炼丹拾遗
权重衰减(weight decay)与学习率衰减(learning rate decay)
https://www.pianshen.com/article/16621212014/
关于weight_decay的深度分析
https://zhuanlan.zhihu.com/p/339448370
【PyTorch】优化器 torch.optim.Optimizer
https://zhuanlan.zhihu.com/p/339448370
语义分割训练与优化技巧
https://blog.csdn.net/xijuezhu8128/article/details/111304151
语义分割中的训练策略和参数设置
https://blog.csdn.net/qiusuoxiaozi/article/details/72851656
PyTorch 学习笔记(八):PyTorch的六个学习率调整方法
https://zhuanlan.zhihu.com/p/69411064
https://www.jianshu.com/p/26a7dbc15246
CNN中的数据增强简单总结
https://zhuanlan.zhihu.com/p/104992391
数据增广 Data Augmentation
https://zhuanlan.zhihu.com/p/89419960
GitHub:数据增广最全资料集锦
https://zhuanlan.zhihu.com/p/265021958
CNN 模型所需的计算力(flops)和参数(parameters)数量是怎么计算的?
https://www.zhihu.com/question/65305385/answer/641705098
深度学习调参有哪些技巧?————继续更新: 语义分割调参、
https://www.zhihu.com/question/25097993/answer/934100939
当数据量不够大的时候,有什么方法可以提高CNN训练效果?
https://www.zhihu.com/question/35577148/answer/63837608
CNN入门实战:我如何把准确率从86% 提高到99%(上)
https://zhuanlan.zhihu.com/p/43679939
【AI不惑境】学习率和batchsize如何影响模型的性能?
https://zhuanlan.zhihu.com/p/64864995
训练cnn时候epoch怎么取?
一个epoch 就是指你数据集里所有数据全过一遍…batch size是指你一次性拿多少个数据去训练…比如你一共有一万个数据点…batch size是200…那么你就要训练50次才是一个epoch…具体要多少个epoch看情况吧…太大缺点有两个…一个是过拟合(overfit)另一个是训练时间太长
如何理解深度学习分布式训练中的large batch size与learning rate的关系?
https://www.zhihu.com/question/64134994/answer/216895968
训练神经网络时如何确定batch size?https://zhuanlan.zhihu.com/p/27763696
听说GPU对2的幂次的batch可以发挥更佳的性能,因此设置成16、32、64、128
如何有效使用大batch训练?
https://zhuanlan.zhihu.com/p/88340684
使用大batch有哪些优势?(即小batch的劣势)
- 训练速度快, 提高并行度
- 针对检测任务, 大batch正负样本更均衡
- 可以有效更新BN层参数(网络使用BN的情况下)
- 精度更高(后续会进一步解释)
使用大batch有哪些劣势?
- 存在拟合问题, batch size越大, 拟合程度更低 -> 精度会低(一个可能原因是大batch训练, 不加任何trick, 会难以收敛, 只能调低learning rate, 但是降低learning rate后, 会导致精度变低)
- 存在优化问题
- 如何调整学习率?
- 多卡BN如何同步?
深度学习中的batch的大小对学习效果有何影响?
https://www.zhihu.com/question/32673260/answer/675161450
随着batch normalization的普及,收敛速度已经不像前bn时代一样需要非常玄学的调参,现在一般都还是采取大batch size,毕竟GPU友好嘛,高票答案说的batch size大了一个epoch update数量少了的这个缺点在bn面前似乎也没太多存在感了。不过bn的坏处就是不能用太小的batch size,要不然mean和variance就偏了。所以现在一般是显存能放多少就放多少。而且实际调起模型来,真的是数据分布和预处理更为重要,数据不行的话 玩再多花招也没用
1 大的batchsize减少训练时间,提高稳定性
2 过分大的batchsize如 8k (不可能用。。)导致模型泛化能力下降
- 如果增加了学习率,那么batch size最好也跟着增加,这样收敛更稳定。
-
尽量使用大的学习率,因为很多研究都表明更大的学习率有利于提高泛化能力。如果真的要衰减,可以尝试其他办法,比如增加batch size,学习率对模型的收敛影响真的很大,慎重调整
怎么选取训练神经网络时的Batch size?
个人经验 以128为中间向上向下 2倍尝试
https://www.zhihu.com/question/61607442/answer/440401209
常见的mini-batch从几十到几百不等,该怎么往哪个方向调试呢?近日,智能芯片创业公司Graphcore的两位工程师就在论文Revisiting Small Batch Training for Deep Neural Networks中给出了建议——2到32之间。
本文通过实验证明,在大规模训练中,对于给定的计算资源,使用小批量可以更好地保证模型的通用性和训练稳定性。在大多数情况下,batch size小于等于32时模型的最终性能较优,而当batch size=2或4时,模型性能可能会达到最优。
如果要进行batch归一化处理,或者使用的是大型数据集,这时我们也可以用较大的batch,比如32和64。但要注意一点,为了保证训练效率,这些数据最好是分布式处理的,比如最好的方法是在多个处理器上分别做BN和随机梯度优化,这样做的优势是对于单个处理器而言,这其实还是在做小批量优化。而且根据文章的实验,BN的最优batch size通常比SGD的还要小。
https://zhuanlan.zhihu.com/p/36404180
归一化的问题:也是一个无固定解的问题;就个人的经验而言大部分情况下归一化比不归一化要好,但是也存在一些特别的数据集,不归一化的情况下反而结果会更好;至于两种归一化方法感觉旗鼓相当了,从经验来说基于最大最小值的[0,1]归一化要稍微好一些。但是图像数据一定要归一化,不归一化结果很烂。所以最终是否归一化,选择哪种归一化方法需要题主用实验来验证你的数据适合哪种情况。
https://www.zhihu.com/question/47908908/answer/112468487
# 训练记录
20201223 下午 kitti19 训练不到一小时,可视化结果很差,没有学到东西,train loss在0.58 test loss在0.72,不知过拟合还是
20201224 晚上,调整临尺寸 224 -》resize 到640 192 VGG 和FCN 都加了一层,最后的最小输出f map大小为10×3,SGM改 ADAM,加了loss绘图, 数据为 全部12000 kitti
第二天下午都没有训完,突然发现 回归问题,loss应该是MSEloss 我写的是BCE。。。
20201226 第三次完成, 测了一下 kitti的效果大概ok吧因为是 训练集 ,然后在apollo测了一下,环境不太一样, 所以除了地面还比较整齐,其他有些乱
在kitti 的 epoch 2的效果?? 其实已经和 epoch200 接近了? 原谅我把 epoch20以后存的权重都删了重新训。。
kitti 19

apollo:
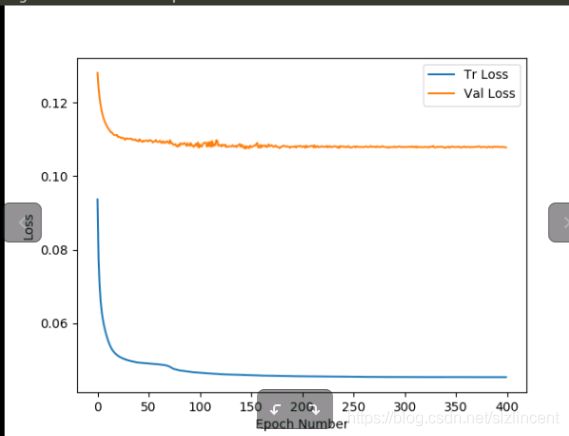
第四次 用SGD 训400 epoch 尝试看到 test loss的上升 验证 early stop
设置optim如下
criterion= nn.MSELoss() # regression
optimizer= optim.SGD(fcn.parameters(), lr= 0.001, momentum= 0.9)
# optimizer = optim.Adam(fcn.parameters(), lr=0.001, betas=(0.9, 0.999))
scheduler= optim.lr_scheduler.StepLR(optimizer, 40, gamma=0.5)1228训练结束 效果很迷 很浅 和第一次 resize224 效果有点像,是后期学习率太小了 没有学到东西的感觉
loss也可以看到 后期 下降太小, 也看不到test loss 上升的过程, 无法验证early stop的过程。
一文搞透sigmoidsoftmax交叉熵/l1/l2/smooth l1 loss https://zhuanlan.zhihu.com/p/148102828
请问 faster RCNN 和 SSD 中为什么用smooth L1 loss,和L2有什么区别?
https://www.zhihu.com/question/58200555/answer/621174180
https://zhuanlan.zhihu.com/p/48426076
pytorch 查看模型结构 网络参数
https://zhuanlan.zhihu.com/p/188323684
简单两步加速PyTorch里的Dataloader
读取jpg图片加速、 预读取
https://zhuanlan.zhihu.com/p/68191407
关于pytorch中BN层(具体实现)的一些小细节
BN层的输出Y与输入X之间的关系是:Y = (X - running_mean) / sqrt(running_var + eps) * gamma + beta,此不赘言。其中gamma、beta为可学习参数(在pytorch中分别改叫weight和bias)
https://zhuanlan.zhihu.com/p/102710590
pytorch多gpu并行训练 https://zhuanlan.zhihu.com/p/102710590
当代研究生应当掌握的并行训练方法(单机多卡)https://zhuanlan.zhihu.com/p/98535650
PyTorch Parallel Training(单机多卡并行、混合精度、同步BN训练指南文档)https://zhuanlan.zhihu.com/p/145427849
pytorch的多机多卡分布式训练,精度比单机低,会是什么原因造成的?https://www.zhihu.com/question/354028014/answer/882739283
关于transforms.Normalize()函数
https://blog.csdn.net/jzwong/article/details/104272600
https://blog.csdn.net/qq_38765642/article/details/109779370
2020.12.24
输入尺寸的问题:
如果存在全连接层,输入尺寸固定,因为fc定好了
全卷积网络没有这个问题,但是batch要求图片大小需要统一,分布多卡似乎可以不同batch的图大小不一样
解决尺度的问题:前面使用SPP、gap 代替 fc、自适应pooling
比如kitti 1240 370 可以直接进backbone,但是计算量会比较大,可以resize或者 crop,但是要保比, 比如 620:185,并且计算量和 backbone的一般输入的计算量一致
学习PSM net
主要模块: SPP 融合特征, 代价匹聚合:basic 3D CNN 输出一层回归 或者 堆叠沙漏 输出三层回归视差。
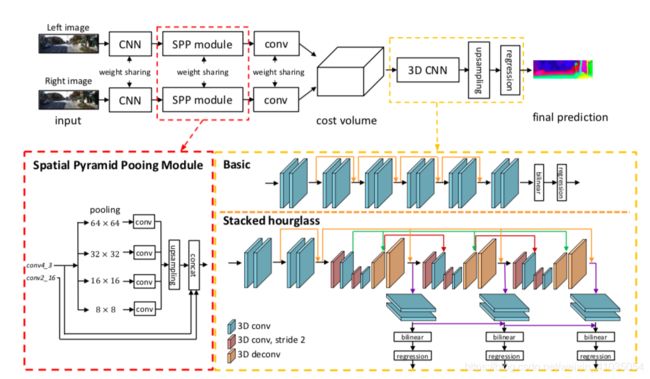
输入尺寸的处理:
图片大小为375 * 1242,训练时将图片随机裁剪至256 * 512的大小,再进行均值为[0.485, 0.456, 0.406],标准差为[0.229, 0.224, 0.225]的标准化。对于读入的视差ground truth,将视差缩小256倍,因为原来视差范围很大。
验证或预测时 若全图比较,考虑卷积神经网络对图片矩阵的一些缩放问题,先将原图裁剪至368*1232,输入网络得到视差图,再填充至原图大小。
loss,loss.cpu().data 及 loss.cpu().detach().numpy()等辨析
https://blog.csdn.net/qq_39938666/article/details/90794240
Pytorch:将图像tensor数据用Opencv显示
https://blog.csdn.net/qq_40859802/article/details/103903807
Pytorch中四维Tensor转图片并保存(维度顺序调整)
https://blog.csdn.net/weixin_43812609/article/details/109479705
PyTorch模型训练特征图可视化(TensorboardX)
https://zhuanlan.zhihu.com/p/60753993
Pytorch训练可视化(TensorboardX)
https://zhuanlan.zhihu.com/p/54947519
PyTorch深度学习训练可视化工具visdom
https://zhuanlan.zhihu.com/p/100182978?utm_source=wechat_session
pytorch用FCN语义分割手提包数据集(训练+预测单张输入图片代码)
https://blog.csdn.net/u014453898/article/details/92080859
Pytorch源码学习之二:torchvision.models.vgg
https://blog.csdn.net/mathlxj/article/details/104951640
二、一些值得学习的用法笔记
#将start_dim至end_dim展成一维向量
torch.flatten(tenor, start_dim, end_dim)
x = torch.flatten(x, start_dim=1)
#效果同下
x = x.view(x.size(0), -1)
#使用何大佬在2015年提出的方法
torch.nn.init.kaiming_normal_(tensor, a=0,
model='fan_in', nonlinearity='leaky_relu')
nn.init.kaiming_normal_(m.weight, model='fan_out',
nonlinearity='relu')
#使用均值为mean,标准差为std的正态分布填充输入tensor
torch.nn.init.normal_(tensor, mean=0., std=1.)
#使用浮点数val填充tensor
nn.init.constant_(tensor, val)
#搭建网络的一种范式
layer = []
layer += [nn.Conv2d(...), nn.ReLU(inplace=True)]
layer += [nn.BatchNorm2d(...)]
nn.Sequential(*layers)
#从网络上加载参数
torch.hub.load_state_dict_from_url(url, model_dir=None, map_location=None, progress=True)
#url-下载的目标网址
#model_dir - 保存参数的目录
#map_location - a function or a dict specifying how to remap storeage locations.
state_dict = load_state_dict_from_url(model_urls[arch],
progress=progress)
#progress - 是否展示下载的进度条
#载入参数到模型
#torch.nn.modules.module.Module
#def load_state_dict(self, state_dict, strict=True)
model.load_state_dict(state_dict)
#*args 和 **kwargs都代表1个或多个参数的意思.*args传入tuple类型的无名参数,而**kwargs传入的参数是dict类型
def myprint(*args):
print(*args)
myprint(10, 2) #10 2
def mykwprint(**kwargs):
key = kwargs.keys()
value = kwargs.values()
print(key) #dict_keys(['epoch', 'LR'])
print(value) #dict_values([10, 2])
mykwprint(epoch=10, LR=2)