【Transformer】Swin Transformer

文章目录
-
- 一、背景
- 二、动机
- 三、方法
-
- 3.1 整体结构
- 3.2 Shifted Window based Self-Attention
- 3.3 Architecture Variants
- 四、效果
- 五、代码
分类代码:https://github.com/microsoft/Swin-Transformer
分割代码:https://github.com/SwinTransformer/Swin-Transformer-Semantic-Segmentation
检测代码:https://github.com/SwinTransformer/Swin-Transformer-Object-Detection
一、背景
Transformer 最开始是在 NLP 中使用较多,因为其 self-attention 组件能够对 Long-range 的信息进行建模,近期有很多人开始将 Transformer 应用到计算机视觉中,作为一个类似于 CNN 的特征提取器。
二、动机
NLP 到 CV ,主要有两个问题:
- 视觉场景中,目标大小不同
- 视觉场景中,图像的分辨率远远大于句子中的单词
基于这两个问题,Transformer通常使用如下方法解决:
- Transformer 通常将图像划分为大小相同的图像块,即为 “token” (NLP 中的token通常为单词),这其实不是很合适,因为目标的大小是不同的。
- Transformer 中使用了 self-attention 机制,而检测/分割这些密集任务要求输入图像分辨率较大,所以self-attention的计算量和图像大小成次方关系,计算量很大
所以本文中,作者提出了一个通用的 Transformer backbone:Swin Transformer,该方法特点如下, 也正是由于这两个特点,使得 swin transformer 能够作为一个通用的 backbone:
-
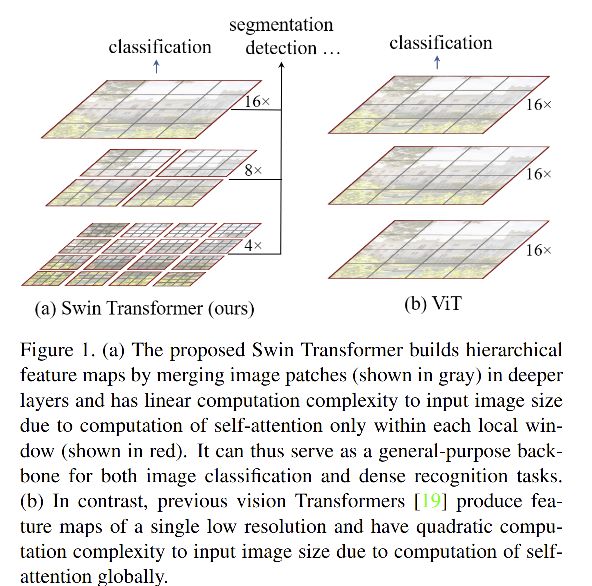
将多级特征进行融合:
如图1a,该方法从最小尺度的 patches(灰色框)开始,逐级和邻域 patches 进行融合,也正是这个模式,使得swin transformer 能够方便的和密集预测网络 FPN 、U-Net 等配合使用。
-
计算量和图像大小呈线性关系:
由于每个 window 中的 patches 数量都是固定的,所以计算量和图像大小是呈线性的变化的。
三、方法
3.1 整体结构
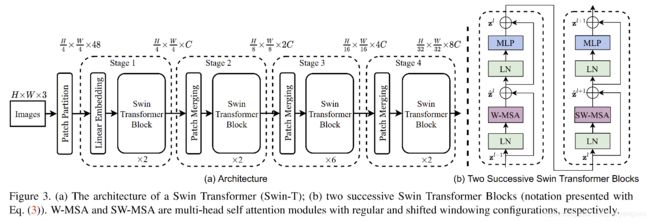
-
首先,将输入的 RGB 图像分成无重叠的patches,每个 patch 被当做一个 token,并且其特征会和原始的输入图像进行concat,本文中,作者将 patch size 设置为 4x4 大小,每个patch的特征维度为 4x4x3=48。
-
Stage1:输入: H 4 × W 4 × 3 \frac{H}{4} \times \frac{W}{4} \times 3 4H×4W×3,输出为 H 4 × W 4 × C \frac{H}{4}\times \frac{W}{4} \times C 4H×4W×C
使用线性编码层,来将其变换到特定的维度(C维),然后使用 2 个 swin transformer block 提取特征。
为了融合不同层级特征,token的数量随着网络的加深而减少
-
Stage2:输入: H 4 × W 4 × C \frac{H}{4} \times \frac{W}{4} \times C 4H×4W×C,输出为 H 8 × W 8 × 2 C \frac{H}{8}\times \frac{W}{8} \times 2C 8H×8W×2C
patch merging 的合并过程,将 2x2 的相邻 patch 特征进行拼接,并对拼接后的 4C 维特征使用线性层,token 的数量减少 4 倍,输出通道数为 2C
-
Stage3:输入: H 8 × W 8 × 2 C \frac{H}{8} \times \frac{W}{8} \times 2C 8H×8W×2C,输出为 H 16 × W 16 × 4 C \frac{H}{16}\times \frac{W}{16} \times 4C 16H×16W×4C
-
Stage4:输入: H 16 × W 16 × 4 C \frac{H}{16}\times \frac{W}{16} \times 4C 16H×16W×4C,输出为 H 32 × W 32 × 8 C \frac{H}{32}\times \frac{W}{32} \times 8C 32H×32W×8C
我们可以看到所有stage的 swin transformer block 都是偶数个,这是因为每个 window MHSA 后面都要跟一个 shift window MHSA。所以都是偶数个。
Patch Merging 代码:
patch merging 代码会将特征图分辨率下降为1/2,通道升为原来的 2 倍,也可以看做 CNN 中的提升感受野的过程。
class PatchMerging(nn.Module):
r""" Patch Merging Layer.
Args:
input_resolution (tuple[int]): Resolution of input feature.
dim (int): Number of input channels.
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm):
super().__init__()
self.input_resolution = input_resolution
self.dim = dim
self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
self.norm = norm_layer(4 * dim)
def forward(self, x):
"""
x: B, H*W, C
"""
H, W = self.input_resolution
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
assert H % 2 == 0 and W % 2 == 0, f"x size ({H}*{W}) are not even."
x = x.view(B, H, W, C)
# patch merging 的输入假设为 1x14x14x384
# patch merging 会首先使用如下方法将其扩展为 1x7x7x1526
x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
x = torch.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
x = x.view(B, -1, 4 * C) # B H/2*W/2 4*C
# 对 1x49x1526 进行规范化
x = self.norm(x)
# 通道降为为 2C, 1x49x768
x = self.reduction(x)
return x
Swin Transformer block:
该结构是使用基于 shifted windows 的 Transformer block 代替 multi-head self attention (MSA) 得到的。
组成结构:基于 shifted window 的 MSA + MLP,每个 MSA 和 MLP 前面都有一个 LN 层(Layer Norm),每个模块之间都使用了 residual connection 连接。

3.2 Shifted Window based Self-Attention
现有的标准 transformer [61][19]等,通常使用全局的self-attention,也就是计算每个token和其他token的关系,所以计算量是和token的数量呈平方关系的,导致其难以适用于高分辨率的任务。
self-attention in non-overlapped windows:
为了更高效的建模,作者提出了只计算局部window内的 self-attention,这些windows是将输入图像均匀的划分为不重叠的块。每个 window 包含 MxM 个 patches。
当输入图像大小为 hxw时,不同方法的self-attention计算量如下:
-
MSA:和 hw 呈二次方关系
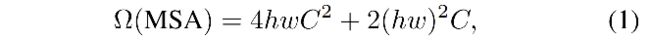
-
W-MSA:和 hw 呈线性关系
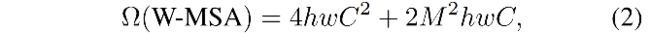
Shifted window partitioning in successive blocks:
window-based self-attention 无法在window之间进行信息提取,这就会限制模型的建模能力,为了实现window之间的联系同时保持高效的计算效率,作者使用 shifted-window 的方法来实现,也就是在连续的 swin transformer block 使用滑动的window,使得不同层级的block的window包含的内容不同。
如图2所示:
- 第一个 module 使用常规的window划分策略,从左上角开始,把8x8大小的特征图划分成2x2大小的window,每个window的大小为 4x4(M=4)。
- 第二个 module 将前一级的 module 的window进行了滑动,将window滑动了 ( ⌊ M / 2 ⌋ , ⌊ M / 2 ⌋ \lfloor M/2 \rfloor, \lfloor M/2 \rfloor ⌊M/2⌋,⌊M/2⌋) 个pixels

基于此,连续的 swin transformer block 计算如下:

- z ^ l \hat z ^l z^l:(S)W-MSA 模块的输出特征(block l l l),SW-MSA 表示基于shift window,W-MSA 表示基于普通 window 的multi-head self-attention。
- z l z^l zl:MLP 模块的输出特征(block l l l)
Efficient batch computation for shifted configuration:
shfited window 分块会产生一个问题,即会产生很多 windows,从 ⌈ h M ⌉ × ⌈ w M ⌉ \lceil \frac{h}{M} \rceil \times \lceil \frac{w}{M} \rceil ⌈Mh⌉×⌈Mw⌉ 到 ( ⌈ h M ⌉ + 1 ) × ( ⌈ w M ⌉ + 1 ) (\lceil \frac{h}{M} \rceil +1)\times (\lceil \frac{w}{M} \rceil+1) (⌈Mh⌉+1)×(⌈Mw⌉+1),而且许多window的大小会小于 M × M M\times M M×M。
一个比较简单的解决方法:
对小于 M × M M\times M M×M 的 window 进行 padding,然后在进行attention计算的时候把填充的东西忽略掉。但这样也带来了计算量的增加。
本文的解决方法:cyclic-shifting toward the top-left direction

通过移位的方法,组成一个可以处理的窗口,这个可处理的窗口是由几个不相邻的子窗口组成的,然后使用掩膜的方式来辅助计算自注意力特征。这种 cyclic-shift 的方法使得shift window 的方法和普通window的方法没有什么计算量上的差别。

Shift window 的具体做法:
- 第一步:先把 window 的位置往右和往下移动 ⌊ M / 2 ⌋ , ⌊ M / 2 ⌋ \lfloor M/2 \rfloor, \lfloor M/2 \rfloor ⌊M/2⌋,⌊M/2⌋
- 第二步:把 window 里边像素不足的 window 进行移动,在每个 window 内部做 mask MHSA 。
- 第三步:将元素移动到原始位置
为什么是 mask 的 MHSA 呢 ?
如下图所示,黄线表示 patch,蓝色粗虚线表示 window,虽然把最左边一列和最上边一行进行移动之后,能凑够四个 window,如下图所示,但其实8/12 和 5/9 是原本没有空间联系的(下图右侧每个红圈内是属于一个空间位置的),所以不能强行计算他们四个元素的 attention,所以作者提出了 mask 的 attention,即计算 8 和其他三个元素的 attention 的时候,计算完attention后,会把5和9对应的权重分别减去100,之后再进行 softmax,该两者对应的权重就为 0 了(-100相比原来的权重来说,是一个非常大的负数,做完softmax 就为0 了)。

Relative position bias:
以每个像素做完基准点来计算其和其他位置的像素的 attention 权重的时候,会给其后面加一个相对位置索引,比如有四个像素点,则总共会有 16 个位置索引组成的 4x4 的相对位置索引的矩阵。
在计算 self-attention 时,作者在每个 head 计算相似度的时候,使用了包含相对位置偏移 B ∈ R M 2 × M 2 B \in R^{M^2\times M^2} B∈RM2×M2 的方法[48,1,31,32]。
![]()
- Q/K/V 分别是 query/key/value
- d 是 query/key 的维度
- M 2 M^2 M2 是window中 patch 的数量
- 由于相对位置的范围为 [-M+1, M+1],所以作者将位置偏移小型化了, B ^ ∈ R ( 2 M − 1 ) × ( 2 M − 1 ) \hat B \in R^{(2M-1)\times (2M-1)} B^∈R(2M−1)×(2M−1)

对于大小为 M 的窗口,其中元素的相对索引其实是在 [-M-1, M+1] 这个范围内,共有 2M-1 个参数可以取,组合之后,就是 ( 2 M − 1 ) × ( 2 M − 1 ) (2M-1)\times (2M-1) (2M−1)×(2M−1)个可取的索引。相对位置偏置表总共也有 ( 2 M − 1 ) × ( 2 M − 1 ) (2M-1)\times (2M-1) (2M−1)×(2M−1) 个元素与可取的索引对应。
作者使用的是单个索引,如果直接相加的话会有很多相同的索引,无法使用,索引作者给所有行、列标加上了 M-1(即1)
3.3 Architecture Variants
作者建立的 base model 叫做 Swin-B,模型大小和 ViT-B/DeiT-B差不多
作者还建立了其他的模型:
- Swin-T:0.25x model size
- Swin-S:0.5x
- Swin-L:2x
不同模型的超参数如下:C 是 first stage 的隐藏层数

Window size: M = 7 M=7 M=7
query dimension of each head: d = 32 d=32 d=32
expansion layer of each MLP: α = 4 \alpha=4 α=4
四、效果

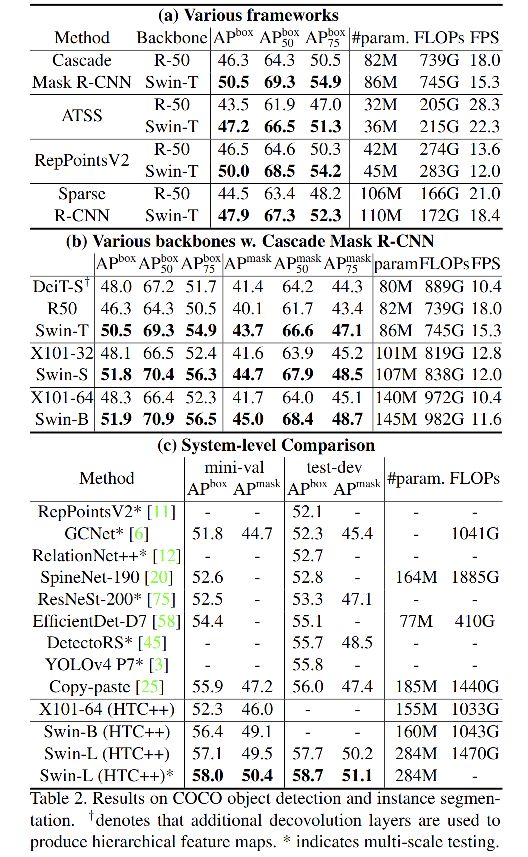
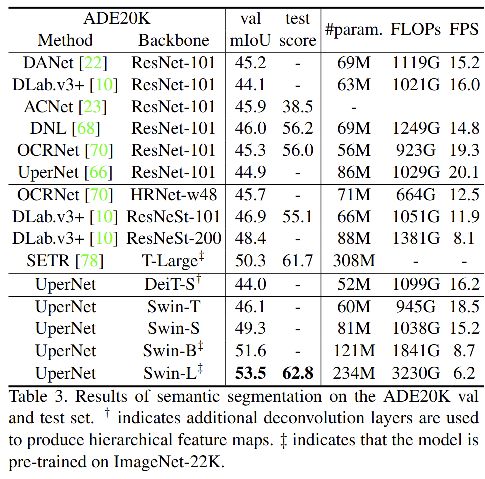
五、代码
使用单GPU训练 Swin-B:
python -m torch.distributed.launch --nproc_per_node 1 --master_port 12345 main.py --eval \
--cfg configs/swin_base_patch4_window7_224.yaml --resume swin_base_patch4_window7_224.pth --data-path <imagenet-path>
如果报错 subprocess.CalledProcessError ,可以改一下 master_port:
python -m torch.distributed.launch --nproc_per_node 2 --master_port 23464 main.py --cfg configs/swin_tiny_patch4_window7_224.yaml --data-path imagenet --batch-size 4
config:
CfgNode({
'BASE': [''],
'DATA': CfgNode({'BATCH_SIZE': 4, 'DATA_PATH': 'imagenet', 'DATASET': 'imagenet', 'IMG_SIZE': 224, 'INTERPOLATION': 'bicubic', 'ZIP_MODE': False, 'CACHE_MODE': 'part', 'PIN_MEMORY': True, 'NUM_WORKERS': 8}),
'MODEL': CfgNode({'TYPE': 'swin', 'NAME': 'swin_tiny_patch4_window7_224', 'RESUME': '', 'NUM_CLASSES': 1000, 'DROP_RATE': 0.0, 'DROP_PATH_RATE': 0.2, 'LABEL_SMOOTHING': 0.1, 'SWIN': CfgNode({'PATCH_SIZE': 4, 'IN_CHANS': 3, 'EMBED_DIM': 96, 'DEPTHS': [2, 2, 6, 2], 'NUM_HEADS': [3, 6, 12, 24], 'WINDOW_SIZE': 7, 'MLP_RATIO': 4.0, 'QKV_BIAS': True, 'QK_SCALE': None, 'APE': False, 'PATCH_NORM': True}),
'SWIN_MLP': CfgNode({'PATCH_SIZE': 4, 'IN_CHANS': 3, 'EMBED_DIM': 96, 'DEPTHS': [2, 2, 6, 2], 'NUM_HEADS': [3, 6, 12, 24], 'WINDOW_SIZE': 7, 'MLP_RATIO': 4.0, 'APE': False, 'PATCH_NORM': True})}),
'TRAIN': CfgNode({'START_EPOCH': 0, 'EPOCHS': 300, 'WARMUP_EPOCHS': 20, 'WEIGHT_DECAY': 0.05, 'BASE_LR': 3.90625e-06, 'WARMUP_LR': 3.90625e-09, 'MIN_LR': 3.90625e-08, 'CLIP_GRAD': 5.0, 'AUTO_RESUME': True, 'ACCUMULATION_STEPS': 0, 'USE_CHECKPOINT': False, 'LR_SCHEDULER': CfgNode({'NAME': 'cosine', 'DECAY_EPOCHS': 30, 'DECAY_RATE': 0.1}),
'OPTIMIZER': CfgNode({'NAME': 'adamw', 'EPS': 1e-08, 'BETAS': (0.9, 0.999), 'MOMENTUM': 0.9})}),
'AUG': CfgNode({'COLOR_JITTER': 0.4, 'AUTO_AUGMENT': 'rand-m9-mstd0.5-inc1', 'REPROB': 0.25, 'REMODE': 'pixel', 'RECOUNT': 1, 'MIXUP': 0.8, 'CUTMIX': 1.0, 'CUTMIX_MINMAX': None, 'MIXUP_PROB': 1.0, 'MIXUP_SWITCH_PROB': 0.5, 'MIXUP_MODE': 'batch'}),
'TEST': CfgNode({'CROP': True}), 'AMP_OPT_LEVEL': 'O1', 'OUTPUT': 'output/swin_tiny_patch4_window7_224/default', 'TAG': 'default', 'SAVE_FREQ': 1, 'PRINT_FREQ': 10, 'SEED': 0, 'EVAL_MODE': False, 'THROUGHPUT_MODE': False, 'LOCAL_RANK': 0})
Swin-B结构:
SwinTransformer(
(patch_embed): PatchEmbed(
(proj): Conv2d(3, 96, kernel_size=(4, 4), stride=(4, 4))
(norm): LayerNorm((96,), eps=1e-05, elementwise_affine=True)
)
(pos_drop): Dropout(p=0.0, inplace=False)
(layers): ModuleList(
(0): BasicLayer(
dim=96, input_resolution=(56, 56), depth=2
(blocks): ModuleList(
(0): SwinTransformerBlock(
dim=96, input_resolution=(56, 56), num_heads=3, window_size=7, shift_size=0, mlp_ratio=4.0
(norm1): LayerNorm((96,), eps=1e-05, elementwise_affine=True)
(attn): WindowAttention(
dim=96, window_size=(7, 7), num_heads=3
(qkv): Linear(in_features=96, out_features=288, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=96, out_features=96, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
(softmax): Softmax(dim=-1)
)
(drop_path): Identity()
(norm2): LayerNorm((96,), eps=1e-05, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=96, out_features=384, bias=True)
(act): GELU()
(fc2): Linear(in_features=384, out_features=96, bias=True)
(drop): Dropout(p=0.0, inplace=False)
)
)
(1): SwinTransformerBlock(
dim=96, input_resolution=(56, 56), num_heads=3, window_size=7, shift_size=3, mlp_ratio=4.0
(norm1): LayerNorm((96,), eps=1e-05, elementwise_affine=True)
(attn): WindowAttention(
dim=96, window_size=(7, 7), num_heads=3
(qkv): Linear(in_features=96, out_features=288, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=96, out_features=96, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
(softmax): Softmax(dim=-1)
)
(drop_path): DropPath()
(norm2): LayerNorm((96,), eps=1e-05, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=96, out_features=384, bias=True)
(act): GELU()
(fc2): Linear(in_features=384, out_features=96, bias=True)
(drop): Dropout(p=0.0, inplace=False)
)
)
)
(downsample): PatchMerging(
input_resolution=(56, 56), dim=96
(reduction): Linear(in_features=384, out_features=192, bias=False)
(norm): LayerNorm((384,), eps=1e-05, elementwise_affine=True)
)
)
(1): BasicLayer(
dim=192, input_resolution=(28, 28), depth=2
(blocks): ModuleList(
(0): SwinTransformerBlock(
dim=192, input_resolution=(28, 28), num_heads=6, window_size=7, shift_size=0, mlp_ratio=4.0
(norm1): LayerNorm((192,), eps=1e-05, elementwise_affine=True)
(attn): WindowAttention(
dim=192, window_size=(7, 7), num_heads=6
(qkv): Linear(in_features=192, out_features=576, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=192, out_features=192, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
(softmax): Softmax(dim=-1)
)
(drop_path): DropPath()
(norm2): LayerNorm((192,), eps=1e-05, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=192, out_features=768, bias=True)
(act): GELU()
(fc2): Linear(in_features=768, out_features=192, bias=True)
(drop): Dropout(p=0.0, inplace=False)
)
)
(1): SwinTransformerBlock(
dim=192, input_resolution=(28, 28), num_heads=6, window_size=7, shift_size=3, mlp_ratio=4.0
(norm1): LayerNorm((192,), eps=1e-05, elementwise_affine=True)
(attn): WindowAttention(
dim=192, window_size=(7, 7), num_heads=6
(qkv): Linear(in_features=192, out_features=576, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=192, out_features=192, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
(softmax): Softmax(dim=-1)
)
(drop_path): DropPath()
(norm2): LayerNorm((192,), eps=1e-05, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=192, out_features=768, bias=True)
(act): GELU()
(fc2): Linear(in_features=768, out_features=192, bias=True)
(drop): Dropout(p=0.0, inplace=False)
)
)
)
(downsample): PatchMerging(
input_resolution=(28, 28), dim=192
(reduction): Linear(in_features=768, out_features=384, bias=False)
(norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
)
(2): BasicLayer(
dim=384, input_resolution=(14, 14), depth=6
(blocks): ModuleList(
(0): SwinTransformerBlock(
dim=384, input_resolution=(14, 14), num_heads=12, window_size=7, shift_size=0, mlp_ratio=4.0
(norm1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)
(attn): WindowAttention(
dim=384, window_size=(7, 7), num_heads=12
(qkv): Linear(in_features=384, out_features=1152, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=384, out_features=384, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
(softmax): Softmax(dim=-1)
)
(drop_path): DropPath()
(norm2): LayerNorm((384,), eps=1e-05, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=384, out_features=1536, bias=True)
(act): GELU()
(fc2): Linear(in_features=1536, out_features=384, bias=True)
(drop): Dropout(p=0.0, inplace=False)
)
)
(1): SwinTransformerBlock(
dim=384, input_resolution=(14, 14), num_heads=12, window_size=7, shift_size=3, mlp_ratio=4.0
(norm1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)
(attn): WindowAttention(
dim=384, window_size=(7, 7), num_heads=12
(qkv): Linear(in_features=384, out_features=1152, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=384, out_features=384, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
(softmax): Softmax(dim=-1)
)
(drop_path): DropPath()
(norm2): LayerNorm((384,), eps=1e-05, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=384, out_features=1536, bias=True)
(act): GELU()
(fc2): Linear(in_features=1536, out_features=384, bias=True)
(drop): Dropout(p=0.0, inplace=False)
)
)
(2): SwinTransformerBlock(
dim=384, input_resolution=(14, 14), num_heads=12, window_size=7, shift_size=0, mlp_ratio=4.0
(norm1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)
(attn): WindowAttention(
dim=384, window_size=(7, 7), num_heads=12
(qkv): Linear(in_features=384, out_features=1152, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=384, out_features=384, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
(softmax): Softmax(dim=-1)
)
(drop_path): DropPath()
(norm2): LayerNorm((384,), eps=1e-05, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=384, out_features=1536, bias=True)
(act): GELU()
(fc2): Linear(in_features=1536, out_features=384, bias=True)
(drop): Dropout(p=0.0, inplace=False)
)
)
(3): SwinTransformerBlock(
dim=384, input_resolution=(14, 14), num_heads=12, window_size=7, shift_size=3, mlp_ratio=4.0
(norm1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)
(attn): WindowAttention(
dim=384, window_size=(7, 7), num_heads=12
(qkv): Linear(in_features=384, out_features=1152, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=384, out_features=384, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
(softmax): Softmax(dim=-1)
)
(drop_path): DropPath()
(norm2): LayerNorm((384,), eps=1e-05, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=384, out_features=1536, bias=True)
(act): GELU()
(fc2): Linear(in_features=1536, out_features=384, bias=True)
(drop): Dropout(p=0.0, inplace=False)
)
)
(4): SwinTransformerBlock(
dim=384, input_resolution=(14, 14), num_heads=12, window_size=7, shift_size=0, mlp_ratio=4.0
(norm1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)
(attn): WindowAttention(
dim=384, window_size=(7, 7), num_heads=12
(qkv): Linear(in_features=384, out_features=1152, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=384, out_features=384, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
(softmax): Softmax(dim=-1)
)
(drop_path): DropPath()
(norm2): LayerNorm((384,), eps=1e-05, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=384, out_features=1536, bias=True)
(act): GELU()
(fc2): Linear(in_features=1536, out_features=384, bias=True)
(drop): Dropout(p=0.0, inplace=False)
)
)
(5): SwinTransformerBlock(
dim=384, input_resolution=(14, 14), num_heads=12, window_size=7, shift_size=3, mlp_ratio=4.0
(norm1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)
(attn): WindowAttention(
dim=384, window_size=(7, 7), num_heads=12
(qkv): Linear(in_features=384, out_features=1152, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=384, out_features=384, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
(softmax): Softmax(dim=-1)
)
(drop_path): DropPath()
(norm2): LayerNorm((384,), eps=1e-05, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=384, out_features=1536, bias=True)
(act): GELU()
(fc2): Linear(in_features=1536, out_features=384, bias=True)
(drop): Dropout(p=0.0, inplace=False)
)
)
)
(downsample): PatchMerging(
input_resolution=(14, 14), dim=384
(reduction): Linear(in_features=1536, out_features=768, bias=False)
(norm): LayerNorm((1536,), eps=1e-05, elementwise_affine=True)
)
)
(3): BasicLayer(
dim=768, input_resolution=(7, 7), depth=2
(blocks): ModuleList(
(0): SwinTransformerBlock(
dim=768, input_resolution=(7, 7), num_heads=24, window_size=7, shift_size=0, mlp_ratio=4.0
(norm1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(attn): WindowAttention(
dim=768, window_size=(7, 7), num_heads=24
(qkv): Linear(in_features=768, out_features=2304, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=768, out_features=768, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
(softmax): Softmax(dim=-1)
)
(drop_path): DropPath()
(norm2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(act): GELU()
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(drop): Dropout(p=0.0, inplace=False)
)
)
(1): SwinTransformerBlock(
dim=768, input_resolution=(7, 7), num_heads=24, window_size=7, shift_size=0, mlp_ratio=4.0
(norm1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(attn): WindowAttention(
dim=768, window_size=(7, 7), num_heads=24
(qkv): Linear(in_features=768, out_features=2304, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=768, out_features=768, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
(softmax): Softmax(dim=-1)
)
(drop_path): DropPath()
(norm2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(act): GELU()
(fc2): Linear(in_features=3072, out_features=768, bias=True)
(drop): Dropout(p=0.0, inplace=False)
)
)
)
)
)
(norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(avgpool): AdaptiveAvgPool1d(output_size=1)
(head): Linear(in_features=768, out_features=1000, bias=True)
)
简化一下就是这个样子的:
SwinTransformer(
(patch_embed): PatchEmbed(
(proj): Conv2d(3, 96, kernel_size=(4, 4), stride=(4, 4))
(norm): LayerNorm((96,), eps=1e-05, elementwise_affine=True))
(pos_drop): Dropout(p=0.0, inplace=False)
(layers): ModuleList(
(0): BasicLayer(dim=96, input_resolution=(56, 56), depth=2
(blocks): ModuleList(
(0): SwinTransformerBlock()
(1): SwinTransformerBlock()
(downsample): PatchMerging())
(1): BasicLayer(dim=192, input_resolution=(28, 28), depth=2
(blocks): ModuleList(
(0): SwinTransformerBlock()
(1): SwinTransformerBlock()
(downsample): PatchMerging())
(2): BasicLayer(dim=384, input_resolution=(14, 14), depth=6
(blocks): ModuleList(
(0): SwinTransformerBlock()
(1): SwinTransformerBlock()
(2): SwinTransformerBlock()
(3): SwinTransformerBlock()
(4): SwinTransformerBlock()
(5): SwinTransformerBlock()
(downsample): PatchMerging())
(3): BasicLayer(dim=768, input_resolution=(7, 7), depth=2
(blocks): ModuleList(
(0): SwinTransformerBlock()
(1): SwinTransformerBlock()))
(norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(avgpool): AdaptiveAvgPool1d(output_size=1)
(head): Linear(in_features=768, out_features=1000, bias=True)
PatchEmbed 结构:
PatchEmbed(
(proj): Conv2d(3, 96, kernel_size=(4, 4), stride=(4, 4))
(norm): LayerNorm((96,), eps=1e-05, elementwise_affine=True)
)
Swin Transformer block 结构:
SwinTransformerBlock(
dim=96, input_resolution=(56, 56), num_heads=3, window_size=7, shift_size=0, mlp_ratio=4.0
(norm1): LayerNorm((96,), eps=1e-05, elementwise_affine=True)
(attn): WindowAttention(
dim=96, window_size=(7, 7), num_heads=3
(qkv): Linear(in_features=96, out_features=288, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=96, out_features=96, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
(softmax): Softmax(dim=-1)
)
(drop_path): Identity()
(norm2): LayerNorm((96,), eps=1e-05, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=96, out_features=384, bias=True)
(act): GELU()
(fc2): Linear(in_features=384, out_features=96, bias=True)
(drop): Dropout(p=0.0, inplace=False)
)
)
class SwinTransformerBlock(nn.Module):
r""" Swin Transformer Block.
Args:
dim (int): Number of input channels.
input_resolution (tuple[int]): Input resulotion.
num_heads (int): Number of attention heads.
window_size (int): Window size.
shift_size (int): Shift size for SW-MSA.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float, optional): Stochastic depth rate. Default: 0.0
act_layer (nn.Module, optional): Activation layer. Default: nn.GELU
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, dim, input_resolution, num_heads, window_size=7, shift_size=0,
mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0., drop_path=0.,
act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.num_heads = num_heads
self.window_size = window_size
self.shift_size = shift_size
self.mlp_ratio = mlp_ratio
if min(self.input_resolution) <= self.window_size:
# if window size is larger than input resolution, we don't partition windows
self.shift_size = 0
self.window_size = min(self.input_resolution)
assert 0 <= self.shift_size < self.window_size, "shift_size must in 0-window_size"
self.norm1 = norm_layer(dim)
self.attn = WindowAttention(
dim, window_size=to_2tuple(self.window_size), num_heads=num_heads,
qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
if self.shift_size > 0:
# calculate attention mask for SW-MSA
H, W = self.input_resolution
img_mask = torch.zeros((1, H, W, 1)) # 1 H W 1
h_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
w_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
cnt = 0
for h in h_slices:
for w in w_slices:
img_mask[:, h, w, :] = cnt
cnt += 1
mask_windows = window_partition(img_mask, self.window_size) # nW, window_size, window_size, 1
mask_windows = mask_windows.view(-1, self.window_size * self.window_size)
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
else:
attn_mask = None
self.register_buffer("attn_mask", attn_mask)
def forward(self, x):
import pdb; pdb.set_trace()
H, W = self.input_resolution # first layer H=W=56
B, L, C = x.shape # [4, 3136, 96]
assert L == H * W, "input feature has wrong size"
shortcut = x
x = self.norm1(x)
x = x.view(B, H, W, C) # [4, 56, 56, 96]
# cyclic shift
if self.shift_size > 0:
shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))
else:
shifted_x = x
# partition windows
x_windows = window_partition(shifted_x, self.window_size) # nW*B, window_size, window_size, C # [256, 7, 7, 96]
x_windows = x_windows.view(-1, self.window_size * self.window_size, C) # nW*B, window_size*window_size, C # [256, 49, 96]
# W-MSA/SW-MSA
attn_windows = self.attn(x_windows, mask=self.attn_mask) # nW*B, window_size*window_size, C # [256, 49, 96]
# merge windows
attn_windows = attn_windows.view(-1, self.window_size, self.window_size, C) # [256, 7, 7, 96]
shifted_x = window_reverse(attn_windows, self.window_size, H, W) # B H' W' C # [4, 56, 56, 96]
# reverse cyclic shift
if self.shift_size > 0:
x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))
else:
x = shifted_x
x = x.view(B, H * W, C) # [4, 3136, 96]
# FFN
x = shortcut + self.drop_path(x)
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
window_partition 结构:切分 window操作
def window_partition(x, window_size):
"""
Args:
x: (B, H, W, C)
window_size (int): window size
Returns:
windows: (num_windows*B, window_size, window_size, C)
"""
B, H, W, C = x.shape # [4, 56, 56, 96]
x = x.view(B, H // window_size, window_size, W // window_size, window_size, C) # [4, 8, 7, 8, 7, 96]
# x.permute(0, 1, 3, 2, 4, 5).shape = [4, 8, 8, 7, 7, 96]
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C) # [256, 7, 7, 96]
return windows
输入尺寸: x.shape = [4, 56, 56, 96]
window_size = 7
经过切分后的尺寸:x.shape = [4, 8, 7, 8, 7, 96]
也就是一组 [56, 56, 96] 的特征图,会被切分成 [64, 7, 7, 96] 的特征图块
window attention 的结构:
WindowAttention(
dim=96, window_size=(7, 7), num_heads=3
(qkv): Linear(in_features=96, out_features=288, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=96, out_features=96, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
(softmax): Softmax(dim=-1)
)
# 以第一层 swin transformer 的特征为例
class WindowAttention(nn.Module):
r""" Window based multi-head self attention (W-MSA) module with relative position bias.
It supports both of shifted and non-shifted window.
Args:
dim (int): Number of input channels.
window_size (tuple[int]): The height and width of the window.
num_heads (int): Number of attention heads.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set
attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
proj_drop (float, optional): Dropout ratio of output. Default: 0.0
"""
def __init__(self, dim, window_size, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.dim = dim
self.window_size = window_size # Wh, Ww
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
# define a parameter table of relative position bias
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)) # 2*Wh-1 * 2*Ww-1, nH
# get pair-wise relative position index for each token inside the window
coords_h = torch.arange(self.window_size[0])
coords_w = torch.arange(self.window_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
self.register_buffer("relative_position_index", relative_position_index)
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
trunc_normal_(self.relative_position_bias_table, std=.02)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x, mask=None):
"""
Args:
x: input features with shape of (num_windows*B, N, C)
mask: (0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None
"""
B_, N, C = x.shape # [256, 49, 96]
# self.qkv(x).shape = [256, 49, 288]
# self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).shape = [256, 49, 3, 3, 32]
qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4) # [3, 256, 3, 49, 32]
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
# q.shape=k.shape=v.shape=[256, 3, 49, 32]
q = q * self.scale
attn = (q @ k.transpose(-2, -1)) # [256, 3, 49, 49]
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # Wh*Ww,Wh*Ww,nH [49, 49, 3]
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww [3, 49, 49]
attn = attn + relative_position_bias.unsqueeze(0)
if mask is not None:
nW = mask.shape[0]
attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
attn = attn.view(-1, self.num_heads, N, N)
attn = self.softmax(attn)
else:
attn = self.softmax(attn)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B_, N, C) # [256, 49, 96]
x = self.proj(x) # [256, 49, 96]
x = self.proj_drop(x)
return x
使用mmsegmentation训练分割网络的时候,要将预训练权重转为mmseg可用的形式,转换方式如下:
python tools/model_converters/swin2mmseg.py \
https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_tiny_patch4_window7_224.pth \
pretrain/swin_tiny_patch4_window7_224.pth