2022CVPR(ToMP):Transforming Model Prediction for Tracking(未完+质量差)
Abstract
背景:基于优化的跟踪方法通过集成目标模型预测模块获得了广泛的成功,其通过最小化目标函数提供有效的全局推理。虽然这种归纳偏差整合了宝贵的领域知识,但它也限制了跟踪网络的表达能力。
本文工作:提出一个基于Transformer模型预测模块的追踪架构。Transformers 以很少的归纳偏差捕获全局关系,使其能够学习更强大的目标模型的预测。进一步,本文扩展这个模型预测器来估计第二组权重,并将这些权重用于准确的边界框回归。
实验结果:在三个数据集上达到SOTA,在LaSOT上实现了68.5%的AUC。
Introduction
问题背景:视觉追踪任务是CV的基础问题之一,其旨在只给定初始目标定位的情况下估计一个视频序列中每一帧的目标定位。其关键问题之一是在给定稀疏的注释下如何学习鲁棒地检测目标。现存的方法中Discriminative Correlation Filters (DCF) 已经实现了巨大的成功,这些方法通过最小化鉴别式目标函数 学习一个目标模型 用于在每一帧中定位目标,其中目标函数常设置为一个卷积核,该卷积核提供跟踪目标紧凑且通用的表达。
DCF和Transformer的对比:DCF中的目标函数继承了先前帧的前景和背景信息,为目标模型的学习提供了有效的全局推理。然而,它也对目标模型造成了严重的归纳偏差,因为目标模型仅通过最小化先前帧的目标获得,使得模型的灵活性很差。比如,它不能在目标模型中集成任何学习到的先验知识。另一方面,Transformer由于自注意力和交叉注意力的使用也在多帧情形中展示了强大的全局推理能力。因此,Transformer已应用于通用对象跟踪,并取得了相当大的成功。
本文工作:提出一个新颖的跟踪框架,其填补了DCF和Transformer之间的空缺。1. 本文使用了一个类似于DCF的紧凑的目标模型用于定位目标,但其权重通过Transformer模型预测器获得,这使得我们可以学习更有利的目标模型。具体地,引入目标状态的新的编码方式,允许Transformer更有效地利用这些信息。2. 进一步,扩展该模型预测器用于生成目标框回归网络的权重。本文相比于基于DCF的方法在跟踪任务上已经获得了巨大的成功。
本文贡献:
- 提出新颖的基于Transformer的模型预测模块以替代传统的基于优化的模型预测器;
- 扩展该模型预测器以估计用于目标框回归的权重;
- 设计了2种新的编码方式,其嵌入了目标定位和目标扩展,以允许基于- Transformer的模型预测器可以利用该信息;
- 提出一个并行的两阶段跟踪过程以解耦目标定位和目标框回归,可以获得更鲁棒和精准的目标检测结果;
- 对算法的每个部分都执行了全面的消融实验。
2. Related Work
2.1 Discriminative Model Prediction
基于DCF的方法通过最小化目标 学习一个目标模型 以从背景中区分出目标。基于长傅里叶变换的求解器在基于 DCF 的跟踪器中占主导地位,如Danelljan 等人采用两层感知器作为目标模型,并使用共轭梯度来解决优化问题。近期,多个方法被引入以将跟踪问题转化为元学习问题来实现端到端训练。这些方法都是基于在固定代数下的迭代优化技术并将其嵌入到跟踪pipeline中用于端到端的训练。Bhat等人学习判别特征空间并根据初始帧中的目标状态预测目标模型的权重,并使用优化算法细化权重。
2.2 Transformers for Tracking
Transformer 通常用于预测判别特征以定位目标对象并回归其边界框。训练特征由Transformer的编码器处理,Transformer的解码器使用交叉注意力融合训练和测试特征来计算判别特征。 (这部分我也不是很理解,训练和测试特征应该指的是搜索区域和目标模板的特征吧)
- DTT:将这些特征提供给预测目标位置和边界框的两个网络;
- TransT:使用包含多个自注意力和交叉注意力的特征混合网络,混合的输出特征送入一个目标分类器和一个边界框回归器中;
- TrDiMP:使用DiMP给定Transformer编码器的输出特征作为训练样本的情况下生成模型权重,之后,目标模型通过将预测权重应用于由Transformer解码器生成的输出特征来计算目标分数。 TrDiMP应用了概率IoUNet用于边界框回归,
- STARK:并非在解码器部分混合训练和测试特征,而是完整的 Transformer对训练和测试特征进行处理。 然后,一个query产生解码器的输出并和编码器的特征混合。这些特征进一步被处理用于直接预测目标的边界框。
3. Method
本文提出一个基于Transformer目标模型预测网络用于追踪问题,称为ToMP。
3.1 Background (看得很懵。。。还是不了解DCF)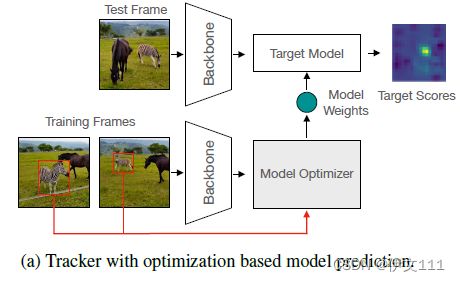
目标跟踪中最流行的范式之一是鉴别式模型预测。这些方法用一个目标模型定位测试帧中的目标。这个目标模型的权重从模型优化器,训练帧及其注释中获得。虽然已有的文献中使用了各种各样的目标模型,但判别跟踪器共享一个共同的基础公式来生成目标模型权重。这其中涉及到优化问题的求解,以使得目标模型产生期望的目标状态。该优化问题如下图所示:
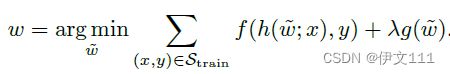 通过显式地优化上图可以学到一个目标模型,能够鲁棒地从先前看到的背景中区分目标。然而,这样的策略有一个很大的缺陷:基于优化的方法计算目标模型只用了先前帧中有限的信息,不能嵌入学到的先验知识来最小化跟踪失败率。类似地,这些方法在计算模型权重以提高跟踪性能时通常缺乏以转换方式利用当前测试帧的可能性。基于优化的方法也需要设置多个优化超参数,易造成过拟合/欠拟合的风险。另外,基于优化的方法产生了鉴别式特征。通常,提供给目标模型的特征只是提取的测试特征,而不是通过使用训练帧中包含的目标状态信息来增强特征。 提取这种增强的特征将允许在测试帧中的目标和背景区域之间进行可靠的区分。
通过显式地优化上图可以学到一个目标模型,能够鲁棒地从先前看到的背景中区分目标。然而,这样的策略有一个很大的缺陷:基于优化的方法计算目标模型只用了先前帧中有限的信息,不能嵌入学到的先验知识来最小化跟踪失败率。类似地,这些方法在计算模型权重以提高跟踪性能时通常缺乏以转换方式利用当前测试帧的可能性。基于优化的方法也需要设置多个优化超参数,易造成过拟合/欠拟合的风险。另外,基于优化的方法产生了鉴别式特征。通常,提供给目标模型的特征只是提取的测试特征,而不是通过使用训练帧中包含的目标状态信息来增强特征。 提取这种增强的特征将允许在测试帧中的目标和背景区域之间进行可靠的区分。
3.2 Transformer-based Target Model Prediction
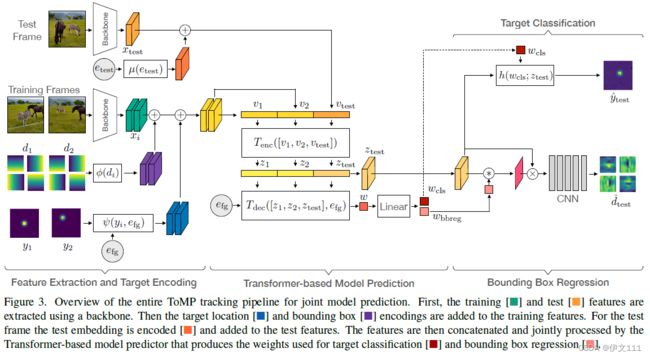
为了克服以上缺陷,本文用基于Transformer的目标模型预测器替代模型优化器。而不是显式地优化等式1,本文学习通过端到端的训练直接预测目标模型,这允许模型预测器在预测模型中整合目标特定先验,以便它可以专注于目标的特征,以及允许将目标与所见背景区分开来的特征。进一步,我们的模型预测器也使用了当前检测帧的特征,和先前训练的特征,以一种transductive的方法预测目标模型。因此,模型预测器可以使用当前帧信息去预测一个更合适的目标模型。最后,不是在一个固定特征空间中应用目标模型,本文利用目标信息对每一帧动态地创建一个更鉴别式地特征空间。下图展示了本文提出的框架。
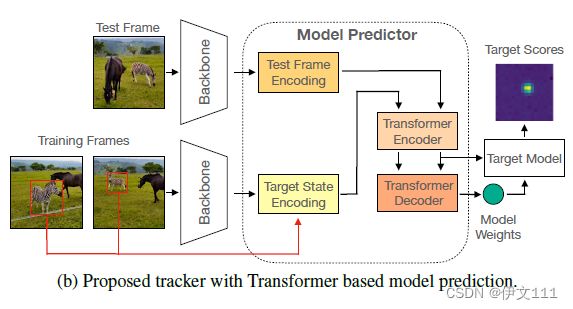
ToMP:包含一个测试和一个训练分支。先编码训练帧中的目标状态信息并和深度图像特征混合。类似地也对测试帧添加编码,将来自测试和训练分支的特征联合输入Transformer编码器中以通过帧间全局推理生成增强特征。接下来,Transformer解码器通过Transformer编码器的输出预测目标模型权重。最后,预测的目标模型被应用于增强测试帧特征中以定位目标。
3.2.1 Target Location Encoding
本文提出了一种目标定位编码,使得模型预测器融入来自训练帧的目标状态信息。具体地,使用嵌入e_{fg}表示前景foreground,高斯分布y_i表示目标定位的中心,等式2展示了目标编码函数:
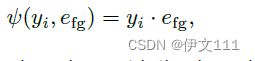 此外,H_{im}=sH, W_{im}=sW定义图像patch的空间维度,s指用于提取深度特征的backbone的步幅。接下来,我们联合目标编码和深度图像特征x:
此外,H_{im}=sH, W_{im}=sW定义图像patch的空间维度,s指用于提取深度特征的backbone的步幅。接下来,我们联合目标编码和深度图像特征x:
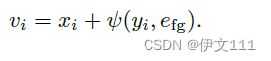 v_i即训练帧特征,其包含了编码的目标状态信息。类似地,本文也添加了一个测试编码以识别对应的测试帧特征:
v_i即训练帧特征,其包含了编码的目标状态信息。类似地,本文也添加了一个测试编码以识别对应的测试帧特征:
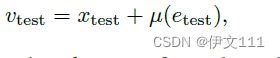
其中\miu指对x_{test}的每个patch的token
3.2.2 Transformer Encoder(和STARK的做法相同)
Transformer编码器先联合处理训练帧和测试帧的特征,其有2个功能:1. 计算即将用于解码器的特征;2. 受到STARK的启发,Transformer编码器计算增强的测试帧特征,在定位目标时用作目标模型的输入。
具体做法:给定多个编码的训练特征v_i,一个编码的测试特征v_{test},reshape这些特征(即flat)并沿着第一个维度concatenate所有v_i特征和v_{test},这些特征通过一个Transformer编码器处理,包含多头自注意力模块。此外,编码后的目标状态识别前景和背景区域,并使 Transformer 能够区分这两个区域。
![]()
Transformer编码器的输出记为z_i和z_{test}
3.2.2 Transformer Decoder
z_i和z_{test}用于Transformer解码器的输入来预测目标模型权重
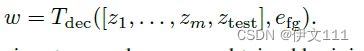
本文使用与目标状态编码相同的前景嵌入 e_{fg} 作为 Transformer 解码器的输入查询,以便解码器预测目标模型权重。
3.2.3 Target Model
本文使用DCF目标模型来获得目标分类分数:
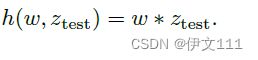
其中,卷积核的权重w由Transformer解码器预测。注意到,目标模型是被应用于z_{test}上的。这些特征是在训练和测试帧联合处理后获得的,从而支持目标模型可靠地定位目标。
3.3 Joint Localization and Box Regression
尽管目标模型可以定位每一帧的目标中心,追踪器还是要估计目标的边界框。基于 DCF 的跟踪器通常为此任务使用专用的边界框回归网络 。 虽然可以遵循类似的策略,但本文还是决定联合预测这两个模型,因为目标定位和边界框回归是相互受益的相关任务。
首先,本文不仅在生成目标状态编码时使用目标中心位置,还对目标大小信息进行编码,以为我们的模型预测器提供更丰富的输入。 其次,除了目标模型权重之外,我们扩展了我们的模型预测器来估计边界框回归网络的权重。 生成的跟踪架构在下图中可视化。
3.3.1 Target Extent Encoding
除了提取的深度图像特征x_i和目标定位编码\fai(y_i, e_{fg})外,本文还添加了其他的编码以嵌入关于目标边界框的信息。
首先,将特征图x_i的每个位置(j^x, j^y)映射回图像域使用下面的公式:
![]()
然后,计算每个映射位置和边界框四个边的归一化距离:
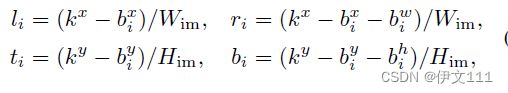
用这种表达,本文使用多层感知器对边界框进行编码,从而在将获得的编码将维数从 4 增加到 C。
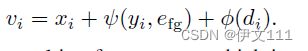
3.3.2 Model Prediction
将Transformer解码器的输出w通过一个线性层以获得边界框回归的权重w_{bbreg}和w_{cls}
3.3.3 Bounding Box Regression
为了使编码器输出z_{test}是目标感知的,本文沿用Yan等人的做法,先计算一个注意力图w_{bbreg}*z_{test}。注意力权重然后和z_{test}点乘,再输入一个CNN中。CNN的最后一层用了一个指数激活函数以预测归一化的目标框。为了获得最终边界框的估计,先通过argmax函数再目标分数图y_{test}上提取中心位置。接下来,query稠密的便加框预测d_{test}在目标的中心上以获得边界框。与 Yan 等人相比,本文使用两个专用网络进行目标定位和边界框回归,它使用一个网络试图预测两者,在跟踪过程中将目标定位与边界框回归解耦。
3.4 Offline Training
损失函数:从一个视频序列中采样多个训练和测试帧构成训练子序列。类似于基于DCF的跟踪器,对训练和测试帧保持同样的空间分辨率。我们将每个图像I_i与边界框b_i对应。使用训练帧的目标状态编码目标信息并使用测试帧的边界框通过计算2个损失去监督训练过程,这2个损失是基于预测边界框和目标的中心位置。
本文使用来自DiMP的目标分类损失,进一步,使用 ltrb 边界框表示来使用广义的 Intersection over Union loss 来监督边界框回归。
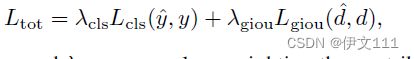
训练细节:训练集:LaSOT, GOt10k, Trackingnet, MS-COCO。采样了40k个子序列并在2个Nvidia Titan RTX GPUs上训练了300个Epoch。
ADAMW优化器,初始lr=0.0001,150和250个epochs后衰减0.2,weight decay=0.0001。
\lambda_{cls}=100, \lambda_{giou}=1。
子序列的构建:在一个视频序列内从200帧的窗口内随机采样2个训练帧和一个测试帧,然后在相对于目标边界框随机平移和缩放图像后提取图像patch。
数据增强:随机反转和颜色抖动。
将目标分数的空间分辨率设置为 18x18,并将搜索区域比例因子设置为 5.0。
3.5 Online Tracking
在追踪的过程中,本文使用了标注的第一帧和先前追踪过的帧作为训练集S_train。与此同时,永久保持第一帧及其注释,包括一个先前跟踪的帧,并将其替换为实现高于阈值的目标分类器置信度的最新帧。因此,训练集S_train中至少有2帧。
我们观察到,将先前的跟踪结果综合到 S_train 中可以显着改善目标定位效果。但由于预测的不准确,综合预测的边界框估计会降低边界框回归性能。因此,本文运行模型预测器2次。1)综合S_train的中间预测以获得分类器权重;2)只用第一帧的注释来预测边界框。为了提高效率,这两个步骤可以在一次前向传递中并行执行。具体地,reshape两个训练和一个测试帧的特征图为一个序列并复制它。 然后,将两者在batch维度堆叠用模型预测器一起处理它们。为了在预测边界框回归时只允许初始帧和测试帧之间的注意力,使用了key_padding_mask来允许忽视某些keys。
4. Experiments
7个数据集。速度:
| ToMP-101 | ToMP-50 |
|---|---|
| ResNet-101 | ResNet-50 |
| single Nvidia RTX 2080Ti GPU | single Nvidia RTX 2080Ti GPU |
| 19.6FPS | 24.8 FPS |
4.1 Ablation Study
所有的消融实验都用ResNet-50作为backbone。
Target State Encoding:
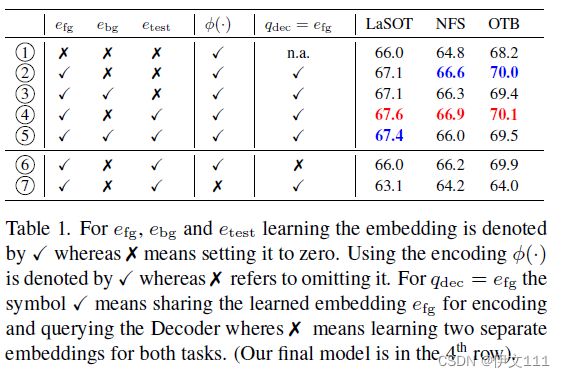
Model Predictor:
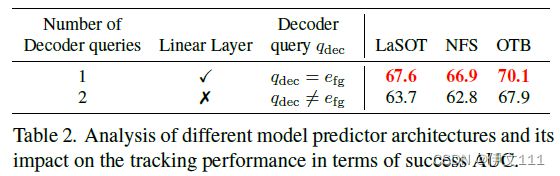
Inference Settings:
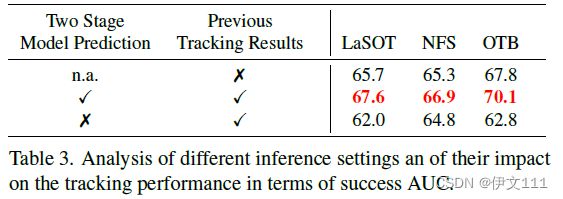
Transforming Model Prediction Step-by-Step:
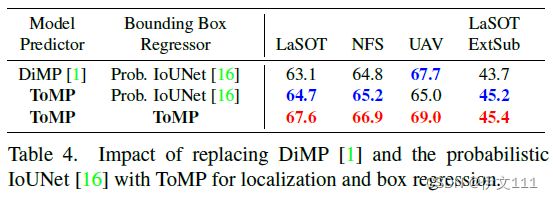
4.2 Comparison to the State of the Art
4.2.1 LaSOT
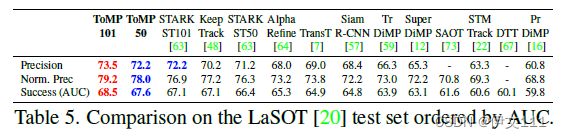
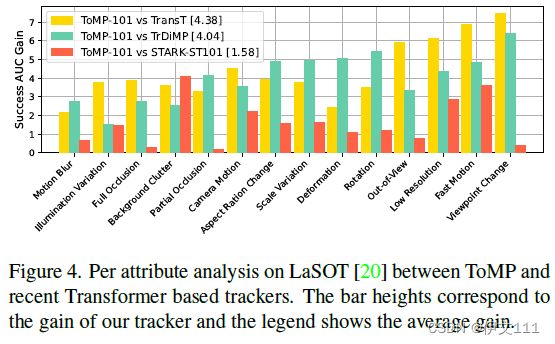
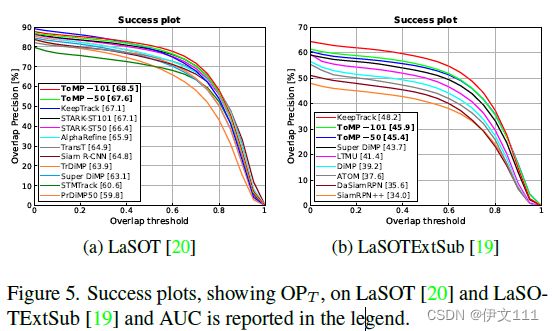
4.2.2 LaSOTExtSub
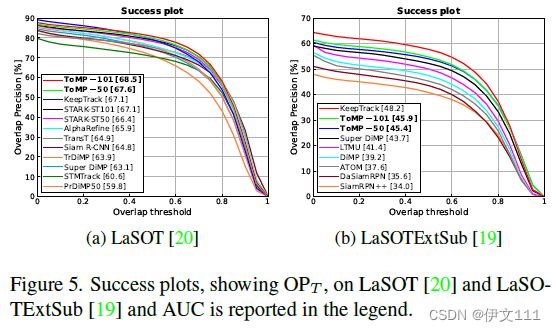
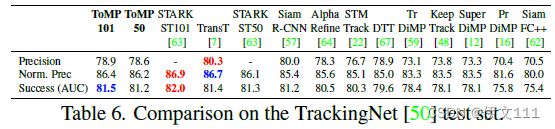
4.2.3 TrackingNet
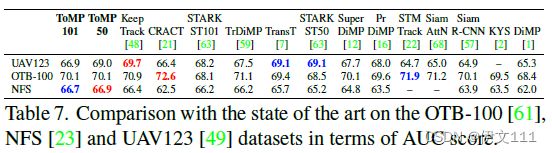
4.2.4 UAV123
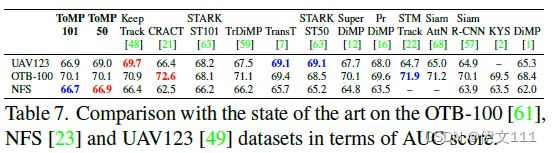
4.2.5 OTB-100
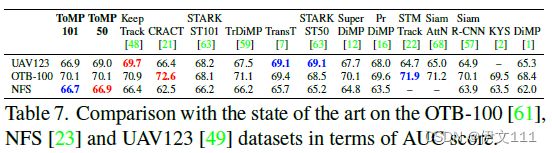
4.2.6 NFS
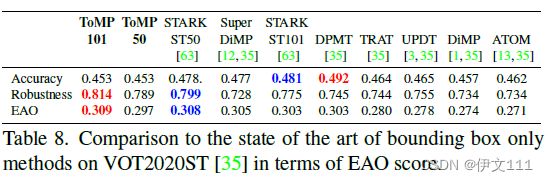
4.2.7 VOT2020
4.3 Limitations
Transformer 编码器由自注意力层组成,这些层计算多个训练和测试帧特征之间的相似性矩阵,因此会导致影响训练和推理运行时间的大量内存占用。 因此,在未来的工作中,应该旨在减少内存负担的替代方案来解决这一限制。 ToMP 的另一个限制因素来自具有挑战性的跟踪序列。 特别是,目标被遮挡时出现的干扰物是 ToMP 的典型失败场景,因为它缺乏像 KeepTrack中那样明确的干扰物处理。