云智慧 AIOps 社区是由云智慧发起,针对运维业务场景,提供算法、算力、数据集整体的服务体系及智能运维业务场景的解决方案交流社区。该社区致力于传播 AIOps 技术,旨在与各行业客户、用户、研究者和开发者们共同解决智能运维行业技术难题,推动 AIOps 技术在企业中落地,建设健康共赢的AIOps 开发者生态。
一、运维领域的预测场景
随着企业数字化转型加速发展,运维领域作为数字化进程的关键一环,受到各行各业的重视,然而海量的运维数据与日益复杂的 IT 技术架构却给运维从业者带来了前所未有的挑战,传统的人工运维的方式已经无法满足时代所需,智能运维应运而生。
与人工智能、大数据、区块链等技术体系不同,智能运维并不是一项“全新”的技术,而是一个以智能运维场景为基础的智能技术应用和融合。值得注意的是,在智能运维领域的海量数据中,时间序列数据占据着不容忽视的地位,时间序列数据预测更是在智能运维领域应用广泛。
现在常见的时间序列预测应用场景包括:
- 磁盘、CPU 的容量预测:当磁盘、CPU 的容量占用较高时,可能会降低应用或者系统的运行性能,所以对磁盘、CPU 的容量预测,对于保证 IT 系统高效稳定运行很重要。
- 磁盘故障预警:海量数据的存储对应着更多的磁盘存储需求,而磁盘的频繁损坏导致的数据丢失将会给企业带来不可估量的损失,企业对于数据存储介质的稳定性和安全性的要求增高,让磁盘故障预警变得越来越重要。
- 业务预测:如商业、金融这类领域,业务种类繁多,通过对各种类的业务量进行监控,可以更精准地制定相应的业务计划,并合理设置资源规划。
下面让我们来详细聊聊时间序列预测算法,这个算法模型可分为经典类与深度学习类,尽管当今深度学习类时间序列预测模型是学术界研究的热点,但是在工业落地方面经典时间序列模型依旧十分重要。
经典时间序列预测模型从时间序列的趋势性、周期性、平稳性等多方面分析时间序列数据的统计性质,在一定的假设下对时间序列的分布进行建模。此类模型具有较为完备的数学理论,以及良好的可解释性,在推理和训练的计算效率上表现出比深度学习类模型更优的性能和更好的可部署性。
此外,经典时间序列预测算法背后的原理对智能运维从业者在设计新的预测模型带来了启发。本文接下来会详细介绍两类经典的预测模型:ARIMA 和 Prophet,简单阐述其背后的思想,并分享相关实际应用的经验。
二、ARIMA 预测模型
ARIMA 模型简介
ARIMA 由 AR(autoreg ressive)、MA(moving average)和 I(integrated)三个部分组成。ARIMA 是 ARMA 模型的一种推广,ARMA 模型是一种描述弱平稳随机过程的统计模型,弱平稳随机过程就是一类均值为常数,自相关函数仅和时间差有关的随机过程。
ARIMA 的主要思想是利用差分(difference)的操作将非平稳时间序列转换成平稳或弱平稳的时间序列,再用 ARMA 模型对转换后的时间序列进行分析和预测([1])。ARMA 模型由 AR(p)模型和 MA(q)模型构成。
若对一个随机过程,ARMA(p,q)模型可以写作为:
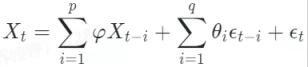
![]()
是一个白噪声序列,在实际应用中往往被
假设成是独立同分布的高斯随机变量:
![]()
其中 AR(p)代表变量对自身 p 个滞后项的回归,MA(q)则表示变量对滞后 q 个残差项的回归。当引入差分这一算子后,ARIMA(p,d,q)模型可以写作:
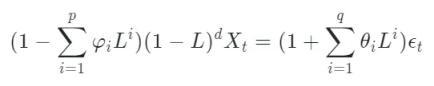
d 为差分的阶数,L 为滞后算子:
![]()
正如 ARMA 模型可以很好的描述弱平稳过程,在引入一定阶数差分算子后,一个在均值上非平稳的随机过程就有可能被转化为一个平稳过程,从而使得 ARMA 可以更好的描述数据背后的分布。
ARIMA 模型的参数选择
ARIMA 模型中三个超参数 p、d、q 阶数的选择对模型的预测效果至关重要。超参数 p 和 q 阶数的选择可以用样本自相关函数(sample ACF)和样本偏自相关函数(sample PACF)来决定。除此之外 AIC、BIC([2])等方法也可以用于超参数 p 和 q 阶数的选择。
在实际应用中,从业者需要通过反复的分析实验来确定 p 和 q 的阶数。对于差分超参数 d 的阶数选择,可以通过绘图软件观察差分后的数据是否为平稳时间序列来确定,也可以结合单位根检验来分析是否有必要进行差分处理。过差分(over difference)会导致模型损失过多的信息量,从而降低其预测效果。通常来说在保证模型预测效果的情况下,阶数越小越好,因为过大的阶数往往意味着更高的模型复杂度,从而导致过拟合的效应。在 ARIMA 模型超参数的阶数选择上,没有绝对的经验法则验,分析师往往需要结合业务情况和实际经验,来判断超参数阶数的选择。
ARIMA 模型的应用经验
从工业落地的角度来说,最重要的是了解模型的优势和劣势。通过上文对 ARIMA 模型的介绍,我们可以认识到此类模型比较适用于平稳或者差分后平稳的时间序列预测。对于有周期性的时间序列来说,ARIMA 模型并不能做到有效的拟合与预测。而 ARIMA 模型的变种 seasonal-ARIMA 模型可以用于周期型时间序列预测。除此之外,若将 ARIMA 模型与一些去周期的时间序列分解方法结合使用,也可以用于周期型时间序列预测。

如上图所示,对于这类具有周期性和线性的趋势性特征的时间序列,如果使用 ARIMA 模型进行预测,那周期分解的预处理和差分操作是不可或缺的。由于 ARIMA 模型的本质是用一类随机过程去拟合数据,且此类随机过程无法准确描述时间序列的变点(change point)和概念漂移(concept drift)现象。因此对于下图所示具有节点和概念漂移现象的时间序列数据预测,如果直接用 ARIMA 模型拟合数据是错误的,更为合理的方法是通过设置滑动窗口,使模型自适应去拟合最新的数据或替换成更合适的模型。

尽管 ARIMA 模型在实际预测应用中有着许多不足之处,但是它依旧是最经典的一种预测模型,学者们也提供了丰富的变种模型来解决 ARIMA 模型的缺陷。除了从递推关系和差分方程的角度来预测,ARIMA 模型也可以从状态空间模型或者谱分析的视角去预测,这为研究者延展出更多解决问题的方向,具体可以参考其它诸多教材文献([1])。
三、Prophet 预测模型
Prophet 模型简介
Prophet([3])模型由 Facebook 公司于 2017 年提出,最初应用于其公司内部的流量预测,在开源后由于模型上手容易和泛用性强,得到了业内更为广泛的应用。Prophet 模型的设计有着浓厚的工程师影子,它利用了时间序列分解的思想,将时间序列的趋势部分、周期部分以及节假日部分,分别建立关于时间轴的回归模型,并且通过贝叶斯的框架优化其回归系数。
若用 Prophet 模型假设时间序列存在如下关系:
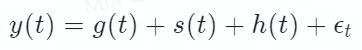
其中
![]()
分别为时间序列的趋势成分、周期成分、节假日成分。
![]()
为噪音成分,通常被假设为独立同分布的零
均值高斯。
Prophet 模型的参数选择
趋势项存在两种函数形式,分别为 Logistic growth 形式和 Linear growth 形式。对于 Logistic growth 形式,可以看作为一种“人口模型”,最基本的函数形式为:
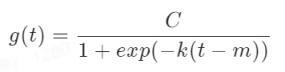
其中 C 为增长上界,k 为增长率,m 是 offset。如果将此函数绘图出来,我们可以看到它的变化类似于自然界人口增长与动物繁殖所呈现出的“S 曲线":
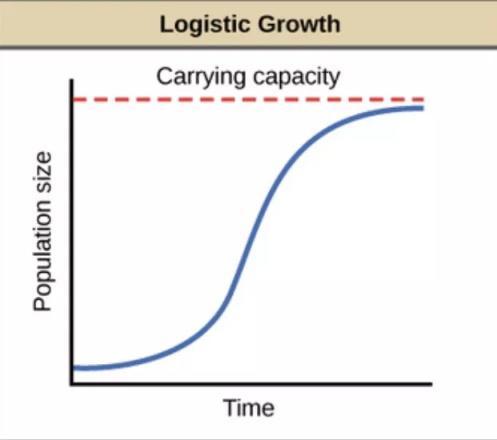
此类函数尤其适用于对流量、人口等有指数增长特性的数据进行建模。Prophet 对 Logistic growth function 做出了一定改进,使得它能够拟合更多特别类型的指数增长数据,例如用户增长数据等。Linear growth 就是捕捉数据中趋势的线性部分。所以针对不同的数据增长模式,我们将根据具体数据情况进行选择。
但是很多时候数据中的趋势又不是一成不变的,改变一些数据背后的生成机制就会影响数据的增长趋势。例如在用户增长中,如果商家给予新用户更多的激励,就会导致其增长趋势发生变化。因此 Prophet 模型中在趋势中引入了变点,在进行预测前使用者可以提前设置变点。如果使用者没有提前设置,Prophet 模型也可以进行变点检测以来适应趋势的变化,从而更加精准地拟合数据。
对周期项,Prophet 模型采取了拟合傅里叶级数的方式:
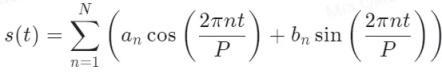
其中
![]()
为参数
P 为周期。Prophet 模型中可同时拟合多个周期,并设置每个周期的傅里叶阶数,阶数如果设置过大,会造成过拟合并且耗费不必要的计算资源。一般建议年周期用 10 阶傅里叶。没有一定的标准,可根据数据实际情况再动态调整。
节假日项是专门针对节假日和特殊事件影响而设计的一个特殊回归项。由于受种种客观因素制约,且周期不明确,节假日往往很难描述其变化。例如农历的清明节,促销活动之类。而时间序列数据受这些时间的影响十分明显,例如,在商场促销期间,其商场销售额会有明显的提升。在清明假期,景区的游客量明显高于平时。所以将节假日和特殊时间的影响加入模型的考虑中来是十分必要且有效的,这也是 Prophet 模型之所以得到广泛应用的一个重要原因。
此外 Prophet 模型可根据实际业务的需要加入外部回归项。例如,在统计自行车骑行人数时,如果只考虑骑行人数这一个指标的话,预测往往会出现很大偏差。这时,如果将天气因素作为外部回归项加入进来,预测精度会得到大大提升。需要注意的是,周期项、节假日项和外部回归项在 Prophet 模型实际估计的时候,其处理的方式是完全一致的,都是作为多元回归中的一元或多元进行回归,因此学者在形容它时,常说 Prophet 模型是一个对时间回归的模型。
四、Prophet 与 ARIMA 模型的对比
与 ARIMA 不同,Prophet 的模型训练采用了贝叶斯的框架,即对模型参数设置先验分布,通过最大后验(Max a Posterior)的方式去估计模型参数。对比于 ARIMA,Prophet 具有处理时间序列中的变点和节假日的能力,使得它在工业中得到了更为广泛的应用。不过要是想将这一工具用好,我们往往需要对其提供充分正确的信息,如节假日信息、参数的先验分布等。
Prophet 在提供的傅立叶级数 n 较低的情况下,往往会拟合出一条较为平滑的曲线,这在一些预测任务上有特别的价值,比如还原时间序列原本的模式。如下图所示,对同样的低信噪比周期数据,ARIMA 模型(经过周期分解预处理)会倾向于拟合较为复杂的尖峰波动,而线性增长 Prophet 模型仅仅是在做傅立叶级数的拟合,N 则决定了拟合曲线的平滑程度。
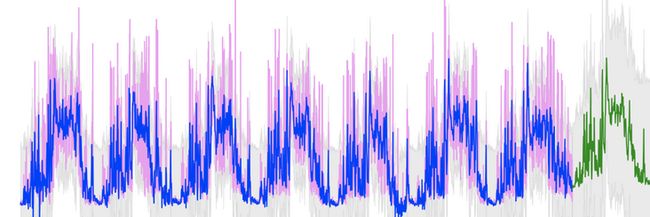
ARIMA 预测效果图

线性 Prophet 预测效果图
可以看出,对于时间序列预测问题,ARIMA 和 Prophet 采取了截然不同的两种角度。从建模的角度来说,ARIMA 试图拟合生成差分后的时间序列的平稳随机过程,而 Prophet 则是对时间序列的不同成分分别建立回归模型。从训练的角度来说,ARIMA 采用了极大似然估计,在对噪音的独立同分布高斯假设下,其最后对每一个时间点的预测分布依旧是一种高斯分布,所以 ARIMA 模型的预测上下界可以准确的通过预测分布计算出。而 Prophet 模型的预测分布则不存在一个闭式,使得 Prophet 的预测上下界往往具有随机性。
五、总结
在深度学习大行其道的今天,经典的统计时序模型并没有失去其应用价值,反而在很多实际问题上表现出了其特有的优势,比如良好的结果鲁棒性、可解释性和易于落地等。现在经典统计模型其背后的思想亦是很多深度学习框架灵感的来源。智能运维领域时间序列预测的发展则依赖于算法模型的性能。
未来如何使经典模型的优势在实际应用中大放异彩?又如何将其思想与深度学习相结合开发出更适合数字化发展的算法?或将是智能运维算法开发人员研究的首要任务。
开源福利
云智慧已开源数据可视化编排平台 FlyFish 。通过配置数据模型为用户提供上百种可视化图形组件,零编码即可实现符合自己业务需求的炫酷可视化大屏。 同时,飞鱼也提供了灵活的拓展能力,支持组件开发、自定义函数与全局事件等配置, 面向复杂需求场景能够保证高效开发与交付。
点击下方地址链接,欢迎大家给 FlyFish 点赞送 Star。参与组件开发,更有万元现金等你来拿。
GitHub 地址: https://github.com/CloudWise-...
Gitee 地址:https://gitee.com/CloudWise/f...
万元现金福利: http://bbs.aiops.cloudwise.co...
微信扫描识别下方二维码,备注【飞鱼】加入AIOps社区飞鱼开发者交流群,与 FlyFish 项目 PMC 面对面交流~

参考文献
[1]Box, George E. P., and Gwilym M. Jenkins. 1976. Time series analysis: forecasting and control. San Francisco: Holden-Day.
[2]Wikipedia contributors, "Autoregressive integrated moving average," Wikipedia, The Free Encyclopedia, https://en.wikipedia.org/w/index.php?title=Autoregressive_integrated_moving_average&oldid=1020508954 (accessed December 7, 2021).
[3]Taylor SJ, Letham B. 2017. Forecasting at scale. PeerJ Preprints 5:e3190v2 https://doi.org/10.7287/peerj.preprints.3190v2