百度网盘AI大赛——图像处理挑战赛:手写文字擦除第8名方案
比赛第八名解决方案
百度网盘大赛二,手写文字擦除
感谢百度组织比赛,感谢团队成员共同努力
特别感谢Jordan2020开源的 基于MTRNet++ 实现图像文字擦除,榜评分0.55599方案,受益颇多。
一、算法介绍
俗话说,选择一个好的baseline就成功了一半(手动狗头),拿到数据集后,我们用Pixel2Pixel,CycleGAN,EnsNet,MTRNet++进行了测试,最后选定了MTRNet++作为baseline。
理由是:带加号的一般更强,这个模型带了俩加号
- End2End,集成度好;
- 模型小,效果也不差,有魔改空间;
- 网络设计更贴近本次比赛任务。
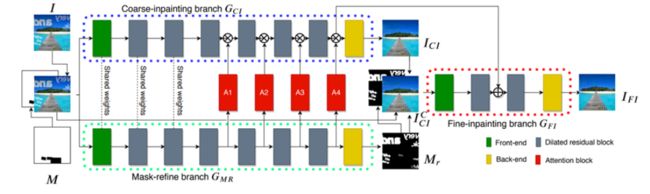
网络架构图:
从MTRNet++
改成了
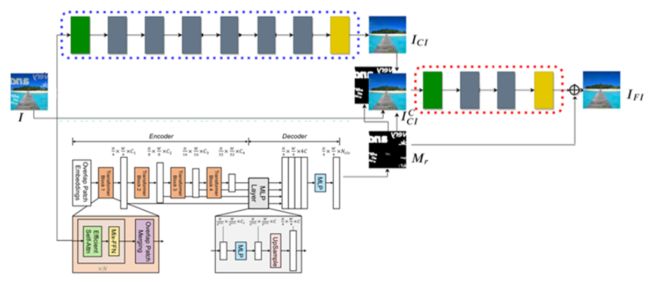
请大家酌情dis
魔改思路:
-
移除输入mask。MTRNet++需要输入mask作为第四通道,
这多不方便,我们给扔了吧若采用全图1填充的方法,感觉这数据多余了,但如果想传入高精度的分割结果,如何获取准确的Mask本身就是一个挑战。因此,我们删除了第四通道,用基于transformer的segformer替代网络中生成msdk的部分,删除A1-A4的门结构,使网络松耦合,便于分离、调优(详见第三节实践调优部分)。 -
修复区域聚焦。原文中,预生成图片(中间那张图,经过GCI后的生成图)经过了cmp(mask白色区域选择生成图片内容,黑色区域选择原图内容,进行叠加生成一张新的图片)操作,我们把这个机制引入到了下一个迭代,最后生成的图片也经过cmp操作后,再与GT做loss运算,这样生成网络的梯度几乎全部来源于mask部分,而非mask部分基本被忽略。我们认为这样训练更快,效果更好。
二、数据增强
兵马未动,粮草先行。这玩意,就是口粮。
- 数据清洗
测量专业的我们拿到图,第一反应永远是:误差在哪?
经过试验后我们认为:两张图片的差别,由系统差别、人为差别、手写字造成的差别共同造成。

上图中,图片排列顺序如下:
原图 真值 阈值1 阈值5
阈值10 阈值15 阈值25
分析结论:
- 阈值为1出现大量像素点,这部分是由于数据存储压缩、插值等原因造成的,认定为系统差别(非计算机专业,表述可能有问题,请意会,请轻拍)
- 阈值为5-25基本可见手写字,但出现的噪点不同,因为处理过程中有的作业员把噪点区域擦出了,有的作业员没有擦除(特别是字里行间,不容易处理的地方)
- 手写字造成的差别,这才是我们真正应该关注的地方
经过数据处理,保留了2、3两类差别,第一类用cmp的方式去除掉了。
增强扩充
- 结合本数据集与公开数据集形成手写字文字素材

- 针对括号、圆圈等误识别区形成素材

- MixUp

简单粗暴,且卓有成效
三、实践调优
代码实现与实践调优:
经过对上述工作后,开始网络训练,发现两个问题:
- 多任务训练过程中,mask任务生成效果不够理想;
- 预测过程中,若对mask进行增强预测,有利于提高精度,但一个网络中难以实现。
理论归理论,实践归实践,精度才是最重要的。模型肢解,优雅不在(这也是前面强调松耦合的原因)。
我们把网络分为两块
- 第一块直接使用PaddleSeg生成网络,单独训练segformerB2
- 另一块训练本网络的其他部分,包含对抗网络生成器与判别器
推理时使用512 512大小的窗口,256 256步长进行滑动预测,生成整张大图的mask(有重复区域滑动效果好);随后擦除图片中对应区域的内容,以512X512大小输入后续网络进行预测。
四、代码介绍-训练复现介绍
#1.准备原料:解压比赛的数据集
!unzip data/data126591/dehw_testB_dataset.zip -d data/ >>/dev/null
!unzip data/data126591/dataset1.zip -d data/ >>/dev/null
!unzip data/data126591/dataset2.zip -d data/ >>/dev/null
#2.准备工具
!pip install scikit_image -q
!pip install paddleseg -q
#3.开始训练第一部分
!python work/train/train_seg.py
#4.开始训练第二部分
!python work/train/train.py
五、代码介绍-预测代码介绍
本部分包含了预测结果代码,运行方式:
1、B榜图片数据放入/dehw_testB_dataset文件夹下(保留,可直接运行);
2、运行1_predict_segformer.py文件,在segoutput文件夹中会出现手写字语义分割的结果,效率:4s/step;
3、第二步运行完毕后,运行2_predictgan.py文件,效率:4s/step;
4、最终提交结果出现在submit文件夹中。
#1.预测大图mask
!python work/pre_and_submit/1_predict_segformer.py
segoutput路径下生成语义分割结果。如下图所示:

#3.手写字压盖信息修补
!python work/pre_and_submit/2_predictgan.py
submit文件夹下得到预测结果:
#4.压缩文件提交评分
%cd submit/
!zip result.zip *.png *.txt
六、致谢
再次郑重感谢:
感谢百度组织比赛,提供机会与舞台
感谢团队成员共同努力,感谢杨立博同学忍受23:00开讨论会的恶习,感谢沈忱的24小时5分钟重启服务,感谢翟雪奎同学分担火力,感谢吕金声的数据支持、协同保障。
特别感谢:
Jordan2020开源的 基于MTRNet++ 实现图像文字擦除,榜评分0.55599方案,受益颇多。