数据分析36计(16):和 A/B 测试同等重要的观察性研究:群组研究 VS 病例-对照方法...
往期系列原创文章集锦:
数据分析36计(15):这个序贯检验方法让 A/B 实验节约一半样本量
数据分析36计(14):A/B测试中的10个陷阱,一不注意就白做
数据分析36计(13):中介模型利用问卷数据探究用户心理过程,产品优化思路来源
数据分析36计(12):做不了AB测试,如何量化评估营销、产品改版等对业务的效果
数据分析36计(11):如何用贝叶斯概率准确提供业务方营销转化率
数据分析36计(十):Facebook开源时间序列预测算法 Prophet
数据分析36计(九):倾向得分匹配法(PSM)量化评估效果分析
数据运营36计(八):断点回归(RDD)评估产品设计效果
数据分析36计(七):营销增益模型(uplift model)如何识别营销敏感用户群-Python
数据运营36计(六):BG/NBD概率模型预测用户生命周期LTV-Python
数据运营36计(五):马尔可夫链对营销渠道归因建模,R语言实现
数据运营36计(四):互联网广告渠道归因分析之Sharply Value
数据运营36计(三):熵权法如何确定指标权重构建评价体系
数据运营36计(二):如何用合成控制法判断策略实施效果
数据运营36计(一):生存分析与用户行为如何联系起来
1. 群组研究 VS 病例-对照研究
观察性研究是研究设计中的重要类别,目前能准确得出因果关系的方法主要是随机分组实验设计方法,即我们常说的 A/B 测试,对于无法实现随机分组实验的场景,可以通过观察性研究得出结论。观察性研究可能是解决因果关系这类问题的下一个最佳方法。之前在这里已经总结了常用的观察性研究方法:一图讲清因果推断方法论,无法 AB 测试时分析的万能钥匙。
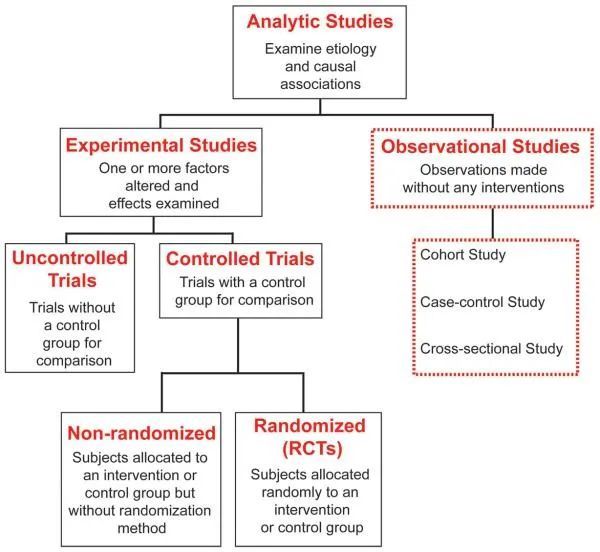
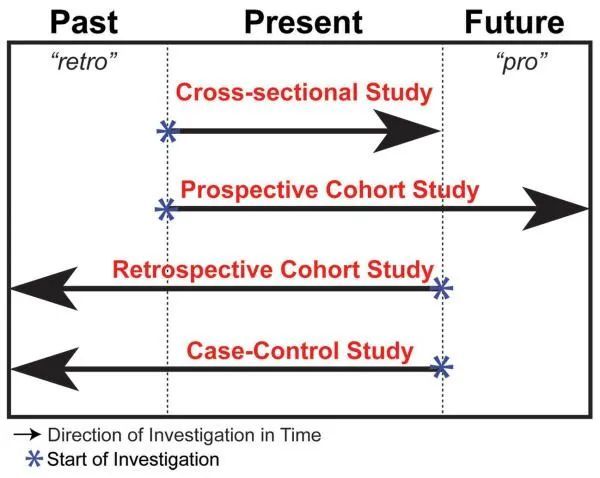
群组研究(cohort study)和 病例-对照研究(case-control study)是观察研究的两种主要类型,主要用于医学判断评估疾病和条件暴露之间的关联。其中群组研究又分为前瞻性群组研究和回顾性群组研究。前瞻性群组研究是指研究开始时,暴露因素已经存在,但研究结果还未出现,需要前瞻随访观察一段时间才能得到,即从现在追踪到未来。回顾性群组研究是指研究开始时暴露和疾病均已发生,其特点是追溯过去历史资料确定暴露于非暴露组,然后追查到现在的发病情况。下图展示了几个观察性研究的时间段和研究方向:
群组研究(cohort study)是将某一特定人群按是否暴露于某可疑因素或暴露程度分为不同组,追踪观察两组或多组成员结果(如疾病)发生的情况,比较各组之间结果发生率的差异,从而判定这些因素与该结果之间有无因果关联及关联程度的一种观察性研究方法。即由因及果,从因素追踪结果。
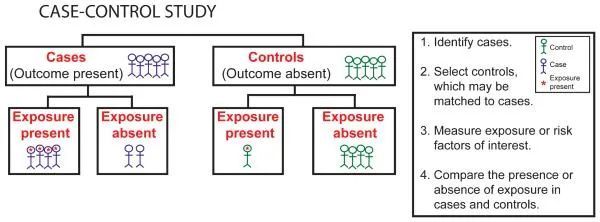
病例对照研究(case-control study)利用已患病(或相关症状)的病人,再与没有患病的人作出比较,以找出一些病症的特征,即从结果的不同分为不同组,比较某因素导致该结果的可能性,由果及因,先确定结果,再找之前的因素。

2. 统计学中常用的 RR、OR、HR的含义及区别
相对风险率 Risk Ratio (RR)
RR=暴露组的发病率/非暴露组的发病率,它是反映暴露与发病(死亡)关联强度的指标。通常,暴露可以指危险因素,比如吸烟、高血压,也可指服用某种药物。而事件可以是疾病发生,比如肺癌、心血管病,也可指服药后的治疗效果。RR表明暴露组发病或死亡的危险是非暴露组的多少倍。RR值越大,表明暴露的效应越大,暴露与结局关联的强度越大。
暴露因素 |
患肺癌 |
未患肺癌 |
抽烟者 |
a=20 |
b=80 |
非抽烟者 |
c=1 |
d=99 |
其中吸烟者患肺癌的概率为20%,非吸烟者患肺癌的概率为1%。这种情况在上边的2×2表中表示。这里的RR=(a/(a+b))/(c/(c+d)),相对风险经常用于二元结果的统计分析,其中感兴趣的结果具有相对低的概率。因此,它通常适用于临床试验数据,用于比较未接受新药物治疗(或接受安慰剂)的人群与接受既定(标准治疗)治疗的人群发生疾病的风险。或者,它用于比较接受药物的人产生副作用的风险与未接受治疗(或接受安慰剂)的人相比。它特别有吸引力,因为它可以在简单的情况下手工计算,但也适用于回归建模,通常在泊松回归框架中。在实验组和对照组之间进行简单比较:
RR = 1 意味着两组之间的风险没有差异。
RR <1 表示实验组中发生的事件不太可能发生在对照组中。
RR> 1 表示事件更可能发生在实验组而不是对照组。
优势比 Odds Ratio (OR)
优势比用于反映病例与对照在暴露上的差异,从而建立疾病与暴露因素之间的联系。
OR=(病例组暴露人数/非暴露人数)/(非病例组暴露人数/非暴露人数),适用于retrospective cohort(回溯性研究)。
示例:OR的计算公式是: OR=a/c/(b/d)=ad/cb,OR 的三个要素:
OR的值,和RR判断标准一致。
P_value <0.05 时两组的暴露史比例差异显著,提示暴露可能与疾病有联系。
计算OR 95%可信限(confidence interval)可由R软件 fisher.test() 函数计算出这三个值。
OR与RR的区别:
1、RR的计算需要使用发病率,因此群组研究、随机对照试验等前瞻性研究均可使用RR;但若是开展回顾性研究(如病例-对照研究),只能根据研究对象的结果状态分组,无法直接计算暴露人群和非暴露人群的发病率,这种情况则需要使用OR。
2、公式不难看出,两者的差异主要来源于分母,即 a/(a+b) 和 a/b 的区别,因此,若a数值较小,则 a/(a+b)≈a/b ,也就是说,当该疾病发生率较低时(罕见病),其RR值和OR值的大小是近似的。因此这类疾病,若无法实施群组研究,则可采用病例-对照研究中的OR值替代RR值。
风险比 Hazard Ratio(HR)
HR=暴露组的风险函数h1(t)/非暴露组的风险函数h2(t)
t 指在相同的时间点上
风险函数指危险率函数、条件死亡率、瞬时死亡率。
Cox比例风险模型可以得到,HR要用于生存分析。
HR与RR的区别
1. 两者均用于前瞻性研究,多数认为HR与RR意思一样,但从计算公式可看出,HR还考虑了时间因素,换言之,包含了时间效应的RR就是HR;
2. 从终点时间的角度来看,也可以这样理解,RR考虑了终点事件的差异,而HR不仅考虑了终点事件的有无,还考虑了到达终点所用的时间及截尾数据。
3. 分析案例
上面主要是从医学概念上介绍了两个观察性研究的原理,对于该方法如何使用到产品效果分析和影响因子分析中,这里主要用两个案例说明:
群组研究
背景:某在线学习类产品同时上线三个功能,且三个功能都可能对课程完成率有影响,现在需要分析三个功能哪个更有可能导致了课程完成率的出现。
方法:这里用相对风险率 RR 来分析。比如功能1的相对风险率 RR=0.70/0.41=1.70。通过上面的方法分别算出3个功能的相对风险率 RR,汇总如下:
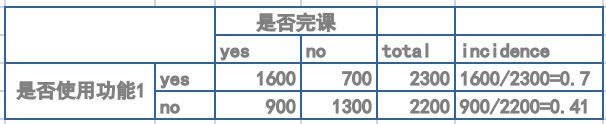

如果特定的变量与结果之间没有关联,那么我们期望RR = 1.0。这里可以看到功能3的RR最大,且95%的置信区间的最小值都在2.74,且p值显著,说明这里由功能3导致课程完成率上升的事件不太可能是随机误差导致的结果,即功能3最有可能导致完课效果变好。
病例-对照研究
背景:目前有性别、过去成绩和过去学习时长三个变量可能会影响到用户课程完成率,判断影响用户是否完成课程的因素。
方法:这里用Logistic回归分析,回归结果的回归系数和OR值来定量说明结论。拟合一个包含性别、成绩、学习时长的Logistic回归,模型为 ln(p/(1-p) = β0 +β1* grade+β2* female+β3* time,回归结果如下(结果经过编辑):
系数β |
P-value |
|
grade |
0.122 |
0.000 |
female |
0.979 |
0.020 |
time |
.0590 |
0.026 |
截距 |
-11.770 |
0.000 |
该结果说明:
性别:在其他两个变量都相同的条件下,女性(female=1)完课的几率(odds)是男性(female=0)的exp(0.979) = 2.7倍,或者说,女性的几率比男性高167%。
成绩:在性别和学习时长都相同的条件下,成绩每提高1,完课的几率提高13%(因为exp(0.122) = 1.13)。
这里假设的是变量间没有交互效应,所谓交互效应,是指一个变量对结果的影响因另一个变量取值的不同而不同。但是对于交互效应存在时,比如性别和成绩有交互效应时,我们可以分别拟合两个方程,然后分别解释。
参考资料:
https://en.wikipedia.org/wiki/Cohort_study
https://api.center.medsci.cn/learn/share-news/7a70e1068f5/17490092
https://zhuanlan.zhihu.com/p/23176211
https://zhuanlan.zhihu.com/p/23268612
https://zhuanlan.zhihu.com/p/24236035