深度学习基础知识之激活函数
在深度视觉的三大基本任务中,我们构建一个卷积神经网络,激活函数是必不可少的,例如sigmoid,relu等,下面我们来介绍下激活函数。
什么是激活函数?
神经网络中每层的输入是上一层的输出,每层输出是下一层的输入,所以在多层神经网络中,上层节点的输出和下层节点的输入之间具有一个函数关系,这个函数称为激活函数。
如图所示:
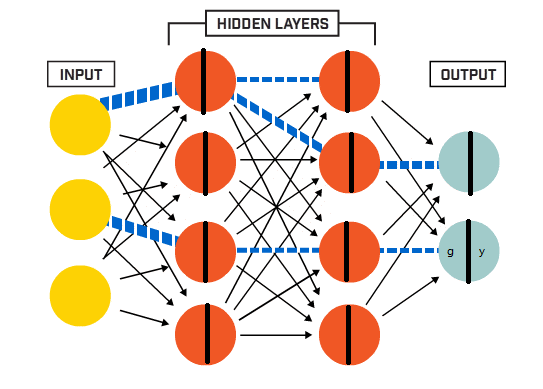 除输入层外,每个神经元被分成两部分,第一部分我们认为就是上一层的输出;第二部分就是经过一个激活函数的作用,作为下一层的输入。
除输入层外,每个神经元被分成两部分,第一部分我们认为就是上一层的输出;第二部分就是经过一个激活函数的作用,作为下一层的输入。
为什么要用激活函数?
不使用激活函数的话,神经网络的每层都只是做线性变换,线性函数无论叠加多少层,都是线性的,只是斜率和截距不同,叠加网络对解决实际问题没有多大帮助;因为需要神经网络解决的实际问题基本都是非线性的。
我们现在有一个任务,要分4个类别,用下面两个图来说明:
 没有加入激活函数,绿色的五角星在直线上,占了一部分。
没有加入激活函数,绿色的五角星在直线上,占了一部分。
 加入了激活函数,绿色五角星被很好的分开了。
加入了激活函数,绿色五角星被很好的分开了。
从以上两幅图片对比,用了激活函数分类效果更准确,这也说明非线性拟合能力更强。
线性非线性在这里就可以理解为直线和曲线。
其实光理解直线和曲线不太严谨,不过这里不影响后续学习。
常用的激活函数
sigmoid
函数公式:
s i g m o i d = 1 1 + e − x sigmoid = \frac{1}{1+e^{-x}} sigmoid=1+e−x1
函数图像如图所示

Sigmoid函数:输出值范围为[0,1]之间的实数,用作2分类问题。
缺点:
- sigmoid函数饱和使梯度消失。
- sigmoid函数输出不是零为中心,即zigziag现象,收敛慢。
- 指数函数计算比较消耗计算资源。
tanh
函数公式:
t a n h = 1 − e − x 1 + e − x tanh = \frac{1 - e^{-x}}{1+e^{-x}} tanh=1+e−x1−e−x
函数图像如下图所示:

优点:tanh解决了sigmoid的输出非“零为中心”的问题
缺点:
- 依然有sigmoid函数过饱和的问题。
- 依然进行的是指数运算
ReLU
函数公式:
r e l u = m a x ( 0 , x ) relu = max(0, x) relu=max(0,x)
函数图像如下图所示:

优点:
- ReLU解决了梯度消失的问题,至少x在正区间内,神经元不会饱和。
- 由于ReLU线性、非饱和的形式,在SGD中能够快速收敛。
- 算速度要快很多。ReLU函数只有线性关系,不需要指数计算,计算速度都比sigmoid和tanh快。
缺点:
- ReLU的输出不是“零为中心”。
- 随着训练的进行,可能会出现神经元死亡,权重无法更新的情况。这种神经元的死亡是不可逆转的死亡。
常用的还是relu函数,当你不知道用啥,就用relu。
softmax
softmax简单理解:将输出值变成概率化。
公式:
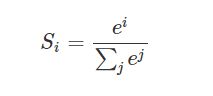
其直观理解:
 如上图,输出为 z 1 , z 2 , z 3 z_1,z_2,z_3 z1,z2,z3,对应的值为 [ 3 1 − 3 ] [3~~~1 ~~-3] [3 1 −3],经过softmax函数作用,就是将输出的值,带入saoftmax公式,得到的 y y y就会被映射到 ( 0 1 ) (0 ~1) (0 1)之间,这些值的和为 1 1 1,在最后的输出选取概率输出的最大值为分类结果,上图中就是 z 1 , 3 z_1,3 z1,3对应的输出 y 1 y_1 y1的概率值最大,他的索引值【0】,即为我们的目标分类 0 0 0 。
如上图,输出为 z 1 , z 2 , z 3 z_1,z_2,z_3 z1,z2,z3,对应的值为 [ 3 1 − 3 ] [3~~~1 ~~-3] [3 1 −3],经过softmax函数作用,就是将输出的值,带入saoftmax公式,得到的 y y y就会被映射到 ( 0 1 ) (0 ~1) (0 1)之间,这些值的和为 1 1 1,在最后的输出选取概率输出的最大值为分类结果,上图中就是 z 1 , 3 z_1,3 z1,3对应的输出 y 1 y_1 y1的概率值最大,他的索引值【0】,即为我们的目标分类 0 0 0 。
选择激活函数的一些建议
- 通常来说,不能把各种激活函数串起来在一个网络中使用。
- 如果使用ReLU,那么一定要小心设置学习率(learning rate),并且要注意不要让网络中出现很多死亡神经元。
- 尽量不要使用sigmoid激活函数,可以试试tanh,不过我还是感觉tanh的效果会比不上ReLU。
参考文章链接:
https://www.cnblogs.com/XDU-Lakers/p/10557496.html