根据 2022 年最新 DB-engines排名,主流时序数据库依然是 InfluxDB、Prometheus 等。但从排行上升趋势不难看出,近一年新的时序数据库崭露头角,这也说明企业技术选型的方向也越来越多。
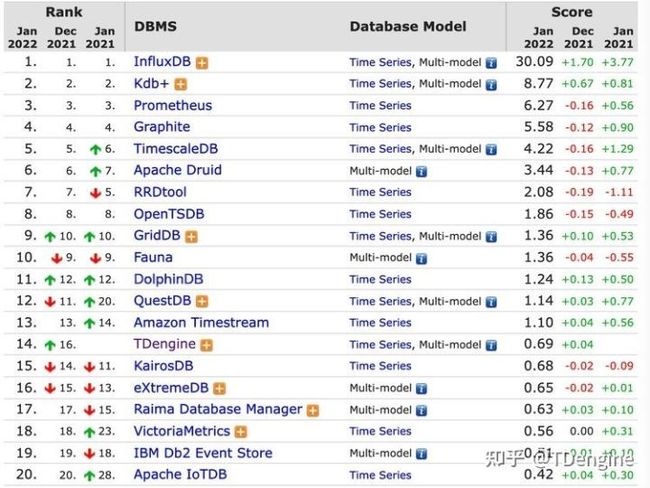
如何做好时序数据库的选择,也是困扰众多企业的根本问题。数据迁移的难度、后期运维的成本、更甚至是物理条件的限制等等一系列问题都会成为阻碍企业发展的一道不可逾越的鸿沟。TDengine 作为一款集群版都开源的时序数据库,近几年也帮助很多大厂完成了技术选型和企业数据的迁移。如果你正在为技术选型而头秃,不妨循着前人的脚步进行一番探索。
用户案例
TDengine:十年期货股票行情数据轻松处理——TDengine在同心源基金的应用
TDengine:TDengine在弘源泰平量化投资中的实践
TDengine:TDengine在同花顺组合管理业务中的优化实践
作为众多公司的最终选择,TDengine 能脱颖而出的根本原因还是在于其技术的完备。大数据有很多处理工具,例如 HBase,Hive,YARN,Storm,Spark 等系列工具。整个大数据平台中往往还有 Kafka,Redis 等类似的消息队列、缓存软件。这些软件较好的解决了通用大数据问题,但是物联网、车联网、工业互联网等场景的数据有其独特性,充分利用这些独特之处,必定可以使数据处理有数量级的提升,并且大大减少研发和运维成本。
TDengine 专为物联网、车联网等时序空间大数据设计,其核心功能是时序数据库。但为减少大数据平台的研发和运维的复杂度,更进一步降低计算资源,TDengine 还提供大数据处理所需要的消息队列、消息订阅、缓存、流式计算等功能。TDengine 的优势十分明显,主要表现在以下几个方面:
1. 大幅提升数据插入和查询性能
物联网的数据是结构化的,因此 TDengine 采取的是结构化存储,而不是流行的 KV 存储。物联网场景里,每个数据采集点的数据源是唯一的,数据是时序的,而且用户关心的往往是一个时间段的数据,而不是某个特殊时间点。基于这些特点,TDengine 要求对每个采集设备单独建表。如果有 1000 万个设备,就需要建 1000 万张表。
基于这样的设计,任何一台设备采集的数据在存储介质里可以是一块一块连续的存放的,而且按照时间排序。因此查询单个设备一个时间段的数据,查询性能就有数量级的提升。另外一方面,虽然不同设备由于网络的原因,到达服务器的时间无法控制,是完全乱序的,但对于同一个设备而言,数据点的时序是保证的。一个设备一张表,就保证了一张表插入的数据是有时序保证的,这样数据插入操作就变成了一个简单的追加操作,插入性也能大幅度提高。
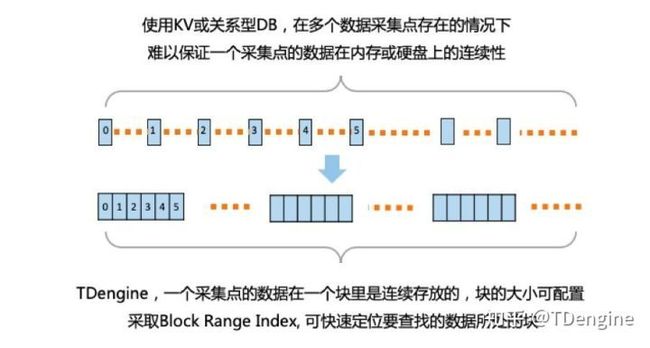
KV 存储的好处是不用定义数据库表结构,每条记录都可以变换格式。但在物联网、车联网这些场景里,一般数据格式是固定的,改动的频次很低,而且 TDengine 实现了一种高效的修改表结构的方法,因此 TDengine 采取格式化存储不会带来太大的不便。
2. 大幅降低硬件或云服务成本
由于数据插入查询性能大幅度提升,系统所需要的计算资源就大幅减少。另外一方面,物联网采集的物理量的值是随时间改变的,但正常情况下,是渐变的,因此 TDengine 采取列式存储,将同一个物理量在多个时间点采集的值连续存放,这样能成倍的提高压缩效率。而且 TDengine 针对不同的数据类型采取不同的压缩方法,比如 delta-delta 编码、simple 8B 方法、zig-zag 等等,这样更进一步的提高压缩率。与通用数据库相比,在已经测试过的物联网场景中,TDengine存储空间不到 1/5,大幅节省存储资源。在 TDengine 公布的对比测试报告里,有如下的结果:

3. 大幅简化大数据系统架构
与互联网应用不一样的是,物联网场景中,只要指定联网设备数量,数据采集频次,系统所需要的流量就可以较为准确地估算出来,不像双 11,电商的流量可以几十倍的变化,而物联网的流量则较为平稳。同时,物联网设备都有一定的数据缓存能力,以防止网络连接失败,因此物联网平台对消息队列的需求没有那么强烈。TDengine 内部实现了一简单的消息队列,同时提供订阅功能,这样就不需要使用 Kafka 等类似的消息队列软件了。
TDengine 对数据库分配了固定的内存区域,新插入的数据,会先写入内存。内存按照先进先出的原则进行管理,内存不足时,老的数据会被持久化存储,而内存里的老数据会被最新的覆盖掉。TDengine 还保证了任何一台设备最后一条记录一定在内存中,如果应用要获取每个设备的最新数据或状态,都将从内存里直接获取,这样的设计让系统可以不再需要 Redis 这类软件。
因此 TDengine提供了大数据处理所需要的数据库、缓存、消息队列、流式计算等系列功能。使用TDengine,在物联网大数据平台中完全可以抛弃掉Kafka、HDFS、HBase、Spark和Redis等软件,大幅简化大数据平台的设计,降低研发成本大,而且系统将更加健壮,数据的一致性更有保证。
因此 TDengine 提供了大数据处理所需要的数据库、缓存、消息队列、流式计算等系列功能。使用 TDengine,在物联网大数据平台中完全可以抛弃掉 Kafka、HDFS、HBase、Spark 和 Redis 等软件,大幅简化大数据平台的设计,降低研发成本大,而且系统将更加健壮,数据的一致性更有保证。
4. 强大的历史数据分析能力
TDengine 设计上让用户对历史数据和实时数据的处理完全透明,不区分历史数据和实时数据。用户只需要在 SQL 语句里指定时间段,TDengine 自动决定是否从内存、从本地硬盘,还是从网络存储上获取数据,这样应用的实现变的简单。
每个设备的数据按块存储,而且每个数据块都已经做了预聚合(比如和、最大、最小值等),这样执行一个设备一个时间段的各种统计操作,有可能不用扫描原始数据,就能计算出来,性能大幅提升。即使有的计算需要扫描原始数据,但由于数据是一块一块连续存储的,读取速度远超通用数据库,计算分析速度也是大幅提升。而且由于结构化存储,解压后,不用做任何解析,读进内存就可以直接计算,相对于 NoSQL 数据库,计算分析速度也是大幅提升。
TDengine 定义了一新的概念——超级表,用以描述同一类型的设备。给每个设备或表打上静态标签后,就可以用标签值筛出一部分满足过滤条件的设备,然后对这一部分设备的数据进行聚合。TDengine 还设计了一特殊的机制,对于多个设备数据聚合,仅仅需要扫描一次数据文件,这样大幅减少IO操作次数,提高聚合计算速度。为提高易用性,用户可以通过 TDengine 自带的 shell,或者 Python、R、Matlab 等工具直接进行各种 Ad-Hoc 的查询或分析。TDengine 用来做物联网、车联网、工业互联网的数据仓库,会是一个理想的选择。
5. 零运维管理,零学习成本
TDengine 安装包很小,下载、安装几秒钟搞定。对于企业版,把一台机器加入集群一条命令就能完成,而且数据库是实时自动备份,不用手动分库分表,运维极其简单。系统使用标准的 SQL,支持 C/C++、Java、Python 和 Go 等各种语言开发接口,支持 JDBC,支持 RESTful 接口。使用起来就像是在使用MySQL,几乎不需要学习成本。
6. 与第三方工具无缝集成
目前 TDengine 在数据采集侧,已经支持 Telegraf、Kafka,后续还将支持 MQTT、OPC 等。在应用侧,已经支持 Grafana 可视化工具,支持 Matlab,R 以及一些 BI 工具。因为 TDengine 支持 JDBC 接口,很容易实现与第三方工具的接口,可以预见,更多的工具将会被无缝集成。
对于运维监测场景,不用写任何代码,只要将开源的 Telegraf、Grafana与TDengine配置好,就可以迅速搭建一个高效的运维监测平台。
开源
TDengine 由北京涛思数据技术有限公司自主开发,没有依赖任何第三方软件。研发时间已经超过 2 年,而且已经有一批付费商业客户,涉及电力、数控机床、智慧城市、车辆网等多个领域,客户的使用反馈都很不错。可喜的是,涛思数据将 TDengine 的核心存储、计算引擎完全开源。TDengine 的社区版完全能满足一定规模的物联网、车联网、工业互联网的应用需求。因为涛思数据核心团队就在北京,相比其他开源软件,应该能够给中国的软件工程师提供更好的本地服务。
结语
对比其他时序数据库,TDengine 在易用性、功能上、性能上有明显的优势。采用 TDengine,让物联网、工业互联网、运维监测的大数据平台的搭建变得极为简单,具备超强性能,不仅降低硬件成本、运维成本,还能大幅降低对研发和运维人员的需求。
想了解更多 TDengine Database的具体细节,欢迎大家在GitHub上查看相关源代码。