循环神经网络(二)——LSTM
1. 为什么需要LSTM
普通RNN的信息不能长久传播(存在于理论上)。 ,输入x会稀释掉状态s,故其信息不能长久的传播。
2. LSTM中引入了什么
2.1 选择性机制
- 选择性输入
- 选择性遗忘
- 选择性输出
-
2.2 实现选择性机制的方法
-
2.2.1 门——> sigmoid 函数
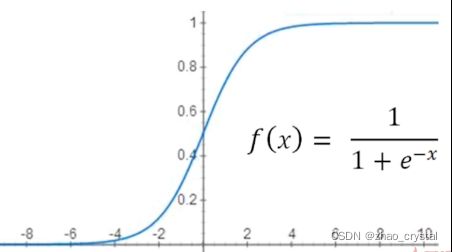
2.2.2 门限机制
向量A——>sigmoid ——>[0.1, 0.9, 0.4, 0, 0.6]
向量B——>[13.8, 14, -7, -4, 30.0]
A为门限,B为信息
A * B = [0.138, 12.6, -2.8, 0, 18.0](通过门限,对B的信息做一些选择,可以把值的大小,当作包含信息的大小)
3 LSTM模型结构

三个门:遗忘门,传入门,输出门
两个状态:Ct,ht
3.1 cell的状态传递
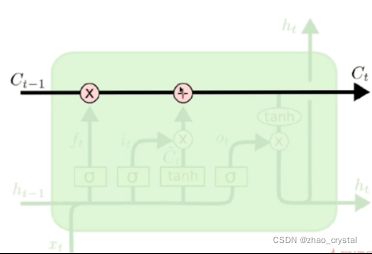
3.2 遗忘门

ft决定ct-1中哪些东西需要被遗忘。
eg:新的一句有新的主语,就应该把之前的主语忘掉
3.3 传入门
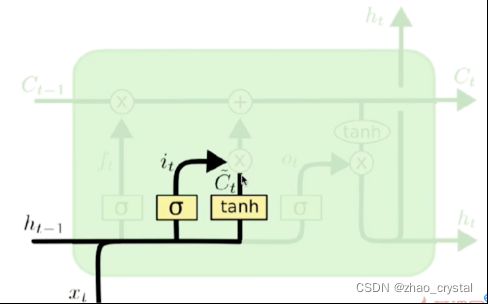
Ct波浪,表示从输入中得到的信息;it是门限,控制有多少信息可以保存下来。
eg:是不是要把主语的性别信息添加进来
3.4 输出门
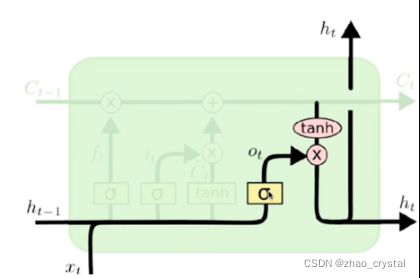
Ct的哪些信息可以输出出来。
eg:比如下一个词是动词,除了预测这个动词之外,还要加其是单数或者是负数的信息(动词该用单数还是复数?)
3.5 当前状态
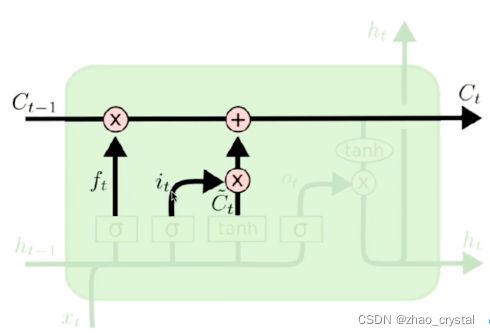
经过遗忘门的上一状态;
经过传入门的输入状态
4.实战
4.1 文本分类
该文本分类把如下代码中的SimpleRNN 改为LSTM即可2.4.1文本分类 https://blog.csdn.net/zhao_crystal/article/details/123319419?spm=1001.2014.3001.5501#t23
https://blog.csdn.net/zhao_crystal/article/details/123319419?spm=1001.2014.3001.5501#t23
4.2 文本生成
该文本分类把如下代码中的SimpleRNN 改为LSTM
2.4.2文本生成https://blog.csdn.net/zhao_crystal/article/details/123319419?spm=1001.2014.3001.5501#t24需做如下调整
4.2.1 需要调节LSTM接口的两个参数
stateful:Boolean (default False). If True, the last state for each sample at index i in a batch will be used as initial state for the sample of index i in the following batch.
recurrent_initializer:Initializer for the recurrent_kernel weights matrix, used for the linear transformation of the recurrent state. Default: orthogonal.
# 调参:新加两个参数 stateful, recurrent_initializer
keras.layers.LSTM(units = run_units,
stateful = True,
recurrent_initializer = 'glorot_uniform',
return_sequences = True),4.2.2 使logistic更greedy
令predictions乘以某个小于1的数temperature,使得predictions分布更集中,数据更greedy。 temperature > 1, predictions的分布更均匀,即数据更随机,random
temperature < 1, predictions的分布更集中,greddy
predictions:logits ——> softmax ——> prob
softmax: e^xi
eg: 4, 2 e^4/(e^4 + e^2) = 0.88, e^2/(e^4 + e^2) = 0.12
eg: 2, 1 e^2/(e^2 + e) = 0.73, e/(e^2 + e) = 0.27
def generate_text(model, start_string, num_gengrate = 1000):
input_eval = [char2idx[ch] for ch in start_string]
# 因为输入的是[1, None] 二维的,故需要做维度的扩展
input_eval = tf.expand_dims(input_eval, 0)
text_generated = []
model.reset_states()
# temperature > 1, predictions的分布更均匀,即数据更随机,random
# temperature < 1, predictions的分布更集中,greddy
# predictions:logits ——> softmax ——> prob
# softmax: e^xi
# eg: 4, 2 e^4/(e^4 + e^2) = 0.88, e^2/(e^4 + e^2) = 0.12
# eg: 2, 1 e^2/(e^2 + e) = 0.73, e/(e^2 + e) = 0.27
temperature = 0.5
for _ in range(num_generate):
# model inference --> predictions
# sample --> ch --> text_generated
# update input_eval
# predictions: [batch_size, input_eval_len, vocab_size]
predictions = model(input_eval)
predictions = predictions / temperature
# batch_size 总是1(why?)所以可以将batch_size 那个维度消掉
# predictions: [input_eval_len, vocab_size]
predictions = tf.squeeze(predictions, 0)
# predicted_ids: [input_eval_len, 1]
# a b c --> b c d (其中,b是对a的预测,c是对ab的预测,d是对abc的预测,所以只有最后一个d是有用的)
predicted_id = tf.random.categorical(predictions, num_sample = 1)[-1, 0].numpy()
text_generated.append(idx2char[predicted_id])
# 更新input_eval
# 循环神经网络模型 s, x --> run --> s', y
input_eval = tf.expand_dims([predicted_id], 0)
return start_string + ''.join(text_generated)
new_text = generated_text(model2, "All: ")
print(new_text)