i \nabla_θL_i ∇θLi 计算为高阶梯度。然后将 K K K task 的 ∇ θ L 1 , … , ∇ θ L K ∇_θL_1,\dots,∇_θL_K ∇θL1,…,∇θLK 平均为 1 k ∑ i = 1 k ∇ θ L i \displaystyle \frac 1 k \sum_{i=1}^k\nabla_{\theta}\mathcal L_i k1i=1∑k∇θLi 用于更新 M \mathbb M M (外部更新),从而使 M \mathbb M M 能够学习一般模拟能力。
Loss Function. 在训练中,我们采用知识蒸馏的损耗模型,使模拟器输出与采样网络 N i \mathbb N_i Ni 相似的预测结果,并在内部和外部步骤中使用。给定 Bandits(老虎机攻击需要在有限差分中进行两个查询来估计梯度。因此,在每次迭代中都会生成一个查询对)生成的第 i i i 个查询对 Q i Q_i Qi 中的两个查询 Q i , 1 Q_{i,1} Qi,1 和 Q i , 2 Q_{i,2} Qi,2,其中 i ∈ { 1 , … , n } i\in \{1,\dots,n\} i∈{1,…,n} 和 n n n 表示元列或元测试集中的查询对个数。模拟器的 logits 输出和 N i \mathbb N_i Ni 分别记为 p ^ \hat p p^ 和 p p p 。 E q . ( 1 ) Eq.(1) Eq.(1) 中定义的 MSE 损失函数使模拟器和伪标签的预测更接近:
L ( p ^ , p ) = 1 n ∑ i = 1 n ( p ^ Q i , 1 − p Q i , 1 ) 2 + 1 n ∑ i = 1 n ( p ^ Q i , 2 − p Q i , 2 ) 2 \mathcal{L}(\hat{\boldsymbol{p}}, \boldsymbol{p})=\frac{1}{\boldsymbol{n}} \sum_{i=1}^{n}\left(\widehat{\boldsymbol{p}}_{Q_{i, 1}}-\boldsymbol{p}_{Q_{i, 1}}\right)^{2}+\frac{1}{\boldsymbol{n}} \sum_{i=1}^{n}\left(\widehat{\boldsymbol{p}}_{Q_{i, 2}}-\boldsymbol{p}_{Q_{i, 2}}\right)^{2} L(p^,p)=n1i=1∑n(p Qi,1−pQi,1)2+n1i=1∑n(p Qi,2−pQi,2)2

Input: 训练数据 D D D,Bandits attack [20] 算法 A \mathcal A A, n n n 个预训练的分类网络 N 1 , … , N n \N_1,\dots,\N_n N1,…,Nn,模拟器网络 M \mathbb M M,定义为 E q . ( 1 ) Eq.(1) Eq.(1) 的损失函数 L ( ⋅ , ⋅ ) \mathcal L(\cdot,\cdot) L(⋅,⋅);
Parameters: 训练迭代次数 N N N,查询序列大小 V V V,元训练集大小 t t t,batch size K K K,内层更新学习率 λ 1 \lambda_1 λ1,外层更新学习率 λ 2 \lambda_2 λ2,内层更新迭代次数 T T T;
Output: 训练好的模拟器 M \mathbb M M;
1:迭代 T T T 次;
2:从训练数据集 D D D 中采样 K K K 个正常图像 x 1 , … , x K x_1,\dots,x_K x1,…,xK;
3:迭代 K K K 次,对应 K K K 个任务;
4:从 n n n 个预训练的分类模型中随机选取一个网络 N i \N_i Ni;
5:将 Bandits attack 算法 A ( x k , N i ) \mathcal A(x_k,\N_i) A(xk,Ni) 产生的网络中间数据组成查询序列 Q 1 … , Q k Q_1\dots,Q_k Q1…,Qk ,其中生成的第 i i i 个查询对 Q i Q_i Qi 中包含两个查询 Q i , 1 Q_{i,1} Qi,1 和 Q i , 2 Q_{i,2} Qi,2;
6:查询序列前 t t t 个作为元训练集;
7:查询序列剩余样本作为元训练集;
8:将元训练集数据通过分类网络 N i \N_i Ni 得到要模仿的网络输出标签作为元训练集标签;
9:将元测试集数据通过分类网络 N i \N_i Ni 得到要模仿的网络输出标签作为元测试集标签;
10:初始化内层任务模型参数 θ ′ \theta' θ′ 初始化为当前的元学习器模型参数(元知识) θ \theta θ;
11:迭代 T T T 次。即将内层模型参数使用梯度下降算法迭代更新 T T T 次;
12:使用梯度下降算法对参数 θ ′ \theta' θ′ 进行更新,朝着任务模型输出 f θ ′ ( D mtr ) f_{\theta'}(\mathcal D_{\text{mtr}}) fθ′(Dmtr) 与要模仿的分类模型的输出标签 P train \mathbf P_{\text{train}} Ptrain 损失函数减少的方向进行更新;
13:结束循环 - 11;
14:数组 L L L 保存此次内层更新的所有损失函数 L \mathcal L L。
15:结束循环 - 3;
16:进行外层更新,使用所有损失函数的均值乘上外层更新学习率对元学习器模型参数(元知识) θ \theta θ 进行更新;
17:结束循环 - 1;
18:返回训练好的元学习器 M \mathbb M M。
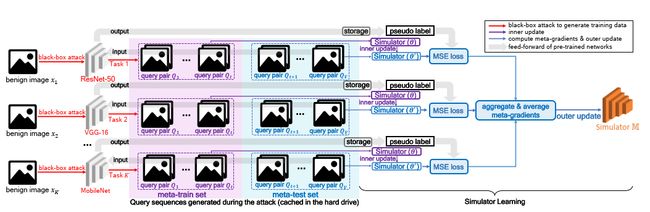
图 2:在一个小批量中训练模拟器的过程。 在这里,攻击期间生成的查询对序列被收集为训练数据,然后重新组织成多个任务。 每个任务包含攻击一个网络产生的数据,并进一步分为元训练集和元测试集。 接下来,模拟器网络 M \mathbb M M 在开始学习每个任务时将其权重重新初始化为 θ \theta θ,之后它随后在元训练集上进行训练。 经过多次迭代(内部更新), M \mathbb M M 收敛,其权重更新为 θ ′ \theta' θ′。 M \mathbb M M 的元梯度是根据 K K K 个任务的元测试集计算出来的,然后累积起来更新 M \mathbb M M(外层更新)。 更新后的 M \mathbb M M 为下一次小批量学习做好准备。 最后,学习到的模拟器可以在攻击阶段使用有限的查询来模拟任何未知的黑盒模型。
3.3. Simulator Attack
算法 2 显示了 ℓ p \ell_p ℓp 范数约束下的模拟器攻击。 前 t t t 次迭代的查询对被馈送到目标模型(预热阶段)。 这些查询和相应的输出被收集到一个双端队列 D \mathbb D D 中。然后,一旦它满了, D \mathbb D D 就丢弃最旧的项目,这有利于在使用 D \mathbb D D 微调 M \mathbb M M 时专注于新查询。预热后,后续查询每 m m m 次迭代将被输入到目标模型中。其余的由微调的 M \mathbb M M 完成。 为了与训练保持一致,梯度估计步骤遵循 Bandits 的步骤。 等式所示的攻击目标损失函数。 E q . ( 2 ) Eq.(2) Eq.(2) 在攻击期间最大化:
L ( y ^ , t ) = { max j ≠ t y ^ j − y ^ t , if untargeted attack; y ^ t − max j ≠ t y ^ j , if targeted attack; \mathcal{L}(\hat{y}, t)=\left\{\begin{array}{ll}\max _{j \neq t} \hat{y}_{j}-\hat{y}_{t}, & \text { if untargeted attack; } \\\hat{y}_{t}-\max _{j \neq t} \hat{y}_{j}, & \text { if targeted attack; }\end{array}\right. L(y^,t)={maxj=ty^j−y^t,y^t−maxj=ty^j, if untargeted attack; if targeted attack;
其中 y ^ \hat y y^ 表示模拟器或目标模型的 logits 输出, t t t 是目标攻击中的目标类或非目标攻击中的真实类, j j j 索引其他类。

模拟器攻击的算法流程主要还是沿袭了 Bandits 攻击的算法逻辑。( Bandits 攻击算法的具体算法逻辑详见 繁凡的对抗攻击论文精读(三)ICLR2019 利用先验知识进行高效黑盒对抗攻击的 bandits 算法 Prior Convictions: Black-Box Adversarial Attacks with Bandits and Priors )
其中第 8 行至第 17 行,在刚开始攻击的 t t t 个迭代内(warm-up 阶段),生成的对抗性样本直接被输入到目标模型中,并且使用一个双端队列 D \mathbb D D 保存这些输入和输出。在 warm-up 之后的迭代中,每隔 m m m 次迭代使用一次目标模型,其余迭代一律输入使用模拟器来输出。因此目标模型和模拟器的使用是轮流交替进行的,这种方法一方面保证了大部分查询压力被转移到模拟器中,另一方面保证了模拟器每隔 m m m 次迭代就得到机会 fine-tune 一次,这保证了后期的迭代中模拟器能够跟得上不断演化的查询的节奏,及时与目标模型保持一致。
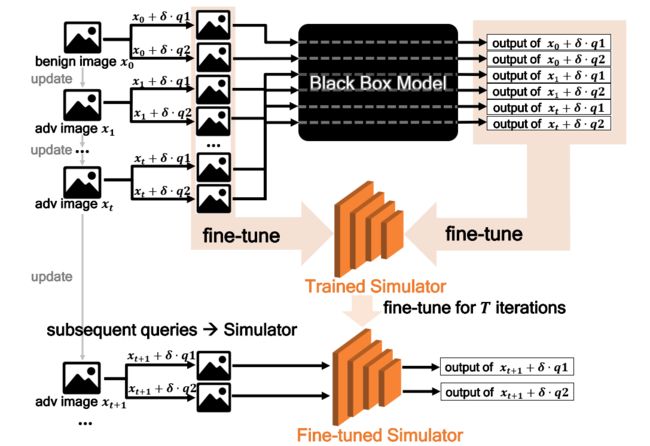
图 1:模拟器攻击的过程,其中 q 1 q_1 q1 和 q 2 q_2 q2 是攻击中生成查询对的相应扰动(算法 2)。 将前 t t t 次迭代的查询输入目标模型以估计辐射。 收集这些查询和相应的输出以微调模拟器,该模拟器在不使用目标模型的情况下进行训练。 微调的模拟器可以准确模拟未知的目标模型,从而转移查询并提高整体查询效率。
3.4. Discussion
在攻击期间,模拟器必须在提供真实攻击的查询时准确地模拟输出。 因此,模拟器以知识蒸馏的方式在真实攻击的中间数据上进行训练。 现有的元学习方法都没有以这种方式学习模拟器,因为它们都专注于少样本分类或强化学习问题。 此外,算法 2 交替向 M \mathbb M M 和目标模型提供查询以学习最新的查询。 当面临困难的攻击时(例如,图 3b 中的目标攻击的结果),定期微调对于实现高成功率至关重要。
4. Experiment
4.1. Experiment Setting
Dataset and Target Models. 我们使用 CIFAR-10 [23]、CIFAR-100 [23] 和 TinylmageNet [38] 数据集进行实验。 根据之前的研究 [457,从验证集中随机选择 1.000 张测试图像进行评估。 在 CIFAR-10 和 CIFAR 100 数据集中,我们遵循 Yan 等人的方法。 [45] 选择目标模型:(1)使用 AutoAugment 训练的 272 层 PyramidNet+Shakedrop 网络(PyramidNet-272)[15, 44];(2)通过神经架构搜索获得的模型,称为 GDAS [111 ; (3) 一个WRN-28 [46],有28层和10倍的宽度扩展; (4) 一个 40 层的 WRN-40。 在 TinyImageNet 数据集中,我们选择 ResNeXt-101(32x4d) [43]、ResNeXt-101 (64x4d) 和 DenseNet-12[171,增长率为 32。
Method Setting. 在训练中,我们在每个任务中生成查询序列数据 Q 1 , . . , Q 100 Q_1,..,Q_{100} Q1,..,Q100。 元训练集 D mtr D_{\text{mtr}} Dmtr 包含 Q 1 , . . . , Q 50 Q_1,..., Q_{50} Q1,...,Q50,元测试集 D mte D_{\text{mte}} Dmte 包含 Q 51 , . . . Q 100 Q_{51},... Q_{100} Q51,...Q100。 我们选择 ResNet-34 [16] 作为模拟器的主干,我们训练了三个 epoch 超过 30 , 000 30,000 30,000 个任务。 在这里, 30 30 30 个采样任务构成了一个 mini-batch。 使用 NVIDIA Tesla V100 GPU 训练每个模拟器持续 72 72 72 小时。 微调迭代次数在第一次微调中设置为 10 10 10 次,然后为后续的从 3 3 3 到 5 5 5 减少到一个随机数。 在针对性攻击中,我们将所有攻击的目标类别设置为 y adv = ( y + 1 ) m o d C y_{\text{adv}} = (y+1) \bmod C yadv=(y+1)modC,其中 y adv y_{\text{adv}} yadv 是目标类别, y y y 是真实类别, C C C 是类别编号。 根据之前的研究 [8, 45],我们使用攻击成功率以及查询的平均值和中值作为评估指标。 表 1 列出了默认参数。
Pre-trained Networks. 为了评估模拟未知目标模型的能力。 我们确保算法 1 中 N 1 , … , N n \N_1,\dots ,\N_n N1,…,Nn 的选择与目标模型不同。 CIFAR-10 和 CIFAR-100 数据集中共选择了 14 14 14 个网络,TinymageNet 数据集选择了 16 16 16 个网络。 详细信息可以在补充材料中找到。 在涉及防御模型攻击的实验中,我们通过删除 ResNet 网络的数据来重新训练模拟器。 这是因为防御模型采用 ResNet-50 的主干。
Compared Methods. 比较的方法包括NES [19]、Bandits [20]、Meta Attack [12]、RGF [32] 和P-RGF [8]。 Bandits 被选为基线。为确保公平比较,Meta Attack 的训练数据(即图像和梯度)是直接使用本研究的预训练分类网络生成的。我们将 TensorFlow 官方实现中的 NES、RGF 和 P-RGF 代码翻译成 PyTorch 版本进行实验。 P-RGF 通过使用代理模型提高了 RGF 查询效率。它在 CIFAR-10 和 CIFAR-100 数据集中采用 ResNet110 [16],在 TinyImageNet 数据集中采用 ResNet-101 [16]。我们在针对性攻击实验中排除了 RGF 和 P-RGF 的实验,因为它们的官方工具只支持非针对性攻击。在非针对性攻击和针对性攻击中,所有方法都限制为最多 10.000 次查询。我们为所有攻击设置相同的 ϵ \epsilon ϵ 值,在 ℓ 2 \ell_2 ℓ2 范数攻击和 ℓ ∞ \ell_{\infin} ℓ∞ 范数攻击中分别为 4.6 4.6 4.6 和 8 255 \dfrac 8{255} 2558。补充材料中提供了所有比较方法的详细配置。
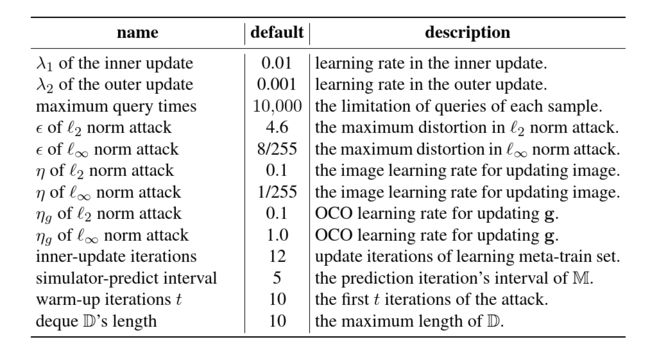
表 1:Simulator Attack 的默认参数设置。
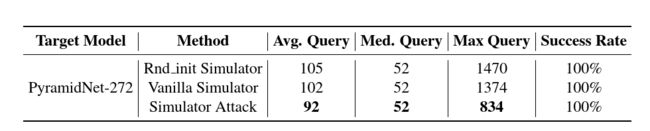
表 2:通过对 CIFAR-10 数据集执行 ℓ 2 \ell_2 ℓ2 范数攻击来比较不同模拟器。 Rnd init Simulator 使用未经训练的 ResNet-34 作为模拟器; Vanilla Simulator 使用 ResNet-34,在不使用元学习作为模拟器的情况下进行训练。
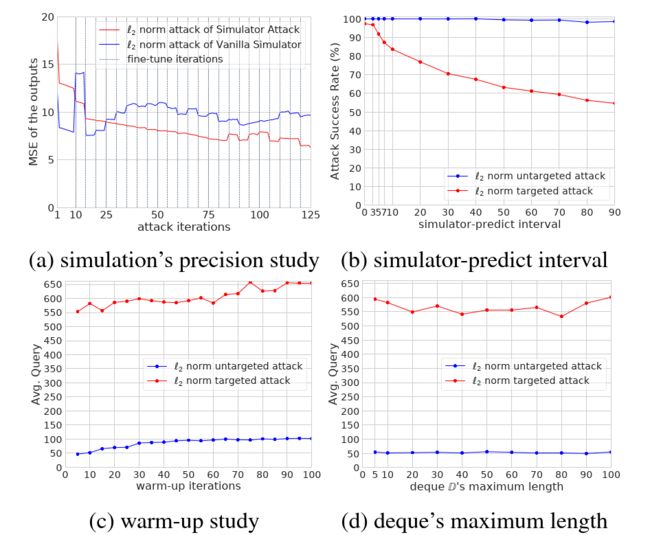
图 3:我们通过攻击 CIFAR-10 数据集中的 WRN-28 模型,对模拟的精确度、模拟器预测间隔、预热迭代和双端队列 D \mathbb D D 的最大长度进行消融研究。 结果表明:(1)元训练有利于实现准确的模拟(图 3a),(2)困难的攻击(例如,有针对性的攻击)需要一个小的模拟器预测间隔(图 3b), (3)更多的预热迭代会导致更高的平均查询(图 3c)。
4.2. Ablation Study
进行消融研究是为了验证元训练的好处并确定元训练关键参数的效果。
Meta Training. 我们通过在所提出的算法中配备不同的模拟器来验证元训练的好处。 模拟器 M \mathbb M M 被替换为两个网络进行比较,即 Rnd_init 模拟器:一个没有训练的随机初始化的 ResNet-34 网络,和 Vanilla 模拟器:一个基于本研究数据训练但没有使用元学习的 ResNet-34 网络。 表 2 显示了实验结果,这表明 Simulator Attack 能够实现最少的查询次数,从而证实了元训练的好处。 为了详细检查模拟能力,我们计算了模拟器输出与不同攻击迭代的目标模型之间的平均 MSE(图 3a)。 结果表明,模拟器攻击在大多数迭代中实现了最低的 MSE。 从而表现出令人满意的模拟能力。
Simulator-Predict Interval m m m. 该参数是使用模拟器 M \mathbb M M 进行预测的迭代间隔,较大的 m m m 导致微调 M \mathbb M M 的机会较少。 在图 3b) 中,导致成功率低。
Warm-up. 如图 3c 所示,更多的预热迭代会导致更高的平均查询,因为更多的查询在预热阶段被输入到目标模型中。
4.3. Comparisons with State-of-the-Art Methods
Results of Attacks on Normal Models. 在本研究中,正常模型是没有防御机制的分类模型。 我们对 4.1 节中描述的目标模型进行了实验。 表 3 和表 4 分别显示了 CIFAR-10 和 CIFAR-100 数据集的结果,而表 6 和表 7 显示了 TinylmageNet 数据集的结果。 结果表明:(1)与基线 Bandits 相比,Simulator Attack 最多可以将查询的平均值和中值减少 2 倍,以及(2)Simulator Attack 可以获得更少的查询和更高的攻击成功率 率高于元攻击 [12](例如,表 6 和 7 中元攻击的低成功率)。 Meta Attack 的性能不佳可归因于其高成本的梯度估计(特别是使用 ZOO [61)。
Experimental Figures. 表 3、4、6、7 显示了将最大查询数设置为 10,000 后的结果。 为了进一步检查不同最大查询的攻击成功率,我们通过限制每个对抗样本的不同最大查询来执行 ℓ ∞ \ell_{\infin} ℓ∞ 范数攻击。 所提出的方法在攻击成功率方面的优越性如图 4 所示。同时,图 5 展示了达到不同期望成功率的平均查询次数。 图 5 显示,所提出的方法比其他攻击更具查询效率,并且差距被放大以获得更高的成功率。
Results of Attacks on the Defensive Models. 表5显示了攻击防御模型后获得的实验结果。 ComDefend (CD) [211 和 Feature Distillation (FD) [26] 配备了降噪器,可在输入目标模型之前将输入图像转换为其干净版本。原型一致性损失 (PCL) [31] 引入了一种新的损失函数,以最大限度地分离每个类的中间特征。在这里,PCL 防御模型是在我们的实验中不使用对抗性训练的情况下获得的。 Adv Train [29] 是一种基于对抗训练的强大防御方法。根据表 5 所示结果,我们得出以下结论:
(1) 在所有方法中,Simulator Attack 在破坏 CD 方面表现出最好的性能,特别是显着优于基线方法 Bandits。
(2) Meta Attack 表现出较差的性能CD和FD基于其不理想的成功率。相比之下,模拟器攻击可以以较高的成功率打破这种类型的防御模型。
(3)在Adv Train 被攻击的实验中,模拟器攻击消耗更少的查询来达到与 Bandits 相当的成功率。
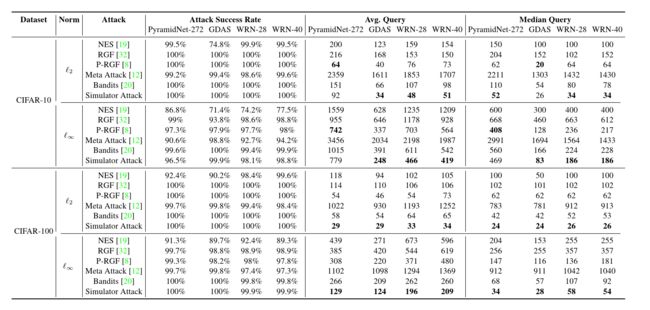
表 3:CIFAR-10 和 CIFAR-100 数据集中无针对性攻击的实验结果。
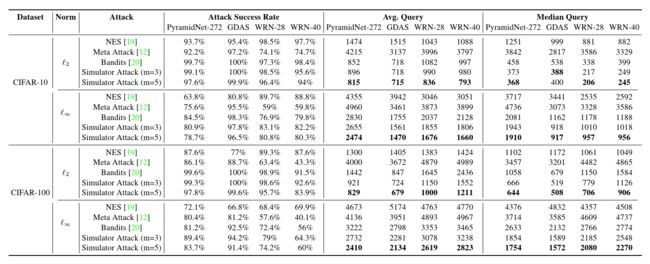
表 4:CIFAR-10 和 CIFAR-100 数据集中针对性攻击的实验结果,其中 m m m 是模拟器预测区间。
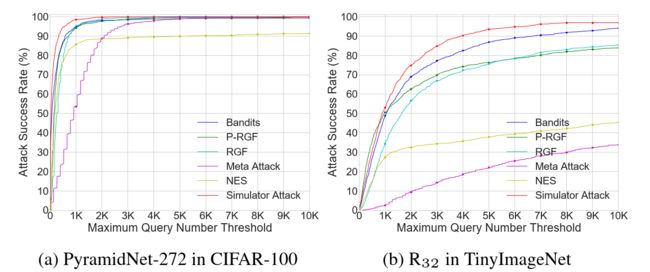
图 4: ℓ ∞ \ell_{\infin} ℓ∞ 范数下无目标攻击中不同有限最大查询的攻击成功率比较,其中 R 32 R_{32} R32 表示 ResNext-101 (32x4d)。
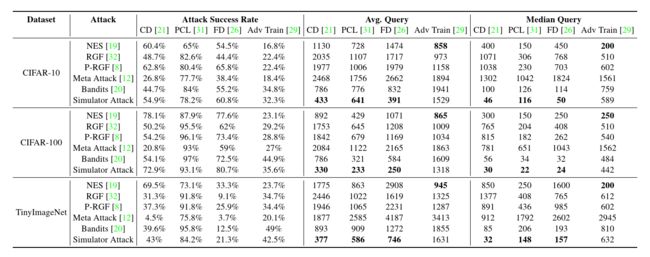
表 5:对防御模型执行 ℓ ∞ \ell_{\infin} ℓ∞ 范数攻击后的实验结果,其中 CD 代表 ComDefend [21],FD 是特征蒸馏 [26],PCL 是原型一致性损失 [31]。
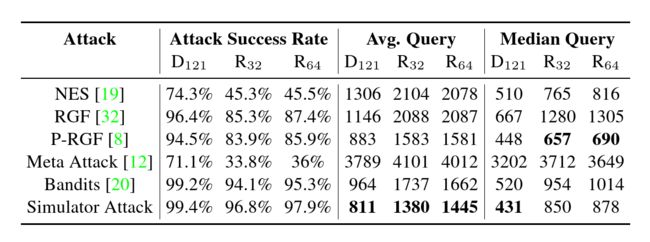
表 6:TinymageNet 数据集中 ℓ ∞ \ell_{\infin} ℓ∞ 范数下无目标攻击的实验结果。 D121:DenseNet-121、 R 32 R_{32} R32:ResNeXt-101 (32x4d)、 R 64 R_{64} R64:ResNeXt-101 (64x4d)。
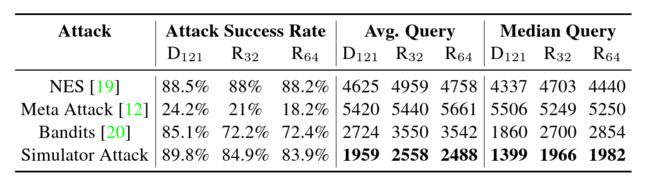
表 7:TinymageNet 数据集中 ℓ 2 \ell_2 ℓ2 范数下针对性攻击的实验结果。 D121:DenseNet-121, R 32 R_{32} R32:ResNeXt-101(32x4d), R 64 R_{64} R64:ResNeXt-101(64x4d)。

图 5:无目标 ℓ ∞ \ell_{\infin} ℓ∞ 范数攻击下不同成功率下的平均查询比较。 补充材料中提供了更多结果。
0x02 全文翻译
1. Introduction
深度神经网络(DNNs)容易受到对敌攻击[3,13,391],它会在良性图像中加入人的不易察觉的扰动,从而导致目标模型的误分类。对抗性攻击的研究是实现鲁棒dnn[29]的关键。对抗性攻击可以分为两种类型,即白盒攻击和黑盒攻击。在白盒攻击设置中,目标模型完全暴露给对手。因此,可以通过使用渐变轻松地制作扰动[4]。131. 在黑箱攻击设置中,对手只有目标模型的部分信息,而对手的例子是在没有任何梯度信息的情况下制作的。因此,黑箱攻击(即基于查询和传输的攻击)在现实场景中更实用。
基于查询的攻击主要是通过查询估计梯度[6,41,19,20]。这些攻击被认为是非常有效的,因为它们的攻击成功率令人满意。然而,尽管它们在实际应用中有一定的优点,但在高精度估计近似梯度时,不可避免地会产生较高的查询复杂度,从而导致程序开销较大。此外,查询通常没有得到充分利用,也就是说,从目标模型返回的隐含但深刻的消息被忽略了,因为它们在估计梯度之后被抛弃了。因此,如何充分利用目标模型的反馈信息来提高攻击的查询效率是一个值得深入研究的问题。
基于传输的攻击通过对源模型使用白盒攻击方法来欺骗目标模型来生成对抗示例[25,33,10,18]。基于传输的攻击有两个缺点:(1)它们的成功率不高,(2)它们在针对目标的攻击中较弱。为了提高可移植性,模型窃取攻击训练一个局部替代模型来模拟使用合成数据集的黑箱模型,其中标签由目标模型通过查询[40,36,34]给出。这样,将替代模型与目标模型之间的差异最小化,从而提高了攻击成功率。然而,这样的训练需要查询目标模型,因此,查询的复杂性增加了,可以通过部署防御机制(如[35,241])很容易地防御这种攻击。此外,不可避免的重新培训以替代新的目标模型是一个昂贵的过程。因此,如何在不满足目标模型要求的情况下培养替代模型是一个值得进一步探索的问题。
为了消除训练中对目标模型的要求,我们提出了一种新的基于元学习的框架,在多个不同的网络上学习广义替代模型(即模拟器),从而利用它们的特点实现快速适应。经过训练和微调后,模拟器可以模拟训练中看不到的任何目标模型的输出,使其最终能够替代目标模型(图1)。具体来说,真实黑箱攻击的中间查询被移动到训练阶段,从而允许模拟器学习如何区分查询之间的细微差别。所有的训练数据被重新组织成由多个任务组成的格式。每个任务都是一个小数据子集,由一个网络的查询序列组成。在这个系统中,大量的任务让模拟器经历各种网络的攻击。
我们提出了三个组件来优化泛化。首先,查询序列水平分区策略是采用把每个任务分成meta-train和meta-test集(图2)迭代匹配的微调和仿真的攻击,分别(图1)。第二,均方误差(MSE)的knowledge-distillation损失进行元学习的内外循环。最后,对一批任务的元梯度进行计算和汇总,以更新模拟器,提高泛化能力。这些策略很好地解决了培训过程中目标模型需求的问题。在攻击(命名为“Simulator attack”)中,利用未知目标模型的有限反馈微调训练后的模拟器,精确模拟其输出,从而转移其查询应力(图1)。因此,充分利用目标模型的反馈来提高查询效率。训练中目标模型的消除带来了新的安全威胁,即对目标模型信息最少的对手也可以伪造该模型进行成功攻击。
在这项研究中,我们使用CIFAR-10[23]评估所提出的方法。CIFAR-100[23]和TinylmageNet[38]数据集,并将其与自然进化策略(NES)[19]、bt[20]、Meta攻击[12]、随机无梯度(RGF)[32]和先验引导RGF (P-RGF)[8]进行比较。实验结果表明,与基线方法相比,模拟器攻击可以显著降低查询复杂度。
本文的主要贡献如下:
(1)通过训练一个广义替代模型“模拟器”,提出了一种新的黑盒攻击方法。训练使用知识蒸馏损失来实现模拟器和采样网络之间的元学习。训练结束后,模拟器只需要几个查询就可以准确模拟训练中看不到的任何目标模型。
(2)通过消除训练中的目标模型,我们识别出一种新型的安全威胁。
(3)通过使用CIFAR-10、CIFAR-100和TinylmageNet数据集进行大量实验,我们证明了所提出的方法获得了与那些最先进的攻击相似的成功率,但具有前所未有的低查询数量。
图 1:模拟器攻击的过程,其中 q 1 q_1 q1 和 q 2 q_2 q2 是攻击中生成查询对的相应扰动(算法 2)。 将前 t t t 次迭代的查询输入目标模型以估计辐射。 收集这些查询和相应的输出以微调模拟器,该模拟器在不使用目标模型的情况下进行训练。 微调的模拟器可以准确模拟未知的目标模型,从而转移查询并提高整体查询效率。
2. Related Works
Query-based Attacks. 黑箱攻击可分为基于查询的攻击和基于传输的攻击。基于查询的攻击可以进一步分为基于分数的攻击和基于决策的攻击,基于对手可以使用多少目标模型返回的信息。在参考的攻击。对手使用目标模型的输出分数来生成对抗的示例。大多数基于分数的攻击通过零阶优化来估计近似梯度[6,2]。然后,对手可以利用估计的梯度对对手实例进行优化。虽然这种类型的方法可以提供成功的攻击,但它需要大量的查询,因为每个像素需要两个查询。文献中介绍了几种改进的方法,利用数据的主成分[2]、降维潜在空间[41]、先验梯度信息[20,27]、随机搜索[14,1]和主动学习[37]来降低查询复杂度。基于决策的攻击[5,7]只使用目标模型的输出标签。在本研究中,我们主要关注基于分数的攻击。
Transfer-based Attacks. 基于传输的攻击在源模型上生成对抗示例,然后将它们转移到目标模型[25,10,18]。然而,由于源模型和目标模型的差异较大,这类攻击的成功率并不高。许多努力,包括使用模型窃取攻击,已作出提高攻击成功率。模型窃取攻击的初衷是复制公共服务的功能[42,40,30,34]。Papernot等人扩大了模型窃取攻击的使用范围。他们使用目标模型标记的合成数据集训练替代模型。然后,这个替代品被用来制作对抗性的例子。在本研究中,我们着重于在不使用目标模型的情况下训练一个替代模型。
Meta-learning. 元学习在 few-shot 分类中很有用。它培养了一种只需要少量样本就能快速适应新环境的超学习者。Ma等人[28]提出MetaAdvDet以高精度检测新型对抗性攻击,以便在对抗性攻击领域利用元学习。Meta Attack[12]训练一个自动编码器来预测目标模型的梯度,以降低查询的复杂性。然而,它的自动编码器只训练自然图像和梯度对,而不是来自实际攻击的数据。因此,它的预测精度在攻击中并不令人满意。大梯度映射的自动编码器的轻量级也给预测带来了困难。因此。Meta攻击只提取前 128 128 128 个值的梯度来更新示例,导致性能较差。相比之下,本研究提出的模拟器采用知识蒸馏损失训练进行对数预测;因此,性能不受图像分辨率的影响。训练数据为黑盒攻击的查询序列,分为元序列集和元测试集。前者对应微调迭代,后者对应攻击中的模拟迭代。这些策略将训练和攻击无缝地连接起来,以最大限度地提高性能。
3. Method
3.1. Task Generation
在攻击期间,经过训练的模拟器必须准确地模拟任何未知目标模型的输出,而提供的查询彼此之间仅略有不同。为此,模拟器应该从真实的攻击中学习。即各种网络攻击产生的中间数据(查询序列和输出)。为此,有几个分类网络N1…采集神经网络构建训练任务,创建巨大的仿真环境,提高通用仿真能力(图2)。每个任务包含 V V V 个查询对 Q 1 , … , Q V ( Q i ∈ R D , i ∈ { 1 , … , V } ) Q_1,\dots,Q_V(Q_i\in\R^D,i\in\{1, \dots,V\}) Q1,…,QV(Qi∈RD,i∈{1,…,V}) ,其中 D D D 为图像维数。这些对是通过使用土匪攻击随机选择的网络而产生的。土匪使用的数据源可以是从互联网上下载的任何图像。在本研究中,我们使用标准数据集的训练集与测试图像的数据分布不同。每个任务被划分为两个子集,即元训练集 D mtr D_{\text{mtr}} Dmtr,它由前 t t t 个查询对 Q 1 , … Q t Q_1,\dots Q_t Q1,…Qt 和元测试集 D mte D_{\text{mte}} Dmte,以及下面的查询对 Q t + 1 , … Q V Q_{t+1},\dots Q_V Qt+1,…QV。前者用于训练的内部更新步骤,对应于攻击阶段的微调步骤。后者对应于使用模拟器作为替代的攻击迭代(图1)。这个划分无缝地连接了训练和攻击阶段。 N 1 … N n \N_1\dots \N_n N1…Nn 的 logits 输出被称为“伪标签”。所有查询序列和伪标签都缓存在硬盘中,以加速训练。
3.2. Simulator Learning
Initialization. 算法1和图2给出了训练过程。在训练中,我们随机抽样 K K K 个任务形成一个小批量。在学习每个任务的开始。模拟器 M \mathbb M M 使用最后一个小批量学到的权重 θ \theta θ 重新初始化它的权重。在外部更新步骤中,保留这些权重用于计算元梯度。
Meta-train. M \mathbb M M 对元训练集 D mtr D_{\text{mtr}} Dmtr 执行梯度下降,进行多次迭代(内部更新)。这个步骤类似于在知识蒸馏中训练一个学生模型,与攻击的微调步骤相匹配。
Meta-test. 经过多次迭代, M \mathbb M M 的权值更新为 θ ′ \theta ' θ′。然后,基于 θ ′ θ′ θ′ 条件下的第 i i i 个任务的元测试集,计算损失 L i L_i Li。随后,将元梯度 ∇ θ L i \nabla_θL_i ∇θLi 计算为高阶梯度。然后将 K K K task 的 ∇ θ L 1 , … , ∇ θ L K ∇_θL_1,\dots,∇_θL_K ∇θL1,…,∇θLK 平均为 1 k ∑ i = 1 k ∇ θ L i \displaystyle \frac 1 k \sum_{i=1}^k\nabla_{\theta}\mathcal L_i k1i=1∑k∇θLi 用于更新 M \mathbb M M (外部更新),从而使 M \mathbb M M 能够学习一般模拟能力。
Loss Function. 在训练中,我们采用知识蒸馏的损耗模型,使模拟器输出与采样网络 N i \mathbb N_i Ni 相似的预测结果,并在内部和外部步骤中使用。给定 Bandits(老虎机攻击需要在有限差分中进行两个查询来估计梯度。因此,在每次迭代中都会生成一个查询对)生成的第 i i i 个查询对 Q i Q_i Qi 中的两个查询 Q i , 1 Q_{i,1} Qi,1 和 Q i , 2 Q_{i,2} Qi,2,其中 i ∈ { 1 , … , n } i\in \{1,\dots,n\} i∈{1,…,n} 和 n n n 表示元列或元测试集中的查询对个数。模拟器的 logits 输出和 N i \mathbb N_i Ni 分别记为 p ^ \hat p p^ 和 p p p 。 E q . ( 1 ) Eq.(1) Eq.(1) 中定义的 MSE 损失函数使模拟器和伪标签的预测更接近:
L ( p ^ , p ) = 1 n ∑ i = 1 n ( p ^ Q i , 1 − p Q i , 1 ) 2 + 1 n ∑ i = 1 n ( p ^ Q i , 2 − p Q i , 2 ) 2 \mathcal{L}(\hat{\boldsymbol{p}}, \boldsymbol{p})=\frac{1}{\boldsymbol{n}} \sum_{i=1}^{n}\left(\widehat{\boldsymbol{p}}_{Q_{i, 1}}-\boldsymbol{p}_{Q_{i, 1}}\right)^{2}+\frac{1}{\boldsymbol{n}} \sum_{i=1}^{n}\left(\widehat{\boldsymbol{p}}_{Q_{i, 2}}-\boldsymbol{p}_{Q_{i, 2}}\right)^{2} L(p^,p)=n1i=1∑n(p Qi,1−pQi,1)2+n1i=1∑n(p Qi,2−pQi,2)2
图 2:在一个小批量中训练模拟器的过程。在这里,攻击期间生成的查询对序列被收集为训练数据,然后重新组织成多个任务。 每个任务包含攻击一个网络产生的数据,并进一步分为元训练集和元测试集。 接下来,模拟器网络 M \mathbb M M 在开始学习每个任务时将其权重重新初始化为 θ \theta θ,之后它随后在元训练集上进行训练。 经过多次迭代(内部更新), M \mathbb M M 收敛,其权重更新为 θ ′ \theta' θ′。 M \mathbb M M 的元梯度是根据 K K K 个任务的元测试集计算出来的,然后累积起来更新 M \mathbb M M(外层更新)。 更新后的 M \mathbb M M 为下一次小批量学习做好准备。 最后,学习到的模拟器可以在攻击阶段使用有限的查询来模拟任何未知的黑盒模型。
3.3. Simulator Attack
算法 2 显示了 ℓ p \ell_p ℓp 范数约束下的模拟器攻击。 前 t t t 次迭代的查询对被馈送到目标模型(预热阶段)。 这些查询和相应的输出被收集到一个双端队列 D \mathbb D D 中。然后,一旦它满了, D \mathbb D D 就丢弃最旧的项目,这有利于在使用 D \mathbb D D 微调 M \mathbb M M 时专注于新查询。预热后,后续查询每 m m m 次迭代将被输入到目标模型中。其余的由微调的 M \mathbb M M 完成。 为了与训练保持一致,梯度估计步骤遵循 Bandits 的步骤。 等式所示的攻击目标损失函数。 E q . ( 2 ) Eq.(2) Eq.(2) 在攻击期间最大化:
L ( y ^ , t ) = { max j ≠ t y ^ j − y ^ t , if untargeted attack; y ^ t − max j ≠ t y ^ j , if targeted attack; \mathcal{L}(\hat{y}, t)=\left\{\begin{array}{ll}\max _{j \neq t} \hat{y}_{j}-\hat{y}_{t}, & \text { if untargeted attack; } \\\hat{y}_{t}-\max _{j \neq t} \hat{y}_{j}, & \text { if targeted attack; }\end{array}\right. L(y^,t)={maxj=ty^j−y^t,y^t−maxj=ty^j, if untargeted attack; if targeted attack;
其中 y ^ \hat y y^ 表示模拟器或目标模型的 logits 输出, t t t 是目标攻击中的目标类或非目标攻击中的真实类, j j j 索引其他类。
3.4. Discussion
在攻击期间,模拟器必须在提供真实攻击的查询时准确地模拟输出。 因此,模拟器以知识蒸馏的方式在真实攻击的中间数据上进行训练。 现有的元学习方法都没有以这种方式学习模拟器,因为它们都专注于少样本分类或强化学习问题。 此外,算法 2 交替向 M \mathbb M M 和目标模型提供查询以学习最新的查询。 当面临困难的攻击时(例如,图 3b 中的目标攻击的结果),定期微调对于实现高成功率至关重要。
4. Experiment
4.1. Experiment Setting
Dataset and Target Models. 我们使用 CIFAR-10 [23]、CIFAR-100 [23] 和 TinylmageNet [38] 数据集进行实验。 根据之前的研究 [457,从验证集中随机选择 1.000 张测试图像进行评估。 在 CIFAR-10 和 CIFAR 100 数据集中,我们遵循 Yan 等人的方法。 [45] 选择目标模型:(1)使用 AutoAugment 训练的 272 层 PyramidNet+Shakedrop 网络(PyramidNet-272)[15, 44];(2)通过神经架构搜索获得的模型,称为 GDAS [111 ; (3) 一个WRN-28 [46],有28层和10倍的宽度扩展; (4) 一个 40 层的 WRN-40。 在 TinyImageNet 数据集中,我们选择 ResNeXt-101(32x4d) [43]、ResNeXt-101 (64x4d) 和 DenseNet-12[171,增长率为 32。
Method Setting. 在训练中,我们在每个任务中生成查询序列数据 Q 1 , . . , Q 100 Q_1,..,Q_{100} Q1,..,Q100。 元训练集 D mtr D_{\text{mtr}} Dmtr 包含 Q 1 , . . . , Q 50 Q_1,..., Q_{50} Q1,...,Q50,元测试集 D mte D_{\text{mte}} Dmte 包含 Q 51 , . . . Q 100 Q_{51},... Q_{100} Q51,...Q100。 我们选择 ResNet-34 [16] 作为模拟器的主干,我们训练了三个 epoch 超过 30 , 000 30,000 30,000 个任务。 在这里, 30 30 30 个采样任务构成了一个 mini-batch。 使用 NVIDIA Tesla V100 GPU 训练每个模拟器持续 72 72 72 小时。 微调迭代次数在第一次微调中设置为 10 10 10 次,然后为后续的从 3 3 3 到 5 5 5 减少到一个随机数。 在针对性攻击中,我们将所有攻击的目标类别设置为 y adv = ( y + 1 ) m o d C y_{\text{adv}} = (y+1) \bmod C yadv=(y+1)modC,其中 y adv y_{\text{adv}} yadv 是目标类别, y y y 是真实类别, C C C 是类别编号。 根据之前的研究 [8, 45],我们使用攻击成功率以及查询的平均值和中值作为评估指标。 表 1 列出了默认参数。
Pre-trained Networks. 为了评估模拟未知目标模型的能力。 我们确保算法 1 中 N 1 , … , N n \N_1,\dots ,\N_n N1,…,Nn 的选择与目标模型不同。 CIFAR-10 和 CIFAR-100 数据集中共选择了 14 14 14 个网络,TinymageNet 数据集选择了 16 16 16 个网络。 详细信息可以在补充材料中找到。 在涉及防御模型攻击的实验中,我们通过删除 ResNet 网络的数据来重新训练模拟器。 这是因为防御模型采用 ResNet-50 的主干。
Compared Methods. 比较的方法包括NES [19]、Bandits [20]、Meta Attack [12]、RGF [32] 和P-RGF [8]。 Bandits 被选为基线。为确保公平比较,Meta Attack 的训练数据(即图像和梯度)是直接使用本研究的预训练分类网络生成的。我们将 TensorFlow 官方实现中的 NES、RGF 和 P-RGF 代码翻译成 PyTorch 版本进行实验。 P-RGF 通过使用代理模型提高了 RGF 查询效率。它在 CIFAR-10 和 CIFAR-100 数据集中采用 ResNet110 [16],在 TinyImageNet 数据集中采用 ResNet-101 [16]。我们在针对性攻击实验中排除了 RGF 和 P-RGF 的实验,因为它们的官方工具只支持非针对性攻击。在非针对性攻击和针对性攻击中,所有方法都限制为最多 10.000 次查询。我们为所有攻击设置相同的 ϵ \epsilon ϵ 值,在 ℓ 2 \ell_2 ℓ2 范数攻击和 ℓ ∞ \ell_{\infin} ℓ∞ 范数攻击中分别为 4.6 4.6 4.6 和 8 255 \dfrac 8{255} 2558。补充材料中提供了所有比较方法的详细配置。
表 1:Simulator Attack 的默认参数设置。
表 2:通过对 CIFAR-10 数据集执行 ℓ 2 \ell_2 ℓ2 范数攻击来比较不同模拟器。 Rnd init Simulator 使用未经训练的 ResNet-34 作为模拟器; Vanilla Simulator 使用 ResNet-34,在不使用元学习作为模拟器的情况下进行训练。
图 3:我们通过攻击 CIFAR-10 数据集中的 WRN-28 模型,对模拟的精确度、模拟器预测间隔、预热迭代和双端队列 D \mathbb D D 的最大长度进行消融研究。 结果表明:(1)元训练有利于实现准确的模拟(图 3a),(2)困难的攻击(例如,有针对性的攻击)需要一个小的模拟器预测间隔(图 3b), (3)更多的预热迭代会导致更高的平均查询(图 3c)。
4.2. Ablation Study
进行消融研究是为了验证元训练的好处并确定元训练关键参数的效果。
Meta Training. 我们通过在所提出的算法中配备不同的模拟器来验证元训练的好处。 模拟器 M \mathbb M M 被替换为两个网络进行比较,即 Rnd_init 模拟器:一个没有训练的随机初始化的 ResNet-34 网络,和 Vanilla 模拟器:一个基于本研究数据训练但没有使用元学习的 ResNet-34 网络。 表 2 显示了实验结果,这表明 Simulator Attack 能够实现最少的查询次数,从而证实了元训练的好处。 为了详细检查模拟能力,我们计算了模拟器输出与不同攻击迭代的目标模型之间的平均 MSE(图 3a)。 结果表明,模拟器攻击在大多数迭代中实现了最低的 MSE。 从而表现出令人满意的模拟能力。
Simulator-Predict Interval m m m. 该参数是使用模拟器 M \mathbb M M 进行预测的迭代间隔,较大的 m m m 导致微调 M \mathbb M M 的机会较少。 在图 3b) 中,导致成功率低。
Warm-up. 如图 3c 所示,更多的预热迭代会导致更高的平均查询,因为更多的查询在预热阶段被输入到目标模型中。
4.3. Comparisons with State-of-the-Art Methods
Results of Attacks on Normal Models. 在本研究中,正常模型是没有防御机制的分类模型。 我们对 4.1 节中描述的目标模型进行了实验。 表 3 和表 4 分别显示了 CIFAR-10 和 CIFAR-100 数据集的结果,而表 6 和表 7 显示了 TinylmageNet 数据集的结果。 结果表明:(1)与基线 Bandits 相比,Simulator Attack 最多可以将查询的平均值和中值减少 2 倍,以及(2)Simulator Attack 可以获得更少的查询和更高的攻击成功率 率高于元攻击 [12](例如,表 6 和 7 中元攻击的低成功率)。 Meta Attack 的性能不佳可归因于其高成本的梯度估计(特别是使用 ZOO [61)。
Experimental Figures. 表 3、4、6、7 显示了将最大查询数设置为 10,000 后的结果。 为了进一步检查不同最大查询的攻击成功率,我们通过限制每个对抗样本的不同最大查询来执行 ℓ ∞ \ell_{\infin} ℓ∞ 范数攻击。 所提出的方法在攻击成功率方面的优越性如图 4 所示。同时,图 5 展示了达到不同期望成功率的平均查询次数。 图 5 显示,所提出的方法比其他攻击更具查询效率,并且差距被放大以获得更高的成功率。
Results of Attacks on the Defensive Models. 表5显示了攻击防御模型后获得的实验结果。 ComDefend (CD) [211 和 Feature Distillation (FD) [26] 配备了降噪器,可在输入目标模型之前将输入图像转换为其干净版本。原型一致性损失 (PCL) [31] 引入了一种新的损失函数,以最大限度地分离每个类的中间特征。在这里,PCL 防御模型是在我们的实验中不使用对抗性训练的情况下获得的。 Adv Train [29] 是一种基于对抗训练的强大防御方法。根据表 5 所示结果,我们得出以下结论:
(1) 在所有方法中,Simulator Attack 在破坏 CD 方面表现出最好的性能,特别是显着优于基线方法 Bandits。
(2) Meta Attack 表现出较差的性能CD和FD基于其不理想的成功率。相比之下,模拟器攻击可以以较高的成功率打破这种类型的防御模型。
(3)在Adv Train 被攻击的实验中,模拟器攻击消耗更少的查询来达到与 Bandits 相当的成功率。
表 3:CIFAR-10 和 CIFAR-100 数据集中无针对性攻击的实验结果。
表 4:CIFAR-10 和 CIFAR-100 数据集中针对性攻击的实验结果,其中 m m m 是模拟器-预测区间。
图 4: ℓ ∞ \ell_{\infin} ℓ∞ 范数下无目标攻击中不同有限最大查询的攻击成功率比较,其中 R 32 R_{32} R32 表示 ResNext-101 (32x4d)。
表 5:对防御模型执行 ℓ ∞ \ell_{\infin} ℓ∞ 范数攻击后的实验结果,其中 CD 代表 ComDefend [21],FD 是特征蒸馏 [26],PCL 是原型一致性损失 [31]。
表 6:TinymageNet 数据集中 ℓ ∞ \ell_{\infin} ℓ∞ 范数下无目标攻击的实验结果。 D121:DenseNet-121、 R 32 R_{32} R32:ResNeXt-101 (32x4d)、 R 64 R_{64} R64:ResNeXt-101 (64x4d)。
表 7:TinymageNet 数据集中 ℓ 2 \ell_2 ℓ2 范数下针对性攻击的实验结果。 D121:DenseNet-121, R 32 R_{32} R32:ResNeXt-101(32x4d), R 64 R_{64} R64:ResNeXt-101(64x4d)。
图 5:无目标 ℓ ∞ \ell_{\infin} ℓ∞ 范数攻击下不同成功率下的平均查询比较。 补充材料中提供了更多结果。
5. Conclusion
在这项研究中,我们提出了一种名为 Simulator Attack 的新型黑盒攻击。 它侧重于训练一个广义替代模型(“模拟器”)来准确模拟任何未知目标模型,目的是降低攻击的查询复杂度。 为此,将攻击许多不同网络时生成的查询序列用作训练数据。 所提出的方法在元学习的内部和外部更新中使用基于 MSE 的知识蒸馏损失来学习模拟器。 经过训练后,可以将大量查询转移到模拟器,从而与基线相比,将攻击的查询复杂度降低几个数量级。
References
[1] Maksym Andriushchenko, Francesco Croce, Nicolas Flammarion, and Matthias Hein. Square attack: A query-efficient black-box adversarial attack via random search. In Andrea Vedaldi. Horst Bischof. Thomas Brox. and Jan-MichaelFrahm, editors, Computer Vision - ECCV 2020. pages 484501, Cham, 2020. Springer International Publishing. 2
[2] Arjun Nitin Bhagoji, Warren He, Bo Li, and Dawn Song. Practical black-box attacks on deep neural networks using efficient query mechanisms. In European Conference on Computer Vision, pages 158-174. Springer, 2018. 2
[3] Battista Biggio, Igino Corona. Davide Maiorca, Blaine Nelson, Nedim Srndić, Pavel Laskov, Giorgio Giacinto, andFabio Roli. Evasion attacks against machine learning at test time. In Joint European conference on machine learning and knowledge discovery in databases, pages 387-402. Springer,2013. 1
[4] Nicholas Carlini and David A. Wagner. Towards evaluatingthe robustness of neural networks. In IEEE Symposium on Security and Privacy (SP), pages 39-57, May 2017. 1
[5] Jianbo Chen, Michael I Jordan. and Martin J Wainwright. HopSkipJumpAttack: a query-efficient decision-based adversarial attack. In 2020 IEEE Symposium on Security and Privacy (SP).IEEE. 2020. 2
[6] Pin-Yu Chen. Huan Zhang, Yash Sharma, Jinfeng Yi, and Cho-Jui Hsieh. Zoo: Zeroth order optimization based blackbox attacks to deep neural networks without training substitute models. In Proceedings of the 10th ACM Workshopon Artificial Intelligence and Security, pages 15-26. ACMI2017. 1.2.6
[7] Minhao Cheng, Thong Le, Pin-Yu Chen, Huan Zhang, JinFeng Yi, and Cho-Jui Hsieh. Query-efficient hard-label black-box attack: An optimization-based approach. In 7th International Conference on Learning Representations,ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenReview.net. 2019. 2
[8] Shuyu Cheng, Yinpeng Dong, Tianyu Pang, Hang Su, anoJun Zhu. Improving black-box adversarial attacks with a transfer-based prior. In Advances in Neural Information Processing Systems, volume 32. Curran Associates. Inc… 2019.2,5,7, 8, 1
191 Ekin D. Cubuk, Barret Zoph, Dandelion Mane, Vijay Vasudevan, and Quoc V. Le. Autoaugment: Learning augmentation strategies from data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2019.5
[10] Ambra Demontis, Marco Melis, Maura Pintor, MatthewJagielski, Battista Biggio, Alina Oprea, Cristina Nita-Rotaru,and Fabio Roli. Why do adversarial attacks transfer? explaining transferability of evasion and poisoning attacks. In 28th USENIX Security Symposium (USENIX Security 19),pages 321-338, Santa Clara, CA, Aug. 2019. USENIX Association. 2.3[11] Xuanyi Dong and Yi Yang. Searching for a robust neural architecture in four gpu hours. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1761-1770. 2019. 5
[12] Jiawei Du, Hu Zhang, Joey Tianyi Zhou, Yi Yang, and Jiashi Feng. Query-efficient meta attack to deep neural networks. In International Conference on Learning Representations, 2020. 2, 3, 5, 6,7, 8, 11
[13] lan Goodfellow, Jonathon Shlens, and Christian Szegedy.Explaining and harnessing adversarial examples. In International Conference on Learning Representations, 2015. 1
[14] Chuan Guo, Jacob Gardner, Yurong You, Andrew Gordon Wilson. and Kilian Weinberger. Simple black-box adversarial attacks. In Kamalika Chaudhuri and Ruslan Salakhutdinov, editors, Proceedings of the 36th International Conference on Machine Learning, volume 97 of Proceedings of Machine Learning Research, pages 2484-2493. PMLR. 0915 Jun 2019. 2
[15] Dongyoon Han, Jiwhan Kim, and Junmo Kim. Deep pyramidal residual networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages5927-5935, 2017. 5
[16] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun.Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770-778, 2016. 5.13
[17] Gao Huang, Zhuang Liu, Laurens van der Maaten, and Kilian Q. Weinberger. Densely connected convolutional networks. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), July 2017. 5
[18] Qian Huang, Isay Katsman, Horace He, Zeqi Gu, Serge Belongie, and Ser-Nam Lim. Enhancing adversarial example transferability with an intermediate level attack. In Proceedings of the IEEE International Conference on Computer Vision, pages 4733-4742, 2019. 2, 3
[19] Andrew llyas, Logan Engstrom, Anish Athalye, and Jessy Lin. Black-box adversarial attacks with limited queries and information. In Jennifer Dy and Andreas Krause, editors, Proceedings of the 35th International Conference on Machine Learning, volume 80 of Proceedings of Machine Learning Research, pages 2137-2146. PMLR. 10-15 Jul2018. 1.2.5.7.8. 11. 1
[20] Andrew lyas, Logan Engstrom, and Aleksander Madry.Prior convictions: Black-box adversarial attacks with bandits and priors. In International Conference on Learning Representations, 2019. 1.2.5.7. 8. 11
[21] Xiaojun Jia, Xingxing Wei, Xiaochun Cao, and HassanForoosh. Comdefend: An efficient image compression model to defend adversarial examples. In Proceedings of theIEEE Conference on Computer Vision and Pattern Recogniion, pages 6084-6092. 2019. 7. 8. 12
[22] P. Diederik Kingma and Lei Jimmy Ba. Adam: A methodfor stochastic optimization. In International Conference on Learning Representations. 2015. 12
[23] Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009. 2,5
[24] T. Lee, B. Edwards, I. Molloy, and D. Su. Defending against neural network model stealing attacks using deceptive perturbations. In 2019 IEEE Security and Privacy WorkshopsSPW), pages 43-49, May 2019. 2
[25] Yanpei Liu, Xinyun Chen, Chang Liu, and Dawn Song.Delving into transferable adversarial examples and blackbox attacks. In Proceedings of 5th International Conference on Learning Representations, 2017. 2. 3
[26] Zihao Liu, Qi Liu, Tao Liu, Nuo Xu, Xue Lin, Yanzhi Wang,and Wujie Wen. Feature distillation: Dnn-oriented jpeg compression against adversarial examples. In 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 860-868. IEEE. 2019. 7,8. 13
[27] Chen Ma, Shuyu Cheng, Li Chen, and Junhai Yong. Switching transferable gradient directions for query-efficient blackbox adversarial attacks. arXiv preprint arXiv:2009.07191.2020. 2
[28] Chen Ma, Chenxu Zhao, Hailin Shi, Li Chen, Junhai Yong,and Dan Zeng. Metaadvdet: Towards robust detection of evolving adversarial attacks. In Proceedings of the 27th ACM International Conference on Multimedia, MM '19.page 692-701. New York. NY. USA. 2019. Association for Computing Machinery. 3
[29] Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt,Dimitris Tsipras, and Adrian Vladu. Towards deep learning models resistant to adversarial attacks. In International Conference on Learning Representations, 2018. 1. 8. 13
[30] Smitha Milli, Ludwig Schmidt, Anca D Dragan, and MoritzHardt. Model reconstruction from model explanations. In Proceedings of the Conference on Fairness, Accountability, and Transparency, pages 1-9, 2019. 3
[31] Aamir Mustafa, Salman Khan, Munawar Hayat, RolandGoecke. Jianbing Shen. and Ling Shao. Adversarial defense by restricting the hidden space of deep neural networks. In Proceedings of the IEEE International Conference on Computer Vision, pages 3385-3394. 2019. 7,8, 13
[32] Yurii Nesterov and Vladimir Spokoiny. Random gradientfree minimization of convex functions. Foundations of Computational Mathematics, 17(2):527-566, 2017. 2, 5, 7, 8,11
[33] Seong Joon Oh. Bernt Schiele, and Mario Fritz. Towardsreverse-engineering black-box neural networks. In Explainable Al: Interpreting, Explaining and Visualizing Deep Learning, pages 121-144. Springer, 2019. 2[341 Tribhuvanesh Orekondy, Bernt Schiele, and Mario Fritz.Knockoff nets: Stealing functionality of black-box models.In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 4954-4963, 2019. 2,3
[35] Tribhuvanesh Orekondy, Bernt Schiele, and Mario Fritz.Prediction poisoning: Towards defenses against dnn model stealing attacks. In International Conference on Learning Representations, 2020. 2
[36] Nicolas Papernot, Patrick McDaniel, lan Goodfellow, Somesh Jha. Z Berkay Celik, and Ananthram Swami. Practical black-box attacks against machine learning. In Proceedings of the 2017 ACM on Asia conference on computer ana communications security, pages 506-519. ACM, 2017. 2.3
[37] Li Pengcheng, Jinfeng Yi, and Lijun Zhang. Query-efficient black-box attack by active learning. In 2018 IEEE International Conference on Data Mining (ICDM), pages 12001205. IEEE. 2018. 2
[38] Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Saneev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy,Aditya Khosla. Michael Bernstein, et al. Imagenet large scale visual recognition challenge. International journal of computer vision. 115(3):211-252. 2015. 2.5
[39] Christian Szegedy, Wojciech Zaremba, llya Sutskever, JoanBruna, Dumitru Erhan. lan Goodfellow. and Rob Fergus. Intriguing properties of neural networks. In International Conference on Learning Representations, 2014. 1
[40] Florian Tramèr. Fan Zhang. Ari Juels. Michael K Reiter,and Thomas Ristenpart. Stealing machine learning models via prediction apis. In 25th {USENIX} Security Symposium (USENIX} Security 16), pages 601-618, 2016. 2,3
[41] Chun-Chen Tu. Paishun Ting, Pin-Yu Chen, Sijia Liu, HuarZhang, Jinfeng Yi, Cho-Jui Hsieh, and Shin-Ming ChengAutozoom: Autoencoder-based zeroth order optimization method for attacking black-box neural networks. In Proceedings of the AAAl Conference on Artificial Intelligence,volume 33, pages 742-749, 2019. 1. 2
[42] Binghui Wang and Neil Zhengiang Gong. Stealing hyperparameters in machine learning. In 2018 IEEE Symposium on Security and Privacy (SP), pages 36-52. IEEE, 2018. 3
[43] Saining Xie, Ross Girshick, Piotr Dollár, Zhuowen Tu, andKaiming He. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1492-15002017. 5
[44] Y. Yamada, M. Iwamura, T. Akiba, and K. Kise. Shakedrop regularization for deep residual learning. IEEE Access,7:186126-186136, 2019. 5
[45] Ziang Yan, Yiwen Guo, and Changshui Zhang. Subspace attack: Exploiting promising subspaces for query-efficient black-box attacks. In Advances in Neural Information Processing Systems, pages 3820-3829, 2019. 5[461 Sergey Zagoruyko and Nikos Komodakis. Wide residual networks. In BMVC. 2016. 5
0x03 论文模型代码实现
论文开源代码:SimulatorAttack https://github.com/machanic/SimulatorAttack
0x04 预备知识
0x04.1 元学习
详见:一文弄懂元学习 (Meta Learing)(附代码实战)《繁凡的深度学习笔记》第 15 章 元学习详解 (上)万字中文综述https://blog.csdn.net/weixin_45697774/article/details/121587904
0x05 References
[1] Ma, Chen and Chen, Li and Yong, Jun-Hai, Simulating Unknown Target Models for Query-Efficient Black-Box Attacks,Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR),June,2021,11835-11844
[2] SimulatorAttack https://github.com/machanic/SimulatorAttack