vs2017+配置opencv+cuda环境
在这个VS2017配置OpenCV4.4.0(Win10环境)_m0_54844818的博客-CSDN博客的基础之上在进行下面的配置
一、配置cuda库
1.1 情况1
先装cuda后装vs2017。这样的安装的顺序,一般情况下,cuda和vs2017安装过程不会出现冲突。在确保cuda和vs2017都安装成功情况下,这个时候配置相对简单,主要是把cuda的动态库路径配置好就行。方法和配置opencv环境一样。详细步骤如下:
新建一个vs2017项目,在参考上面贴出配置opencv环境的博客后,你应该知道如下操作(也建议采用临时配置方法):
右键项目 → 属性 → 配置属性 → VC++目录 → 包含目录,添加以下目录:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0\include(注意自己的cuda路径,安装cuda时我是默认安装路径的)
C:\ProgramData\NVIDIA Corporation\CUDA Samples\v11.0\common\inc
库目录,添加以下目录:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0\lib\x64
C:\ProgramData\NVIDIA Corporation\CUDA Samples\v11.0\common\lib\x64
右键项目 → 属性 → 配置属性 → 链接器 → 输入 → 附加依赖项,添加以下库(注意我安装的是cuda10,不同cuda版本下面的库名可能不一样,最好是到这个“C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0\lib\x64”目录去看一下):
cublas.lib
cublasLt.lib
cuda.lib
cudadevrt.lib
cudart.lib
cudart_static.lib
cudnn.lib
cudnn64_8.lib
cudnn_adv_infer.lib
cudnn_adv_infer64_8.lib
cudnn_adv_train.lib
cudnn_adv_train64_8.lib
cudnn_cnn_infer.lib
cudnn_cnn_infer64_8.lib
cudnn_cnn_train.lib
cudnn_cnn_train64_8.lib
cudnn_ops_infer.lib
cudnn_ops_infer64_8.lib
cudnn_ops_train.lib
cudnn_ops_train64_8.lib
cufft.lib
cufftw.lib
curand.lib
cusolver.lib
cusolverMg.lib
cusparse.lib
nppc.lib
nppial.lib
nppicc.lib
nppidei.lib
nppif.lib
nppig.lib
nppim.lib
nppist.lib
nppisu.lib
nppitc.lib
npps.lib
nvblas.lib
nvjpeg.lib
nvml.lib
nvrtc.lib
OpenCL.libVS2017安装
1.下载
这里直接在微软官网下载即可。链接: Visual Studio: 面向软件开发人员和 Teams 的 IDE 和代码编辑器.
其中三个版本都可以选,Community 2017是免费社区版本,Professional 2017和Enterprise 2017是付费版,功能好像没有区别,我这里选择的是Professional版本。
付费版可以使用密匙激活,这里提供两个密匙,如果不能用了就网上找,很多的:
Professional 2017:KBJFW-NXHK6-W4WJM-CRMQB-G3CDH
Enterprise 2017:NJVYC-BMHX2-G77MM-4XJMR-6Q8QF
当然也有网盘链接 里面有安装细节
链接:https://pan.baidu.com/s/1a2gTta31hkJeBYjP0w6J3g
提取码:m1nj
2.安装
VS2017的安装包不同于以前的版本,它提供了一个新的轻量化和模块化的安装体验,可根据需要量身定制安装,只有不到1MB大小。这只是一个引导程序(Web Installer),启动之后勾选需要的组件即可进行安装。
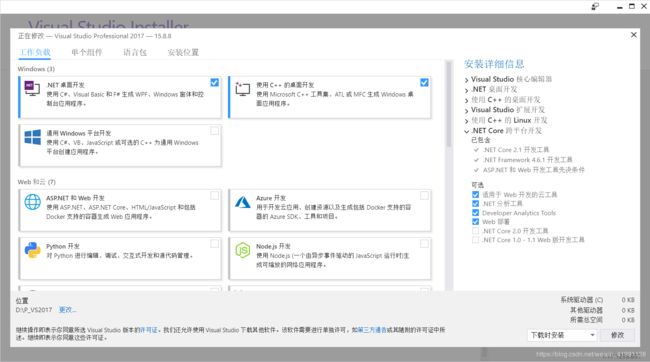
如果初学者并且没有其他特殊需求,选上Windows中的“.NET桌面开发”和“使用C++的桌面开发”以及最下面其他工具集中的“Visual Studio扩展开发”即可。不知道选什么也不要紧,留着这个安装包(严格来说不叫安装包),需要其他组件的时候随时可以添加。
开始前最后的准备:
漫长的等待之后就安装好了,完了之后可能会需要重启,然后打开VS2017,来到这个页面:
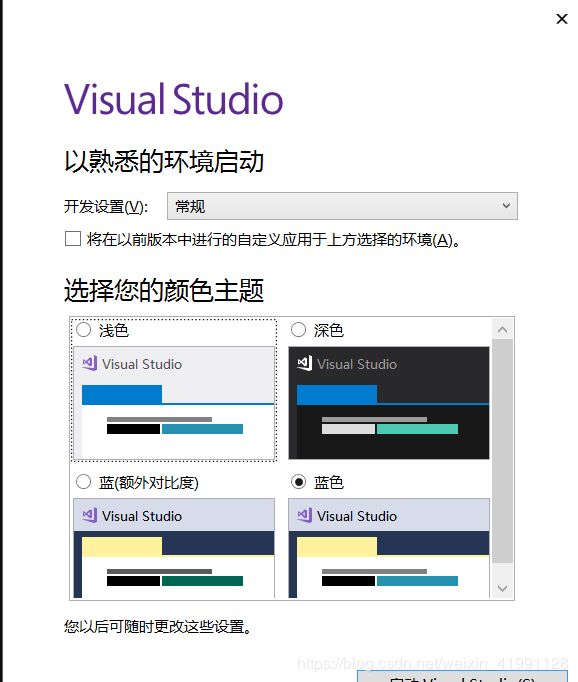
开发设置选择C++,再选一个你喜欢的颜色,即可进入VS2017了。
注册&激活
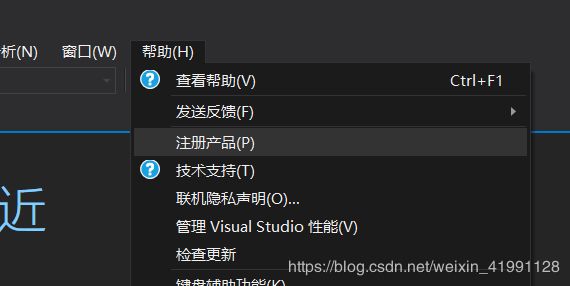
如果是安装的专业版或者企业版的在这里输入密匙激活:帮助—>产品注册—>更改产品密匙。然后就大功告成啦
1.2 情况2
先装vs2017后装cuda会有点小问题。详细情况如下:
安装vs2017肯定没啥问题了。但是安装cuda时,如果还默认安装就会有问题,原因是安装了vs2017。其实,安装cuda时里面会带有vs组件,如果已经安装了vs2017或者比cuda里面自带的版本要高,这个时候cuda安装是不会成功的。正确的方法如下:
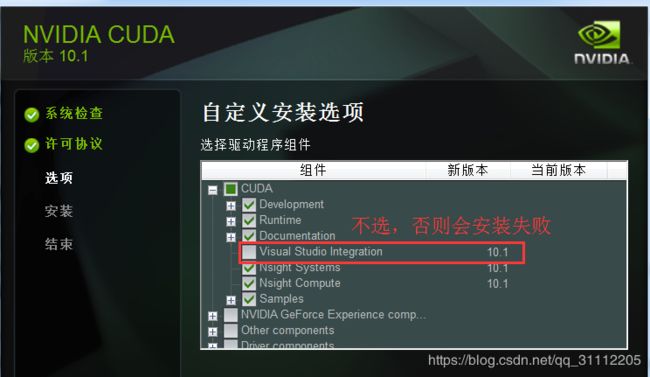

安装的路径看个人习惯了。配置cuda的系统环境和cudnn的资料就比较多了,这里就不贴出了。安装好vs2017和cuda后,现在我们来配置vs2017的cuda环境。
由于安装cuda时我们没有勾选vs相关组件,所以,现在需要做一些其他操作。解压cuda安装程序(即解压cuda_10.0.130_411.31_win10.exe),把“CUDAVisualStudioIntegration\extras\visual_studio_integration\MSBuildExtensions”文件复制到自己安装vs2017路径的“\Common7\IDE\VC\VCTargets\BuildCustomizations”。比如我的如下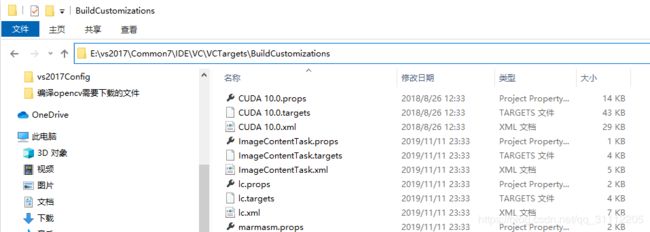
配置完这个后,后面的操作就和第一种情况一样了,按照上面的操作就行。下面配置cuda编辑,编译环境。opencv的就不多说了,贴出的博客中全有。
二、配置cuda编辑、编译和运行环境
2.1 添加.cu源码拓展类型
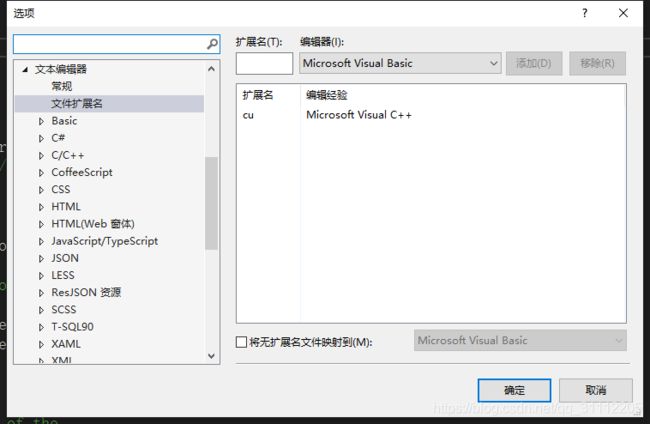
打开VS, 依次打开 工具 选项 文本编辑器 文件拓展名, 新增扩展名:.cu 编辑器:Microsoft Visual C++,点击添加。如下所示:
2.2 设置cuda的生成模板
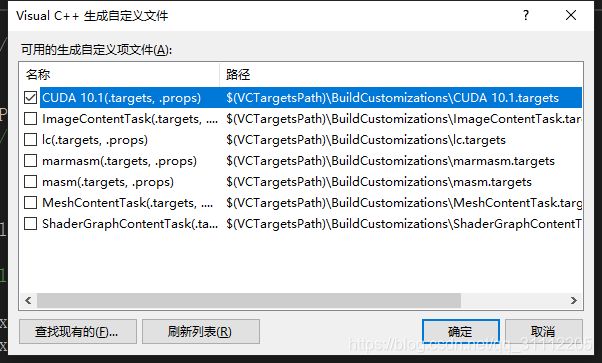
右键项目名称,依次点击 生成依赖项 生成自定义,勾选含有cuda的选项(按照上述两种情况安装的,一般含有该选项,如果没有可参考这里)。如下:
2.3 为项目添加包含的文件类型
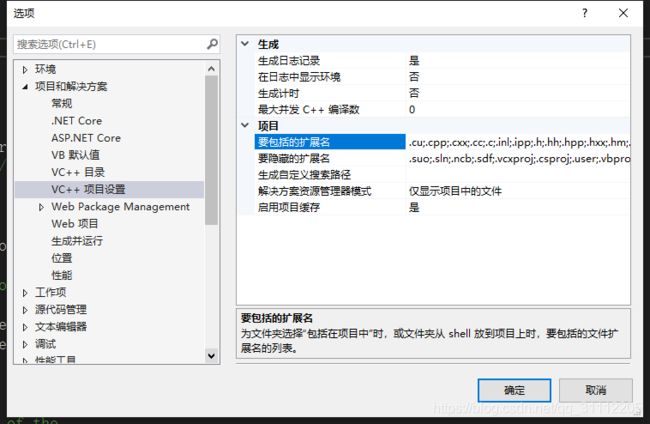
依次选择:工具 选项 项目和解决方案 vc++项目设置;添加.cu,使用分号隔开。如下图:
2.4 为.cu文件选择编译类型
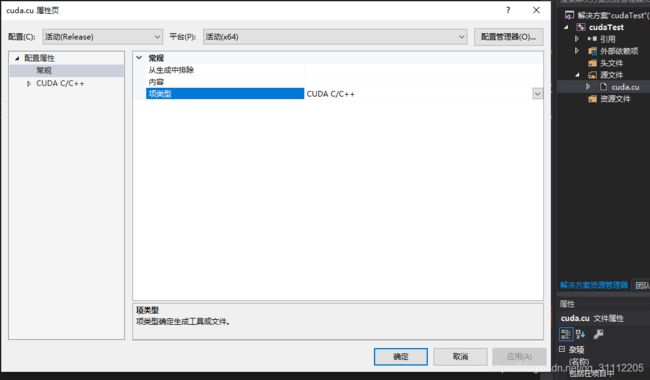
新建.cu文件,要确保项类型是CUDA C/C++类型,具体操作是:右键该.cu文件,选择属性,如下图所示:
三、测试
3.1 测试1
#include
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include
#include
int main() {
int deviceCount;
cudaGetDeviceCount(&deviceCount);
int dev;
for (dev = 0; dev < deviceCount; dev++)
{
int driver_version(0), runtime_version(0);
cudaDeviceProp deviceProp;
cudaGetDeviceProperties(&deviceProp, dev);
if (dev == 0)
if (deviceProp.minor = 9999 && deviceProp.major == 9999)
printf("\n");
printf("\nDevice%d:\"%s\"\n", dev, deviceProp.name);
cudaDriverGetVersion(&driver_version);
printf("CUDA驱动版本: %d.%d\n", driver_version / 1000, (driver_version % 1000) / 10);
cudaRuntimeGetVersion(&runtime_version);
printf("CUDA运行时版本: %d.%d\n", runtime_version / 1000, (runtime_version % 1000) / 10);
printf("设备计算能力: %d.%d\n", deviceProp.major, deviceProp.minor);
printf("Total amount of Global Memory: %u bytes\n", deviceProp.totalGlobalMem);
printf("Number of SMs: %d\n", deviceProp.multiProcessorCount);
printf("Total amount of Constant Memory: %u bytes\n", deviceProp.totalConstMem);
printf("Total amount of Shared Memory per block: %u bytes\n", deviceProp.sharedMemPerBlock);
printf("Total number of registers available per block: %d\n", deviceProp.regsPerBlock);
printf("Warp size: %d\n", deviceProp.warpSize);
printf("Maximum number of threads per SM: %d\n", deviceProp.maxThreadsPerMultiProcessor);
printf("Maximum number of threads per block: %d\n", deviceProp.maxThreadsPerBlock);
printf("Maximum size of each dimension of a block: %d x %d x %d\n", deviceProp.maxThreadsDim[0],
deviceProp.maxThreadsDim[1],
deviceProp.maxThreadsDim[2]);
printf("Maximum size of each dimension of a grid: %d x %d x %d\n", deviceProp.maxGridSize[0], deviceProp.maxGridSize[1], deviceProp.maxGridSize[2]);
printf("Maximum memory pitch: %u bytes\n", deviceProp.memPitch);
printf("Texture alignmemt: %u bytes\n", deviceProp.texturePitchAlignment);
printf("Clock rate: %.2f GHz\n", deviceProp.clockRate * 1e-6f);
printf("Memory Clock rate: %.0f MHz\n", deviceProp.memoryClockRate * 1e-3f);
printf("Memory Bus Width: %d-bit\n", deviceProp.memoryBusWidth);
}
//读取图片(使用图片的绝对路径)
cv::Mat src = cv::imread("123.png");
//显示图片
cv::imshow("Output", src);
//显示灰度图
cv::Mat Gray;
cvtColor(src, Gray, 6);
cv::imshow("Gray", Gray);
cv::waitKey(0);
return 0;
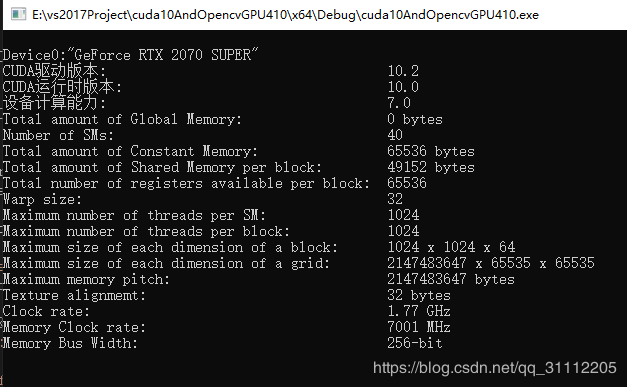
} 结果图:
3.2 测试2
链接:https://pan.baidu.com/s/1QkGrF5uilBjCLgfZpBqCSA
提取码:2xk6
里面包含了c++和python调用的cuda dnn的案例代码,下载的cache缓存和opencv450的cuda10.1版本编译好的opencv库
dnn yolo使用cuda加速程序验证
验证代码如下:
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
constexpr float CONFIDENCE_THRESHOLD = 0;
constexpr float NMS_THRESHOLD = 0.4;
constexpr int NUM_CLASSES = 80;
// colors for bounding boxes
const cv::Scalar colors[] = {
{0, 255, 255},
{255, 255, 0},
{0, 255, 0},
{255, 0, 0}
};
const auto NUM_COLORS = sizeof(colors) / sizeof(colors[0]);
int main()
{
std::vector class_names;
{
std::ifstream class_file("yolo/coco.names");
if (!class_file)
{
std::cerr << "failed to open classes.txt\n";
return 0;
}
std::string line;
while (std::getline(class_file, line))
class_names.push_back(line);
}
cv::VideoCapture source("yolo_test.mp4");
auto net = cv::dnn::readNetFromDarknet("yolo/yolov4-tiny.cfg", "yolo/yolov4-tiny.weights");
net.setPreferableBackend(cv::dnn::DNN_BACKEND_CUDA);
net.setPreferableTarget(cv::dnn::DNN_TARGET_CUDA);
//net.setPreferableBackend(cv::dnn::DNN_BACKEND_OPENCV);
//net.setPreferableTarget(cv::dnn::DNN_TARGET_CPU);
auto output_names = net.getUnconnectedOutLayersNames();
cv::Mat frame, blob;
std::vector detections;
while (cv::waitKey(1) < 1)
{
source >> frame;
if (frame.empty())
{
cv::waitKey();
break;
}
auto total_start = std::chrono::steady_clock::now();
cv::dnn::blobFromImage(frame, blob, 0.00392, cv::Size(416, 416), cv::Scalar(), true, false, CV_32F);
net.setInput(blob);
auto dnn_start = std::chrono::steady_clock::now();
net.forward(detections, output_names);
auto dnn_end = std::chrono::steady_clock::now();
std::vector indices[NUM_CLASSES];
std::vector boxes[NUM_CLASSES];
std::vector scores[NUM_CLASSES];
for (auto& output : detections)
{
const auto num_boxes = output.rows;
for (int i = 0; i < num_boxes; i++)
{
auto x = output.at(i, 0) * frame.cols;
auto y = output.at(i, 1) * frame.rows;
auto width = output.at(i, 2) * frame.cols;
auto height = output.at(i, 3) * frame.rows;
cv::Rect rect(x - width / 2, y - height / 2, width, height);
for (int c = 0; c < NUM_CLASSES; c++)
{
auto confidence = *output.ptr(i, 5 + c);
if (confidence >= CONFIDENCE_THRESHOLD)
{
boxes[c].push_back(rect);
scores[c].push_back(confidence);
}
}
}
}
for (int c = 0; c < NUM_CLASSES; c++)
cv::dnn::NMSBoxes(boxes[c], scores[c], 0.0, NMS_THRESHOLD, indices[c]);
for (int c = 0; c < NUM_CLASSES; c++)
{
for (size_t i = 0; i < indices[c].size(); ++i)
{
const auto color = colors[c % NUM_COLORS];
auto idx = indices[c][i];
const auto& rect = boxes[c][idx];
cv::rectangle(frame, cv::Point(rect.x, rect.y), cv::Point(rect.x + rect.width, rect.y + rect.height), color, 3);
std::ostringstream label_ss;
label_ss << class_names[c] << ": " << std::fixed << std::setprecision(2) << scores[c][idx];
auto label = label_ss.str();
int baseline;
auto label_bg_sz = cv::getTextSize(label.c_str(), cv::FONT_HERSHEY_COMPLEX_SMALL, 1, 1, &baseline);
cv::rectangle(frame, cv::Point(rect.x, rect.y - label_bg_sz.height - baseline - 10), cv::Point(rect.x + label_bg_sz.width, rect.y), color, cv::FILLED);
cv::putText(frame, label.c_str(), cv::Point(rect.x, rect.y - baseline - 5), cv::FONT_HERSHEY_COMPLEX_SMALL, 1, cv::Scalar(0, 0, 0));
}
}
auto total_end = std::chrono::steady_clock::now();
float inference_fps = 1000.0 / std::chrono::duration_cast(dnn_end - dnn_start).count();
float total_fps = 1000.0 / std::chrono::duration_cast(total_end - total_start).count();
std::ostringstream stats_ss;
stats_ss << std::fixed << std::setprecision(2);
stats_ss << "Inference FPS: " << inference_fps << ", Total FPS: " << total_fps;
auto stats = stats_ss.str();
int baseline;
auto stats_bg_sz = cv::getTextSize(stats.c_str(), cv::FONT_HERSHEY_COMPLEX_SMALL, 1, 1, &baseline);
cv::rectangle(frame, cv::Point(0, 0), cv::Point(stats_bg_sz.width, stats_bg_sz.height + 10), cv::Scalar(0, 0, 0), cv::FILLED);
cv::putText(frame, stats.c_str(), cv::Point(0, stats_bg_sz.height + 5), cv::FONT_HERSHEY_COMPLEX_SMALL, 1, cv::Scalar(255, 255, 255));
cv::namedWindow("output");
cv::imshow("output", frame);
}
return 0;
} 结果图

参考
VS2015配置Opencv踩坑_m0_54844818的博客-CSDN博客
vs2017配置cuda和opencv环境_SeventhBlue-CSDN博客_cuda opencv
VS2017配置OpenCV4.4.0(Win10环境)_m0_54844818的博客-CSDN博客