计算机视觉学习建议
装载自:https://blog.csdn.net/gdengden/article/details/80369458#commentBox
目录
- 简介
- 方向
- 热点
简介
计算机视觉(Computer Vision)又称为机器视觉(Machine Vision),顾名思义是一门“教”会计算机如何去“看”世界的学科。在机器学习大热的前景之下,计算机视觉与自然语言处理(Natural Language Process, NLP)及语音识别(Speech Recognition)并列为机器学习方向的三大热点方向。而计算机视觉也由诸如梯度方向直方图(Histogram of Gradient, HOG)以及尺度不变特征变换(Scale-Invariant Feature Transform, SIFT)等传统的手办特征(Hand-Crafted Feature)与浅层模型的组合逐渐转向了以卷积神经网络(Convolutional Neural Network, CNN)为代表的深度学习模型。
| 方式 | 特征提取 | 决策模型 |
|---|---|---|
| 传统方式 | SIFT,HOG, Raw Pixel … | SVM, Random Forest, Linear Regression … |
| 深度学习 | CNN … | CNN … |
svm(Support Vector Machine) : 支持向量机
Random Forest : 随机森林
Linear Regression : 线性回归
Raw Pixel : 原始像素
传统的计算机视觉对待问题的解决方案基本上都是遵循: 图像预处理 → 提取特征 → 建立模型(分类器/回归器) → 输出 的流程。 而在深度学习中,大多问题都会采用端到端(End to End)的解决思路,即从输入到输出一气呵成。本次计算机视觉的入门系列,将会从浅层学习入手,由浅入深过渡到深度学习方面。
方向
计算机视觉本身又包括了诸多不同的研究方向,比较基础和热门的几个方向主要包括了:物体识别和检测(Object Detection),语义分割(Semantic Segmentation),运动和跟踪(Motion & Tracking),三维重建(3D Reconstruction),视觉问答(Visual Question & Answering),动作识别(Action Recognition)等。
物体识别和检测
物体检测一直是计算机视觉中非常基础且重要的一个研究方向,大多数新的算法或深度学习网络结构都首先在物体检测中得以应用如VGG-net, GoogLeNet, ResNet等等,每年在imagenet数据集上面都不断有新的算法涌现,一次次突破历史,创下新的记录,而这些新的算法或网络结构很快就会成为这一年的热点,并被改进应用到计算机视觉中的其它应用中去,可以说很多灌水的文章也应运而生。
物体识别和检测,顾名思义,即给定一张输入图片,算法能够自动找出图片中的常见物体,并将其所属类别及位置输出出来。当然也就衍生出了诸如人脸检测(Face Detection),车辆检测(Viechle Detection)等细分类的检测算法。
近年代表论文
- He, Kaiming, et al. “Deep residual learning for image recognition.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016.
- Liu, Wei, et al. “SSD: Single shot multibox detector.” European Conference on Computer Vision. Springer International Publishing, 2016.
- Szegedy, Christian, et al. “Going deeper with convolutions.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2015.
- Ren, Shaoqing, et al. “Faster r-cnn: Towards real-time object detection with region proposal networks.” Advances in neural information processing systems. 2015.
- Simonyan, Karen, and Andrew Zisserman. “Very deep convolutional networks for large-scale image recognition.” arXiv preprint arXiv:1409.1556 (2014).
- Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. “Imagenet classification with deep convolutional neural networks.” Advances in neural information processing systems. 2012.
数据集
- IMAGENET
- PASCAL VOC
- MS COCO
- Caltech
语义分割
语义分割是近年来非常热门的方向,简单来说,它其实可以看做一种特殊的分类——将输入图像的每一个像素点进行归类,用一张图就可以很清晰地描述出来。 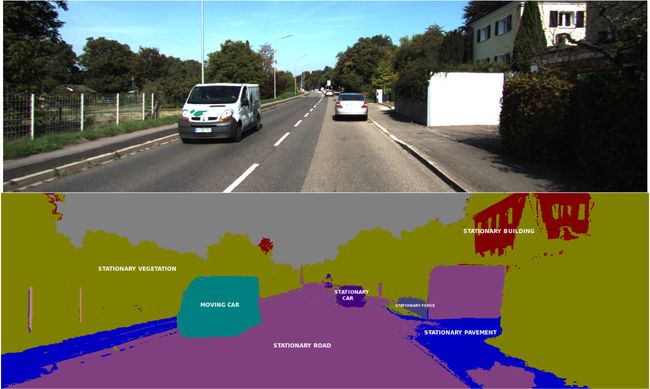
很清楚地就可以看出,物体检测和识别通常是将物体在原图像上框出,可以说是“宏观”上的物体,而语义分割是从每一个像素上进行分类,图像中的每一个像素都有属于自己的类别。
近年代表论文
- Long, Jonathan, Evan Shelhamer, and Trevor Darrell. “Fully convolutional networks for semantic segmentation.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2015.
- Chen, Liang-Chieh, et al. “Semantic image segmentation with deep convolutional nets and fully connected crfs.” arXiv preprint arXiv:1412.7062 (2014).
- Noh, Hyeonwoo, Seunghoon Hong, and Bohyung Han. “Learning deconvolution network for semantic segmentation.” Proceedings of the IEEE International Conference on Computer Vision. 2015.
- Zheng, Shuai, et al. “Conditional random fields as recurrent neural networks.” Proceedings of the IEEE International Conference on Computer Vision. 2015.
数据集
- PASCAL VOC
- MS COCO
运动和跟踪
跟踪也属于计算机视觉领域内的基础问题之一,在近年来也得到了非常充足的发展,方法也由过去的非深度算法跨越向了深度学习算法,精度也越来越高,不过实时的深度学习跟踪算法精度一直难以提升,而精度非常高的跟踪算法的速度又十分之慢,因此在实际应用中也很难派上用场。
那么什么是跟踪呢?就目前而言,学术界对待跟踪的评判标准主要是在一段给定的视频中,在第一帧给出被跟踪物体的位置及尺度大小,在后续的视频当中,跟踪算法需要从视频中去寻找到被跟踪物体的位置,并适应各类光照变换,运动模糊以及表观的变化等。但实际上跟踪是一个不适定问题(ill posed problem),比如跟踪一辆车,如果从车的尾部开始跟踪,若是车辆在行进过程中表观发生了非常大的变化,如旋转了180度变成了侧面,那么现有的跟踪算法很大的可能性是跟踪不到的,因为它们的模型大多基于第一帧的学习,虽然在随后的跟踪过程中也会更新,但受限于训练样本过少,所以难以得到一个良好的跟踪模型,在被跟踪物体的表观发生巨大变化时,就难以适应了。所以,就目前而言,跟踪算不上是计算机视觉内特别热门的一个研究方向,很多算法都改进自检测或识别算法。 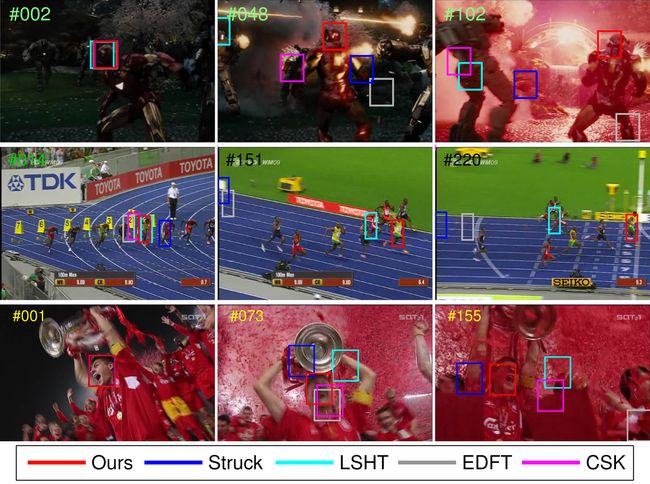
近年代表论文
- Nam, Hyeonseob, and Bohyung Han. “Learning multi-domain convolutional neural networks for visual tracking.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016.
- Held, David, Sebastian Thrun, and Silvio Savarese. “Learning to track at 100 fps with deep regression networks.” European Conference on Computer Vision. Springer International Publishing, 2016.
- Henriques, João F., et al. “High-speed tracking with kernelized correlation filters.” IEEE Transactions on Pattern Analysis and Machine Intelligence 37.3 (2015): 583-596.
- Ma, Chao, et al. “Hierarchical convolutional features for visual tracking.” Proceedings of the IEEE International Conference on Computer Vision. 2015.
- Bertinetto, Luca, et al. “Fully-convolutional siamese networks for object tracking.” European Conference on Computer Vision. Springer International Publishing, 2016.
- Danelljan, Martin, et al. “Beyond correlation filters: Learning continuous convolution operators for visual tracking.” European Conference on Computer Vision. Springer International Publishing, 2016.
- Li, Hanxi, Yi Li, and Fatih Porikli. “Deeptrack: Learning discriminative feature representations online for robust visual tracking.” IEEE Transactions on Image Processing 25.4 (2016): 1834-1848.
数据集
- OTB(Object Tracking Benchmark)
- VOT(Visual Object Tracking)
视觉问答
视觉问答也简称VQA(Visual Question Answering),是近年来非常热门的一个方向,其研究目的旨在根据输入图像,由用户进行提问,而算法自动根据提问内容进行回答。除了问答以外,还有一种算法被称为标题生成算法(Caption Generation),即计算机根据图像自动生成一段描述该图像的文本,而不进行问答。对于这类跨越两种数据形态(如文本和图像)的算法,有时候也可以称之为多模态,或跨模态问题。 
近年代表论文
- Xiong, Caiming, Stephen Merity, and Richard Socher. “Dynamic memory networks for visual and textual question answering.” arXiv 1603 (2016).
- Wu, Qi, et al. “Ask me anything: Free-form visual question answering based on knowledge from external sources.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016.
- Zhu, Yuke, et al. “Visual7w: Grounded question answering in images.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016.
数据集
- VQA
热点
随着深度学习的大举侵入,现在几乎所有人工智能方向的研究论文几乎都被深度学习占领了,传统方法已经很难见到了。有时候在深度网络上改进一个非常小的地方,就可以发一篇还不错的论文。并且,随着深度学习的发展,很多领域的现有数据集内的记录都在不断刷新,已经向人类记录步步紧逼,有的方面甚至已经超越了人类的识别能力。那么,下一步的研究热点到底会在什么方向呢?就我个人的一些观点如下:
- 多模态研究: 目前的许多领域还是仅仅停留在单一的模态上,如单一分物体检测,物体识别等,而众所周知的是现实世界就是有多模态数据构成的,语音,图像,文字等等。 VQA 在近年来兴起的趋势可见,未来几年内,多模态的研究方向还是比较有前景的,如语音和图像结合,图像和文字结合,文字和语音结合等等。
- 数据生成: 现在机器学习领域的许多数据还是由现实世界拍摄的视频及图片经过人工标注后用作于训练或测试数据的,标注人员的职业素养和经验,以及多人标注下的规则统一难度在一定程度上也直接影响了模型的最终结果。而利用深度模型自动生成数据已经成为了一个新的研究热点方向,如何使用算法来自动生成数据相信在未来一段时间内都是不错的研究热点。
无监督学习:人脑的在学习过程中有许多时间都是无监督(Un-supervised Learning)的,而现有的算法无论是检测也好识别也好,在训练上都是依赖于人工标注的有监督(Supervised Learning)。如何将机器学习从有监督学习转变向无监督学习,应该是一个比较有挑战性的研究方向,当然这里的无监督学习当然不是指简单的如聚类算法(Clustering)这样的无监督算法。而LeCun也曾说: 如果将人工智能比喻作一块蛋糕的话,有监督学习只能算是蛋糕上的糖霜,而增强学习(Reinforce Learning)则是蛋糕上的樱桃,无监督学习才是真正蛋糕的本体。
最后,想要把握领域内最新的研究成果和动态,还需要多看论文,多写代码。
计算机视觉领域内的三大顶级会议有:Conference on Computer Vision and Pattern Recognition (CVPR)
International Conference on Computer Vision (ICCV)
European Conference on Computer Vision (ECCV)较好的会议有以下几个:
The British Machine Vision Conference (BMVC)
International Conference on Image Processing (ICIP)
Winter Conference on Applications of Computer Vision (WACV)
Asian Conference on Computer Vision (ACCV)
当然,毕竟文章的发表需要历经审稿和出版的阶段,因此当会议论文集出版的时候很可能已经过了小半年了,如果想要了解最新的研究,建议每天都上ArXiv的cv板块看看,ArXiv上都是预出版的文章,并不一定最终会被各类会议和期刊接收,所以质量也就良莠不齐,对于没有分辨能力的入门新手而言,还是建议从顶会和顶级期刊上的经典论文入手。
这是一篇对计算机视觉目前研究领域的几个热门方向的一个非常非常简单的介绍,希望能对想要入坑计算机视觉方向的同学有一定的帮助。由于个人水平十分有限,错误在所难免,欢迎大家对文中的错误进行批评和指正。
小白入门计算机视觉:这是最全的一份CV技术学习之路
AI
菌
最近AI菌决定把自己的机器学习之路向计算机视觉方面发展。所以今天就来给大家分享一下AI菌收集到的资料以及心得
The M Tank 编辑了一份报告《A Year in Computer Vision》,记录了 2016 至 2017 年计算机视觉领域的研究成果,对开发者和研究人员来说是不可多得的一份详细材料。该材料共包括四大部分
简介
第一部分
分类/定位
目标检测
目标追踪
第二部分
分割
超分辨率、风格迁移、着色
动作识别
第三部分
3D 目标
人体姿势估计
3D 重建
其他未分类 3D
总结
第四部分
卷积架构
数据集
不可分类的其他材料与有趣趋势
结论
有兴趣的同学可以读一读,完整 PDF 地址:http://www.themtank.org/pdfs/AYearofComputerVisionPDF.pdf
下面是收集到的学习资料与心得的汇总:
(文中没有发的资源将在之后陆续放出)
01 掌握好相应的基础能力
计算机视觉的理念其实与很多概念有部分重叠,包括:人工智能、数字图像处理、机器学习、深度学习、模式识别、概率图模型、科学计算以及一系列的数学计算等。
所以在入门CV之前,同学们最好对基础的学术课程都有对应的了解,比如数学方面的微积分,概率学,统计学,线性代数这几门基础课程。
在编程语言方面,Matlab,Python,C++,最好熟悉其中2种,因为计算机视觉离开计算机编程是完全行不通的
02 需要的专业工具
工欲善其事,必先利其器。对于想要学好计算机视觉的同学来说,一个专业的工具,绝对是助攻的不二神器。
OpenCV(开源计算机视觉库)是一个非常强大的学习资料库,包括了计算机视觉,模式识别,图像处理等许多基本算法。
它免费提供给学术和商业用途,有C++,C,Python和java接口,支持Windows、Linux、Mac OS、iOS和Android。
而关于OpenCV的学习,AI菌推荐(其中第三本目前无中文版):
学习OpenCV(Learning.OpenCV)
链接:
https://pan.baidu.com/s/1c2GrPEK 密码:7012
毛星云老师编著的OpenCV3编程入门
链接:
https://pan.baidu.com/s/1c2xuVFq 密码:2s4a
学习OpenCV3(
Learning OpenCV 3
)
链接:
https://pan.baidu.com/s/1geQeT0J 密码:cuco
而深度学习方面,有TensorFlow,PyTorch,Caffe等深度学习框架,它们也内置了OpenCV的API接口。而哪种框架好,就要看你自己的需要了
推荐资料:
莫凡教程系列之PyTorch :https://morvanzhou.github.io/tutorials/machine-learning/torch/
TensorFlow中文社区:
http://www.tensorfly.cn/
深度学习 21天实战Caffe
03 绕不开的数字图像处理与模式识别
数字图像处理(Digital Image Processing)是通过计算机对图像进行去除噪声、增强、复原、分割、提取特征等处理的方法和技术。
入门的同学推荐
冈萨雷斯的《数字图像处理》《数字图像处理(第3版)(英文版)》和对应的Matlab版本
一本讲基础的理论,一本讲怎么用Matlab实现。
除此之外同学们还可以去YouTube上找到相关的课程信息,相信大家会有所收获的。
模式识别(Pattern Recognition),就是通过计算机用数学技术方法来研究模式的自动处理和判读。我们把环境与客体统称为“模式”。
计算机视觉很多东西都是基于图像识别的,图像识别就是模式识别的一种。
模式识别通常是训练一个模型来拟合当前的数据,当我们拿到一堆数据或图片,需要从当中找到它们的关系,最便捷的便是用模式识别算法来训练一个模型。
AI菌推荐一本模式识别入门级的教材《模式分类》,相对于《模式识别》这本书来说可能比较难,但书中介绍了很多模式识别经典的分类器,还是很值得一读。
其中的一些思想在神经网络中也可以应用的
04 系统的学习下计算机视觉课程
对于CV新手来说,想要从小白到大神,最快的方法就是先系统的学习一下计算机视觉的课程,全面了解一下计算机视觉这个领域的背景及其发展、这个领域有哪些基本的问题、哪些问题的研究已经比较成熟了,哪些问题的研究还处于基础阶段。
在这里AI菌推荐3本经典教材:
《计算机视觉:一种现代方法》(Computer Vision: A Modern Approach)
《计算机视觉_算法与应用》
(Computer Vision: Algorithms and Applications)
《计算机视觉:模型 学习和推理》
(Computer Vision: Models, Learning, and Inference)
这三本教材AI菌认为是计算机视觉最好的入门教材了,内容丰富,难度适中,其中第二本书涉及大量的文献,很适合对计算机视觉没什么概念的同学。
虽然其中的一些方法在现在看来已经过时了,但还是值得一读
05 深度学习与CNN
关于深度学习这几年讲的已经太多了,资料也非常多,AI菌在这里就不在赘述啦
计算机视觉里经常使卷积神经网络,即CNN,是一种对人脑比较精准的模拟。
什么是卷积?卷积就是两个函数之间的相互关系,然后得出一个新的值,他是在连续空间做积分计算,然后在离散空间内求和的过程。
同学们可以试着学习下CNN在计算机视觉当中的应用
推荐的资料:
斯坦福CS231n—深度学习与计算机视觉网易云课堂课程:http://study.163.com/course/introduction.htm?courseId=1003223001
斯坦福CS231n—深度学习与计算机视觉官方课程:http://cs231n.stanford.edu/
CS231n官方笔记授权翻译总集篇:https://www.52ml.net/17723.html
吴恩达 deeplearning.ai与网易云课堂的微专业深度学习工程师卷积神经网络
http://mooc.study.163.com/course/2001281004?tid=2001392030#/info
神经网络方面的经典教材
《深度学习》
(Deep Learning)
《神经⽹络与深度学习》
(Neural Networks and Deep Learning(Nielsen,2017))
06 了解最新领域动态
很多同学做研究的时候,容易陷入自我封闭的“怪圈”,过于执着于埋头学习相关知识,有时候会忘记及时了解相关领域的最新动态,这是非常不科学的。
同学们在学习计算机视觉相关知识的时候,可以通过最新的paper来了解这个领域最新提出的一些概念以及发展的情况。
计算机视觉的期刊有两个PAMI(模式分析与机器智能汇刊)和IJCV(计算机视觉国际期刊)
顶级的学术会议有 CVPR、ICCV、 ECCV、 BMVC这四个,同学们可以跟着浏览这些期刊论文以及会议文章,相信一定可以学到不少有用的知识。
AI
菌
听做视觉的师兄师姐硕:做好计算机视觉研究并不是一件容易的事情,在大多数情况下它甚至是一件很枯燥的事情。
研究成果毫无进展,研究方向不在明朗等等,这一切都会给你前所未有的压力
所以希望同学们在决定入这一行的时候,是出于自己的热爱,而不是出于当前的趋势。
因为热爱不会变,但趋势每一年都在变。
计算机视觉是人工智能技术的一个重要领域,打个比方(不一定恰当),我认为计算机视觉是人工智能时代的眼睛,可见其重要程度。计算机视觉其实是一个很宏大的概念,下图是有人总结的计算机视觉所需要的技能树。 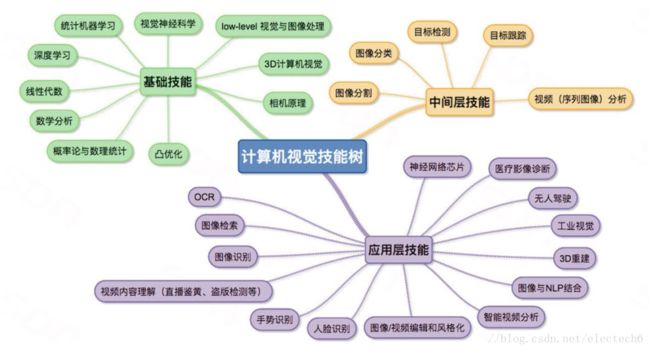
如果你是一个对计算机视觉一无所知的小白,千万不要被这棵技能树吓到。没有哪个人能够同时掌握以上所有的技能,这棵树只是让你对计算机视觉有个粗浅的认识。
以下是我站在一个小白的视角给出一个入门计算机视觉的相对轻松的姿势。
一、宏观认识
小白通常看到这么多的细分方向大脑一片茫然,到底是学习人脸识别、物体跟踪,又或者是计算摄影,三维重建呢?不知道该怎么下手。其实这些细分方向有很多共通的知识,我的建议是心急吃不了热豆腐,只有对计算机视觉这个领域有了一个初步的全面了解,你才能够结合实际问题找到自己感兴趣的研究方向,而兴趣能够支持一个自学的小白克服困难持续走下去。
1、入门书籍
既然说是入门,这里就不推荐类似《 Multiple View Geometry in Computer Vision》这种虽然经典但是小白看了容易放弃的书了。
像素级的图像处理知识是计算机视觉的底层基础知识。不管你以后从事计算机视觉的哪个细分领域,这些基础知识都是必须要了解的。即使一个急切入门的小白,这一关也必须走的踏实。看到网上有人说直接从某个项目开始,边做边学,这样学的快。对此我表示部分赞成,原因是他忽略了基础知识的重要性,脑子里没有基本的术语概念知识打底,很多问题他根本不知道如何恰当的表达,遇到问题也没有思路,不知道如何搜索,这会严重拖慢进度,也无法做较深入的研究,欲速则不达。
入门图像处理的基础知识也不是直接去啃死书,否则几个公式和术语可能就会把小白打翻在地。这里推荐两条途径,都是从实践出发并与理论结合:一个是OpenCV,一个是MATLAB。
OpenCV以C++为基础,需要具备一定的编程基础,可移植性强,运行速度比较快,比较适合实际的工程项目,在公司里用的较多;MATLAB只需要非常简单的编程基础就可以很快上手,实现方便,代码比较简洁,可参考的资料非常丰富,方便快速尝试某个算法效果,适合做学术研究。当然两者搭配起来用更好啦。下面分别介绍一下。
用MATLAB学习图像处理
推荐使用冈萨雷斯的《数字图像处理(MATLAB版)》(英文原版2001年出版,中译版2005年)。不需要一上来就全部过一遍,只需要结合MATLAB学习一下基本原理、图像变换、形态学处理、图像分割,以上章节强烈建议按照书上手动敲一遍代码(和看一遍的效果完全不同),其他章节可快速扫描一遍即可。但这本书比较注重实践,对理论的解释不多,理论部分不明白的可以在配套的冈萨雷斯的《数字图像处理(第二版)》这本书里查找,这本书主要是作为工具书使用,以后遇到相关术语知道去哪里查就好。 
用OpenCV学习图像处理
OpenCV(Open Source Computer Vision Library)是一个开源跨平台计算机视觉程序库,主要有C++预研编写,包含了500多个用于图像/视频处理和计算机视觉的通用算法。
学习OpenCV参考《学习OpenCV》或者《OpenCV 2 计算机视觉编程手册》都可以。这两本都是偏实践的书,理论知识较少,按照书上的步骤敲代码,可以快速了解到OpenCV的强大,想要实现某个功能,只要学会查函数(在https://www.docs.opencv.org/查询对应版本),调函数就可以轻松搞定。由于每个例子都有非常直观的可视化图像输出,所以学起来比较轻松有趣。 
2、进阶书籍
经过前面对图像处理的基本学习,小白已经了解了图像处理的基础知识,并且会使用OpenCV或MATLAB来实现某个简单的功能。但是这些知识太单薄了,并且比较陈旧,计算机视觉领域还有大量的新知识在等你。
同样给你两种选择,当然两个都选更佳。一本书是2010年出版的美国华盛顿大学Richard Szeliski写的《Computer Vision: Algorithms and Application》;一本是2012年出版的,加拿大多伦多大学Simon J.D. Prince写的《Computer Vision: Models, Learning, and Inference》。两本书侧重点不同,前者侧重视觉和几何知识,后者侧重机器学习模型。当然两本书也有互相交叉的部分。虽然都有中文版,但是如果有一定的英语阅读基础,推荐看英文原版(见文末获取方式)。老外写的书,图和示例还是挺丰富的,比较利于 理解。
《Computer Vision: Algorithms and Application》
这本书图文并茂地介绍了计算机视觉这门学科的诸多大方向,有了前面《数字图像处理》的基础,这本书里有些内容你已经熟悉了,没有那么强的畏惧感。相对前面的图像处理基础本书增加了许多新的内容,比如特征检测匹配、运动恢复结构、稠密运动估计、图像拼接、计算摄影、立体匹配、三维重建等,这些都是目前比较火非常实用的方向。如果有时间可以全书浏览,如果时间不够,你可以根据兴趣,选择性的看一些感兴趣的方向。这本书的中文版翻译的不太好,可以结合英文原版看。
《Computer Vision: Models, Learning, and Inference》
该书从基础的概率模型讲起,涵盖了计算机视觉领域常用的概率模型、回归分类模型、图模型、优化方法等,以及偏底层的图像处理、多视角几何知识,图文并茂,并辅以非常多的例子和应用,非常适合入门。在其主页:
http://www.computervisionmodels.com/
上可以免费下载电子书。此外还有非常丰富的学习资源,包括给教师用的PPT、每章节对应的开源项目、代码、数据集链接等,非常有用。 
二、深入实践
当你对计算机视觉领域有了比较宏观的了解,下一步就是选一个感兴趣的具体的领域去深耕。这个时期就是具体编程实践环节啦,实践过程中有疑问,根据相关术语去书里查找,结合Google,基本能够解决你大部分问题。
那么具体选择什么方向呢?
如果你实验室或者公司有实际的项目,最好选择当前项目方向深耕下去。如果没有具体方向,那么继续往下看。
我个人认为计算机视觉可以分为两大方向:基于学习的方法和基于几何的方法。其中基于学习的方法最火的就是深度学习,而基于几何方法最火的就是视觉SLAM。下面就这两个方向给出一个相对轻松的入门姿势。
1、深度学习
深度学习(Deep Learning)的概念是Hinton等人于2006年提出的,最早最成功的应用领域就是计算机视觉,经典的卷积神经网络就是为专门处理图片数据而生。目前深度学习已经广泛应用在计算机视觉、语音识别、自然语言处理、智能推荐等领域。
学习深度学习需要一定的数学基础,包括微积分、线性代数,很多小白一听到这些课程就想起了大学时的噩梦,其实只用了非常基础的概念,完全不用担心。不过如果一上来就啃书本,可能会有强烈的畏难情绪,很容易早早的放弃。
Andrew Ng (吴恩达)的深度学习视频课程我觉得是一个非常好的入门资料。首先他本人就是斯坦福大学的教授,所以很了解学生,可以很清晰形象、深入浅出的从最基本的导数开始讲起,真的非常难得。 
该课程可以在网易云课程上免费观看,有中文字幕,但没有配套习题。也可以在吴恩达自己创办的在线教育平台Coursera上学习,有配套习题,限时免费,结业通过后有相应证书。
该课程非常火爆,不用担心听不懂,网上有数不清的学习笔记可以参考。简直小白入门必备佳肴。
2、视觉SLAM
SLAM(Simultaneous Localization and Mapping)(详见《SLAM初识》),中文译作同时定位与地图创建。视觉SLAM就是用摄像头作为主传感器,用拍摄的视频流作为输入来实现SLAM。视觉SLAM广泛应用于VR/AR、自动驾驶、智能机器人、无人机等前沿领域。
视觉SLAM最好的入门资料是高翔(清华博士,慕尼黑理工博后)的《视觉SLAM十四讲-从理论到实践》。该书每章节都涵盖了基础理论和代码示例,深入浅出,非常注重理论与实践结合,大大降低了小白的学习门槛。 
好了,入门介绍到此为止,你可以开始你的计算机视觉学习之旅了! 
温馨提示:本文提到的部分书籍资料,公众号:“计算机视觉life” 已经为你准备好了,公众号下方回复“入门”即可获取。
以下内容整理自 2017 年 6 月 29 日由“趣直播–知识直播平台”邀请的嘉宾实录。
分享嘉宾: 罗韵
目前,人工智能,机器学习,深度学习,计算机视觉等已经成为新时代的风向标。这篇文章主要介绍了下面几点:
第一点,如果说你要入门计算机视觉,需要了解哪一些基础知识?
第二点,既然你要往这方面学习,你要了解的参考书籍,可以学习的一些公开课有哪些?
第三点,可能是大家都比较感兴趣的,就是计算机视觉作为人工智能的一个分支,它不可避免的要跟深度学习做结合,而深度学习也可以说是融合到了计算机视觉、图像处理,包括我们说的自然语言处理,所以本文也会简单介绍一下计算机视觉与深度学习的结合。
第四点,身处计算机领域,我们不可避免的会去做开源的工作,所以本文会给大家介绍一些开源的软件。
第五点,要学习或者研究计算机视觉,肯定是需要去阅读一些文献的,那么我们如何开始阅读文献,以及慢慢的找到自己在这个领域的方向,这些都会在本文理进行简单的介绍。
1.基础知识
接下来要介绍的,第一点是计算机视觉是什么意思,其次是图像、视频的一些基础知识。包括摄像机的硬件,以及 CPU 和 GPU 的运算。
在计算机视觉里面,我们也不可避免的会涉及到考虑去使用 CPU 还是使用 GPU 去做运算。然后就是它跟其他学科的交叉,因为计算机视觉可以和很多的学科做交叉,而且在做学科交叉的时候,能够发挥的意义和使用价值也会更大。另外,对于以前并不是做人工智能的朋友,可能是做软件开发的,想去转型做计算机视觉,该如何转型?需要学习哪些编程语言以及数学基础?这些都会在第一小节给大家介绍。
1.0 什么是计算机视觉
计算机视觉是一门研究如何使机器“看”的科学。
更进一步的说,就是指用摄影机和电脑代替人眼对目标进行识别、跟踪和测量等机器视觉,并进一步做图形处理,使电脑处理成为更适合人眼观察或传送给一起检测的图像
作为一个科学学科,计算机视觉研究相关的理论和技术,视图建立能够从图像或者多维数据中获取“信息”的人工智能系统。
目前,非常火的VR、AR,3D处理等方向,都是计算机视觉的一部分。
计算机视觉的应用
- 无人驾驶
- 无人安防
- 人脸识别
- 车辆车牌识别
- 以图搜图
- VR/AR
- 3D重构
- 医学图像分析
- 无人机
- 其他
了解了计算机视觉是什么之后,给大家列了一下当前计算机视觉领域的一些应用,几乎可以说是无处不在,而且当前最火的所有创业的方向都涵盖在里面了。其中包括我们经常提到的无人驾驶、无人安防、人脸识别。人脸识别相对来说已经是一个最成熟的应用领域了,然后还有文字识别、车辆车牌识别,还有以图搜图、 VR/AR,还包括 3D 重构,以及当下很有前景的领域–医学图像分析。
医学图像分析他在很早就被提出来了,已经研究了很久,但是现在得到了一个重新的发展,更多的研究人员包括无论是做图像的研究人员,还是本身就在医疗领域的研究人员,都越来越关注计算机视觉、人工智能跟医学图像的分析。而且在当下,医学图像分析也孕育了不少的创业公司,这个方向的未来前景还是很值得期待的。然后除此之外还包括无人机,无人驾驶等,都应用到了计算机视觉的技术。
1.1图像和视频,你要知道的概念
- 图像
一张图片包含了:维数、高度、宽度、深度、通道数、颜色格式、数据首地址、结束地址、数据量等等。
- 图像深度:存储每个像素所用的位数(bits)
- 当一个像素占用的位数越多时,它所能表现的颜色就更多,更丰富。
- 举例:一张400*400的8位图,这张图的原始数据量是多少?像素值如果是整型的话,取值范围是多少?
1,原始数据量计算:400 * 400 * ( 8/8 )=160,000Bytes
(约为160K)
2,取值范围:2的8次方,0~255
- 图片格式与压缩:常见的图片格式JPEG,PNG,BMP等本质上都是图片的一种压缩编码方式
- 举例:JPEG压缩
1,将原始图像分为8*8的小块,每个block里有64pixels。
2,将图像中每个8*8的block进行DCT变换(越是复杂的图像,越不容易被压缩)
3,不同的图像被分割后,每个小块的复杂度不一样,所以最终的压缩结果也不一样
- 举例:JPEG压缩
- 图像深度:存储每个像素所用的位数(bits)
- 视频
原始视频=图片序列。
视频中的每张有序图片称为“帧(frame)”。压缩后的视频,会采取各种算法减少数据的容量,其中IPB就是最常见的。
- I帧:表示关键帧,可以理解为这一幅画面的完整保留;解码时只需要本帧数据就可以完成(因为包含完整画面)
- P帧:表示的是这一帧跟之前的一个关键帧(或P帧)的差别,解码时需要用之前缓存的画面叠加上本帧定义的差别,生成最终画面。(也就是差别帧,P帧没有完整画面数据,只有与前一帧画面差别的数据)
- B帧表示双向差别帧,记录的本帧与前后帧的差别(具体比较复杂,有4种情况),换言之,要解码B帧,不仅要取得之前的缓存画面,还要解码之后的画面,要通过前后画面与本帧数据的叠加取得最终的画面。B帧压缩率高,但是解码比较麻烦。
- 码率:码率越大,体积越大;码率越小,体积越小。
码率就是数据传输时单位时间传送的数据位数,一般我们用的单位是kbps即千位每秒。也就是取样率(并不等同于采样率,采样率用的单位是Hz,表示每秒采样的次数),单位时间内取样率越大,精度就越高,处理出来的文件就越接近原始文件,但是文件体积与取样率是成正比的,所以几乎所有的编码格式重视的都是如何用最低的码率达到最少的失真,围绕这个核心衍生出来cbr(固定码率)与vbr(可变码率),码率越高越清晰,反之则画面粗糙而且多马赛克。 - 帧率
影响画面流畅度,与画面流畅度成正比:帧率越大,画面越流畅;帧率越小,画面越有跳动感。如果码率为变量,则帧率也会影响体积,帧率越高,每秒钟经过的画面就越多,需要的码率也越高,体积也越大。
帧率就是在一秒钟时间里传输的图片的帧数,也可以理解为图形处理器每秒钟刷新的次数。 - 分辨率
- 影响图像大小,与图像大小成正比;分辨率越高,图像越大;分辨率越低,图像越小。
- 清晰度
在码率一定的情况下,分辨率与清晰度成反比关系:分辨率越高,图像越不清晰,分辨率越低,图像越清晰
在分辨率一定的情况下,码率与清晰度成正比关系:码率越高,图像越清晰;码率越低,图像越不清晰 - 带宽、帧率
例如在ADSL线路上传输图像,上行带宽只有512Kbps,但要传输4路CIF分辨率的图像。按照常规,CIF分辨率建议码率是512Kbps,那么照此计算就只能传一路,降低码率势必会影响图像质量。那么为了确保图像质量,就必须降低帧率,这样一来,即便降低码率也不会影响图像质量,但在图像的连贯性上会有影响。
1.2摄像机
摄像机的分类:
- 监控摄像机(网络摄像机和摸你摄像机)
- 不同行业需求的摄像机(超宽动态摄像机、红外摄像机、热成像摄像机等)
- 智能摄像机
- 工业摄像机
当前的摄像机硬件我们可以分为监控摄像机、专业行业应用的摄像机、智能摄像机和工业摄像机。而在监控摄像机里面,当前用的比较多的两个类型一个叫做网络摄像机,一个叫做模拟摄相机,他们主要是成像的原理不太一样。
网络摄像机一般比传统模拟摄相机的清晰度要高一些,模拟摄像机当前应该说是慢慢处于一个淘汰的状态,它可以理解为是上一代的监控摄像机,而网络摄像机是当前的一个主流的摄相机,大概在 13 年的时候,可能市场上 70% 到 80% 多都是模拟摄像机,而现在可能 60% 到 70% 都是的网络摄像机。
除此之外,不同的行业其时会有特定的相机,想超宽动态摄像机以及红外摄像机、热成像摄像机,都是在专用的特定的领域里面可能用到的,而且他获得的画面跟图像是完全不一样的。如果我们要做图像处理跟计算机视觉分析,什么样的相机对你更有利,我们要学会利用硬件的优势。
如果是做研究的话一般是可以控制我们用什么样的摄相机,但如果是在实际的应用场景,这个把控的可能性会稍微小一点,但是在这里你要知道,有些问题可能你换一种硬件,它就能够很好的被解决,这是一个思路。
还有些问题你可能用算法弄了很久也没能解决,甚至是你的效率非常差,成本非常高,但是稍稍换一换硬件,你会发现原来的问题都不存在了,都被很好的解决了,这个就是硬件对你的一个新的处境了。
包括现在还有智能摄像机、工业摄像机,工业摄像机一般的价格也会比较贵,因为他专用于各种工业领域,或者是做一些精密仪器,高精度高清晰度要求的摄像机。
1.3 CPU和GPU
接下来给大家讲一下 CPU 跟 GPU,如果说你要做计算机视觉跟图像处理,那么肯定跳不过 GPU 运算,GPU 运算这一块可能也是接下来需要学习或者自学的一个知识点。
因为可以看到,当前大部分关于计算机视觉的论文,很多实现起来都是用 GPU 去实现的,但是在应用领域,因为 GPU 的价格比较昂贵,所以 CPU 的应用场景相对来说还是占大部分。
而 CPU 跟 GPU 的差别主要在哪里呢? 它们的差别主要可以在两个方面去对比,第一个叫性能,第二个叫做吞吐量。
性能,换言之,性能会换成另外一个单词叫做 Latency(低延时性)。低延时性就是当你的性能越好,你处理分析的效率越高,相当于你的延时性就越低,这个是性能。另外一个叫做吞吐量,吞吐量的意思就是你同时能够处理的数据量。
而 CPU 跟 GPU 的差别在哪里呢?主要就在于这两个地方,CPU 它是一个高性能,就是超低延时性的,他能够快速的去做复杂运算,并且能达到一个很好的性能要求。而 GPU是以一个叫做运算单元为格式的,所以他的优点不在于低延时性,因为他确实不善于做复杂运算,他每一个处理器都非常的小,相对来说会很弱,但是它可以让它所有的弱处理器,同时去做处理,那相当于他就能够同时处理大量的数据,那这个就意味着它的吞吐量非常大,所以 CPU重视的是性能,GPU重视的是吞吐量。
所以大部分时候,GPU 他会跟另外一个词语联系在一起,叫做并行计算,意思就是它可以同时做大量的线程运算,为什么图像会特别适合用 GPU 运算呢?这是因为 GPU 它最开始的设计就是叫做图形处理单元,它的意思就是我可以把每一个像素,分割为一个线程去运算,每一个像素只做一些简单的运算,这个就是最开始图形处理器出现的原理。
它要做图形渲染的时候,要计算的是每一个像素的变换。所以每一个像素变换的计算量是很小很小的,可能就是一个公式的计算,计算量很少,它可以放在一个简单的计算单元里面去做计算,那这个就是 CPU 跟 GPU 的差别。
基于这样的差别,我们才会去设计什么时候用 CPU,什么时候用 GPU。如果你当前设计的算法,它的并行能力不是很强,从头到尾从上到下都是一个复杂的计算,没有太多可并性的地方,那么即使你用了 GPU,也不能帮助你很好提升计算性能。
所以,不要说别人都在用 GPU 那你就用 GPU,我们要了解的是为什么要用 GPU ,以及什么样的情况下用 GPU,它效果能够发挥出来最好。
1.4计算机视觉与其他学科的关系
计算机视觉目前跟其他学科的关系非常的多,包括机器人,以及刚才提到的医疗、物理、图像、卫星图片的处理,这些都会经常使用到计算机视觉,那这里呢,最常问到的问题无非就是有三个概念,一个叫做计算机视觉,一个叫做机器视觉,一个叫做图像处理,那这三个东西有什么区别呢?
这三个东西的区别还是挺因人而异的,每一个研究人员对它的理解都不一样。
首先,Image Processing更多的是图形图像的一些处理,图像像素级别的一些处理,包括 3D 的处理,更多的会理解为是一个图像的处理;而机器视觉呢,更多的是它还结合到了硬件层面的处理,就是软硬件结合的图形计算的能力,跟图形智能化的能力,我们一般会理解为他就是所谓的机器视觉。
而我们今天所说的计算机视觉,更多的是偏向于软件层面的计算机处理,而且不是说做图像的识别这么简单,更多的还包括了对图像的理解,甚至是对图像的一些变换处理,当前我们涉及到的一些图像的生成,也是可以归类到这个计算机视觉领域里面的。
所以说计算机视觉它本身的也是一个很基础的学科,可以跟各个学科做交叉,同时,它自己内部也会分的比较细,包括机器视觉、图像处理。
1.5 编程语言AND数学基础
这一部分的内容可以参见《非计算机专业,如何学习计算机视觉》
2.参考书籍和公开课
参考书
第一本叫《Computer Vision:Models, Learning and Inference》written by Simon J.D. prince,这个主要讲的更适合入门级别的,因为这本书里面配套了非常多的代码,Matlab 代码,C 的代码都有,配套了非常多的学习代码,以及参考资料、文献,都配得非常详细,所以它很适合入门级别的同学去看。
第二本《Computer Vision:Algorithms and Applications》written by Richard Szeliski,这是一本非常经典,非常权威的参考资料,这本书不是用来看的,是用来查的,类似于一本工具书,它是涵盖面最广的一本参考书籍,所以一般会可以当成工具书去看,去查阅。
第三本《OpenCV3编程入门》作者:毛星云,冷雪飞 ,如果想快速的上手去实现一些项目,可以看看这本书,它可以教你动手实现一些例子,并且学习到 OpenCV 最经典、最广泛的计算机视觉开源库。
公开课:
Stanford CS223B
比较适合基础,适合刚刚入门的同学,跟深度学习的结合相对来说会少一点,不会整门课讲深度学习,而是主要讲计算机视觉,方方面面都会讲到。
Stanford CS231N
这个应该不用介绍了,一般很多人都知道,这个是计算机视觉和深度学习结合的一门课,我们上 YouTube 就能够看到,这门课的授课老师就是李飞飞老师,如果说不知道的话可以查一下,做计算机视觉的话,此人算是业界和学术界的“执牛耳”了。
3.需要了解的深度学习知识
深度学习没有太多的要讲的,不是说内容不多,是非常多,这里只推荐一本书给大家,这本书是去年年底才出的,是最新的一本深度学习的书,它讲得非常全面,从基础的数学,到刚才说的概率学、统计学、机器学习以及微积分、线性几何的知识点,非常的全面。 
4.需要了解和学习的开源软件
OpenCV
它是一个很经典的计算机视觉库,实现了很多计算机视觉的常用算法。可以帮助大家快速上手。
Caffe
如果是做计算机视觉的话,比较建议 Caffe。Caffe 更擅长做的是卷积神经网络,卷积神经网络在计算机视觉里面用的是最多的。
所以无论你后面学什么样其它的开源软件, Caffe 是必不可免的,因为学完 Caffe 之后你会发现,如果你理解了 Caffe,会用 Caffe,甚至是有能力去改它的源代码,你就会发现你对深度学习有了一个质的飞跃的理解。
TensorFlow
TensorFlow 最近很火,但是它的入门门槛不低,你要学会使用它需要的时间远比其他所有的软件都要多,其次就是它当前还不是特别的成熟稳定,所以版本之间的更新迭代非常的多,兼容性并不好,运行效率还有非常大的提升空间。
5.如何阅读相关的文献
先熟悉所在方向的发展历程,然后精读历程中的里程碑式的文献。
例如:深度学习做目标检测,RCNN,Fast RCNN,Faster RCNN,SPPNET,SSD和YOLO这些模型肯定是要知道的。又例如,深度学习做目标跟踪,DLT,SO-DLT等。
计算机视觉的顶会:
ICCV:International Conference on Computer Vision,国际计算机视觉大会
CVPR:International Conference on Computer Vision and Pattern Recognition,国际计算机视觉与模式识别大会
ECCV:European Conference on Computer Vision,欧洲计算机视觉大会
除了顶会之外呢,还有顶刊。像 PAMI、IJCV,这些都是顶刊,它代表着这个领域里面最尖端最前沿以及当下的研究方向。