序列标注相关方案
1.背景
序列标注是一个比较广泛的任务,包括分词,词性标注,命名实体识别,关系抽取等等,甚至你也可以用来做抽取式QA,直接在文章中标注出答案。
这里跟大家提一下分词,很基础也是很重要的一个任务,我说重要指的是我们应该掌握分词有哪些算法,而不是说这是一个很好的研究方向,目前分词可提升的空间很小了,所以不建议大家研究这个,但是可以做一些小实验看看。
另外给大家介绍一些比较好用的中文分词工具:
结巴分词(比较简单方便,我用这个来分词)
LTP(哈工大NLP(https://www.ltp-cloud.com/),我用这个做过词性标注和命名实体识别,有时候可能需要在词向量的基础上加一些人工特征,引入额外特征信息)
Hanlp(Github文档写得挺不错的(https://github.com/hankcs/HanLP),Java接口,现在也有人写了Python接口)
StandfordCoreNlp(这也是中文的,我一般用Standford工具来处理英文)
序列标注任务的一般形式:
对于待标注的一段序列 X={x1,x2,…,xn},我们需要给每个xi预测一个tag,
先定义Tag集合是 T = {t1,t2,…,tm},比如,分词的Tag可以定义为{Begin,Middle,End,Single},命名实体识别的Tag可以定义为{形容词,名词,动词,…..},
假设预测序列是 Y={y1,y2,…,yn},那我们要计算P(Y|X)从而得到序列Y,
再定义对应的真实Label序列是 L = {l1,l1,…,ln},那我们就对Y和L使用交叉熵计算Loss,通过梯度下降来求解参数。
这么说来,他比较像序列分类,但是和普通分类不一样的是,这些预测的tag之间可能是有关联的,我们可能需要通过上一个tag的信息去预测下一个tag,比如分词,如果上一个预测的tag是Begin,那么下一个tag就不应该是Single。
序列标注常见的算法有HMM(隐马尔科夫模型),MEMM(最大熵隐马尔科夫模型),CRF(条件随机场),以及LSTM-CRF模型,
其中HMM和CRF都是概率图模型,而LSTM本身也很适合序列建模问题,LSTM-CRF是目前比较主流的做法,本文主要介绍HMM,CRF和LSTM-CRF,怎么用于序列标注任务。
2.HMM
2.1 基本概念
HMM是一种生成式有向图模型,对**联合分布进行建模求解**p(x, y)。

如图,HMM包括两组变量x和y:
x={x1,x2,…,xn}属于观测变量,也就是我们观测到的信息,定义观测值集合为O \in {o1,…,oM},其中M为可能的观测值。
y={y1,y2,…,yn}属于状态变量,或者叫隐变量,因为y是不可观测的,系统通常会在状态值集合S \in {s1,s2,…,sN}中进行状态转换,其中N为可能的状态数。
首先我们来定义以下两个隐马尔科夫假设:
1)观测独立性假设:在任意时刻t下,观察值 x_t 仅与当前的状态值 y_t 有关
(也正是这个假设限制了HMM的特征选择,无法考虑到上下文特征)
2)齐次马尔科夫假设:在任意时刻t下,状态 yt y t 只和前一个状态 yt−1 y t − 1 有关,与其他状态及观察值无关,和 yt−2 y t − 2 无关,和 xt x t 也无关
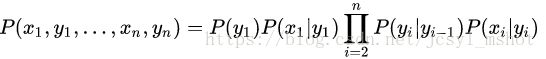
接下来还会涉及到以下三组概率参数:
状态转移矩阵:A = [aij]N∗N [ a i j ] N ∗ N ,表示在 t 时刻下,状态 si s i 转移到状态 s_j 的概率:
aij=P(yt+1=sj|yt=si),1≤i,j≤N a i j = P ( y t + 1 = s j | y t = s i ) , 1 ≤ i , j ≤ N
观测概率矩阵: B=[bij]N∗M,表示在状态si下生成观测oj的概率: B = [ b i j ] N ∗ M , 表 示 在 状 态 s i 下 生 成 观 测 o j 的 概 率 :
bij=P(xt=oj|yt=si),1≤i≤N,1≤j≤M b i j = P ( x t = o j | y t = s i ) , 1 ≤ i ≤ N , 1 ≤ j ≤ M
初始状态概率分布: π=(π1,π2,...,πN) π = ( π 1 , π 2 , . . . , π N ) ,表示初始时刻下各状态出现的概率:
πi=P(y1=si),1≤i≤N π i = P ( y 1 = s i ) , 1 ≤ i ≤ N
HMM可以解决以下三类推断问题:
1)似然问题:给定模型 λ=[A,B,π] λ = [ A , B , π ] ,求解 P(x|λ) P ( x | λ )
2)解码问题:给定模型 λ=[A,B,π] λ = [ A , B , π ] 和观测序列x,求解 状态序列 y
3)学习问题:给定观测序列x,求解模型参数 λ=[A,B,π] λ = [ A , B , π ]
2.2 HMM解决序列标注问题
回到我们的序列标注问题,也就是解码问题,这里以分词为例,状态集合可以定义为{B,M,E,S},观测序列就是我们的句子,状态序列y是我们的分词结果,我们用Viterbi算法来求解最大概率对应的状态序列y,也就是最有可能出现的状态序列.
Viterbi算法
大家不要把viterbi算法和HMM绑定到一起,这个算法本来是用动态规划来求最短路的,不是专门给HMM设计的,只是恰好可以求解HMM的解码问题。
算法基于这样的前提:最优路径的子路径也一定是最优的。
算法思路大概是:从根节点出发,每走一步,比较根节点到上层节点的最短路径+上层节点到当前节点的最短距离,递归计算到达该点的最短路径,一直走到终点。
那么viterbi算法用于HMM,就是求解给定观测值x后概率最大的状态序列y,如果使用穷举法会带来巨大的计算量,所以viterbi对状态进行转移,而状态数往往是比较少的。
【【https://zh.wikipedia.org/wiki/维特比算法 讲解清晰移动】
下面三张图可以清楚的展示这过程:
一个人可以观察到的状态有三种 正常 发冷 头晕,对应的状态分别可能是健康或则发烧 健康与发烧之间转换为状态转换矩阵,健康或发烧 状态下的正常、发冷,头晕概率为发射矩阵
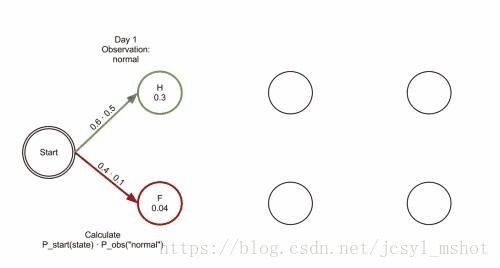
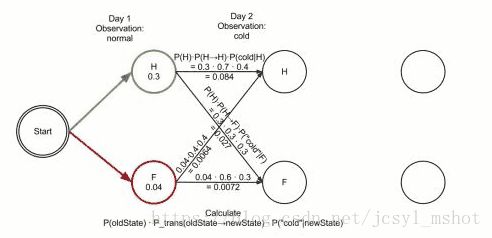
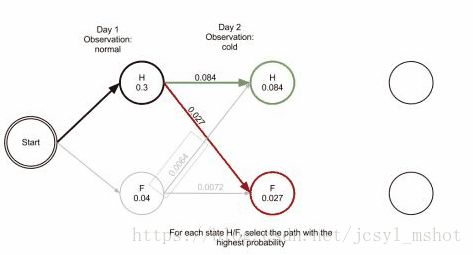

回到分词任务,tag集合是{B,M,E,S},假设现在观测序列是“我喜欢吃海底捞”:
第一步“我”对应的状态y1有4种取值,取最大概率应该是tag S
第二步“喜”对应的状态y2也有4种,根据y1计算出最大概率应该是tag B
第三步“欢”对应的状态y3也有4种,根据y2计算出最大概率是tag E
……
可以看到,这里只需要计算4*4*7次,而穷举法却需要计算4^7次!
另外,结巴分词对viterbi算法做了一些改进:
1)PrevStatus转移条件,比如,状态B的前一状态只能是E或者S。
2)终止条件,最后一个状态只能是E或者S,表示词的结尾。
3)取log把概率连乘转化为连加,所以概率矩阵中可能有负数
3. CRF(条件随机场)
前面介绍的HMM其实分词结果比较一般,在很长一段时间,CRF都是序列标注任务的标配(当然现在主流做法也是LSTM套上CRF)。
3.1 基本概念
CRF是一种判别式无向图模型,对条件分布进行建模,构建条件概率模型p(y|x)。
1.直观感受
令G=(V,E)表示节点与标记向量y中元素一一对应的无向图,V是节点的集合,E是无向边, yv y v 表示与节点v所对应的标记变量,n(v)表示节点v的邻接节点,V/v 表示除了结点v 以外的所有结点。如果图G的每个变量 yv y v 都满足以下的马尔科夫性质:
P(yv|x,yV/v)=P(yv|x,yn(v)) P ( y v | x , y V / v ) = P ( y v | x , y n ( v ) ) ]
那么(y, x)就构成了一个条件随机场。(可以直观理解为某个位置的赋值仅与相邻的位置赋值和当前的状态有关)
2. 通过特征函数构建结点与标签直接的关系
CRF引入了特征函数(exp形式)来定义序列y的条件概率:
P(y|x)=1Zexp(∑j∑n−1i=1λitj(yi+1,yi,x,i)+∑k∑ni=1μksk(yi,x,i)) P ( y | x ) = 1 Z e x p ( ∑ j ∑ i = 1 n − 1 λ i t j ( y i + 1 , y i , x , i ) + ∑ k ∑ i = 1 n μ k s k ( y i , x , i ) )
其中tj和sk 其 中 t j 和 s k 都是特征函数, tj t j 用来描述两个相邻位置的y 之间的关系 以及x对y的影响, sk s k 描述x 在位置i 对y 的影响。特征函数是事先定义好的, λj和μk λ j 和 μ k 才是我们的参数,也就是说,CRF需要训练的,只是这些特征的权重。
另外,这里还做了全局归一化,Z是规范化因子,CRF对Y中所有可能的状态序列做了全局的归一化,避免了label bias的问题。(MMEN是本地归一化)
3.2. CRF解决序列标注问题
我们需要事先定义特征函数,因此CRF开源工具提供了特征模板,Unigram /Bigram Template,自动生成特征函数。
假设L是标注的类别数量,N是从模板中扩展出来的字符串种类数量,
Unigram Template是一元模板,反映了训练样例的情况(比如词性和对应的标注情况),一个模型生成的特征函数的个数总数为L*N
Bigram Template是二元模板,自动产生当前output token和前一个output token的组合,最终产生L * L * N种特征。(如果类别数很大,会产生非常多的特征)
现在特征函数有了,那我们就可以求解概率了,然后进行解码,Viterbi算法大家还记得吗?我们依然要用viterbi算法寻找最佳标注路径。viterbi算法并不是只能用于HMM,我们只要定义好概率的计算方式,就可以用上viterbi算法来求最佳路径了
现在我们来分析一下,CRF在序列标注任务上的地位:
1)解决HMM的观测独立性限制特征选择的问题(此时MEMM表示自己也可以),CRF会用到了上下文信息作为特征。
2)解决MEMM对节点进行归一化所造成的label bias问题,CRF是全局归一化。
3)对特征的融合能力强,在消歧和新词发现上表现得比较好
那么,我们现在把LSTM加入PK阵营:(先假定我们在LSTM上接softmax进行序列标注)
1)LSTM在序列建模问题上表现很强势大家都知道,可以capsule到较为长远的上下文信息,从这一点来看,CRF……猝。但是LSTM也可能会增加模型复杂度,耗费时间。
2)CRF对整个序列来计算似然概率,而LSTM方法是对单步似然进行叠加,从原理上CRF更加符合序列标注任务,考虑到整个序列的标注情况。
3)CRF比较适合小数据集(因为LSTM在缺少数据的情况下可能会过拟合),LSTM比较适合大数据集,自动学习文本特征
4. LSTM-CRF
既然CRF依赖于特征模板,而LSTM可以自动学习特征,那我们可以把LSTM和CRF结合起来。
Pytorch入门文档中提供了一个简单的Bi-LSTM CRF模型,有一点比较坑的是 竟然不是矩阵运算!所以还要改成矩阵运算,不然慢到你怀疑人生。
接下来分析一下这个模型:

假设fθ是LSTM的输出矩阵,[fθ]i,t表示在时刻t下,当前输入映射到tagi的非归一化转移概率,Aij是CRF的状态转移矩阵,表示从tagi转移到tagj的概率 假 设 f θ 是 L S T M 的 输 出 矩 阵 , [ f θ ] i , t 表 示 在 时 刻 t 下 , 当 前 输 入 映 射 到 t a g i 的 非 归 一 化 转 移 概 率 , A i j 是 C R F 的 状 态 转 移 矩 阵 , 表 示 从 t a g i 转 移 到 t a g j 的 概 率
下面定义观测序列x 对于状态序列y 的score是:
s(x,y,θ~)=∑Tt=1([A]yt−1,yt+[fθ]yt,t) s ( x , y , θ ~ ) = ∑ t = 1 T ( [ A ] y t − 1 , y t + [ f θ ] y t , t )
然后通过softmax函数对score进行归一化:
p(y|x)=es(x,y,θ~)∑y~∈Yes(x,y~,θ~) p ( y | x ) = e s ( x , y , θ ~ ) ∑ y ~ ∈ Y e s ( x , y ~ , θ ~ )
其中Y表示所有可能的序列(计算稍微麻烦一些),通过极大似然概率求解 θ θ 。
训练好之后,解码过程依然是用viterbi算法,来求解最佳路径。(训练过程并不会用到viterbi算法,只是在调用模型的时候会用到)
参考文章:
https://zhuanlan.zhihu.com/p/35620631