CascadePSP:解决4K超高分辨率图像的分割,简单实用 | CVPR2020
点击上方“AI算法修炼营”,选择“星标”公众号
精选作品,第一时间送达

本文是一篇关于精细化语义分割边界的文章,主要提出了一种无需使用任何高分辨率训练数据即可解决高分辨率分割问题的新颖方法。网络中使用级联的结构,其中全局步骤可分割整个图像,并为后续的局部步骤提供足够的图像上下文以执行全分辨率高质量分割。整体思路巧妙,看好其应用价值。
论文地址:https://arxiv.org/pdf/1909.03402.pdf
代码地址:https://github.com/hkchengrex/CascadePSP
最先进的语义分割方法几乎只针对固定分辨率范围内的图像进行训练。这些分割对于非常高分辨率的图像来说是不准确的,因为使用 bicubic 上采样的低分辨率分割方法不能充分捕捉沿物体边界的高分辨率细节。在本文中,提出了一种无需使用任何高分辨率训练数据即可解决高分辨率分割问题的新颖方法——Cascade PSP网络,该网络会在可能的情况下完善和纠正局部边界。尽管该网络是用低分辨率分割数据训练的,但即使对于大于4K的高分辨率图像也同样适用。经过在不同的数据集上进行定量和定性研究,实验表明CascadePSP可以在不进行任何微调的情况下分割出像素精确的分割边界。
简介
随着4K UHD(3840×2160)成为新的行业标准,商用相机和显示器的分辨率已显着提高。尽管对高分辨率媒体有需求,但是许多先进的计算机视觉算法在具有高像素数量的图像方面仍面临各种挑战。图像语义分割是这些计算机视觉任务之一,针对低分辨率图像(例如PASCAL或COCO数据集)设计的深度学习语义分割模型通常无法推广到更高分辨率的场景。具体来说,这些模型通常使用与像素数成线性关系的GPU内存,因此实际上不可能直接训练4K UHD高分辨率图像。同时,由于高分辨率图像的标注困难,导致训练所需的数据难以获取。目前,解决4K分辨率的图像的分割主要手段有下采样和剪裁两种,但是下采样消除了细节信息,而剪裁则破坏了图像的上下文信息。
本文提出的CascadePSP,是一种通用的精细化分割优化模型,可将任何给定的图像的分割效果从低分辨率细化为高分辨率。该模型经过独立训练,可以轻松地附加到任何现有方法中以改善其分割效果,从而可以生成对象的更精细,更准确的分割mask。同时,该模型将初始mask作为输入,该mask可以是由任何算法输出的粗略结果。然后,CascadePSP将输出精细化的mask。

为了对非常高分辨率的图像进行评估,首先为高分辨率数据集添加了标注,该数据集具有50个验证对象和100个测试对象,并具有与PASCAL中相同的语义类别,称为BIG数据集。最终在PASCALVOC 2012,BIG和ADE20K数据集上测试了模型。实验证明,不必针对特定数据集或特定模型的输出来训练CascadePSP的模型,相反,通过干扰ground truth来执行数据扩充就足够了。CascadePSP模型还可以扩展为具有直接适应的密集多类语义分割的场景解析任务。
本文方法:CascadePSP
1、Refinement Module

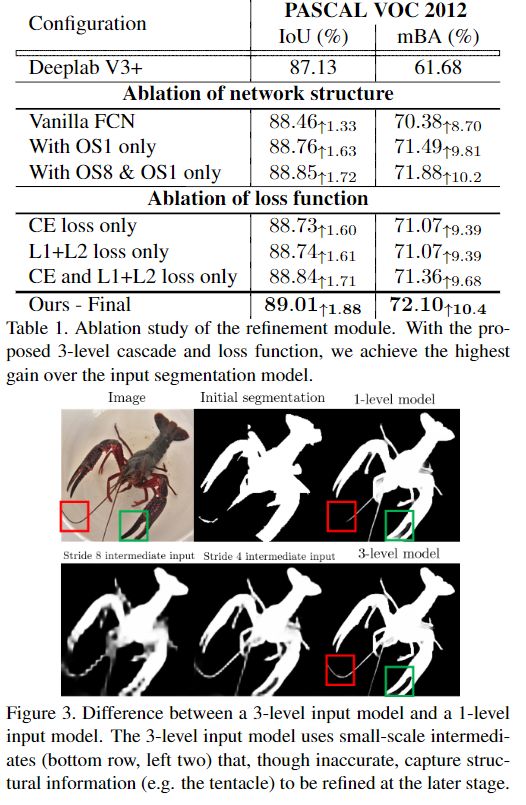
如图2所示,优化模块用不同的比例拍摄图像和多个不完美的分割mask来生成精确的分割。 多尺度输入使模型能够捕获不同层次的结构和边界信息,使网络能够学习自适应地融合不同尺度的mask特征,在最精细的层次上完善分割。
所有较低分辨率的输入分割均被双线性上采样为相同大小,并与RGB图像连接在一起。使用ResNet-50作为主干网络的PSPNet来从输入中提取步长为8的特征图。其中金字塔池化大小为[1,2,3,6],这有助于捕获全局上下文。除了最终的OS 1输出之外,模型还生成了OS 8和OS 4的分割结果,并跳过OS 2来提供纠正局部错误边界的灵活性。(OS指输出特征图的分辨率与输入图像分辨率的比值)
为了重建在提取过程中丢失的像素级图像细节,采用了来自主干网络的skip connection,并使用上采样模块融合了特征。将skip分支的特征和来自主干分支的双线性上采样的特征连接起来,并使用两个ResNet块对其进行处理。使用2层1×1conv生成分割输出,然后进行sigmoid函数激活。
损失函数
对于较粗糙的OS 8,使用交叉熵损失,对于较精细的OS 1,使用L1 + L2损失,对于OS 4,使用交叉熵和L1 + L2损失的平均值,可以得出最佳结果。为了进行更好的边界细化,在OS 1上还采用了分段梯度幅度上的L1损失。分割梯度由一个3×3均值滤波器和Sobel算子组成。
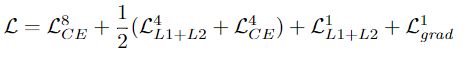

其中fm(·)表示3×3均值滤波器,∇表示由Sobel算子近似的梯度算子。
消融实验
为了强调边界精度的感知重要性,提出了一种新的评价指标mean Boundary Accuracy (mBA)。
class RefinementModule(nn.Module):
def __init__(self):
super().__init__()
self.feats = extractors.resnet50()
self.psp = PSPModule(2048, 1024, (1, 2, 3, 6))
self.up_1 = PSPUpsample(1024, 1024+256, 512)
self.up_2 = PSPUpsample(512, 512+64, 256)
self.up_3 = PSPUpsample(256, 256+3, 32)
self.final_28 = nn.Sequential(
nn.Conv2d(1024, 32, kernel_size=1),
nn.ReLU(inplace=True),
nn.Conv2d(32, 1, kernel_size=1),
)
self.final_56 = nn.Sequential(
nn.Conv2d(512, 32, kernel_size=1),
nn.ReLU(inplace=True),
nn.Conv2d(32, 1, kernel_size=1),
)
self.final_11 = nn.Conv2d(32+3, 32, kernel_size=1)
self.final_21 = nn.Conv2d(32, 1, kernel_size=1)
def forward(self, x, seg, inter_s8=None, inter_s4=None):
images = {}
"""
First iteration, s8 output
"""
if inter_s8 is None:
p = torch.cat((x, seg, seg, seg), 1)
f, f_1, f_2 = self.feats(p)
p = self.psp(f)
inter_s8 = self.final_28(p)
r_inter_s8 = F.interpolate(inter_s8, scale_factor=8, mode='bilinear', align_corners=False)
r_inter_tanh_s8 = torch.tanh(r_inter_s8)
images['pred_28'] = torch.sigmoid(r_inter_s8)
images['out_28'] = r_inter_s8
else:
r_inter_tanh_s8 = inter_s8
"""
Second iteration, s8 output
"""
if inter_s4 is None:
p = torch.cat((x, seg, r_inter_tanh_s8, r_inter_tanh_s8), 1)
f, f_1, f_2 = self.feats(p)
p = self.psp(f)
inter_s8_2 = self.final_28(p)
r_inter_s8_2 = F.interpolate(inter_s8_2, scale_factor=8, mode='bilinear', align_corners=False)
r_inter_tanh_s8_2 = torch.tanh(r_inter_s8_2)
p = self.up_1(p, f_2)
inter_s4 = self.final_56(p)
r_inter_s4 = F.interpolate(inter_s4, scale_factor=4, mode='bilinear', align_corners=False)
r_inter_tanh_s4 = torch.tanh(r_inter_s4)
images['pred_28_2'] = torch.sigmoid(r_inter_s8_2)
images['out_28_2'] = r_inter_s8_2
images['pred_56'] = torch.sigmoid(r_inter_s4)
images['out_56'] = r_inter_s4
else:
r_inter_tanh_s8_2 = inter_s8
r_inter_tanh_s4 = inter_s4
"""
Third iteration, s1 output
"""
p = torch.cat((x, seg, r_inter_tanh_s8_2, r_inter_tanh_s4), 1)
f, f_1, f_2 = self.feats(p)
p = self.psp(f)
inter_s8_3 = self.final_28(p)
r_inter_s8_3 = F.interpolate(inter_s8_3, scale_factor=8, mode='bilinear', align_corners=False)
p = self.up_1(p, f_2)
inter_s4_2 = self.final_56(p)
r_inter_s4_2 = F.interpolate(inter_s4_2, scale_factor=4, mode='bilinear', align_corners=False)
p = self.up_2(p, f_1)
p = self.up_3(p, x)
"""
Final output
"""
p = F.relu(self.final_11(torch.cat([p, x], 1)), inplace=True)
p = self.final_21(p)
pred_224 = torch.sigmoid(p)
images['pred_224'] = pred_224
images['out_224'] = p
images['pred_28_3'] = torch.sigmoid(r_inter_s8_3)
images['pred_56_2'] = torch.sigmoid(r_inter_s4_2)
images['out_28_3'] = r_inter_s8_3
images['out_56_2'] = r_inter_s4_2
return images
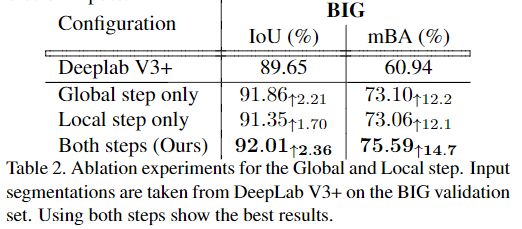
2、Global and Local Cascade Refinement
在测试中,使用全局步骤和局部步骤通过采用相同的优化模块来执行高分辨率分割优化。具体来说,“全局”步骤考虑将整个调整大小后的图像用于修复结构,而“局部”步骤则使用图像裁剪以全分辨率优化细节。可以将相同的优化模块递归用于更高分辨率的优化。
Global Step

图4详细介绍了Global步骤的设计,该步骤使用3级级联优化整个图像。由于测试过程中的全分辨率图像通常无法放入GPU进行处理,因此首先对输入进行降采样,以使较长的轴具有L长度的同时保持相同的纵横比。
级联的输入使用input segmentation进行初始化,并进行复制以保持输入通道尺寸固定。在级联的第一级之后,其中一个输入通道将被双线性向上采样的粗略输出代替。重复此操作直到最后一级,其中输入既包含初始的分割结果,也包含来自先前级别的所有输出。
此设计使网络能够逐步修复分割的错误,同时保留初始分割结果中的详细信息。使用多个层次,可以粗略地勾画出对象,并在粗略层次中修复较大的误差,同时使用粗略层次提供的更强大的特征。这使得整个网络专注于精细层次的边界精度。
Local Step
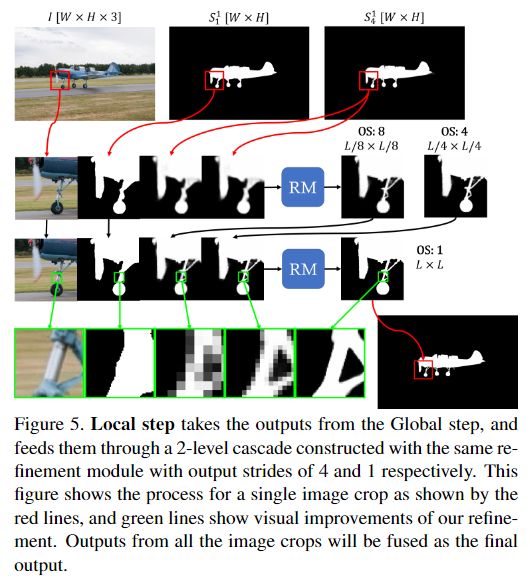
图5说明了Local步骤的细节。由于内存的限制,即使使用GPU,也无法单次处理非常高分辨率的图像。而且,训练数据和测试数据之间规模的急剧变化将导致分割质量变差。因此,本文利用级联模型首先使用降采样后的图像执行全局优化,然后使用来自高分辨率图像的图像裁剪执行局部优化。这些剪裁使Local步骤能够在不考虑高分辨率训练数据的情况下处理高分辨率图像,同时Global步骤能够将图像上下文考虑在内。
在局部步骤中,模型采用全局步骤最后一级的两个输出,两个输出均被线性调整为图像的原始尺寸W×H。模型对图像进行尺寸为L×L的裁剪,裁剪输出的每边将被削去16个像素,以避免边界伪影,但图像边界处有例外。裁剪的步幅统一为L/2-32,这样大部分像素被4个裁剪覆盖,超出图像边界的无效裁剪被移位到与图像的最后一行/一列对齐。然后将图像裁剪送入2级级联,步幅分别为4和1。在融合过程中,由于图像上下文不同,不同补丁的输出可能会有差异,我们通过对所有输出值进行平均来解决这个问题。 对于分辨率更高的图像,可以采用从粗到细的方式递归应用局部步骤。
L的选择

消融实验

def resize_max_side(im, size, method):
h, w = im.shape[-2:]
max_side = max(h, w)
ratio = size / max_side
if method in ['bilinear', 'bicubic']:
return F.interpolate(im, scale_factor=ratio, mode=method, align_corners=False)
else:
return F.interpolate(im, scale_factor=ratio, mode=method)
def safe_forward(model, im, seg, inter_s8=None, inter_s4=None):
"""
Slightly pads the input image such that its length is a multiple of 8
"""
b, _, ph, pw = seg.shape
if (ph % 8 != 0) or (pw % 8 != 0):
newH = ((ph//8+1)*8)
newW = ((pw//8+1)*8)
p_im = torch.zeros(b, 3, newH, newW, device=im.device)
p_seg = torch.zeros(b, 1, newH, newW, device=im.device) - 1
p_im[:,:,0:ph,0:pw] = im
p_seg[:,:,0:ph,0:pw] = seg
im = p_im
seg = p_seg
if inter_s8 is not None:
p_inter_s8 = torch.zeros(b, 1, newH, newW, device=im.device) - 1
p_inter_s8[:,:,0:ph,0:pw] = inter_s8
inter_s8 = p_inter_s8
if inter_s4 is not None:
p_inter_s4 = torch.zeros(b, 1, newH, newW, device=im.device) - 1
p_inter_s4[:,:,0:ph,0:pw] = inter_s4
inter_s4 = p_inter_s4
images = model(im, seg, inter_s8, inter_s4)
return_im = {}
for key in ['pred_224', 'pred_28_3', 'pred_56_2']:
return_im[key] = images[key][:,:,0:ph,0:pw]
del images
return return_im
def process_high_res_im(model, im, seg, L=900):
stride = L//2
_, _, h, w = seg.shape
"""
Global Step
"""
if max(h, w) > L:
im_small = resize_max_side(im, L, 'area')
seg_small = resize_max_side(seg, L, 'area')
elif max(h, w) < L:
im_small = resize_max_side(im, L, 'bicubic')
seg_small = resize_max_side(seg, L, 'bilinear')
else:
im_small = im
seg_small = seg
images = safe_forward(model, im_small, seg_small)
pred_224 = images['pred_224']
pred_56 = images['pred_56_2']
"""
Local step
"""
for new_size in [max(h, w)]:
im_small = resize_max_side(im, new_size, 'area')
seg_small = resize_max_side(seg, new_size, 'area')
_, _, h, w = seg_small.shape
combined_224 = torch.zeros_like(seg_small)
combined_weight = torch.zeros_like(seg_small)
r_pred_224 = (F.interpolate(pred_224, size=(h, w), mode='bilinear', align_corners=False)>0.5).float()*2-1
r_pred_56 = F.interpolate(pred_56, size=(h, w), mode='bilinear', align_corners=False)*2-1
padding = 16
step_size = stride - padding*2
step_len = L
used_start_idx = {}
for x_idx in range((w)//step_size+1):
for y_idx in range((h)//step_size+1):
start_x = x_idx * step_size
start_y = y_idx * step_size
end_x = start_x + step_len
end_y = start_y + step_len
# Shift when required
if end_y > h:
end_y = h
start_y = h - step_len
if end_x > w:
end_x = w
start_x = w - step_len
# Bound x/y range
start_x = max(0, start_x)
start_y = max(0, start_y)
end_x = min(w, end_x)
end_y = min(h, end_y)
# The same crop might appear twice due to bounding/shifting
start_idx = start_y*w + start_x
if start_idx in used_start_idx:
continue
else:
used_start_idx[start_idx] = True
# Take crop
im_part = im_small[:,:,start_y:end_y, start_x:end_x]
seg_224_part = r_pred_224[:,:,start_y:end_y, start_x:end_x]
seg_56_part = r_pred_56[:,:,start_y:end_y, start_x:end_x]
# Skip when it is not an interesting crop anyway
seg_part_norm = (seg_224_part>0).float()
high_thres = 0.9
low_thres = 0.1
if (seg_part_norm.mean() > high_thres) or (seg_part_norm.mean() < low_thres):
continue
grid_images = safe_forward(model, im_part, seg_224_part, seg_56_part)
grid_pred_224 = grid_images['pred_224']
# Padding
pred_sx = pred_sy = 0
pred_ex = step_len
pred_ey = step_len
if start_x != 0:
start_x += padding
pred_sx += padding
if start_y != 0:
start_y += padding
pred_sy += padding
if end_x != w:
end_x -= padding
pred_ex -= padding
if end_y != h:
end_y -= padding
pred_ey -= padding
combined_224[:,:,start_y:end_y, start_x:end_x] += grid_pred_224[:,:,pred_sy:pred_ey,pred_sx:pred_ex]
del grid_pred_224
# Used for averaging
combined_weight[:,:,start_y:end_y, start_x:end_x] += 1
# Final full resolution output
seg_norm = (r_pred_224/2+0.5)
pred_224 = combined_224 / combined_weight
pred_224 = torch.where(combined_weight==0, seg_norm, pred_224)
_, _, h, w = seg.shape
images = {}
images['pred_224'] = F.interpolate(pred_224, size=(h, w), mode='bilinear', align_corners=True)
return images['pred_224']
def process_im_single_pass(model, im, seg, L=900):
"""
A single pass version, aka global step only.
"""
_, _, h, w = im.shape
if max(h, w) < L:
im = resize_max_side(im, L, 'bicubic')
seg = resize_max_side(seg, L, 'bilinear')
if max(h, w) > L:
im = resize_max_side(im, L, 'area')
seg = resize_max_side(seg, L, 'area')
images = safe_forward(model, im, seg)
if max(h, w) < L:
images['pred_224'] = F.interpolate(images['pred_224'], size=(h, w), mode='area')
elif max(h, w) > L:
images['pred_224'] = F.interpolate(images['pred_224'], size=(h, w), mode='bilinear', align_corners=True)
return images['pred_224']
实验与结果
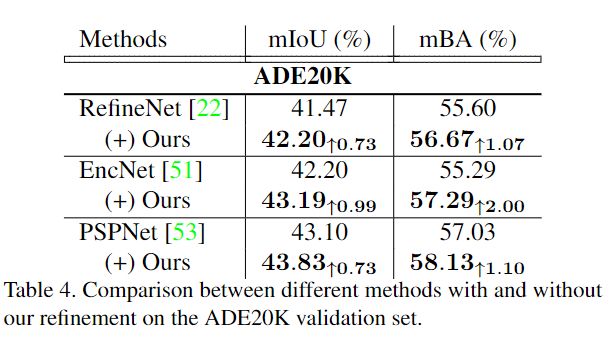
数据集: PASCAL VOC 2012 , BIG (our high-resolutiondata set), ADE20K
评价指标:mIoU、mBA
Baseline:PSPNet with ResNet-50
训练方法:在训练过程中,随机抽取224×224个图像crop,并通过扰动ground truth来生成输入分割。具体扰动方法如下图所示:

实验效果


对比实验


更多实验细节,可以参考原文。

