算法导论-上课笔记7:贪心算法
文章目录
- 0 前言
- 1 活动选择问题
-
- 1.1 活动选择问题的最优子结构
- 1.2 贪心选择
- 1.3 递归贪心算法
- 1.4 迭代贪心算法
- 2 贪心算法原理
-
- 2.1 贪心选择性质
- 2.2 最优子结构
- 2.3 贪心VS动态规划
- 3 哈夫曼编码
-
- 3.1 前缀码
- 3.2 构造哈夫曼编码
- 3.3 哈夫曼算法的正确性
-
- 3.3.1 引理D
- 3.3.2 引理E
- 3.3.3 定理F
- 4 拟阵和贪心算法
- 5 用拟阵求解任务调度问题
0 前言
求解最优化问题的算法通常需要经过一系列的步骤,在每个步骤都面临多种选择,可以使用动态规划算法或者贪心算法(greedy algorithm)等算法来求最优解。贪心算法在每一步都做出当时看起来最佳的选择,它总是做出局部最优的选择,希望这样的选择能导致全局最优解。但是贪心算法并不保证总可以得到最优解,但对很多问题确实可以求得最优解。
1 活动选择问题
下面讨论调度竞争共享资源的多个活动的问题,目标是选出一个最大的互相兼容的活动集合。
假定有一个由n个活动(activity)构成的集合S={a1,a2,…,an},这些活动使用同一个资源,而这个资源在某个时刻只能供一个活动使用。每个活动ai都有一个开始时间si和一个结束时间fi,其中0≤si
si≥fj或sj≥fi⇔ai和aj是兼容的。
在活动选择问题中,希望选出一个最大兼容活动集。假定活动已按结束时间的单调递增顺序排序:
![]()
例如,考虑下面的活动集合S:

对于这个例子,子集{a3,a9,a11}由相互兼容的活动组成。但它不是一个最大集,因为子集{a1,a4,a8,a11}更大。实际上,{a1,a4,a8,a11}是一个最大兼容活动子集,另一个最大子集是{a2,a4,a9,a11}。
下面分4步解决这个问题。
事实上可以通过动态规划方法将这个问题分为两个子问题,然后将两个子问题的最优解整合成原问题的一个最优解。在确定该将哪些子问题用于最优解时,要考虑几种选择。而贪心算法只需考虑一个选择(即贪心的选择),在做贪心选择时,子问题之一必是空的,因此,只留下一个非空子问题。基于这些观察,将找到一种递归贪心算法来解决活动调度问题,并将递归算法转化为迭代算法,以完成贪心方法的过程。
1.1 活动选择问题的最优子结构
容易验证活动选择问题具有最优子结构性质。令Sij表示在ai结束之后开始,且在aj开始之前结束的那些活动的集合。假定希望求Sij的一个最大的相互兼容的活动子集,进一步假定Aij就是这样一个子集,包含活动ak。由于最优解包含活动ak,因此得到两个子问题:寻找Sik中的兼容活动(在ai结束之后开始且ak开始之前结束的那些活动)以及寻找Skj中的兼容活动(在ak结束之后开始且在aj开始之前结束的那些活动)。
令Aik=Aij∩Sik和Akj=Aij∩Skj,这样Aik包含Aij中那些在ak开始之前结束的活动,Akj包含Aij中那些在ak结束之后开始的活动。因此:Aij=Aik∪{ak}∪Akj,而且Sij中最大兼容任务子集Aij包含|Aij|=|Aik|+|Akj|+1个活动。
下面仍然用剪切-粘贴法证明最优解Aij必然包含两个子问题Sik和Skj的最优解:如果可以找到Skj的一个兼容活动子集A’kj,满足|A’kj|≥|Akj|,则可以将A’kj而不是Akj作为Sij的最优解的一部分。这样就构造出一个兼容活动集,其大小|Aik|+|A’kj|+1≥|Aik|+|Akj|+1=|Aij|,与Aij是最优解的假设矛盾。对子问题Sik类似可证。
这样刻画活动选择问题的最优子结构,意味着可以用动态规划方法求解活动选择问题。如果用c[i,j]表示集合Sij的最优解的大小,则可得递归式:c[i,j]=c[i,k]+c[k,j]+1。
但是如果不知道Sij的最优解包含活动ak,就需要考查Sij中所有活动,寻找哪个活动可获得最优解,于是:
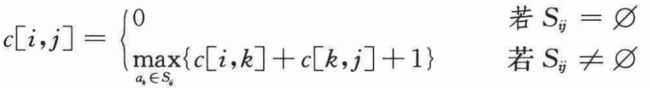
1.2 贪心选择
对于活动选择问题,只需考虑一个选择:贪心选择。直观上应该选择这样一个活动:选出它后剩下的资源应能被尽量多的其他任务所用。现在考虑可选的活动,其中必然有一个最先结束。因此应该选择S中最早结束的活动,因为它剩下的资源可供它之后尽量多的活动使用。如果S中最早结束的活动有多个,可以选择其中任意一个。换句话说,由于活动已按结束时间单调递增的顺序排序,贪心选择就是活动a1。同时要注意,选择最早结束的活动并不是本问题唯一的贪心选择方法。
当做出贪心选择后,只剩下一个子问题需要求解:寻找在a1结束后开始的活动。为什么不需要考虑在a1开始前结束的活动呢?因为s1
之前已证明活动选择问题具有最优子结构性质。
令Sk={ai∈S|si≥fk}为在ak结束后开始的任务集合。当做出贪心选择,即选择了a1后,剩下的S1是唯一需要求解的子问题。如果a1在最优解中,那么原问题的最优解由活动a1及子问题S1中所有活动组成。那么贪心选择即最早结束的活动总是最优解的一部分吗?
定理:考虑任意非空子问题Sk,令am是Sk中结束时间最早的活动,则am在Sk的某个最大兼容活动子集中。
证明:令Ak是Sk的一个最大兼容活动子集,且aj是Ak中结束时间最早的活动。若aj=am,则am在Sk的最大兼容活动子集Ak中。若aj≠am,令集合A’k=(Ak-{aj})∪{am},即将Ak中的aj替换为am。A’k中的活动都是不相交的,因为Ak中的活动都是不相交的,aj是Ak中结束时间最早的活动,而fm≤fj(本不等式需要仔细想想)。由于|A’k|=|Ak|,因此得出结论A’k也是Sk的一个最大兼容活动子集,且它包含am。得证。
可以反复选择最早结束的活动,保留与此活动兼容的活动,重复这一过程,直至不再有剩余活动。因为总是选择最早结束的活动,所以选择的活动的结束时间必然是严格递增的。因此只需按结束时间的单调递增顺序处理所有活动,每个活动会考查且仅考查一次。
求解活动选择问题的算法不必像基于表格的动态规划算法那样自底向上进行计算,可以自顶向下进行计算,选择一个活动放入最优解,然后,对剩余的子问题集(集合中包含的是与已选择的活动兼容的活动)进行求解。贪心算法通常都是这种自顶向下的设计:做出一个选择,然后求解剩下的那个子问题,而不是自底向上地求解出很多子问题,然后再做出选择。
1.3 递归贪心算法
需要一个直接的递归过程来实现贪心算法。
下面的RECURSIVE-ACTIVITY-SELECTOR的输入为两个数组s和f,表示活动的开始和结束时间,下标k指出要求解的子问题Sk,以及问题规模n。它返回Sk的一个最大兼容活动集。假定输入的n个活动已经按结束时间的单调递增顺序排列好,若未排好序,可以在Θ(n·lgn)时间内对它们进行排序,结束时间相同的活动可以任意排列。为了方便算法初始化,添加一个虚拟活动a0,其结束时间f0=0,这样子问题S0就是完整的活动集S。求解原问题即可调用RECURSIVE-ACTIVITY-SELECTOR(s,f,0,n)。
RECURSIVE-ACTIVITY-SELECTOR(s,f,k,n)
m=k+1
while m<=n and s[m]<f[k] //找到Sk中最先结束的活动
m+=1
if m<=n
return {am}∪RECURSIVE-ACTIVITY-SELECTOR(s,f,m,n)
else return ∅
下图是对前文给出的11个活动执行RECURSIVE-ACTIVITY-SELECTOR(s,f,0,11)的过程:

每次递归调用中处理的活动位于水平线之间。虚拟活动a0于时刻0结束,因此RECURSIVE-ACTIVITY-SELECTOR(s,f,0,11)会选择活动a1。在每次递归调用中,被选择的活动用阴影表示,而白底方框表示正在处理的活动。如果一个活动的开始时间早于最近选中的活动的结束时间(两者间的箭头是指向左侧的),它将被丢弃。否则(箭头指向右侧),将选择该活动。最后一次递归调用RECURSIVE-ACTIVITY-SELECTOR(s,f,11,11)返回∅。选择的活动的最终结果集为{a1,a4,a8,a11}。
在一次递归调用RECURSIVE-ACTIVITY-SELECTOR(s,f,k,n)的过程中,第3-4行while循环查找Sk中最早结束的活动。循环检查ak+1,ak+2,…,an,直至找到第一个与ak兼容的活动am,此活动满足sm≥fk。如果循环因为查找成功而结束, 第6行返回{am}与RECURSIVE-ACTIVITY-SELECTOR(s,f,m,n)返回的Sm的最大子集的并集。循环也可能因为m>n而终止,这意味着已经检查了Sk中所有活动,未找到与ak兼容者。在此情况下,Sk=∅,因此第7行返回∅。
假定活动已经按结束时间排好序,则递归调用RECURSIVE-ACTIVITY-SELECTOR(s,f,0,n)的运行时间为Θ(n)。在整个递归调用过程中,每个活动会被第3行的while循环检查且只检查一次。
1.4 迭代贪心算法
下面将算法转换为迭代形式。
RECURSIVE-ACTIVITY-SELECTOR以一个对自身的递归调用和一次并集操作结尾,用来求解子问题Sk。而下面的GREEDY-ACTIVITY-SELECTOR是它的一个迭代版本,同样假定输入活动已按结束时间单调递增顺序排好序,算法将选出的活动存入集合A中,算法最终将返回A:
GREEDY-ACTIVITY-SELECTOR(s,f)
n=s.length
A={a1}
k=1
for m=2 to n
if s[m]>=f[k]
A=A∪{am}
k=m
return A
上述伪代码中的变量k记录了最近加入集合A的活动的下标,它对应递归算法中的活动ak。由于按结束时间的单调递增顺序处理活动,因此fk总是集合A中活动的最大结束时间:
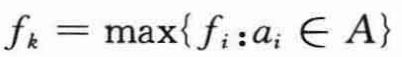
在GREEDY-ACTIVITY-SELECTOR中,第3-4行将A的初值设置为只包含活动a1,并将k的初值设为此活动的下标1。第5-8行的for循环查找Sk中最早结束的活动。循环依次处理每个活动am,am若与之前选出的活动兼容,则将其加入A,这样选出的am必然是Sk中最早结束的活动。为了检查活动am是否与A中所有活动都兼容,过程检查上图的公式是否成立,即检查活动的开始时间sm是否不早于最近加入到A中的活动ak的结束时间fk。如果活动am是兼容的,第7-8行将其加入A中,并将k设置为m。GREEDY-ACTIVITY-SELECTOR(s,f)返回的集合A与RECURSIVE-ACTIVITY-SELECTOR(s,f,0,n)返回的集合完全相同。在输入活动已按结束时间排序的前提下,GREEDY-ACTIVITY-SELECTOR的运行时间也为Θ(n)。
2 贪心算法原理
贪心算法通过做出一系列选择来求出问题的最优解。在每个决策点,它做出在当时看来最佳的选择。这种启发式策略并不保证总能找到最优解,但对某些问题确实有效,如上一节的活动选择问题。下面讨论贪心方法的一些一般性质。
【1 活动选择问题】一节中设计贪心算法的过程比通常的过程繁琐一些,当时经过了如下几个步骤:
1、确定问题的最优子结构。
2、设计一个递归算法。
3、证明如果做出一个贪心选择,则只剩下一个子问题。
4、证明贪心选择总是安全的。
5、设计一个递归算法实现贪心策略。
6、将递归算法转换为迭代算法。
在上述过程中,可见贪心算法是以动态规划方法为基础的。例如,在活动选择问题中,首先定义了子问题Sij,其中i和j都是可变的。如果总是做出贪心选择,则可以将子问题限定为Sk的形式。
可通过贪心选择来改进最优子结构,使得选择后只留下一个子问题。在活动选择问题中,可以一开始就将子问题Sij的第二个下标j去掉,将子问题定义为Sk的形式。可以证明贪心选择(Sk中最早结束的活动am)与剩余兼容活动集的最优解组合在一起,就会得到Sk的最优解。更一般地,可以按如下步骤设计贪心算法:
1、将最优化问题转化为这样的形式——对其做出一次选择后,只剩下一个子问题需要求解。
2、证明做出贪心选择后,原问题总是存在最优解,即贪心选择总是安全的。
3、证明做出贪心选择后,剩余的子问题满足性质——其最优解与贪心选择组合即可得到原问题的最优解,这样就得到了最优子结构。
本文剩余部分将使用这种更直接的设计方法。但在每个贪心算法之下,几乎总有一个更繁琐的动态规划算法。
如何证明一个贪心算法是否能求解一个最优化问题呢?遗憾的是并没有适合所有情况的方法,但贪心选择性质和最优子结构是两个关键要素。如果能够证明问题具有这2个性质,就向贪心算法迈出了重要一步。
2.1 贪心选择性质
第一个关键要素是贪心选择性质(greedy-choice property):可以通过做出局部最优(贪心)选择来构造全局最优解。当进行选择时,直接做出在当前问题中看来最优的选择,而不必考虑子问题的解。
这也是贪心算法与动态规划的不同之处。在动态规划方法中,每个步骤都要进行一次选择,但选择通常依赖于子问题的解。因此,通常以自底向上的方式求解动态规划问题——先求解较小的子问题,然后是较大的子问题(也可以自顶向下求解,但需要备忘机制。当然,即使算法是自顶向下进行计算,仍然需要先求解子问题再进行选择)。在贪心算法中,总是做出当时看来最佳的选择,然后求解剩下的唯一的子问题。贪心算法进行选择时可能依赖之前做出的选择,但不依赖任何将来的选择或是子问题的解。因此,与动态规划先求解子问题才能进行第一次选择不同,贪心算法在进行第一次选择之前不求解任何子问题。一个动态规划算法是自底向上进行计算的,而一个贪心算法通常是自顶向下的,进行一次又一次选择,将给定问题实例变得更小。
必须证明每个步骤做出贪心选择确实能生成全局最优解,这种证明通常首先考查某个子问题的最优解,然后用贪心选择替换某个其他选择来修改此解,从而得到一个相似但更小的子问题。
如果进行贪心选择时不得不考虑众多选择,通常意味着可以改进贪心选择,使其更为高效。例如,在活动选择问题中,假定已经将活动按结束时间单调递增顺序排好序,则对每个活动能够只需处理一次即可。通过对输入进行预处理或者使用适合的数据结构(通常是优先队列),通常可以使贪心选择更快速,从而得到更高效的算法。
2.2 最优子结构
如果一个问题的最优解包含其子问题的最优解,则称此问题具有最优子结构性质。此性质是能否应用动态规划和贪心方法的关键要素。以【1 活动选择问题】一节的活动选择问题为例,如果一个子问题Sij的最优解包含活动ak,那么它必然也包含子问题Sik和Skj的最优解。给定这样的最优子结构,如果知道Sij的最优解应该包含哪个活动ak,就可以组合ak以及Sik和Skj的最优解中所有活动来构造Sij的最优解。基于对最优子结构的这种观察结果,就可以设计出递归式:
来描述最优解值的计算方法。
当应用于贪心算法时,通常使用更为直接的最优子结构。可假定通过对原问题应用贪心选择即可得到子问题。而真正要做的全部工作就是论证:将子问题的最优解与贪心选择组合在一起就能生成原问题的最优解。这种方法隐含地对子问题使用了数学归纳法,证明了在每个步骤进行贪心选择都有助于生成原问题的最优解。
2.3 贪心VS动态规划
由于贪心和动态规划策略都利用了最优子结构性质,有时候可能会对一个可用贪心算法求解的问题设计一个动态规划算法,或者对一个实际上需要用动态规划求解的问题使用了贪心方法。为了说明两种方法之间的细微差别,下面讨论背包问题的两个变形:
1、0-1背包问题(0-1 knapsack problem)是这样的:一个正在抢劫商店的小偷发现了n个商品,第i个商品价值vi美元,重wi磅,vi和wi都是整数。这个小偷希望拿走价值尽量高的商品,但他的背包最多能容纳W磅重的商品,W是一个整数。他应该拿哪些商品呢?称这个问题是0-1背包问题,因为对每个商品,小偷要么把它完整拿走,要么把它留下。他不能只拿走一个商品的一部分,或者把一个商品拿走多次。
2、在分数背包问题(fractional knapsack problem)中,设定与0-1背包问题是一样的,但对每个商品,小偷可以拿走其一部分,而不是只能做出二元(0-1)选择。
两个背包问题都具有最优子结构性质。对0-1背包问题,考虑重量不超过W而价值最高的装包方案。如果将商品j从此方案中删除,则剩余商品必须是重量不超过W-wj的价值最高的方案,同时小偷只能决定从不包括商品j的n-1个商品中选择拿走哪些东西。
虽然两个问题相似,但用贪心策略可以求解分数背包问题,而不能求解0-1背包问题。为了求解分数背包问题,首先计算每个商品的平均价值vi/wi。遵循贪心策略,小偷首先尽量多地拿走平均价值最高的商品。如果该商品已全部拿走而背包尚未满,他继续尽量多地拿走平均价值第二高的商品,依此类推,直至达到重量上限W。伪代码如下:
GREEDY-FRACTIONAL-KNAPSACK(p,w,W,x,n)
x=0 //初始化x为零向量
c=W //c是背包剩余容量
for i=1 to n
if w(i)<=c
x(i)=1 //将第i个商品整个放入背包
c=c-w(i) //更新背包剩余容量
else
break //其他情况就退出循环
if i<=n
x(i)=c/w(i) //最后一个商品只能被拿走一部分
return x //返回x向量
在上述伪代码中,参数W是背包的总容量,n是可选商品的件数,p、w均是向量且分别代表商品的价值、重量,x是最后的解向量。注意:向量p、w共有n维且已按平均价值pi/wi排序:对i=1,2,…,n-1,pi/wi≥pi+1/wi+1。除此之外,解释下怎么通过向量x得到最后的装包方案:首先,x是n维向量,设xi是第i个维度,则xi只可能有三种取值:
1、=0,这代表不能拿走第i个商品;
2、=1,这代表整个拿走第i个商品;
3、=a,其中0 为了说明贪心策略对0-1背包问题无效,考虑下图a所示的问题实例。此例包含3个商品和一个能容纳50磅重量的背包。商品1重10磅,价值60美元。商品2重20磅,价值100美元。商品3重30磅,价值120美元。因此,商品1的平均价值为6美元,高于商品2的平均价值(5美元)和商品3的平均价值(4美元)。因此,上述贪心策略会首先拿走商品1。但是,如图b的实例分析所示,最优解应该拿走商品2和商品3,而留下商品1。拿走商品1的两种方案都是次优的。 1、a:小偷必须选择所示三个商品的一个子集,总重量不超过50磅。 2、b:最优子集由商品2和商品3组成。虽然商品1有最大的平均价值,但包含它的任何解都是次优的。 3、c:对于分数背包问题,按平均价值降序拿走商品会生成一个最优解。 对于分数背包问题,上述贪心策略首先拿走商品1,是可以生成最优解的。拿走商品1的策略对0-1背包问题无效是因为小偷无法装满背包,空闲空间降低了方案的有效平均价值。在0-1背包问题中,当考虑是否将一个商品装入背包时,必须比较包含此商品的子问题的解与不包含它的子问题的解,然后才能做出选择。这会导致大量的重叠子问题,这也是动态规划的标识。 下面虽然不会具体给出动态规划解决0-1背包问题的伪代码,但会给出0-1背包问题的最优子结构呢! 设c[i,j]代表总容量为j的背包中装下的总共i种商品的最大总价值,则0-1背包问题的目标是获得c[n,W]的最大值,其中n是可选商品的种类,W是背包总容量。则0-1背包问题的最优子结构为: 1、如果最优解包含第n种商品,则接下来需要解决子问题:背包剩余容量为W-wn,需要在前n-1种商品中作出选择并得出最优解。 2、如果最优解不包含第n种商品,则接下来需要解决子问题:背包剩余容量为W,需要在前n-1种商品中作出选择并得出最优解。 综上所述,c[i,j]的递推式为: c[i,j]=max{c[i-1,j],c[i-1,j-wi]+vi} 上式的边界条件是: 1、当j≥0时,c[0,j]=0; 2、当j<0时,c[i,j]=-∞。 则有: 哈夫曼编码可以很有效地压缩数据:通常可以节省20%-90%的空间,具体压缩率依赖于数据的特性。可将待压缩数据看做字符序列,根据每个字符的出现频率,哈夫曼贪心算法将构造出字符的最优二进制表示。 假定需要压缩一个由10万个字符组成的数据文件,下图(记为图A)给出了文件中所出现的字符和它们的出现频率: 有很多方法可以表示这个文件的信息。在本节中,考虑一种二进制字符编码(之后简称编码)的方法,每个字符用一个唯一的二进制串表示,称为码字。如果使用定长编码,需要用3位来表示6个字符:a=000,b=001,…,f=101。这种方法需要300000个二进制位来编码文件。 是否有更好的编码方案呢? 变长编码(variable-length code)可以达到比定长编码好得多的压缩率,其思想是赋予高频字符短码字,赋予低频字符长码字。上面的图A显示了本例的一种变长编码:1位的串0表示a,4位的串1100表示f。因此,这种编码表示此文件共需: 只考虑前缀码(prefix code),即没有任何码字是其他码字的前缀。与任何其他的字符编码相比,前缀码确实可以保证达到最优数据压缩率。 任何二进制字符码的编码过程都很简单,只要将表示每个字符的码字连接起来即可完成文件压缩。例如,使用前文中图A所示的变长前缀码,可以将3个字符的文件abc编码为:0·101·100=0101100,其中“.”表示连结操作。 前缀码的作用是简化解码过程。由于没有码字是其他码字的前缀,编码文件的开始码字是无歧义的。可以简单地识别出开始码字,将其转换回原字符,然后对编码文件剩余部分重复这种解码过程。如二进制串001011101可以唯一地解析为0·0·101·1101,解码为aabe。 解码过程需要前缀码的一种方便的表示形式,以便可以容易地截取开始码字。一种二叉树表示可以满足这种需求,其叶结点为给定的字符。字符的二进制码字用从根结点到该字符叶结点的简单路径表示,其中0意味着“转向左孩子”,1意味着“转向右孩子”。下图(记为图B)给出了两个编码示例的二叉树表示: 1、a对应定长编码a=000,…,f=101的二叉树。 2、b对应最优前缀码a=0,b=101,…,f=1100的二叉树。 注意,编码树并不是二叉搜索树,因为叶结点并未有序排列,而且内部结点并不包含字符关键字。 文件的最优编码方案总是对应一棵“满的二叉树”,注意本文中指的“满的二叉树”并不是通常意义上的满二叉树,而是指每个非叶结点都有两个孩子结点。前文给出的定长编码实例不是最优的,因为它的二叉树表示并非“满的二叉树”,如图B的树a所示:它包含以10开头的码字,但不包含以11开头的码字。 现在只关注“满的二叉树”,因此若C为字母表且所有字符的出现频率均为正数,则最优前缀码对应的树恰有|C|个叶结点,每个叶结点对应字母表中一个字符,且恰有|C|-1个内部结点。 给定一棵对应前缀码的树T,可以容易地计算出编码一个文件需要多少个二进制位。对于字母表C中的每个字符c,令属性c.freq表示c在文件中出现的频率,令: 哈夫曼设计了一个贪心算法来构造最优前缀码,被称为哈夫曼编码(Huffman code),它的正确性证明也依赖于贪心选择性质和最优子结构。下面先设计算法,以明确算法是如何做出贪心选择的。 在下面给出的伪代码HUFFMAN中,假定C是一个由n个字符组成的集合,而其中每个字符c∈C都是一个对象,其属性c.freq给出了字符c的出现频率。算法自底向上地构造出对应最优编码的二叉树T。它从|C|个叶结点开始,执行|C|-1个“合并”操作创建出最终的二叉树。算法使用一个以属性freq为关键字最小优先队列Q,以识别两个最低频率的对象然后将其合并。当合并两个对象时,得到的新对象的频率设置为原来两个对象的频率之和。 对前文给出的例子,HUFFMAN的执行过程如下图所示: 在HUFFMAN中,第3行用C中字符初始化最小优先队列Q。第4-9行的for循环反复从队列中提取两个频率最低的结点x和y,将它们合并为一个新结点z,替代它们。z的频率为x和y的频率之和(第8行)。结点z将x作为其左孩子,将y作为其右孩子(顺序是任意的,交换左右孩子会生成一个不同的编码,但代价完全一样)。经过n-1次合并后,第10行返回队列中剩下的唯一结点——编码树的根结点。 如果不使用变量x和y(第6、7行直接对z.left和z.right直接赋值,将第8行改为z.freq=z.left.freq+z.right.freq),算法还是会生成相同的结果,但后面在证明算法正确性时,需要用到结点名x和y。因此,保留x和y更方便。 为了分析哈夫曼算法的运行时间,假定Q是使用最小二叉堆实现的。对一个n个字符的集合C,在第3行用BUILD-MIN-HEAP过程将Q初始化,花费时间为O(n)。第4-9行的for循环执行了n-1次,且每个堆操作需要O(lgn)的时间,所以循环对总时间的贡献为O(n·lgn)。因此,处理一个n个字符的集合,HUFFMAN的总运行时间为O(n·lgn)。 为了证明贪心算法HUFFMAN是正确的,需要证明确定最优前缀码的问题具有贪心选择和最优子结构性质。 下面的引理D证明了构造最优前缀码的问题具有贪心选择性质。 引理D:令C为一个字母表,其中每个字符c∈C都有一个频率c.freq。令x和y是C中频率最低的两个字符。那么存在C的一个最优前缀码,其中x和y的码字长度相同,且二者只有最后一个二进制位不同。 证明思路:令T表示任意一个最优前缀码所对应的编码树,对其进行修改,得到表示另外一个最优前缀码的编码树,使得在新树中,x和y是深度最大的叶结点,且它们为兄弟结点。如果可以构造这样一棵树,那么x和y的码字将有相同长度,且只有最后一位不同。 证明: 设a和b是T中深度最大的兄弟叶结点。不失一般性地,假定a.freq≤b.freq且x.freq≤y.freq。由于x.freq和y.freq是最低的两个频率,而a.freq和b.freq是两个任意频率,因此有x.freq≤a.freq且y.freq≤b.freq。这样的话,有可能x.freq=a.freq或y.freq=b.freq成立。但如果x.freq=b.freq,则有a.freq=b.freq=x.freq=y.freq(读者需要好好想想呢),此时引理显然是成立的。因此,下文假定x.freq≠b.freq,这意味着x≠b。如下图所示: 但是如果x=b且y≠a,如下图: 1、a.freq-x.freq是非负的,因为x是出现频率最低的结点; 2、dT(a)-dT(x)是非负的,因为a是T中深度最深的叶结点。 类似地,交换y和b也不能增加代价,所以同理B(T’)-B(T")≥0,因此B(T")≤B(T)。又由于T是最优的,故B(T)≤B(T"),这意味着B(T")=B(T)。因此,T"也是最优树,且x和y是其中深度最深的兄弟叶结点。 由此,引理D得证。 引理D说明,不失一般性地,通过合并来构造最优树的过程,可以从合并出现频率最低的两个字符这样一个贪心选择开始。为什么这是一个贪心选择呢?可以将一次合并操作的代价看做被合并的两项的频率之和。在每个步骤可选的所有合并操作中,HUFFMAN选择是代价最小的那个。因此这是一个贪心选择! 下面的引理E证明了构造最优前缀码的问题具有最优子结构性质。 引理E:令C为一个给定的字母表,其中每个字符c∈C都定义了一个频率c.freq。令x和y是C中频率最低的两个字符。令C’为C去掉字符x和y,加入一个新字符z后得到的字母表,即C’=(C-{x,y})∪{z}。类似C,也为C’定义freq,不同之处只是z.freq=x.freq+y.freq。令T’为字母表C’的任意一个最优前缀码对应的编码树。于是可以将T’中叶结点z替换为一个以x和y为孩子的内部结点,得到树T,而T表示字母表C的一个最优前缀码。 首先说明如何用树T’的代价B(T’)来表示树T的代价B(T),方法是考虑公式: 证明:假定T对应的前缀码并不是C的最优前缀码,则存在最优编码树T"满足B(T") 由此,引理E得证。 定理F:过程HUFFMAN会生成一个最优前缀码。 证明:引理D证明了构造最优前缀码的问题具有贪心选择性质,而引理E证明了构造最优前缀码的问题具有最优子结构性质,因此由引理D和引理E可得定理F。 由此,定理F得证。 至此,已经证明了确定最优前缀码的问题具有: 1、贪心选择; 2、最优子结构性质。 综上所述,贪心算法HUFFMAN是正确的。 不会更新 不会更新 END

上图中:

3 哈夫曼编码

根据上表,文件中有100000个字符,且只包含a-f共6个不同字符,出现频率如上表第二行所示。如果为每个字符指定一个如上表第三行的3位定长编码,可以将文件编码为300000位的长度。但使用上表最后一行所示的变长编码,可以仅用224000位编码文件。
![]()
与定长编码相比节约了25%的空间。3.1 前缀码
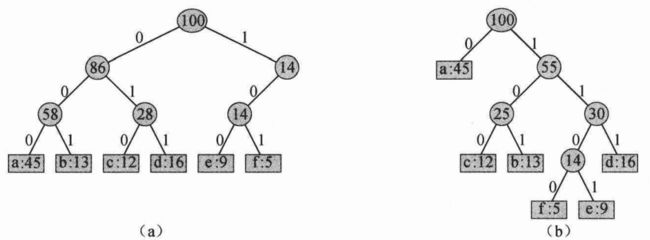
图B是图A中的两种编码方案的两棵二叉树表示。每个叶结点标记了一个字符及其出现频率。每个内部结点标记了其子树中叶结点的频率之和。其中:
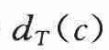
表示c的叶结点在树中的深度,它也是字符c的码字的长度。则编码文件需要:
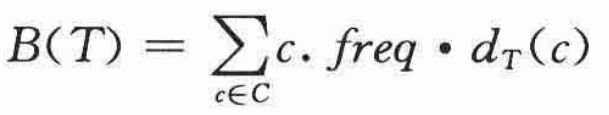
个二进制位,将B(T)定义为T的代价。3.2 构造哈夫曼编码
HUFFMAN(C)
n=|C|
Q=C
for i=1 to n-1
allocate a new node z
z.left=x=EXTRACT-MIN(Q)
z.right=y=EXTRACT-MIN(Q)
z.freq=x.freq+y.freq
INSERT(Q,z)
return EXTRACT-MIN(Q)

上图是对图A中给出的频率执行HUFFMAN的过程。每一部分显示了优先队列的内容,已按频率递增顺序排好序。在每个步骤,频率最低的两棵树进行合并。叶结点用矩形表示,每个叶结点包含一个字符及其频率。内部结点用圆圈表示,包含其孩子结点的频率之和。内部结点指向左孩子的边标记为0,指向右孩子的边标记为1。一个字母的码字对应从根到其叶结点的路径上的边的标签序列。其中,a表示初始集合有n=6个结点,每个结点对应一个字母。b-e为中间步骤。f为最终的编码树。由于字母表包含6个字母,初始队列大小为n=6,需要5个合并步骤构造二叉树。3.3 哈夫曼算法的正确性
3.3.1 引理D

在上图中,最优树T的叶结点a和b是最深的叶结点中的两个,并且是兄弟。由于x和y是C中频率最低的两个字符,因此叶结点x和y为哈夫曼算法首先合并的两个叶结点,且它们可能出现在T中的任意位置上。由于假定了x.freq≠b.freq,因此x≠b,现在在T中交换x和a生成一棵新树T’,并在T’中交换b和y生成一棵新树T",那么在T"中x和y是深度最大的两个兄弟叶结点。
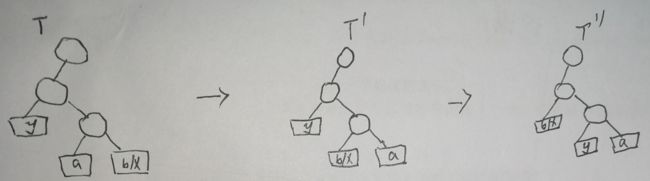
那么T"中x和y不是深度最深的兄弟叶结点,因此下文依然假定x≠b。由公式:
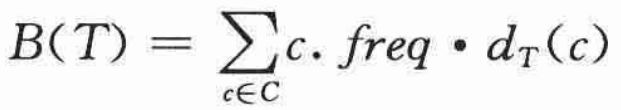
得【3.3.1 引理D】一节的第一张图中T和T’的代价差为:
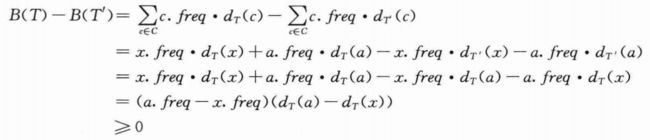
最后≥0是因为下面二者都是非负的:3.3.2 引理E
中每项的代价。然后:

于是可以得到结论:
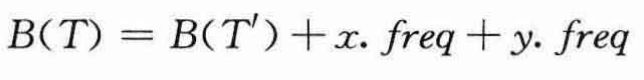
或者等价地:
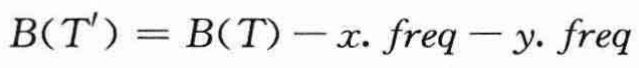
下面用反证法来证明引理E。![]()
这与T’对应C’的一个最优前缀码的假设矛盾。因此,T必然表示字母表C的一个最优前缀码。3.3.3 定理F
4 拟阵和贪心算法
5 用拟阵求解任务调度问题