日志易有自己的搜索处理语言 SPL(Search Processing Language), SPL 语言有些类似于SQL ,但却比 SQL 更加强大、灵活,SQL 用于结构化数据查询,SPL 专门用于日志这种非结构化数据的查询和分析。用户可通过在日志易搜索框中编写SPL 脚本程序进行各种查询、统计、分析,包括机器学习和智能运维。
尽管需要对 SPL 有一定了解才能更好地在日志易中搜索统计,但实际上,我们并不需要了解所有的 SPL 函数。掌握了一些使用 SPL 的方法,再配合日志易检索参考手册,就能够完成 90% 以上的统计了。
日志易有自己的搜索处理语言 SPL(Search Processing Language), SPL 语言有些类似于SQL ,但却比 SQL 更加强大、灵活,SQL 用于结构化数据查询,SPL 专门用于日志这种非结构化数据的查询和分析。用户可通过在日志易搜索框中编写SPL 脚本程序进行各种查询、统计、分析,包括机器学习和智能运维。
尽管需要对 SPL 有一定了解才能更好地在日志易中搜索统计,但实际上,我们并不需要了解所有的 SPL 函数。掌握了一些使用 SPL 的方法,再配合日志易检索参考手册,就能够完成 90% 以上的统计了。
不信?来看完这篇文章再说。
1确定分析场景
通常来说,数据搜索的目的可分为两类:故障排查和统计可视化。基于这两种目的, SPL 的用法也有着明显的不同。
故障排查
故障排查主要通过关键字、唯一标识符等低频词元,利用索引中倒排表的高性能查找特性,快速定位和读取原始日志内容。常见场景有:查找错误代码、关联跟踪特定订单或客户访问在多模块之间的流动情况、分析异常堆栈等等。
故障排查需要进行原文检索,由于原文日志量大,通常我们需要使用更高效的方式来减少系统的工作量。这体现在以下几个原则上:
1. 设置刚刚好的时间范围:从时间范围上排除不必要的数据,如果你知道一个故障的发生时间是下午 3 点左右,可以指定下午 2 点 45 到 3 点 15 时间段。这可以通过 starttime、 endtime 实现,或在搜索框的时间选择器选定;
2. 只获取必要的数据:从日志类型上排除不必要的数据。发生故障的系统是 Nginx 系统,可以指定日志类型为 nginx 。这一般通过 appname、tag、source、logtype 等字段进行过滤。Source 指日志来源,日志来源可能是日志文件路径,logtype 表示该日志被何种解析规则所解析,appname 和 tag 是由用户自己定义的标识;
3. 尽量不要跨主机传输数据:在使用 lookup 之类的函数时,应尽量不要跨主机加载外部文件中的字段,这会加重 SPL 的工作负载,消耗更多的服务器资源。如需使用,也应用在日志范围已经足够精确时;
4. 尽量采用可并行的指令:注意 eval、where、lookup、join、limit 等指令在 SPL 语句中的位置。使用字段限定查询条件,能够大大较少检索范围,应放在 SPL 语句最前面使用;where 用在限定范围某字段时,需基于已有日志进行,应尽量放在 SPL 前面,以缩小后续 SPL 语句的检索范围;join 用在关联分析时,需要先执行子查询,并将其结果用作限定查询的条件,执行此类语句会比较慢,应根据需求酌情使用该函数。使用 SPL 进行范围限定时,范围指定的越精确,SPL 统计语句就会执行的越慢,以上指令应结合实际场景使用。eval 会根据已有字段重新生成另一个字段,属于流式处理语句,一般在对日志进行一定程度的筛选过滤后使用。
故障排查和统计分析的原则是相互融合使用,而非对立割裂的。统计变化的结果可以以子查询的形式帮助过滤原文检索的范围;原文检索同样也可以帮助过滤缩小统计变换的运算数据集范围。
统计分析
统计分析需要对检索数据集进行一系列指标运算,得到二维表格式的变换结果。常见场景有:错误事件数的时间趋势、特定用户登录行为的排行和分布、访问响应时间的百分比统计、KPI 指标的平滑预测等等。
根据场景的不同,统计分析的方向也会有所差异。
1、 时间趋势分析:当我们要对某天的访问趋势进行分析,或想得知哪个时间段发生错误事件的比重最高时,我们常常会用到 bucket 来对时间粒度(按分钟为单位,还是按小时为单位)进行切分。对时间范围进行选择,如对本周数据进行分析,方法与上面限定时间范围的方式相同,即通过 starttime、endtime 或时间选择器选定;
2、 排行及数值分布:如需对网站的前十访问量最高的 IP 进行统计,获取这些 IP 及对应的访问次数时,stats 等基础统计分析函数就显得十分便利了;
3、 百分比统计及数值计算:当我们需要对交易成功率或失败率做一个统计,或有某类型的数值计算需求,我们需要用到能够进行数值计算的函数,如 eval、autoregress 等;
4、 智能运维场景预测:根据已有的数据,对异常数值进行检测,或预测某数值可能会出现的异常时段时,movingavg、rollingstd、pct、esma、ARIMA、Kmeans等函数可进行高级统计分析。
2根据场景,选择相应函数
时间趋势分析
当我们想要将昨天和今天的 Nginx 访问趋势做一个对比分析时看,我们需要用 append 在主查询(今天访问趋势)后附加上子查询(昨天访问趋势)。在该查询语句中,除了需要指定今天和昨天的时间范围,还需要用 bucket 将时间以 1 小时为粒度进行切分。
实现该查询所用到的 SPL 语句如下:
starttime="-1d/d" endtime="now/d" appname:nginx
| bucket timestamp span=1h as ts
| eval time=formatdate(ts,"HH")
| stats count() as count_ by time
| eval group="yesterday"
| append
[[
starttime="now/d" endtime="now" appname:nginx
| bucket timestamp span=1h as ts
| eval time=formatdate(ts,"HH")
| stats count() as count_ by time
| eval group="today"
]]
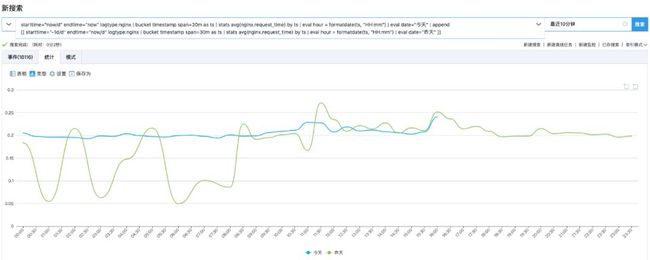
使用 append 把同一个指标不同时段的走势叠加在一起查看,也叫同环比。
排行及数值分布
可以从要展现的图形的维度选择要使用的统计分析函数。
对某一字段的趋势做统计分析,一般使用 stats 函数。与 stats 有关的函数有很多,主要是基础数值统计类的,如:
1、次数统计 count();
2、平均数 avg()、最大值 max()、最小值 min()、求和 sum();
3、求数值对应的百分位 pct_ranks()。可以用于统计请求响应时间高于某一数值的情况的占比。
此外,排行及数值分布场景中,根据分析场景的不同,还有其他的函数可以采用:
stats 函数适合趋势图场景;
当要做的图是饼图时,使用 top 往往更为便捷;
将不同系统的监控数据层叠在一张图里分析,或是做同环比时,参考上面案例,使用 append 即可;
做多种维度的统计结果的面积图,sparkline 更为合适。
百分比统计
当需要对某字段进行数值计算时,需要基于现有字段进行数值类型转换。进行数值类型转换会生成一个临时字段,基于临时字段可以实现复杂的统计分析和展示。
eval 指令可以使用函数及表达式,在已有字段的基础上,创建新的字段,并将函数和表达式的结果赋值给该新字段。eval 所支持的函数和表达式通常都比较简单,但是可以通过嵌套组合的方式,实现复杂需求。
与 eval 相关的搜索命令函数主要包括以下几类:
1、 字段类型转换:如绝对值计算、对数计算、字符串、整型、双精度浮点数类型转换、格式化字符串、字符串大小写转化,向上向下取整等。
使用 urldecode() 还可对字段进行 URL 解码;
2、 字段本身相关的运算:typeof() 获取字段类型、len() 获得字符串的长度;
3、 时间格式转换:UTC 及 UNIX 时间类型转换,now()、relative_time() 返回基于时间戳字段进行某时间运算(如前一天、后一天)后的计算结果;
4、 判断及选择:可使用 if 对布尔型数值进行大小判断,max()、min() 对两个数进行大小判断,使用 empty() 判断字段是否为空,使用 isnum()、isstr() 判断字段是否为数值型或字符串。另外,使用 cidrmatch 还可对 IP 地址进行 CIDR(无类别域间路由)匹配判断;
5、 字符串操作:使用 substring()、trim()、split() 可对字符串进行拆分等处理操作;
6、 多值类型参数操作:使用 mv 开头的几个函数,可以对多值字段进行一系列操作。
此外,进行百分比计算还可以使用以下函数:
top 自带的比率计算功能;
stats pct() 及 stats pct_ranks() 函数计算数值所对应的百分位;
使用 autoregress 进行跨行计算。
以上是结构化日志的计算场景,当面临的日志的解析工作做得不够好时,或现有字段不能满足使用时,我们往往还要借助别的方式生成新的字段以供计算时使用。此时生成临时字段的方法有:
parse 正则提取;
jpath 对 json 格式的日志进行字段提取;
lookup 引入外部定义好的字段信息;
使用 mvexpand 、mvcombine 、split 对多值字段进行处理。
智能运维场景下的数据预测
大数据场景不同,所使用的 SPL 提取函数也会有所不同。
当现有的数据量已经足够丰富时,需基于现有数据趋势进行异常值发现:使用 movingavg 和 rollingstd;
对于较为稳健的长尾数据场景进行异常数值定位:使用 pct 函数;
运维KPI及容量规划相关的数据预测:使用 esma 函数;
对自身数据的了解比较深,愿意进行手动调参:ARIMA 算法;
同一批应用的同类监控指标的异常检测:Kmeans 算法。
3调试及拓展
当我们知道使用什么函数,并能参照日志易检索参考手册按函数所对应的语法规则书写 SPL 语句后,我们就可以对该搜索语句进行运行调试了。
对 SPL 语句的调试可以依据下面几个原则依次进行:
1、 由于 SPL 使用管道进行连接,当运行 SPL 语句出错或已有的展示不符合想要的效果时,我们可以根据管道对内容逐段排查。即保留最前面的搜索语句,逐渐按管道添加新的搜索内容,直到发现出错或未达到理想效果的语句出现为止;
2、 根据报错内容及日志易检索参考手册对错误语句进行调整;
3、 有些非流式函数需要数据加载完之后才能显示出处理结果,如 sort、dedup、transpose 等,这些函数应尽量放在 SPL 语句的后面,因为这些数据可能对事件处理条数有一定限制。可以在咨询日志易售后支持人员后对这些函数相关的配置项进行调整,以避免数据调整过大影响资源分配,从而造成系统宕机;
4、 以上方式暂不可用时,登录 https://rizhiyi.kf5.com/user/login 提交工单,等待日志易售后支持人员处理(工作日分分钟响应哦)。
以上的内容虽然涵盖 SPL 的基础使用场景及常用函数语句,但在有精力的情况下,仍建议先掌握 stats、eval 等简单命令,然后参照日志易搜索实例手册明确一下具体场景的分析方向,了解不同分析需求下应选择的函数类型。
在搜索实例手册的帮助下,可快速掌握检索参考手册中各个函数的主要用途,以便在进行相应的场景应用时选择使用。
在进行 SPL 语句的应用时,有些函数,如 format、jpath、正则等的使用遵循了业界通用方法,可以配合搜索引擎搜索使用。