PyTorch学习(五)——卷积神经网络
计算机视觉基本概念

- 灰度图即将c的通道变成1
- 当描述数据时,我们有时候只需要关注其纹理信息,就不需要关注其彩色空间。如果想要模型对于颜色的变化不那么敏感,我们在训练模型的时候就用灰度图。

- 高频部分指的是图像的噪点,边缘点。图像平滑,就是用该点的邻域点来表示它


- 边缘提取算子
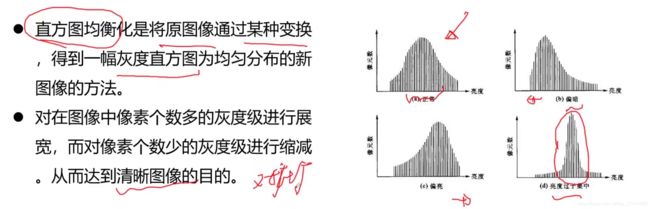


- 计算机视觉中的特征工程

- 如LDA算法,将x投影到x‘ (中层次特征) 直方图统计(低层次特征)
- 特征提取 -> 特征选择 -> 建模 (前两个被CNN处理了 :人脸识别 / 图像检索)
- 卷积运算:利用像素点领域点来计算,是一种特征提取
- 分类问题:在经过特征提取之后,得到的向量中,是一组对应的概率分布。如手写数字识别中的,若数字是1,那么此时1向量中1对应的概率分布就比较高而其他数字的概率分布就比较低
- 检测任务:其实是对图像中的某些局部区域是不是我们想要的目标,如果不是的话,那它离我们想要的目标相差的偏移是多少。(前者还是一个分类问题,我们使用一个卷积神经网,对该区域不断地卷积,最终拿到一个特征向量,用这个特征向量来进行分类或者回归。回归就是对于我们的这个偏移量来进行回归)
- 图像分割是:对于图像中的每一个像素点所属的类别来进行判断。
- 图像匹配:相似性的比较。图片所对应的两个向量之间的欧氏距离/余弦距离很小
- 图像跟踪:单目标/多目标跟踪
卷积神经网络

卷积层
- padding就是对那些卷积之后边缘没有值的地方进行填充
- dilation,空洞/膨胀卷积:不经过pooling层的这个下采样,我们一样能增大感受野

- 缩小图像(或称为下采样(subsampled)或降采样(downsampled))的主要目的有两个:1、使得图像符合显示区域的大小;2、生成对应图像的缩略图。
- 放大图像(或称为上采样(upsampling)或图像插值(interpolating))的主要目的是放大原图像,从而可以显示在更高分辨率的显示设备上。

- 由图中可以看到,两个33的卷积核对应的感受野是55,而三个33的卷积核对应的感受野就是77
- 一个55的卷积核其有25个元素,也就是进行了25次乘加操作,而两个33的卷积核进行的乘加操作是9+9=18次。
- 用小卷积核代替大卷积核还有一个好处是加深网络。可以使网络的非线性表达能力增强,而且参数量和计算量也会下降。



池化层


- 一般还是选择使用resize方法,因为其计算量一般来说会小一点,而且其复杂程度相对于转置卷积来说也会简单很多。
激活层/BN层/FC层/损失层
- 卷积层可以对应为:y=wx+b x是输入卷积层,y是输出卷积层。 w和b对应我们输入卷积核的参数。线性的网络其表达能力是比较差的,所以需要添加一些非线性元素。

- ReLU函数是 max(0,x) 将小于0的部分都变成0
- BatchNorm层

- 疑问:全连接层如何将一个3 * 3 * 5 的输出变成一个 1 * 4096的形式?
- 可以理解为在中间做了一个卷积。当我们用一个3x3x5的filter 去卷积激活函数的输出,得到的结果就是一个fully connected layer 的一个神经元的输出,这个输出就是一个值。因为我们有4096个神经元,所以我们实际就是用一个3x3x5x4096的卷积层去卷积激活函数的输出。
- 这一步卷积一个非常重要的作用:就是把分布式特征representation映射到样本标记空间。即它把特征representation整合到一起,输出为一个值。这样做的好处是:大大减少特征位置对分类带来的影响。

- 卷积层和y=wx+b的关系:在经过卷积之后,得到隐藏层的神经元。卷积核上的每个神经元对应于一个不同的w(weight),这里2*2的卷积核就对应4个weight。原输入经过卷积之后再加上一个bias,得到的就是输出神经元的值。隐藏层的每个神经元对应于同一个卷积核,也就是共享了这四个weight。所以说卷积神经网络共享了权重和偏置,在y = w*x + b中,w和b都是参数,所以也就是减少了参数的数目。所以feature map的大小 = (input_size - filter_size + 2 * padding) / stride + 1 (向上取整,边界不丢弃)
- 举个例子:
对于一个输入的二维神经元(28*28),若使用一个5*5的kernel,对于每一个kernel,需要5*5个权重参数,加上一个偏置bias,则总共有26个参数。
如果有20个kernel,总共需要26*20=520个参数就可以定义CNN
而若向之前一样两两相连的神经网络。首先输入层就有28*28=784个输入的神经元。如第一个隐藏层有30个神经元,那么两两连接,每个连接线上都对应一个weight,即有784*30个weight,另外每个神经元对应一个bias,所以有30个bias,则总共是 784*30+30=23550个参数,多了40倍参数!!!(参考该文)

经典卷积神经网络结构

串联结构的典型代表:LeNet,AlexNet,ZFNet,VGGNet
VGG16的网络模型如下图:

- VGG16包含了16个隐藏层(13个卷积层和3个全连接层)VGG网络的结构非常一致,从头到尾全部使用的是3x3的卷积和2x2的max pooling。(VGG网络的动态演示)

接下来讲解一下每层参数数量如何计算的(转载了这里的博客)
第一个卷积层block1_conv1:
输入 224 ∗ 224 ∗ 3 其 中 224 ∗ 224 224*224*3 其中 224*224 224∗224∗3其中224∗224为图片分辨率 3为图片的通道数
输出 224 ∗ 224 ∗ 64 其 中 224 ∗ 224 224*224*64 其中224*224 224∗224∗64其中224∗224为图片分辨率 64为卷积核数量也就是特征图数量
因此我们采用的是大小为 3 ∗ 3 ∗ 3 3*3*3 3∗3∗3的卷积核一共64个
参数数量为 3 ∗ 3 ∗ 3 ∗ 64 3*3*3*64 3∗3∗3∗64(卷积核参数)+64(bias)=1792
第一个卷积层block1_conv2:
输入 224 ∗ 224 ∗ 64 其 中 224 ∗ 224 224*224*64 其中224*224 224∗224∗64其中224∗224为图片分辨率 64为特征图数量
输出 224 ∗ 224 ∗ 64 其 中 224 ∗ 224 224*224*64 其中224*224 224∗224∗64其中224∗224为图片分辨率 64为卷积核数量也就是特征图数量
因此我们采用的是大小为 3 ∗ 3 ∗ 64 3*3*64 3∗3∗64的卷积核一共64个
参数数量为 3 ∗ 3 ∗ 64 ∗ 64 3*3*64*64 3∗3∗64∗64(卷积核参数)+64(bias)=36928
所有卷积层的参数计算以此类推,不再赘述
第一个全连接层fc1:
输入为 7 ∗ 7 ∗ 512 其 中 7 ∗ 7 7*7*512 其中7*7 7∗7∗512其中7∗7图片分辨率 512为图片的通道数
输出为4096个参数
全连接便是将输出的参数全部对应到输入的参数上去 因此参数个数为 7 ∗ 7 ∗ 512 ∗ 4096 7*7*512*4096 7∗7∗512∗4096(全连接参数)+4096(bias)=102764544
最后一个全连接层fc3,也就是上表中的prediction层:
输入为4096
输入为1000 也就是分类的类别数量
参数为 4096 ∗ 1000 ( 全 连 接 参 数 ) 4096*1000(全连接参数) 4096∗1000(全连接参数)+1000(bias)=4097000
- 可以看到全连接层参数冗余(仅全连接层参数就可占整个网络参数80%左右),所以近期一些性能优异的网络模型如ResNet和GoogLeNet等均用全局平均池化(global average pooling,GAP)取代FC来融合学到的深度特征,最后仍用softmax等损失函数作为网络目标函数来指导学习过程。
- softmax函数,又称归一化指数函数。它是二分类函数sigmoid在多分类上的推广,目的是将多分类的结果以概率的形式展现出来。转载至这里
首先,我们知道概率有两个性质:1)预测的概率为非负数;2)各种预测结果概率之和等于1。
softmax就是将在负无穷到正无穷上的预测结果按照这两步转换为概率的。
1)将预测结果转化为非负数
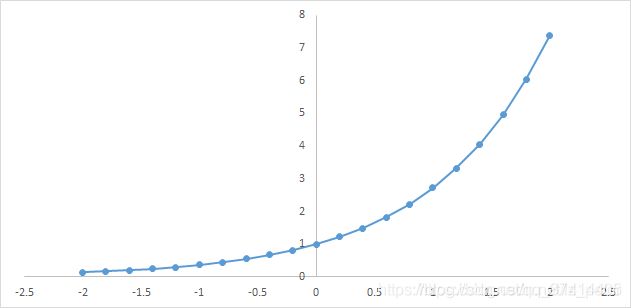
下图为y=exp(x)的图像,我们可以知道指数函数的值域取值范围是零到正无穷。softmax第一步就是将模型的预测结果转化到指数函数上,这样保证了概率的非负性。
2)各种预测结果概率之和等于1
为了确保各个预测结果的概率之和等于1。我们只需要将转换后的结果进行归一化处理。方法就是将转化后的结果除以所有转化后结果之和,可以理解为转化后结果占总数的百分比。这样就得到近似的概率。
下面为大家举一个例子,假如模型对一个三分类问题的预测结果为-3、1.5、2.7。我们要用softmax将模型结果转为概率。步骤如下:
1)将预测结果转化为非负数
y1 = exp(x1) = exp(-3) = 0.05
y2 = exp(x2) = exp(1.5) = 4.48
y3 = exp(x3) = exp(2.7) = 14.88
2)各种预测结果概率之和等于1
z1 = y1/(y1+y2+y3) = 0.05/(0.05+4.48+14.88) = 0.0026
z2 = y2/(y1+y2+y3) = 4.48/(0.05+4.48+14.88) = 0.2308
z3 = y3/(y1+y2+y3) = 14.88/(0.05+4.48+14.88) = 0.7666
总结一下softmax如何将多分类输出转换为概率,可以分为两步:
1)分子:通过指数函数,将实数输出映射到零到正无穷。
2)分母:将所有结果相加,进行归一化。

- VGGNet网络实现代码——Pytorch
import torch
import torch.nn as tnn
import torchvision.datasets as dsets
import torchvision.transforms as transforms
BATCH_SIZE = 10
LEARNING_RATE = 0.01
EPOCH = 50
N_CLASSES = 25
transform = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean = [ 0.485, 0.456, 0.406 ],
std = [ 0.229, 0.224, 0.225 ]),
])
trainData = dsets.ImageFolder('../data/imagenet/train', transform)
testData = dsets.ImageFolder('../data/imagenet/test', transform)
trainLoader = torch.utils.data.DataLoader(dataset=trainData, batch_size=BATCH_SIZE, shuffle=True)
testLoader = torch.utils.data.DataLoader(dataset=testData, batch_size=BATCH_SIZE, shuffle=False)
def conv_layer(chann_in, chann_out, k_size, p_size):
layer = tnn.Sequential(
tnn.Conv2d(chann_in, chann_out, kernel_size=k_size, padding=p_size),
tnn.BatchNorm2d(chann_out),
tnn.ReLU()
)
return layer
def vgg_conv_block(in_list, out_list, k_list, p_list, pooling_k, pooling_s):
layers = [ conv_layer(in_list[i], out_list[i], k_list[i], p_list[i]) for i in range(len(in_list)) ]
layers += [ tnn.MaxPool2d(kernel_size = pooling_k, stride = pooling_s)]
return tnn.Sequential(*layers)
def vgg_fc_layer(size_in, size_out):
layer = tnn.Sequential(
tnn.Linear(size_in, size_out),
tnn.BatchNorm1d(size_out),
tnn.ReLU()
)
return layer
class VGG16(tnn.Module):
def __init__(self, n_classes=1000):
super(VGG16, self).__init__()
# Conv blocks (BatchNorm + ReLU activation added in each block)
self.layer1 = vgg_conv_block([3,64], [64,64], [3,3], [1,1], 2, 2)
self.layer2 = vgg_conv_block([64,128], [128,128], [3,3], [1,1], 2, 2)
self.layer3 = vgg_conv_block([128,256,256], [256,256,256], [3,3,3], [1,1,1], 2, 2)
self.layer4 = vgg_conv_block([256,512,512], [512,512,512], [3,3,3], [1,1,1], 2, 2)
self.layer5 = vgg_conv_block([512,512,512], [512,512,512], [3,3,3], [1,1,1], 2, 2)
# FC layers
self.layer6 = vgg_fc_layer(7*7*512, 4096)
self.layer7 = vgg_fc_layer(4096, 4096)
# Final layer
self.layer8 = tnn.Linear(4096, n_classes)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
vgg16_features = self.layer5(out)
out = vgg16_features.view(out.size(0), -1)
out = self.layer6(out)
out = self.layer7(out)
out = self.layer8(out)
return vgg16_features, out
vgg16 = VGG16(n_classes=N_CLASSES)
vgg16.cuda()
# Loss, Optimizer & Scheduler
cost = tnn.CrossEntropyLoss()
optimizer = torch.optim.Adam(vgg16.parameters(), lr=LEARNING_RATE)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer)
# Train the model
for epoch in range(EPOCH):
avg_loss = 0
cnt = 0
for images, labels in trainLoader:
images = images.cuda()
labels = labels.cuda()
# Forward + Backward + Optimize
optimizer.zero_grad()
_, outputs = vgg16(images)
loss = cost(outputs, labels)
avg_loss += loss.data
cnt += 1
print("[E: %d] loss: %f, avg_loss: %f" % (epoch, loss.data, avg_loss/cnt))
loss.backward()
optimizer.step()
scheduler.step(avg_loss)
# Test the model
vgg16.eval()
correct = 0
total = 0
for images, labels in testLoader:
images = images.cuda()
_, outputs = vgg16(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted.cpu() == labels).sum()
print(predicted, labels, correct, total)
print("avg acc: %f" % (100* correct/total))
# Save the Trained Model
torch.save(vgg16.state_dict(), 'cnn.pkl')