目标检测算法再理解
目标检测算法再理解
一、两阶段检测网络
1、R-CNN
两阶段为:
Region Proposal(候选框选取) + Bbox(Bounding box)
特点:
使用CNN进行特征提取,相比于传统的来说引入了人CNN;
步骤:
① Region Proposal:Selective Search
约为2k个,缩放到同样大小;
②Feature Extraction:CNN
注意Batch size为128 = 32pos + 96neg, neg:iou < 0.5,也就是正负样本比例为1:3;
③SVM Classification + NMS + BBox Regression
缺点:
- 每个region proposal都需要跑一遍CNN;
- post-hoc: CNN features not updated in response to SVMs and regressors
- 繁琐和冗余的操作;
2、Fast R-CNN
特点:
-
整张图片送入CNN,不用每个region proposal 单独计算CNN
-
proposal projection:根据region proposal在原图的位置,映射在feature map上的位置;
-
ROI Pooling:将不同大小的feature map打格成7x7,然后在每一个格中maxpool后就成一个点,最后就变成7x7大小的feature。
注意:本身由于ROI Pooling两次取整产生的误差,容易造成小目标检测效果差;一是原图与feature map的比例不一定是整
数,所以RoI pooling裁剪对应proposal的feature map时存在误差;二是打格的时候存在除不尽的时候; -
ROI Pooling的几种方法:
参考文章:https://blog.csdn.net/discoverer100/article/details/90519423
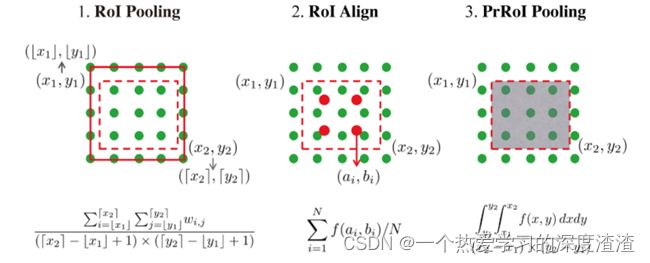
PrRoI Pooling实际上就是对proposal区域内的像素点求和,除以proposal面积,也就是均值池化;
步骤:
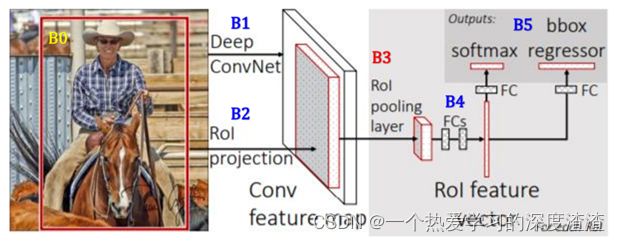
B0:通过select search得到约2k个proposal;
B1:将原图生成一个feature map;
B2:ROI Projection,将Region Proposal映射到原图的feature map上,然后裁剪出来;
B3:ROI Pooling:将裁剪出来的不同大小的feature map reshape成大小相同的feature map;
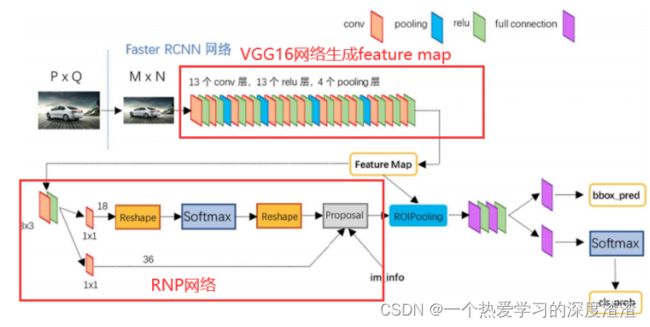
3、Faster R-CNN

特点:
Faster R-CNN相比于Fast R-CNN最大的不同是,用RPN网络架构代替Selective search进行proposal提取;
网络结构图:
Anchor的概念:
由于去掉了selective search,预选框用每个像素点生成9个Anchor来代替;
RPN的回归:

说明:
网络回归框是利用了偏移量,而不是直接回归x、y的值,这样能避免损失函数被大目标控制;
总结:
Faster-RCNN这种两阶段网络由于其推理速度过慢,并且不是端到端的网络,慢慢已经被淘汰,现在大部分的检测任务都采用单阶段的;
二、一阶段检测网络
1、YOLOV1
主要思想:
去除了Region Proposal的步骤,直接将输入图像划分成7x7的网格,目标的中心点所在的网格用于检测该目标;

每个格子用来预测B个Bbox,都是针对同一个目标,最终网络的输出为【7 x 7 x(5 x 2 + 20)】
缺陷:
- 一个网格只预测一个目标,对于稠密的物体的预测不理想;
- 7x7的feature map得到的信息较少,对小目标的检测效果差,如果要预测小目标需要增大feature map;
- 对新的物体形状的效果不好;
- 没有Batch Normalization;
- 没有anchor和offset回归,对小物体和聚集物体的检测效果差;
2、YOLOV2
相对于V1的改进:
- 引入了BN层;
- 将7x7的feature map改成13x13,增大了信息的提取;
- 多尺度训练:用不同尺度的训练集拼起来进行训练;
- shortcut结构,也就是将浅层网络信息和深层网络信息相结合(这里又concat和add两种方式)
- Yolo 把所有Ground Truth的形状集合在一起,做聚类;把所有类的平均的shape取五类作为anchor的初始值;相对于Faster RCNN的9个anchor来说少了很多;
3、YOLOV3
相对于V2的改进:
-
V3网络中的基本组成单元,已经不再是layer了,而是一块module+module,网络结构更简单,速度更快;
-
多尺度输出,有三层输出,每一层输出对应的featuremap大小不一样,目的是能够识别大小不同的物体;
-
总共9个anchor,三层输出分别对应三个anchor;

拓展:
这里介绍一下FPN网络,我们指导YOLOV3中是通过不同的三层特征图直接输出结果,FPN则是关联后输出;

说明:FPN对精度的提升有帮助,但非常吃资源,对于侧重性能的任务要谨慎使用;是一个可以嵌入到单、双阶段检测网络中的模块;
4、YOLOV4
创新点:
- 开创了一种数据增广的方式Mosaic,随机组合图片成一张新的图,增加了图像的复杂度,基本不会发生过拟合,起到了regularization的作用;还相当于增大了batchsize,一张图等于四张图;

-
数据增广Self-Adversarial Training: 中间Freeze掉权重,直接把loss传递到输入层,把loss加到原始图像上生成新的图像,源源不断地产生很多图像,再用于训练;
-
Modified SAM:SAM全称为space attention module,空间注意力模块;

- Modified PAN:将原来用add相连操作换成concat;
拓展:
YOLOV4提出了两个概念:Bag of freebies(BoF)和 Bag of specials(BoS)
BoF:赠品袋,表示在训练过程中可以进行的一些改进,比如数据增强、类别不均衡、成本函数等,用来提高精度,并且这些改动对推理速度没有影响;
BoS:特价品袋:表示对推理速度的影响较小,性能回报较好;例如一些感受野的增加、注意力机制、特征融合以及后处理NMS;
5、RetinaNet
首先思考一个问题,为什么one stage的网络精度会低于two stage?
① 正负样本极度不均衡;(正样本远小于负样本,Faster RCNN中正负样本比控制在1:3)
② gradient/loss被简单样本给稀释了,网络学习到了很多没有用的特征;
提出了一个解决以上问题的方法:Focal Loss
Focal Loss原理:
原始分类问题使用Cross Entroty
CE: log(pt) = logy^ if y = 1 else log(1-y^)
① 解决正负样本不均匀的问题,增加一个at权重
CE’ = -αt*log(pt)
② 解决难易样本问题
CE’’ = -(1-pt)γ*log(pt)
γ:为了产生指数效应,学名focusing parameter,-(1-pt)γ整体叫调节因子,modulating factor;
结合上面两个式子,Focal Loss可以表示为:
FC = -α(1-y^)γlogy^, y = 1
FC = -(1-α)y^γlog(1-y^), y = 0
总结:
RetinaNet的重点在于Focal Loss的提出,理论上只要是样本不均衡的问题,都可以尝试Focal Loss,但不是百分百有效;
6、SSD
SSD出现的比YOLO早,但实际效果没有YOLO好,其一些变体的思路很好,例如FaceBoxes;

FaceBoxes的github地址:https://github.com/zisianw/FaceBoxes.PyTorch
FaceBoxes中最具特点的部分就是anchor的设计,还有以下两点设计也值得学习:
① Bipartite match双边对应:
举个例子,例如两个anchorA、B都离C框比较近,如果C框离B框近,那么说明B和C框属于双边对应;
② online hard example mining 在线难样本的mining:
为了避免学习中只学习到easy样本,在学习中按照score分数排序,每次都学习最难的样本;
总结:
上面两个trick的实现在github里,可以通过理解代码进行学习,这种方式也可以在后续用于其他任务中;
三、一些trick记录
1、Data Augmentation
介绍:数据增强可分为同类增强(如:翻转、旋转、缩放、 移位、模糊等)和混类增强(如 mixup)两种方式;
① Mixup
作用:将随机的两张样本按比例混合,也就是根据权重进行混合;

② Cutout
作用:模拟遮挡,对图像进行随机遮挡的作用;

③ CutMix
作用:将一部分区域cut掉但不填充0 像素而是随机填充数据集中其他数据的其余像素值;

优点:
- 在训练过程中不会出现非信息像素,能够提高训练效率;
- 保留了regional dropout优势,能够关注目标的non-discriminativa parts;
- 要求模型通过局部信息识别对象,在cut区域中加入其他样本信息,能够进一步增强模型定位能力;
- 不会出现图像混合后不自然的情形,能够提升模型的分类表现;
- 训练和推理的代价保持不变;
④ Mosaic
作用:参考了 CutMix 数据增强方式,理论上具有一定的相似性,Mosaic 利用了四张图像,论文中描述其拥有一个巨大的优点就是丰富检测物体的背景,且在 BN 计算的时候一下子会计算四张图片的数据;

2、Regularization
①Label Smoohing
作用:标签平滑的作用, 是一种正则化方法,通常用于分类问题,目的是防止训练时过于自信地预测标签,改善泛化能力差的问题;
公式如下:

例如原来是1、0两个值,经过标签平滑后变成0.95和0.05,也就是将hard label变成soft label;
②DropBlock
作用:DropBlock是一种结构化的dropout形式,它将feature map相邻区域中的单元放在一起 drop掉。除了卷积层外,在跳跃连接中用 DropBlock 可以提高精度。此外,在训练过程中,逐渐增加 dropped unit的数量会有更好的准确性和对超参数选择的鲁棒性;

待补充