数据库
MySQL初步
MySQL基础认知
(Oracle真的是走哪祸害到哪23333)
Java多用MySQL和Oracle
SQLServer也收费,但是还行,比Oracle便宜,一个差不多3w多
SQLite被嵌入到了安卓系统中,主要用于安卓开发,是完全免费的
关于MySQL收费的问题,这篇文章说的很透:
你使用开源软件并不受GPL约束,只有在你基于开源软件,修改开源软件的源码的时候才受 GPL约束。MySQL作为一个开源数据库,几乎所有的用户都只是通过自己的程序去操作这个数据库,不涉及到改动源码的问题,根本不用去考虑是否要遵循 GPL的问题。只有在你修改MySQL源码的情况下,才需要考虑GPL。
如果你只是使用MySQL而不是改写MySQL,那么在这些情况下你应该考虑购买Oracle的商业版本,一是Oracle的商用版本提供的附加组件(监控器、备份工具等)对你有价值,二是Oracle的年度技术支持是你需要的,三是各种潜规则。而不应该是你想合法的使用MySQL才去购买其商业版本。另外,如果你是基于MySQL的源码开发你自己的产品,那么你需要购买的是商业授权,而不是subscription这些商业版本。
除了以上情况,使用社区版就好
关闭服务需要使用管理员权限
服务器无法连接时,要检查服务是否正常开始了
登录MySQL:
mysql -uroot -proot//u代表user,后面的root是用户名,p代表password,后面的root是密码
退出:exit/quit
登录其他电脑的MySQL
mysql -h127.0.0.1 -uroot -proot//这里的127.0.0.1应该替换为对应的服务器ip地址
也可以这样:
mysql --hosst=ip --user=root --password=root
MySQL目录结构
- MySQL安装目录:
bin:二进制可执行文件
include:C语言的头信息
lib:运行所需要的库文件
share:错误记录
- MySQL数据目录
这个目录在C盘隐藏的文件夹ProgramData里面


my.ini是MySQL的配置文件
数据存放的位置:
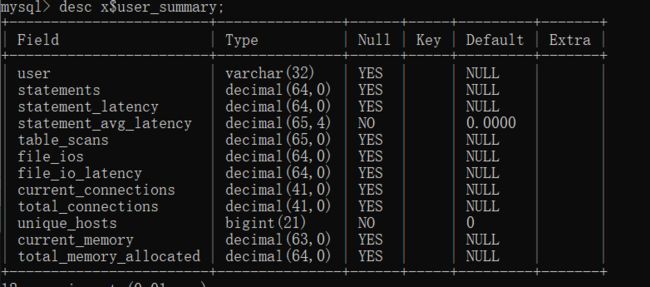
MySQL shell:mysql-shell是一个高级的mysql命令行工具、它直接两种模式(交互式&批处理式)三种语言(javascript\python\sql),格式为JSON。MySQL是在官方版本5.7.12推出,工具的初衷本身都是为了解决一类问题,想必官方从很多方面了解到工具的使用情况,支持的开发语言太多,众口难调,所以这么个命令行工具就出来了
平常对数据库的操作使用Command Line Client其实就好了
SQL语法
注释一定要带空格,命令都要以分号结尾
- SQL的分类
![]()
DDL:对数据库和表进行操作

information_schema:描述数据库的信息,存放的是视图而不是表,不存在真正对应的物理文件
mysql:核心数据库,存放表文件
performance_schema:对性能提升做操作
上面的三个数据库都要求不要贸然修改,否则可能会影响数据库稳定性

(查询数据库的创建语句,可以查看数据库的字符集)
不能创建重名数据库
先判断,再创建
选择使用特定字符集的数据库
总结,关于数据库的创建:
如果数据库不存在,删除会报错,可以先判断是否存在再删除
注意应该写utf8而不是utf-8
DML:对表进行增删改
- 查询表

- 创建表
数据类型:

- 删除表

- 修改表
这里要认识一个单词:alter(修改)

修改列明部分,应该是“新列名”而不是“新列别”
DML:对表中数据进行操作

引号单双都可以
TRYNCATE是直接全部删除,而delete是一条一条删,TRUNCATE效率更高
DQL:查询表中记录


- 基础查询

null参与的运算结果都是null(null就是unkown,计算结果当然也是unkown了)
起别名:
- 条件查询

注意这里的等号是一个的,不要写成==
<>和!=一样,是不等于的意思
&& 和 AND等效
NULL不能用等号去判断,只能用is
NOT放在IS后面
查询优化:
- 用between --- and--做范围查询
- 用数组和IN做多值情况

- like:模糊搜索
- 排序查询
- 聚合函数
- 分组查询

- 分页查询
注意,这个操作对于不同的软件不一样,这里只是MySQL中的方法
DCL:管理用户,授权
DBA:数据库管理员,对数据库专门负责
管理用户

mysql这个数据库是不显示在workbeach上的
题外话:在SQL指令中,如果只想执行script中的某一条或者某几条指令,应该用鼠标将其选起来,这样其他指令就不会执行了
注意,%通配符在主机名这一栏也是可以使用的,可以用来表示所有主机。
修改密码:
注意数据库中的密码是加密的,在查看时候也看不到原密码,修改密码时需要使用PASSWORD()函数来对要设置的密码进行加密
root用户的密码忘记了也有方案!
授权
- 查询权限
- 授予权限
- 撤销权限

约束
- 概念
- 非空约束
- 唯一约束
唯一约束并不要求NULL唯一
- 主键约束
主键:非空且唯一,唯一标识

基于主键约束的自动增长
MySQL 每张表只能有1个自动增长字段,这个自动增长字段即可作为主键,也可以用作非主键使用,但是请注意将自动增长字段当做非主键使用时必须为其添加唯一索引,否则系统将会报错。例如:
– 将自动增长字段设置为主键
create table t1 (id int auto_increment Primary key,sid int);
– 将自动增长字段设置为非主键,注意必须显式添加Unique键
create table t2 (sid int primary key,id int auto_increment Unique);
– 将自动增长字段设置为非主键如果未添加唯一索引将会报错,如下面语句
create table t3 (sid int primary key,id int auto_increment);
这里放在主键里面讲,只是因为大多数情况下自动增长都是用在主键上面的
![]()
自动增长只和上一条有关系,如果人工插入改变了序号,则下一条会接着上一条进行
设置了自动增长的列一般输入NULL就可以了,输入具体数字会改变原有排序
- 外键约束
表之间的关联,可以用来消除冗余数据。
一般外键都关联主表的主键
被关联的表一定要先于主动进行管理的表完成创建
被关联的表在引用解除之前不能被删除,要删除或者修改就必须先解除引用,解除引用不一定是指要删除外键,将调用该对象的那个键指向其他或者是NULL就好了
外键约束会自动要求必须存在,但可以为NULL

注意,外键添加在表创建的末尾,并且会再起一个外键名(这里涉及到了三个名字),之后的删除也是删除这种约束本身,而不是删除被加在其上的列
外键的级联:可以更方便地修改被调用的键值,更改会直接体现在被调用表上
级联包括更新和删除两个方面
级联删除有点危险,而且效率不高
所以,实际开发中,级联的使用是很谨慎的

数据库设计
概述
表是现实的抽象
数据库设计涉及到多表关系和范式(数据库设计准则)两个方面
多表关系
一对多:在多的一方建立外键,指向一的一方的主键
多对多:建立中间表,中间表至少有两个字段,分别指向两张表的主键(联合主键)
一对一:一对一关系的实现,可以在任意一方添加唯一外键指向另一方的主键
? 但是!一般情况下,如果遇到一对一的关系,一般情况下都会直接合成一张表而不是两张表
案例
如何在workbeach中生成EER图

范式

越高范式冗余越小
一般来说,遵守了前三种范式,数据库设计就没有太大问题了
第N范式都是以遵循前面的范式为基础的,所以,范式分析都是从前至后的
第一范式
每一列都是不可分割的原子数据项

这种是不符合第一范式的
![]()
修改为没有复合列的情况就好了
上面的表格存在的问题:
第二范式
例如上面的例子,(学号,课程名称)称为组,这两个属性也被称为主属性,分数这个非主属性是完全依赖于组的,而姓名、系名和系主任这三个非主属性只依赖于学号,这就不符合第二范式了。
如何修改?拆分表

A表中,主属性是学号和课程名称;B表中,主属性是学号
依然没有解决的问题:

第三范式

例如上面的B表中,姓名被系名依赖,而系名被系主任依赖,这就是传递依赖
解决方法?再分表
刚刚所有的问题就全部解决了
数据库的备份与还原
一般地,每一天我们都需要对数据进行备份
多表查询
多表查询出来的是笛卡尔积结果(M*N)

内连接
一般会对不同表起别名来便于写指令
SQL一般写成多行以便于阅读:

最规范的写法
另一种写法:
外连接
子查询
如何写子查询?可以先分开写多条(如上),然后合为一条
子查询的不同结果


查询结果为多行多列的情况,实际上就是将第一次查询出来的结果作为一张暂存的表再和其他表进行组合等操作
事务
控制台cmd默认操作是gbj,数据是utf8,中文字符可能会有显示问题
事务不提交之前是不会对数据库数据出现修改的,如果关闭窗口会自动回复事务前的情况
MySQL中事务默认自动提交,选择START TRANSACTION之后切换到手动提交模式,COMMIT命令之前是不会提交的。当然,我们也可以查看和修改事务的默认提交方法(1:自动提交,0:手动提交)注意,Oracle是手动提交的
对于MySQL,使用手动提交事务正确的操作方式为:
- 打开手动提交START TRANSACTION
- 修改数据
- 在当前窗口查看数据修改结果是否正确
- 如果正确,则输入COMMIT提交;如果不正确,则输入ROLLBACK回滚(直接关窗口理论上也行)
事务的四大特征
多个事务之间,我们想要努力做到隔离,虽然常常不能完全隔离
事务的一致性是建立在事务往往的应用背景下的
事务的隔离级别
注意,幻读这里的描述不准确,不是“查询不到自己的修改”,而可以描述为“发现自己的修改没有应用到所有记录上(也就是说有例外)"
MySQL默认隔离级别为repeatable read,而Oracle是read committed
查询和设置隔离级别:

JDBC
Java数据库连接,(Java Database Connectivity,简称JDBC)是Java语言中用来规范客户端程序如何来访问数据库的应用程序接口,提供了诸如查询和更新数据库中数据的方法。 JDBC也是Sun Microsystems的商标。 JDBC是面向关系型数据库的。
Java定义了一套操作所有关系型数据库的规则(接口),具体的实现由各自的数据库软件负责,从而实现用一套统一的Java代码操作所有的关系型数据库,即以接口类型调用方法,真正实现的是实现类中的方法


JDBC快速入门:
package com.jiading.jdbc;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.Statement;
//JDBC入门
public class JDBCDemo1 {
public static void main(String[] args) throws Exception {
//导入驱动jar包
//注册驱动
Class.forName("com.mysql.cj.jdbc.Driver");
//获取数据库连接对象
Connection conn=DriverManager.getConnection("jdbc:mysql://localhost:3306/jd1?serverTimezone=UTC","root","root");
//定义SQL语句
String sql="update test set figure1 =10 where figure2=3";
Statement stmt=conn.createStatement();
//执行SQL
int count=stmt.executeUpdate(sql);
System.out.println(count);
stmt.close();
conn.close();
}
}Class.forName()将类的字节码文件加载到内存中
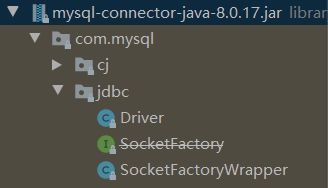
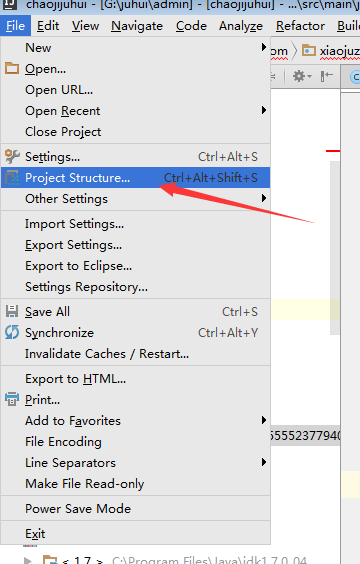
这里注意注册驱动部分的路径怎么写,首先需要先导入jar包,从网络中下载mysql-connect的jar包,将其导入IDEA。导入的过程如下:
先说下第一种方法吧。也就是
File –> Project Structure导入方法
先是进入:File –> Project Structure
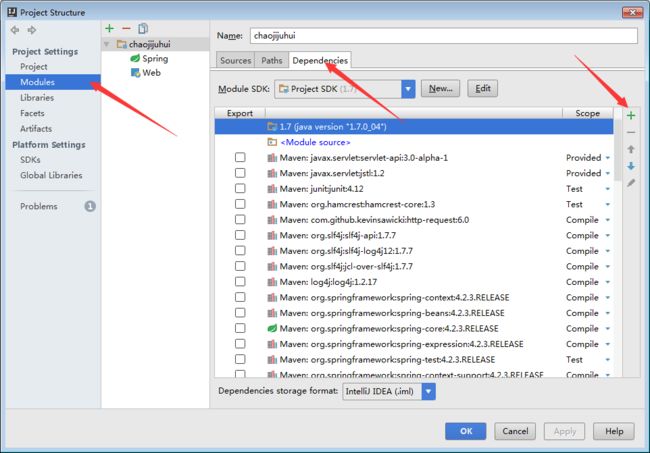
再找到Modules->Dependencies
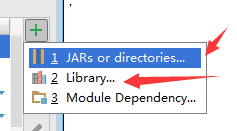
点击最右侧的绿色+号
如图:
选择1或者2都行的:
然后就是选择你要导入的Jar包了。
然后再讲下第二种方式。
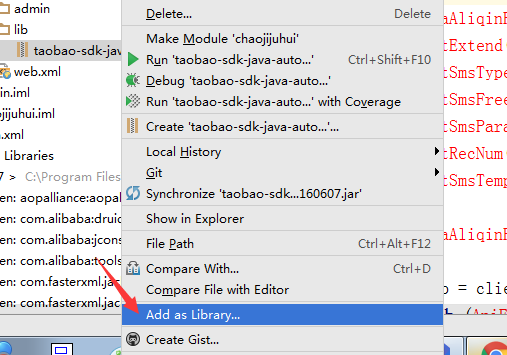
右键添加Jar包
也就是在你需要导入的Jar包上,点击右键,选择Add as Library…
点击OK就行了。
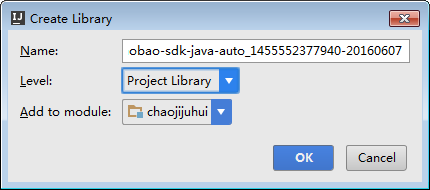
之后按着jar包的目录输入:

题外话,URL中,?被用来分割URL本身和参数,例如这里URL中加入的serverTimezone=UTC就是因为连接时出现了异常“The server time zone value '?й???????' is unrecognized or represents more than one time zo”
详解各个对象
DriverManager

在使用Class.forName()将该Driver类加载到内存时,静态代码块被执行,调用DriverManager的静态方法registerDriver进行了驱动的注册,所以之后我们才能直接调用DriverManager的静态方法使用。
省略注册驱动指的是Class.forName可以省略了:驱动jar包在没有注册驱动时,自动读取META-IN\services下的java.sql.Driver文件进行注册

MySQL默认的端口号是3306
Connection
Statement

Statement执行的静态SQL,PreparedStatement可以执行动态SQL
不经常用statement执行DDL:因为Connection是建立在数据库上的(即URL中有具体的数据库),所以不能用这个命令来处理数据库,而即使是表的设计也是一个很负责的过程,一般都是用SQL的软件完成的,很少用代码直接完成。
刚才代码存在的问题:
- 异常直接抛出了,资源的释放也没有写在finally里面,这样就导致了如果出现异常的话资源就不能正常释放了
示例代码如下:
package com.jiading.jdbc;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.sql.Statement;
//JDBC入门
public class JDBCDemo2 {
public static void main(String[] args) {
//导入驱动jar包
//注册驱动
Statement stmt=null;
Connection conn=null;
try {
Class.forName("com.mysql.cj.jdbc.Driver");
String sql="update test set figure1 =10 where figure2=3";
try {
conn=DriverManager.getConnection("jdbc:mysql://localhost:3306/jd1?serverTimezone=UTC","root","root");
stmt=conn.createStatement();
int count=stmt.executeUpdate(sql);
System.out.println(count);
if(count>0){
System.out.println("添加成功!");
}
else{
System.out.println("添加失败");
}
} catch (SQLException e) {
e.printStackTrace();
}
} catch (ClassNotFoundException e) {
e.printStackTrace();
}finally{
/*
先释放stmt,再释放conn,因为stmt是由conn创建的
为了能够在finally中释放这两个变量,需要将它们定义在try之前,先赋值为Null(这个术语叫变量的抽取)
同样的,为了避免空指针异常,我们需要在释放前先判断,如果是null就不释放了
*/
if(stmt!=null) {
try {
stmt.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if(conn!=null) {
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
//获取数据库连接对象
//定义SQL语句
//执行SQL
}
}
注意,这里的注释有错位
executeupdate方法不仅可以执行DML,还可以执行DDL语句,对表进行修改
ResultSet对象:DQL返回的对象
其实就是对查询的结果的封装。
ResultSet游标:查询开始时指向表第一行的上一行
next():游标向下一行。注意,这里移动游标获取之前一定要先加一个判断,判断是否有数据。这个判断不需要我们去写,而是next方法自己就会返回的:next方法是一个boolean类型的方法,如果调用了之后当前行没有数据其会返回null,否则会返回true。以此为条件就能判断了。将next方法写在while中,还可以实现循环遍历
getXXX(参数):XXX代表数据类型,这是获取数据的方法,例如getInt\getString等。注意,获取数据时不是把一行的所有数据都获取了,而是只获取某一列的数据
其中参数可以接受Int或者String。传入Int代表获取该行中第几列的值(注意,这里特殊的是,标号是从1开始的),传入String则是具体的指明获取的列的label.
练习
定义一个方法,查询emp表的数据将其封装为对象,然后装载集合,返回
代码如下:
- Jd1.java
package com.jiading.jdbc;
/*
封装emo表数据的JavaBean
*/
public class Jd1{
private int day;
private int year;
public int getYear() {
return year;
}
public void setYear(int year) {
this.year = year;
}
public int getDay() {
return day;
}
public void setDay(int day) {
this.day = day;
}
@Override
public String toString() {
return "JDBCDemo3{" +
"year=" + year +
", day=" + day +
'}';
}
}
- JDBCDemo3.java
package com.jiading.jdbc;
import java.sql.*;
import java.util.ArrayList;
import java.util.List;
public class JDBCDemo3 {
public static void main(String[] args) {
//这里又用到了匿名内部类,并且这里的类还是我们写的这个java类
Liste=new JDBCDemo3().findall();
System.out.println(e);
}
public List findall(){
/*
查询所有Jd22对象
*/
/*
如果将对象的创建写在循环内,会产生许多引用。
此时的一个优化策略是将引用写在外面,先赋值为null,在循环中每次new新对象即可
*/
Jd1 re=null;
Listlist=null;
Connection conn=null;
Statement stmt=null;
ResultSet rs=null;
try {
Class.forName("com.mysql.jdbc.Driver");
conn=DriverManager.getConnection("jdbc:mysql://localhost:3306/jd1?serverTimezone=UTC","root","root");
String sql="select * from test";
stmt=conn.createStatement();
rs=stmt.executeQuery(sql);
/*
这里注意,List在Java中是一个抽象类,是不能直接实例化的,而ArrayList则是对List的一种实现,实际实例化的常常是ArrayList
*/
list=new ArrayList();
while(rs.next()){
int year=rs.getInt("year");
int day=rs.getInt("day");
re=new Jd1();//引用绑定到新对象上
re.setDay(day);
re.setYear(year);
list.add(re);
}
} catch (ClassNotFoundException | SQLException e) {
e.printStackTrace();
}finally{if(conn!=null){
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if(stmt!=null){
try {
stmt.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if(rs!=null){
try {
rs.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
return list;
}
}
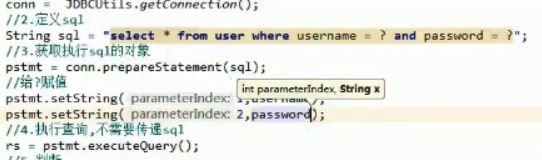
PreparedStatement类
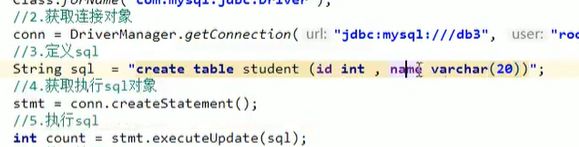
Sql注入问题:
如图,and和or都是左结合的,最后and是嵌套在or里面的
解决:使用PreparedStament对象
PreparedStament是Statement的子接口,但是其是预编译的SQL:参数使用占位符替代,例如:
select * from user where username =? and password=?;获取执行sql语句的对象 PreparedStatemnet connnection.preparedStatment(string sql);//和获取statement不同,获取PreparedStatement对象是要传参数的
由于我们的sql中内容是以占位符形式代替的,所以将sql传入后需要先给它赋值(先传再赋值)
实际情况下使用的大多都是PreparedStatement来完成增删查改,它不仅可以防止SQL注入,而且效率更高
JDBC工具类
这个是自己搭建的,用于简化重复的代码
其实Connection也是工具类,工具类有个特点,就是所有的方法都是静态的,以便我们进行调用具体的方法解决问题,而不至于一直关注于对象的创建(例如String类的valueof方法就是静态的,目的是为了其他类型向String的转化)。所以,我们在写的时候也这样做。
步骤:
- 注册驱动
- 抽取一个方法获取连接对象
- 抽取一个方法释放资源
注意,不是每一次使用我们都需要注册驱动的,所以注册驱动的部分我们写成一个单独的方法,需要的时候再调用
使用JDBC来控制事务
事务的管理是由Connection对象完成的
- 开启事务:事务的开启要放在获取连接之后
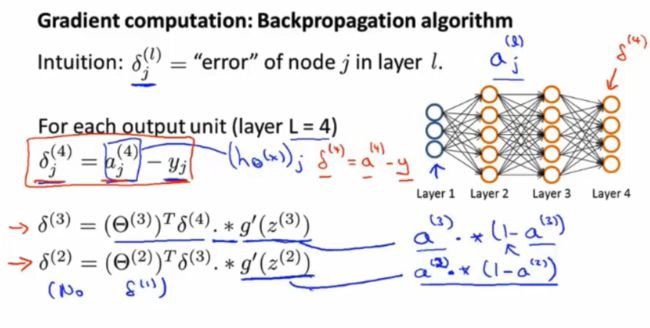
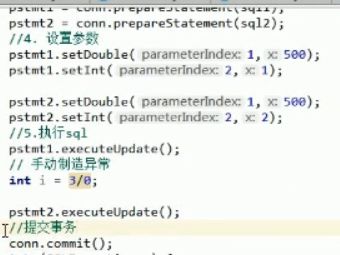
- 提交事务:放在所有业务完成之后,也就是try的末尾
- 回滚事务:放在catch里面
这里catch的是一个大的异常,以便于在遇到各种问题的时候都回滚。当然,我们需要先判断一下conn是不是null,因为可能在conn实例化之前就发生了异常,此时就不需要回滚了。
数据库连接池
连接对象用完了不释放,而是放入连接池,之后需要直接调用
接口由Sun公司定义,由数据库方实现
实现:

对于用户来说,归还和之前使用的销毁对象是没有区别的
这个东西一般我们不去实现,而是由数据库厂商实现
今天讲解两种不同的实现形式:

C3P0
使用起来有两种方法:硬编码和配置文件,一般推荐使用配置文件方法,以增强通用性


注意开发环境,jar包的版本
c3p0-config.xml必须放在src根目录下
配置文件参数讲解:
最大连接数:同时能使用的最大连接数量
和的区别:
c3p0允许用户在配置文件中保存多种配置,使用name进行区分,在new ComboPolledDataSource()时如果括号什么都不写,就使用默认配置;要是括号写了name的字符串,就使用对应的配置 druid

注意,druid和C3P0相比:
- 配置文件可以叫任意名字,可以放在任意目录
- 连接池对象不再是new出来的,而是通过工厂类获取
druid工具类
有些框架不需要获取连接池对象,只需要连接池即可,所以要加上获取连接池的方法
JDBCTemplate
Spring JDBC
使用Junit单元测试:可以让方法独立执行,而不再依赖于主方法。需要在之前加一个@Test.最重要的是,这样我们就可以创建多个方法,分别对其进行调试,而相互之间不会影响,也不需要主方法,非常利于调试
可以将获取JdbcTemplate的部分作为成员变量,这样就不需要每个方法都获取一次了。
注意,queryForMap()查询的结果集长度只能是1:如果本次查询会返回两个及以上结果,则会报错。所以如果结果有可能是多个,应该使用queryForList()或者query()
queryForList()是将每一条记录封装为一个map集合,再将map装载到List中
如果要将查询结果封装为其他类型,就使用query()方法,在传入sql的同时再传入RowMapper接口类型的对象,这里我们自己自己实现一下:
最重要的是要实现一下RowMapper的mapRow方法
注意,我们在自己实现的时候就可以填要返回的类型了,这里填的是需求中的Emp类(泛型)。
而RowMapper也自己提供了一些实现类,有的是很常用的,不需要每次都自己去实现。
这里的泛型填自己要返回的类型就好了,当然,我们的类的属性要和所查询的属性名称以及类型相一致。
这里有一个常见的问题:我们在定义类的时候如果使用的是基本数据类型,那么它是不能接受Null的,这样在sql中就可能会有问题:因为有些数据库中的数据返回的就是null,所以我们应该使用引用数据类型,例如Int、Double等。

对于queryForObject()方法,我们初始化时要输入返回的结果的类型,例如这里的Long.class,返回的就是Long这个类。