
撰文|月踏
更新|赵露阳
前文《AI杂谈:手推BP》讲了Backward Propagation的数学原理。本文以OneFlow的代码为例,梳理Autograd模块的实现细节。
1
一个求梯度的小例子
先看下面这个简单的例子:
import oneflow as of
x = of.randn(2, 2, requires_grad=True)
y = x + 100
z = y.sum()
z.backward()forward pass可以对应到下面的计算图:

图1
即对应下面公式:
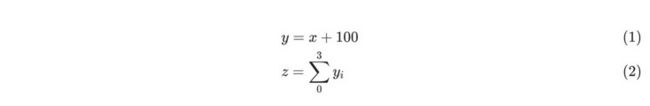
根据前文《AI杂谈:手推BP》很容易手动计算出x的梯度值,即:
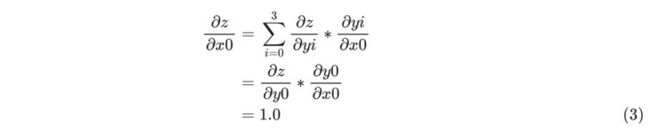
x1、x2、x3的计算过程类似,不再赘述,下面看一下OneFlow的执行结果,执行print(x.grad)可得到如下输出:
tensor([[1., 1.],
[1., 1.]], dtype=oneflow.float32)可以看出,结果和前面公式(3)的计算结果一致,下面通过具体的代码实现来分析OneFlow的Autograd模块。
2
backward接口
上面例子中的python端的backward接口,调用的是
python/oneflow/framework/tensor.py中的_backward接口:
def _backward(self, gradient=None, retain_graph=False, create_graph=False):
if not lazy_mode.is_enabled():
flow.autograd.backward(self, gradient, retain_graph, create_graph)
else:
...可以看到backward只支持eager模式,这是因为graph静态图模式下,计算图是提前编译好的,无需手动通过.backward()调用。flow.autograd.backward()会调用oneflow/api/python/autograd/autograd.cpp中导出的backward方法:
ONEFLOW_API_PYBIND11_MODULE("autograd", m) {
m.def("backward", &Backward);
m.def("grad", &Grad);
}从pybind定义来看,这里面总共导出了两个接口(autograd.backward和autograd.grad)。其中,backward是对所有的requires_grad属性为True的节点求梯度,grad只对指定的叶子结点求梯度,原理上是相同的,本文只以backward为例来看代码的实现,backward接口会调用到同一个文件中的Backward函数:
Maybe Backward(const one::TensorTuple& outputs, const one::TensorTuple& out_grads,
bool retain_graph, bool create_graph) {
if (create_graph) { retain_graph = true; }
std::shared_ptr gradients = JUST(CheckAndInitOutGrads(outputs, out_grads));
JUST(one::GetThreadLocalAutogradEngine()->RunBackwardAndSaveGrads4LeafTensorIf(
outputs, *gradients, retain_graph, create_graph));
return std::make_shared(0);
} 这里的GetThreadLocalAutogradEngine()可以看作是一个thread_local的单例,位于oneflow/core/autograd/autograd_engine.cpp,返回一个autograd引擎(AutogradEngine)对象的指针:
AutogradEngine* GetThreadLocalAutogradEngine() {
thread_local static GraphAutogradEngine autograd_engine;
return &autograd_engine;
}AutogradEngine是OneFlow的Autograd的核心数据结构,它的继承关系如下:
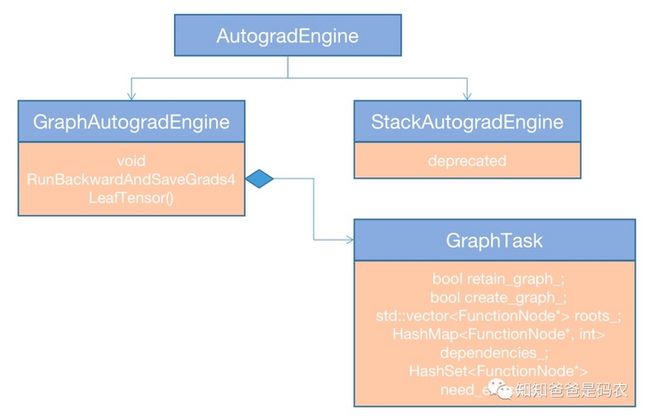
图2
这里autograd引擎的子类实现有基于栈式的、基于图式的实现,默认使用基于图式的GraphAutogradEngine。从前面代码中可以看到,获取autograd引擎指针后,通过调用RunBackwardAndSaveGrads4LeafTensor函数,位于
oneflow/core/autograd/autograd_engine.cpp:L315:
Maybe GraphAutogradEngine::RunBackwardAndSaveGrads4LeafTensor(const TensorTuple& outputs,
const TensorTuple& out_grads,
bool retain_graph,
bool create_graph) {
for (int i = 0; i < outputs.size(); ++i) {
JUST(JUST(outputs.at(i)->current_grad())->PushPartialTensor(out_grads.at(i)));
}
GraphTask graph_task(outputs, retain_graph, create_graph);
JUST(graph_task.ComputeDependencies());
JUST(graph_task.Apply(/*save_grad_for_leaf=*/true));
return Maybe::Ok();
} 这就真正进入了autograd模块的内部处理流程,后面继续分析。
3
FunctionNode和建立反向图
在进行backward pass时,执行的是一张反向图,反向图中的节点是在forward pass的时候建立的,其中的每个节点被称作FunctionNode,主要数据结构如下:
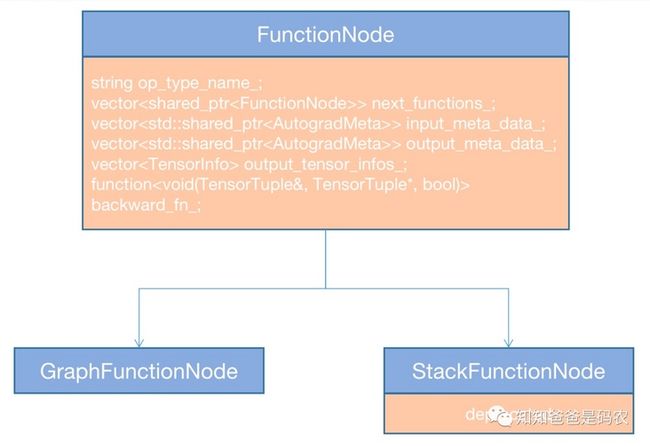
图3
先说图3中FunctionNode(oneflow/core/autograd/autograd_engine.h:L42),包含next_functions_、input_meta_data_、output_meta_data_这三个数据成员,其中next_functions_表示出边,另外两个表示一些meta信息,下面列几个主要的:
- is_leaf_:是不是叶子节点
- requires_grad_:是不是需要求梯度值
- retain_grad_:对于非叶子节点,是不是保存梯度值
- acc_grad_:在gradient accumulation的的情况下,多个mini-batch的梯度累加
- current_grad_:当前这个batch的梯度值
我们用到的是GraphFunctionNod(oneflow/core/autograd/autograd_engine.cpp:L178)
GraphFunctionNode::GraphFunctionNode(const std::string& name,
const std::shared_ptr& backward_fn,
const TensorTuple& inputs, const TensorTuple& outputs)
: FunctionNode(name, backward_fn) {
input_meta_data_.resize(inputs.size());
next_functions_.reserve(inputs.size());
for (int i = 0; i < inputs.size(); ++i) {
if (inputs.at(i)->requires_grad()) {
input_meta_data_.at(i) = inputs.at(i)->mut_autograd_meta();
next_functions_.emplace_back(inputs.at(i)->mut_grad_fn_node());
}
}
output_meta_data_.resize(outputs.size());
output_tensor_infos_.reserve(outputs.size());
for (int i = 0; i < outputs.size(); ++i) {
const auto& autograd_meta =
NewAutogradMeta(outputs.at(i)->requires_grad(), outputs.at(i)->is_leaf());
outputs.at(i)->set_autograd_meta(autograd_meta);
output_meta_data_.at(i) = outputs.at(i)->mut_autograd_meta();
output_tensor_infos_.emplace_back(TensorInfo(*outputs.at(i)));
}
backward_fn_ = backward_fn;
} 可见它主要对FunctionNode中的重要数据成员做了初始化,其中input_meta_data_、output_meta_data_中的AutogradMeta信息是从相应的input、output tensor中获取的,tensor通过桥接模式保存了一个TensorImpl对象指针,这个TensorImpl对象则维护了一个AutogradMeta对象。
继续看下FunctionNode中的反向函数backward_fn_,在《OneFlow学习笔记:从Functor到OpExprInterpreter》中讲到了在进行一个op调用的时候会执行AutogradInterpreter::Apply这个函数(oneflow/core/framework/op_interpreter/op_interpreter.cpp:L86),里面会创建这个反向函数:
Maybe AutogradInterpreter::Apply(
const OpExpr& op_expr,
const TensorTuple& inputs,
TensorTuple* outputs,
const OpExprInterpContext& ctx) const {
...
autograd::AutoGradMode mode(false);
JUST(internal_->Apply(op_expr, inputs, outputs, ctx));
std::shared_ptr grad_closure(nullptr);
if (requires_grad && !LazyMode::is_enabled()) {
grad_closure = JUST(op_expr.GetOrCreateOpGradClosure());
auto backward_fn = std::make_shared();
backward_fn->body = [=](const TensorTuple& out_grads, TensorTuple* in_grads,
bool create_graph) -> Maybe {
autograd::AutoGradMode mode(create_graph);
JUST(grad_closure->Apply(out_grads, in_grads));
return Maybe::Ok();
};
backward_fn->status = [=]() { return grad_closure->state()->SavedTensors().size() > 0; };
JUST(GetThreadLocalAutogradEngine()->AddNode(op_expr.op_type_name() + "_backward", backward_fn,
inputs, outputs));
}
...
return Maybe::Ok();
} 可以看到反向图节点的名字是以正向图op的type name加上_backward的后缀来组成的,使用AddNode方法来创建FunctionNode(
oneflow/core/autograd/autograd_engine.cpp:L356)
Maybe GraphAutogradEngine::AddNode(
const std::string& name, const std::shared_ptr& backward_fn,
const TensorTuple& inputs, TensorTuple* outputs) {
// Firstly push function_node of tensor in stack which is leaf and requires_grad
for (const std::shared_ptr& in_tensor : inputs) {
if (in_tensor->is_leaf() && in_tensor->requires_grad()) {
if (!in_tensor->grad_fn_node()) { JUST(AddAccumulateFunctionNode(in_tensor)); }
}
}
std::shared_ptr func_node =
std::make_shared(name, backward_fn, inputs, *outputs);
for (const std::shared_ptr& out_tensor : *outputs) {
out_tensor->set_grad_fn_node(func_node);
}
return func_node;
} 可见FunctionNode是挂在Tensor上的,通过Tensor的set_grad_fn_node接口维护到Tensor的数据结构中,在《OneFlow学习笔记:Consistent view的相关概念和实现》中画过Tensor的继承关系图,FunctionNode就是保存在TensorIf中:
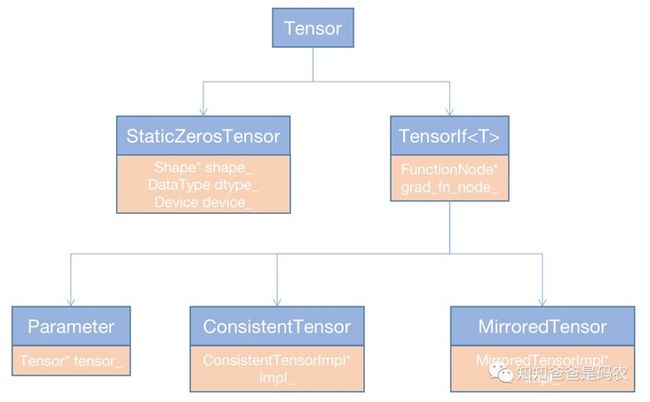
图4
至此,已经理清了FunctionNode中各个成员的作用以及来历,假如以第二节的图1为例来画出对应的反向图的话,如下图所示:
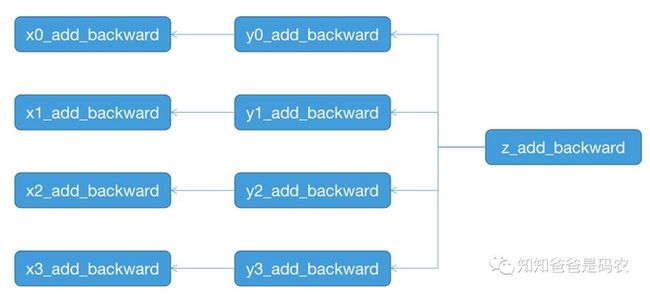
图5
计算好的梯度值会被放到output_meta_data_中得AutogradMeta中,它可以通过tensor的acc_grad、current_grad接口来获取。
4
反向图的执行流程
接第三节列出的最后一段代码,其中最重要的两句话是:
...
JUST(graph_task.ComputeDependencies());
JUST(graph_task.Apply(/*save_grad_for_leaf=*/true));
...这里面的graph_task是GraphTask类型,它是一个很重要的数据结构,用来调度反向图中所有FunctionNode的执行,下面列一下它的主要成员:
class GraphTask final {
bool retain_graph_;
bool create_graph_;
std::vector roots_;
HashMap dependencies_;
HashSet need_execute_;
}; 先看本节开头的
graph_task.ComputeDependencies,它主要是在初始化dependencies_这个map,这个map维护了每个FunctionNode的入度信息,再看graph_task.Apply,它主要是在通过拓扑序来访问反向图中的每个FunctionNode,并且对当前的FunctionNode进行各种操作(
oneflow/core/autograd/autograd_engine.cpp:L287)
Maybe GraphTask::Apply(bool save_grad_for_leaf) {
std::queue queue;
for (FunctionNode* node : roots_) {
if (dependencies_[node] == 0) { queue.push(node); }
}
while (!queue.empty()) {
FunctionNode* node = queue.front();
queue.pop();
if (!need_execute_.empty() && need_execute_.find(node) == need_execute_.end()) {
node->ReleaseOutTensorArgs();
continue;
}
if (/*bool not_ready_to_apply=*/!(JUST(node->Apply(create_graph_)))) { continue; }
if (save_grad_for_leaf) { JUST(node->AccGrad4LeafTensor(create_graph_)); }
JUST(node->AccGrad4RetainGradTensor());
node->ReleaseOutTensorArgs();
if (!retain_graph_) { node->ReleaseData(); }
for (const auto& next_grad_fn : node->next_functions()) {
FunctionNode* next_node = next_grad_fn.get();
dependencies_[next_node] -= 1;
if (dependencies_[next_node] == 0) { queue.push(next_node); }
}
}
return Maybe::Ok();
} 这里最重要的是下面两个语句:
- node->Apply
- node->AccGrad4LeafTensor
下面来逐个分析,先看node->Apply(oneflow/core/autograd/autograd_engine.cpp:L143),首先利用output_meta_data_初始化了output_grads,把它作为反向函数的输入,调用反向函数来求梯度值,求出的梯度值暂存在input_grads中,然后再更新到input_meta_data_中:
Maybe FunctionNode::Apply(bool create_graph) {
...
JUST(backward_fn_->body(output_grads, &input_grads, create_graph));
for (int i = 0; i < input_meta_data_.size(); ++i) {
if (input_grads.at(i)) {
...
JUST(input_meta_data_.at(i)->current_grad()->PushPartialTensor(input_grads.at(i)));
}
}
return true;
} 再看node->AccGrad4LeafTensor,这个函数最终会调用到CopyOrAccGrad,它主要用于在gradient accumulation的时候,多个mini-batch之间把梯度值多累加,和如果有hook函数的的话,使用注册的hook对当前的梯度值进行处理:
Maybe CopyOrAccGrad(AutogradMeta* autograd_meta, bool autograd_mode) {
autograd::AutoGradMode mode(autograd_mode);
auto current_grad = JUST(autograd_meta->current_grad()->GetAccTensor({}));
if (!current_grad) { return Maybe::Ok(); }
if (autograd_meta->acc_grad()) {
...
DevVmDepObjectConsumeModeGuard guard(DevVmDepObjectConsumeMode::NONE);
const auto& output = JUST(functional::Add(autograd_meta->acc_grad(), current_grad, /*alpha=*/1,
/*inplace=*/autograd_meta->is_grad_acc_inplace()));
JUST(autograd_meta->set_acc_grad(output));
} else {
JUST(autograd_meta->set_acc_grad(current_grad));
}
for (const auto& hook : autograd_meta->post_grad_accumulation_hooks()) {
auto new_grad = hook(autograd_meta->acc_grad());
if (new_grad) { JUST(autograd_meta->set_acc_grad(new_grad)); }
}
return Maybe::Ok();
} (*特别感谢同事yinggang中间的各种答疑解惑。本文主要参考代码:
https://github.com/Oneflow-In...*)
欢迎下载体验OneFlow v0.7.0最新版本:
https://github.com/Oneflow-In...