个人总结:降维 特征抽取与特征选择
降维
在维度灾难、冗余,这些在数据处理中常见的场景,不得不需要我们进一步处理,为了得到更精简更有价值的信息,我们所用的的各种方法的统称就是降维。
降维有两种方式:
(1)特征抽取:我觉得叫做特征映射更合适。因为它的思想即把高维空间的数据映射到低维空间。比如PCA和LDA即为一种特征映射的方法。还有基于神经网络的降维等。
(2)特征选择:
- 过滤式(打分机制):过滤,指的是通过某个阈值进行过滤。比如经常会看到但可能并不会去用的,根据方差、信息增益、互信息、相关系数、卡方检验来选择特征。
- 包裹式:每次迭代产生一个特征子集,评分。
- 嵌入式:先通过机器学习模型训练来对每个特征得到一个权值。接下来和过滤式相似,通过设定某个阈值来筛选特征。区别在于,嵌入式使用机器学习训练;过滤式采用统计特征。
特征抽取
典型的特征抽取,如PCA和LDA。将数据映射到新的空间维度。
特征选择
过滤式
方差
方差越大说明这个特征离散程度越大,我们认为这个特征是越有用的。而方差越小,这个特征对算法作用可能没那么大。极端情况方差为0,说明特征取值完全一样,没有任何作用,可以完全舍弃。
相关系数
相关系数也叫皮尔森相关系数,说到相关系数必须提到协方差,协方差能够体现两个变量之间的变化趋势:
变化趋势越接近,各项乘积之和为正,协方差为正:
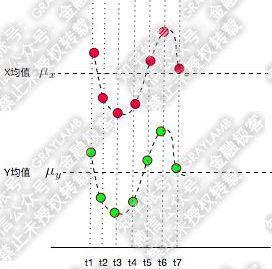
变化趋势越相反,各项乘积之和为负,协方差为负(这里剪了均值是因为协方差会有一个去中心化的操作):

若协方差为0,说明两个变量不相关。
而相关系数可以理解为特殊的协方差,量纲化后的协方差。
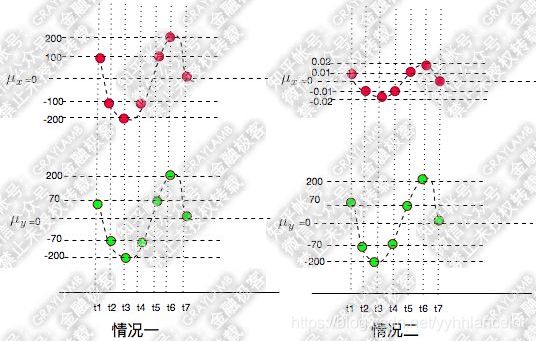
稍微计算一下,情况一的协方差为15428.57,情况二为1.542857。变化的趋势一致,但是变化的幅度不同,导致了这个差别。
于是需要把变化幅度的影响提出,就提出了相关系数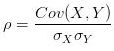 ,标准差
,标准差![]() 描述了变量偏离均值的幅度(为啥要平方开根,这是因为要把可能的负值变为正)。简单计算可以发现两种情况的相关系数是相同的。
描述了变量偏离均值的幅度(为啥要平方开根,这是因为要把可能的负值变为正)。简单计算可以发现两种情况的相关系数是相同的。
所以当相关系数为1时,两者完全正相关,你变大一倍,我也变大一倍;
相关系数为-1,完全负相关;相关系数为0,两个变量无关。
在机器学习中就可以通过计算某一个特征和标签的相关系数,设定一个相关系数的绝对值作为阈值。(负相关的变量也是有用的,再加个负它就是正相关了,所以这里采用绝对值)
卡方检验
卡方检验可以检验某个特征分布与输出值分布之间的相关性。![]() 。它的出发点假设特征分布和输出值分布是独立不相关的。通过计算X2,再通过自由度查表,可以找到无关的概率,从而推断出相关的概率。
。它的出发点假设特征分布和输出值分布是独立不相关的。通过计算X2,再通过自由度查表,可以找到无关的概率,从而推断出相关的概率。
比如一个四格表:
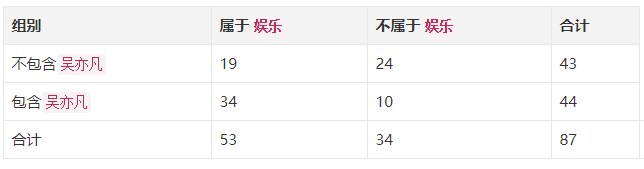
假设吴亦凡这个特征和娱乐这个标签是独立无关的。则一条新闻属于娱乐类别的概率为53/87=60.9%。
于是理论的四格表如下:

然后将这个理论的分布与原始的分布,计算他们的X2。可以很明显看到,如果X2越大,则分布差异越大,两个变量越相关;如果X2为0,则说明分布完全一致,两个变量不相关。找到X2后,再通过自由度和查表就可以了解到两个变量不相关的概率,进而推断出相关的概率。
除了卡方检验,类似的还有F检验和t检验,只不过用的是F分布和t分布而已。
互信息
在决策树中提到了信息增益(互信息),信息增益表示由于特征A而使得数据集的分类不确定性减少的程度,信息增益大的特征具有更强的分类能力。
包裹式
递归消除特征法 recursive feature elimination : RFE
选择一个机器学习模型,每轮训练后移除若干权值系数的特征,再基于新的特征集进行下一轮训练,直到达到规定的n_features_to_select。RFE可结合交叉验证来选择最优的n_features_to_select。
比如选择SVM作为基模型,每次训练得到一个超平面wx+b=0。每次选择w中分量的平方值wi^2最小的值,这个序号对应的特征将其剔除。
包裹式的思想类似于AdaBoost,在每一轮迭代都得到“增强”。
嵌入式
嵌入式与包裹式不同,嵌入式使用所有数据进行训练。这里提到过的Lasso回归,就是通过加大正则化系数,使各个特征系数逐渐变0。越来越大时某些特征系数可能会先变为0,这时我们通过这种方式筛掉一些特征。但是需要注意的是,Ridge回归没办法把系数完全变为0,所以没办法做特征选择。
这是由于:
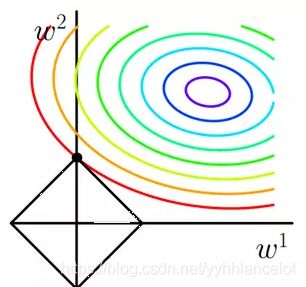
Lasso的惩罚项L1规定的范围“四四方方、有棱有角”,所以最优解的系数刚好被压缩成0,因此Lasso可以实现对变量的选择(系数为0的变量就被筛掉了)。
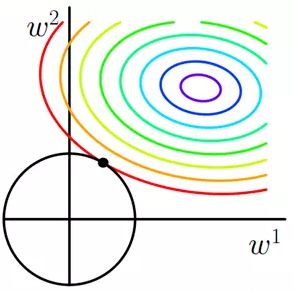
而Ridge的L2是一个“圆锥形”,它的特性无法让系数完全为0,只能越来越趋近0。无法做特征选择。
此外,决策树和GBDT这样可以得到特征系数coef或者特征重要度feature importance的学习模型也可以作为嵌入式的基学习器。
高级特征
高级特征通过某些特征子集来衍生。
比如可以通过相加、相减、乘积、除商来得到。但是在实际业务中没有这么简单,需要通过业务和模型进行得到。在进行聚类的时候可以少一点高级特征,在分类回归的时候可以多一些。