机器学习|决策树算法与python实现

目录:
-
1.决策树简介
-
2.决策树生成
- a) 选择标准——熵
- b) 信息增益——ID3算法
- c) 信息增益率——C4.5算法
- d) Gini系数——CART算法
- e) 评价标准——评价函数
- 3.剪枝操作
- a) 预剪枝
- b) 后剪枝
-
4.决策树的集成——随机森林
-
5.Sklearn构造决策树
- a) 数据包介绍
- b) 5行代码构造决策树
- c) 参数简介
1.决策树简介
决策树概念:决策树(Decision Trees)是一种非参监督学习方法,即没有固定的参数,对数据进行分类或回归学习。决策树的目标是从已知数据中学习得到一套规则,能够通过简单的规则判断,对未知数据进行预测。这里我们只讨论决策树分类的功能。
决策树组成:根节点、非叶子节点(也叫决策点、子节点、内部节点)、分支(有向边)、叶子节点(叶节点)。其中非叶子节点是一个分支的终点,无法继续分离。
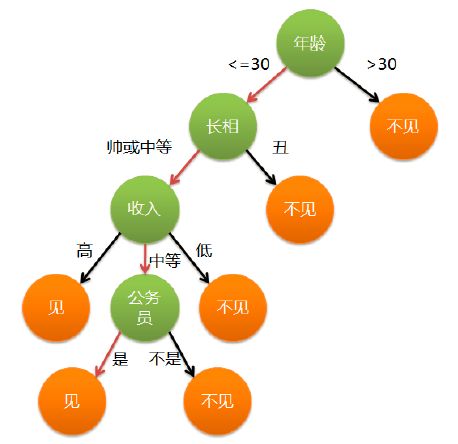
决策流程:所有的数据,从根节点开始,根据某一特征的条件进行分配,进入不同的子节点,不断递归,最终到达叶子节点停止。例如下图是一个判断一家人谁爱玩游戏的决策树。

2.决策树的生成
a.选择标准——熵
决策树很重要的一个问题是选择什么条件和特征来进行分类。举个相亲的例子:当决定是否要与一个相亲的对象见面时,会有一些硬性的标准,比如年龄、长相等,也有一些次要的条件,比如是否是公务员等。和这些标准一样,决策树中也要选择重要的条件和特征进行分类,这种重要性用熵来表示。
熵(entropy):在高中化学中表示物体内部的混乱程度。在概率统计中,表示随机变量不确定性的程度。熵越大,越不确定;熵越接近于0,越确定。举个数组的例子。现在有AB两个数组:
A=[1,2,3,4,2,3,5]
B=[1,1,1,1,2,1,2]
A中数字多,且混乱,而B中主要都是1,偶尔出现2,那么就说A比较混乱,不确定性大,B比较整洁,比较确定。那么A的熵值高,B的熵低。在决策树中,我们希望数据经过一个分支分类后,尽量被分离得清晰整洁,像B一样。熵用数学公式来表达如下:

它表示选用某个特征条件进行分类后,分类结果的混乱程度。其中P代表一个条件下发生的概率。P=0时,定义熵H=0。所以无论P接近0或者1,H都接近0,此时数据结论趋向一致,混乱度低。例如将B数组进行分类,得到[1,1,1,1,1]和[2,2]两个叶子节点,那么根节点的熵为:

有了衡量标准,那么构造决策树的思路也就有了:随着树深度的增加,让节点熵迅速降低。省略掉一些没有实际意义的特征,最终得到一棵最矮的决策树。那么就产生了ID3算法。
b.信息增益——ID3算法
举个分类的例子

在outlook中,一共有14种情况,9个yes和5个no,那么根节点的信息熵为:

经过分类后,形成了三个叶子节点,此时相当于已知两个随机变量X,Y,求联合概率分布下的熵:

根据此公式,先计算各叶子节点中的熵:
Outlook=sunny时,H1=0.971
Outlook=overcast时,H2=0
Outlook=rainy时,H3=0.971
再计算分类后的熵:5/140.971+4/140+5/14*0.971=0.693
这样熵下降了:0.940-0.693=0.247
分类前与分类后,熵的差值,叫做信息增益:
它表示特征A对训练集D的信息增益。因此,我们计算各个分类方法的信息增益,选出最gain(D,A)最大的作为分类条件,即可让总体的熵下降最快。这也是ID3算法的核心思想。
c.信息增益率——C4.5算法
但是信息增益也有行不通的时候。举一个极端的反例。假设每个样本都带有一个不重复的ID,用这些ID作为分类条件,可以一步就完成分类,这种分类方法的熵为0,信息增益很大。但是用这种条件进行分类显然是不靠谱的。因此,可能存在某个条件,分出的种类非常多,每个种类的样本非常少。为了解决这个问题,提出了信息增益率(也叫信息增益比),它等于信息增益除以自身熵:
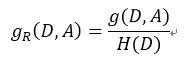
如果分类很快,分布很广的情况发生,虽然方法的信息增益较大,但是自身的熵也会很大,信息增益与自身熵的比就会很小。因此,使用信息增益率来作决策,能够有效地排除上述这种特殊情况。
d.Gini系数——CART算法
同样,Gini系数也是越小,总体越稳定。基于Gini系数最小的原则,产生了CART算法。

e.评价标准——评价函数
在决策树构建完成后,需要评价构建的效果。这个评价效果是由决策树每个叶子节点决定的。

H(t):每个叶子节点的熵值。
Nt:叶子节点上总共的样本数。
3.剪枝操作
当决策树训练完成后,并不是分完就完成了。如果分的太细,可能会出现过拟合的情况。当对未知数据进行分类时,效果可能不好。这时就需要剪枝操作。剪枝操作分两种,分别是预剪枝(前置剪枝)和后剪枝(后置剪枝)。
a.预剪枝
在构建时,加入一些条件,在训练过程中控制决策树的大小。此方法用的较多。预剪枝方法如下:
- 指定最大深度。当达到设定深度后,停止剪枝。
- 指定节点最小样本数量,当小于某个值时,停止剪枝。
b.后剪枝
在决策树构建完成后,对树进行剪枝操作。此方法使用较少。某个节点如果不进行分割时,损失值为:
Cα(T)=C(T)1+α
进行分割后,损失值为:
Cα(T)=C(T)2+α|Tleaf|
哪个损失值低,就采用哪个方法。参数α比较大时,限制比较严,α比较小时,限制较弱。
4.决策树的集成——随机森林
只构造一棵树的时候,可能因为部分错误数据,或某些不重要的特征,造成树过拟合或出现误差。因此可以通过构造很多树,共同来进行决策,降低错误发生的概率。这种集成的算法叫做随机森林。
a.随机有两层含义。第一,有放回的随机采样。假设有100个数据,随机有放回采样60个进行训练。这样能减少离谱数据和错误数据对树造成影响。第二,在特征上也进行随机选择,假设共有10个特征,每棵树随机选5个特征进行分类,降低不重要的特征对树造成影响。
b.森林:训练许多棵树,例如训练20棵。把新的数据分别用这20棵树进行预测,结果遵循少数服从多数的原则,采用20棵树中结果概率最大的分类。
5.sklearn建立决策树:
在sklearn库中,提供了决策树分类方法。大致的步骤是:导入数据→训练模型→预测数据。
a.自带数据包介绍
Sklearn中自带了一些基础的数据集,可供大家练手。例如iris鸢尾花数据集、digits手写数字数据集、boston波士顿房价数据集。它们存放在sklearn.datasets中,只要导入,就可以使用了。
from sklearn import datasets
iris = datasets.load_iris()
boston = datasets.load_boston()这些数据集有点类似于字典,存储了所有的,包括样本、标签、元数据等信息。样本数据存储在.data中,它是一个二维数组,两个维度分别是各样本和各样本的特征,大小为[n_samples, n_features]。对应标签存储在.target中,大小为[n_samples]。因此,可以使用.data和.target可以查看样本和标签。
print (iris.data)
print (iris.target)b.五行代码构造决策树
以iris数据集为例,鸢尾花数据集中包括了3个品种的150朵鸢尾花的数据,数据有4个特征,分别是花瓣和花萼的长度和宽度。以这组数据为例,使用sklearn对150个数据进行分类。我们要设置一个决策树的学习器,并根据需要设置参数。学习器也可以是其他类型,例如支持向量机、线性回归等。
from sklearn import tree
clf = tree.DecisionTreeClassifier()学习器设置完毕后,依次对模型进行拟合与预测。让学习器对数据进行拟合使用.fit函数,预测使用.predict函数。
clf = clf.fit (iris.data[:-2],iris.target[:-2])
clf.predict (iris.data[-2:])以上代码将数据集分成了两部分,从头开始到倒数第二个值作为训练样本,训练完毕后,将最后两个值作为未知样本,进行预测。其中[:-2]表示从头到倒数第二个值,[-2:]最后两个值。完整代码如下:
from sklearn import datasets,tree
iris = datasets.load_iris()
clf = tree.DecisionTreeClassifier()
clf = clf.fit(iris.data[:-2],iris.target[:-2])
print (clf.predict(iris.data[-2:]))同样的,对于随机森林,一段简单的操作代码如下:
from sklearn.ensemble import RandomForestClassifier
from sklearn import datasets
iris =datasets.load_iris()
clf=RandomForestClassifier(n_estimators=5)
clf =clf.fit(iris.data[:-2],iris.target[:-2])
print (clf.predict(iris.data[-2:]))c.参数简介
以上是使用sklearn构造的简单的模型。而sklearn.tree.DecisionTreeClassifier()这个类的构造代码如下:
class sklearn.tree.DecisionTreeClassifier(criterion='gini', splitter='best',max_depth=None, min_samples_split=2, min_samples_leaf=1,min_weight_fraction_leaf=0.0, max_features=None, random_state=None,max_leaf_nodes=None, min_impurity_split=1e-07, class_weight=None, presort=False)以下是一些参数简介。
- criterion:建立划分标准:例如gini系数、熵值划分等
- splitter:best或random,best是找到最好的切分点,random进行随机的选择。
- max_features:最多选多少个特征。特征少的时候不用设置。
- max_depth:指定树最大深度是多少。避免数据太多时太庞大。
- min_samples_split:树进行节点切分时,某个节点样本个数少于此数值,就不再向下切分了。因为切的越多,越准确,但是过拟合的可能越大。
- min_samples_leaf:限制叶子节点最少的样本数。如果叶子节点数目小于样本数,则会和兄弟节点一起被剪枝。
- min_weitht_fraction_leaf:权重项。每个叶子节点加一个权重。当权重乘以叶子节点样本个数太小,则被剪枝。
- max_leaf_nodes:最大的叶子节点数。
- class_weight:样本的权重项。处理不均衡的数据时,可以对这些数据进行权重预处理。
- min_impurity_split:限制决策树的生成。切分后,如果gini系数等参考标准变化小于此值,停止切分。
还有一些优化问题和准确度计算等方面的内容,以后再和大家讨论。
本文参考:
http://scikit-learn.org/stable/modules/tree.html
《决胜AI系列课程》唐宇迪老师