【31】yolov5的使用 | 训练Pascal voc格式的数据集
如有错误,恳请指出。
在上一篇文章中:【30】yolov5的数据集准备 | 处理Pascal voc格式的数据集,已经介绍了如何对自己的数据集进行处理以满足yolov5的格式。现在处理完了数据集,就开始对数据集进行训练。
文章目录
- 1. 数据的准备
- 2. yaml文件配置
-
- 2.1 数据集的yaml文件配置
- 2.2 模型的yaml文件配置
- 3. train.py文件的修改与执行
-
- 3.1 配置train.py文件的部分参数
- 3.2 执行train.py及可能出现的错误
- 4. 查看tensorboard的可视化效果
- 5. yolov5的测试
1. 数据的准备
数据集的处理,详细见:【30】yolov5的数据集准备 | 处理Pascal voc格式的数据集,这里不再细诉。对于我们处理好的数据集,如下所示:

这里只需要将Dataset丢到服务器里就可以了,其他都是不需要的。如下所示:
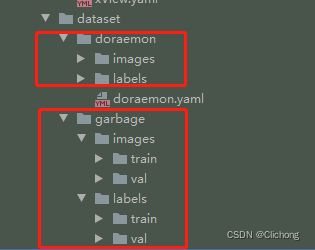
这个固定格式是有VOC.yaml文件所决定的:
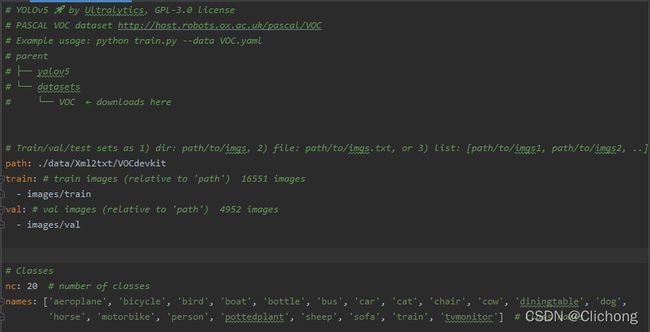
简要来说,对于yolov5所需的的格式为:
DataSet
|---------images
|-------train
|-------val (可以没有)
|-------test(可以没有)
|---------labels
|-------train
|-------val (可以没有)
|-------test(可以没有)
也就是在一个数据集下,需要有images与labels两个子文件夹,images内直接用来存放图片,labels用来存放对应图片的标签文件;没有val与test表示训练的过程中只有train的文件,然后再更改数据的配置yaml文件。
2. yaml文件配置
2.1 数据集的yaml文件配置
这里我用了一个垃圾分类检测的数据集(是学校举行的一个比赛所使用的数据集)。在刚刚上传到服务器的数据集下我新建了一个garbage.yaml文件,整个数据集文件存放在yolov5工程目录的 ./dataset 路径下。garbage.yaml文件用来配置yolov5训练过程中数据与标签的读入。
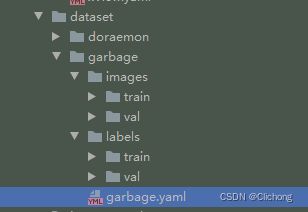
- garbage.yaml内容如下:
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: ./dataset/garbage
train: # train images (relative to 'path') 16551 images
- images/train
val: # val images (relative to 'path') 4952 images
- images/val
# Classes
nc: 44 # number of classes
names: ['锅', '陶瓷器皿', '鞋', '食用油桶', '饮料瓶', '鱼骨', '一次性快餐盒', '书籍纸张', '充电宝', '剩饭剩菜',
'包', '垃圾桶', '塑料器皿', '塑料玩具', '塑料衣架', '大骨头', '干电池', '快递纸袋', '玻璃器皿', '砧板',
'筷子', '纸盒纸箱', '花盆', '茶叶渣', '菜帮菜叶', '蛋壳', '调料瓶', '软膏', '过期药物', '酒瓶',
'金属厨具', '金属器皿', '金属食品罐', '插头电线', '旧衣服', '易拉罐', '枕头', '果皮果肉', '毛绒玩具', '污损塑料',
'污损用纸', '洗护用品', '烟蒂', '牙签']
ps:这里具体的路径,类别信息与类别数量根据自己的数据集路径与数据集类别进行设置。
2.2 模型的yaml文件配置
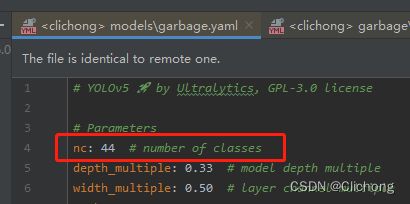
因为这里是使用的权重文件是yolov5s,所以是对yolov5s.yaml进行更改,这里只要是更改检测类别个数。这里我在yolov5的工程项目的 ./model 路径下,新建了garbage.yaml,这个文件用来配置yolov5的模型数据。用于是复制yolov5s.yaml文件进行更改,所以只需要改nc就可以了。
# Parameters
nc: 44 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
如下所示:
3. train.py文件的修改与执行
3.1 配置train.py文件的部分参数
在argparse中设定自己的数据集路径与配置文件路径,还可以调整去的参数比如device,num_worker等。主要更改的部分:

- 参考:
parser.add_argument('--weights', type=str, default='./weights/yolov5s.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default=r'./models/garbage.yaml', help='model.yaml path')
parser.add_argument('--data', type=str, default=r'./dataset/garbage/garbage.yaml', help='dataset.yaml path')
parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch.yaml', help='hyperparameters path')
parser.add_argument('--epochs', type=int, default=30)
parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs')
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)')
说明:
- weights:预训练的权重
- cfg:模型配置文件路径
- data:数据集配置文件路径
- hyp:超参数配置文件路径
- device:选择使用的服务器,可以全部使用
这里更改的是默认权重,我一般用命令行执行,所以这里不改也可以,参考的命令行训练:
python train.py --data ./dataset/garbage/garbage.yaml --cfg ./model/garbage.yaml --epoch 100 --device 1
3.2 执行train.py及可能出现的错误
当yaml配置文件与数据径全部设置好时,就可以跑数据了,如果出现Out of Memery的情况就是显存不够,可以调小batch_size与image_size.
-
问题1:urllib.error.URLError:
第一次跑就出现了这个错误,好像需要下载一个字体的格式,但是代码下次失败,于是我就直接根据链接在本地下下载之后再丢到服务器的对应目录下就可以了。 -
问题2:Error in `python’: double free or corruption (!prev)
但是此外我还出现了一个问题,感觉是设置得过多的num worker,代码会出错。所以,这里我的解决方法是:将dataloader中的num_workers一行直接注释掉,如下所示:

但是,在IDE(pycharm中跑时),进行到Plotting labels时就自动中断了,但是用命令行去跑时,又可以正常执行- Pycharm端:

- MobaXTerm端:

之后就没管了,能在MobaXTerm端能跑就行了,之后需要断点调试再补充。
- Pycharm端:
-
问题3:Error in `/home/fs/anaconda3/envs/yolo/bin/python3.9’: free(): invalid pointer: 0x0000561ac03494a0或者是段错误

对于这个错误,首先要检测你的数据集格式是否满足要求,在yolov5的数据集格式中,是images与labels之间的图片与标注是一一对应的。不能突然的多了一张图片缺少一个标注文件,也不能多了一个标注文件少了一张图片,也就是没有一一匹配,在这里我在labels里面多了一个class.txt文件,这就是一个错误,将其删掉即可。
4. 查看tensorboard的可视化效果
按照官方的指引,在yolov5工程目录下,执行以下代码即可展示数据巡礼过程中的可视化结果:
tensorboard --logdir=./runs
但是,执行了这一步之后,会在服务器上弹出一个链接,本地上打开这个链接是没有用的。我想在本地浏览器中直接访问远程服务器上tensorboard的监控界面,也就是要利用SSH查看远程服务器上的tensorboard可视化界面。参考资料[5]的方法3:方法需要手动输入命令来完成SSH的本地端口转发。
-
步骤1:在服务器端输入tensorboard --logdir=./runs,获取服务器端的监听链接
-
步骤2:输入指令以下指令将PC端口映射到服务器端口
ssh -L 16006:127.0.0.1:6006 fs@192.168.196.209 -p 22
结果如下所示,即完成映射:
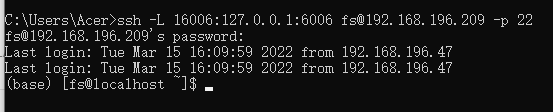
该命令作用是登录远程服务器账户,并将服务器端的6006端口和PC机端的16006端口映射起来。这里利用的是SSH本地端口转发功能-L。那么我们在PC机访问本地16006端口就相当于访问服务器端的6006端口。执行完该命令也就完成了。
- 步骤3:启动tensorboard
在本地PC机浏览器中访问http://localhost:16006/即可,随机可以看见正在训练的参数指标。

训练过程:

5. yolov5的测试
对于用yolov5训练好的模型,用起来简直不要太方便:
detect.py runs inference on a variety of sources, downloading models
automatically from the latest YOLOv5 release and saving results to
runs/detect.
对于测试的都会存放在runs/detect文件目录下,使用例程只需要指定输入的数据,再指定训练好的权重即可
python detect.py --source 0 # webcam
img.jpg # image
vid.mp4 # video
path/ # directory
path/*.jpg # glob
'https://youtu.be/Zgi9g1ksQHc' # YouTube
'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream
具体的配置文件可以通过输入:python detect.py -h(-help) 来查看,这里其实可以解析youtube视频的,但是都知道有墙,所以无法解析,但是已经足够强大了,比较可以直接对目录下的全部文件进行测试。
ps:对于yolo跑出来的结构都会放在 ./run/detect 文件夹中,然后以exp依次命名,如下所示:

- 1)测试单张图片
python detect.py --source ./data/image/bus.jpg
- 2)测试图片目录
python detect.py --source ./data/image/
- 3)测试单个视频
python detect.py --source ./data/videos/test_movie
- 4)测试视频目录
python detect.py --source ./data/videos/
- 5)测试摄像头
python detect.py --source 0 # 其中0代表是本地摄像头,还有其他的摄像头
摄像头捕捉的视频同样会保存在 ./run/detect 文件夹中
- 6)测试Youtube链接
python detect.py --source “https://www.youtube.com/watch?v=PCp2iXA1uLE”
测试Youtube链接需要再安装连个库文件:
pip install pafy
pip install youtube_dl
如下所示:
不过,我以为挂了VP就能跑泡,还是不行,我太天真了。(在cmd中ping youtube.com也是ping不通的)
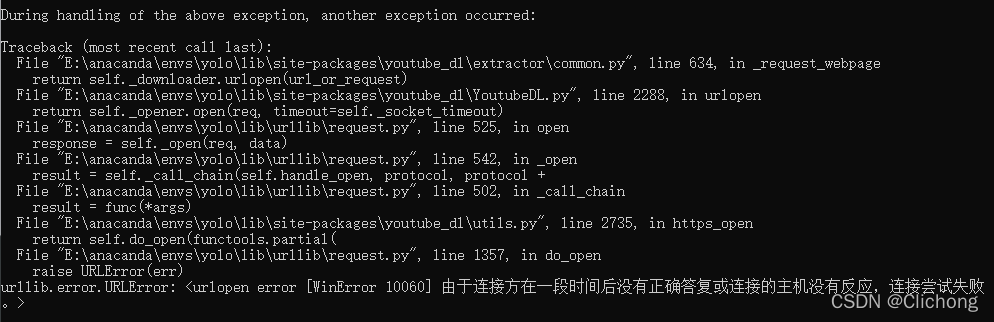
ps:经过测试,出了油管的视频,直接挂优酷,爱奇艺,b站的视频也是不能解析出来的,或者我的使用方法不对吧,有了解的小伙伴可以告诉我。
参考资料:
- 【30】yolov5的数据集准备 | 处理Pascal voc格式的数据集
- 深度学习_目标检测_YOLOv5训练Pascal VOC格式的数据集教程
- YOLOV5 训练PASCAL VOC数据集
- 教程:超详细从零开始yolov5模型训练
- 【Pytorch】利用SSH查看远程服务器上的tensorboard可视化界面
- Visdom 之远程查看服务器可视化结果
- 【YOLO】目标检测第三步——用Pascal voc 2012 数据集训练YOLO网络