视觉单目标跟踪任务概述
视觉目标跟踪的主要目的是:模仿生理视觉系统的运动感知功能,通过对摄像头捕获到的图像序列进行分析,计算出运动目标在每一帧图像中的位置;然后,根据运动目标相关的特征值,将图像序列中连续帧的同一运动目标关联起来,得到每帧图像中目标的运动参数以及相邻帧间目标的对应关系,从而得到目标完整的运动轨迹。视觉跟踪与传统雷达跟踪系统比,工作时不向外辐射无线电波,不易被电子侦察设备发现,具有一定的隐蔽性和抗电子干扰能力。同时,人们能直接从视频监视器上看到目标图像,具有更好的直观性。
目标跟踪是计算机视觉领域的一个重要问题,目前广泛应用在体育赛事转播、安防监控、无人机、无人车、机器人等领域。研究任务包括以下几种:
- 单目标跟踪:给定一个目标,追踪这个目标的位置。
- 多目标跟踪:追踪多个目标的位置。
- Person Re-ID:行人重识别,是利用计算机视觉技术判断图像或者视频序列中是否存在特定行人的技术。广泛被认为是一个图像检索的子问题,即给定一个监控行人图像,检索跨设备下的该行人图像。旨在弥补固定的摄像头的视觉局限,并可与行人检测/行人跟踪技术相结合。
- MTMCT:多目标多摄像头跟踪(Multi-target Multi-camera Tracking),跟踪多个摄像头拍摄的多个人。
- 姿态跟踪:追踪人的姿态。
目录
- 目标跟踪的主要难点
- 单目标跟踪的基本流程
- 单目标跟踪的分类
-
- 1.经典目标跟踪方法(2010年以前)
- 2.相关滤波(Correlation Filter,CF)
- 3.基于深度学习的跟踪方法(Deep Learning,DL)
-
- (1) 基于预训练深度特征的跟踪模型
- (2) 基于离线训练深度特征的跟踪模型
- (3) 相关滤波融入深度学习框架的跟踪模型
- 单目标跟踪的benchmark
目标跟踪的主要难点
现有的算法虽然能一定程度上完成对运动目标的跟踪,但仍存在诸多问题,主要包括:(1)目前的跟踪算法大多基于某一种特征集合对目标进行描述,不够完备;(2)所提取的特征描述无法更好地区分目标与跟踪背景,当背景与目标相似或背景发生很大变化时,跟踪算法往往失效;(3)由于很难长时间对运动轨迹进行准确预测,因此当遮挡频繁发生时,跟踪算法同样会失效。在现有研究中,长时间复杂动态背景中的鲁棒跟踪也是难点:(1)运动目标本身的变化(尺度、旋转、形状等);(2)运动目标被遮挡;(3)跟踪环境的动态变化(光照变化、图像退化等)。
| The challenging aspects in visual tracking | Description |
|---|---|
| Illumination Variation(IV,照明变化) | 目标区域中的照明显著改变 |
| Scale Variation(SV,尺度变化) | 第一帧和当前帧的边界框比例超出范围 |
| Occlusion(OCC,遮挡) | 目标被部分(Partial)或完全(Full)遮挡,可以利用检测或者分块跟踪进行 |
| Deformation(DEF,形变) | 非刚性物体形变,通常导致跟踪发生漂移(Drift),常用方法是更新目标的表观模型,使其适应表观的变化 |
| Motion Blur(MB,运动模糊) | 目标区域由于目标或摄像机的运动而模糊 |
| Fast Motion(FM,快速运动) | 真实的运动大于20像素 |
| In-Plane Rotation(IPR,平面内旋转) | 目标在平面中旋转 |
| Out-of-Plane Rotation(OPR,平面外旋转) | 目标旋转出图像平面 |
| Out-of-View(OV,超出视野) | 目标中的某些部分离开视图 |
| Background Clutters(BC,背景杂斑) | 目标附近的背景具有与目标相似的颜色或纹理,可以预测运动的大致轨迹或提高分类器对背景和目标的判别能力 |
| Low Resolution(LR,低分辨率) | 真实边界框内的像素数小于400 |
单目标跟踪的基本流程
单目标跟踪任务就是在给定某视频序列初始帧的目标大小与位置的情况下,预测后续帧中该目标的大小与位置。基本任务流程:
输入初始化目标框 --> 在下一帧中产生众多候选框 --> 提取这些候选框的特征 --> 对候选框评分 --> 找到得分最高的候选框作为预测的目标(或对多个预测值进行融合得到更优的预测目标)
根据如上流程,可以将目标跟踪划分为5个主要的内容:
- 运动模型:生成候选样本的质量直接决定了跟踪系统表现的优劣,常用的方法包括粒子滤波(Particle Filter)和滑动窗口(Sliding Window)。
- 特征提取:鉴别性的特征表示是目标跟踪的关键之一。常用的特征被分为两种类型:手工设计的特征(Hand-crafted feature)和深度特征(Deep feature)。常用的手工设计的特征有灰度特征(Gray),方向梯度直方图(HOG),哈尔特征(Haar-like),尺度不变特征(SIFT)等。与人为设计的特征不同,深度特征是通过大量的训练样本学习出来的特征,它比手工设计的特征更具有鉴别性。因此,利用深度特征的跟踪方法通常很轻松就能获得一个不错的效果。
- 观测模型:观测模型作为跟踪算法的核心设计,可分为两类,生成式模型(Generative Model)和判别式模型(Discriminative Model)。早期的工作主要集中于生成式模型跟踪算法的研究,如光流法、粒子滤波、Meanshift算法、Camshift算法等。此类方法首先建立目标模型或者提取目标特征,在后续帧中进行相似特征搜索,逐步迭代实现目标定位。但是,由于目标本身的外观变化有随机性和多样性特点,因此,通过单一的数学模型描述待跟踪目标具有很大的局限性。判别式模型是指,将目标模型和背景信息同时考虑在内,通过对比目标模型和背景信息的差异,将目标模型提取出来,从而得到当前帧中的目标位置。 2010年,MOSSE首次将通信领域的相关滤波方法引入到目标跟踪中。作为判别式方法的一种,相关滤波无论在速度上还是准确率上,都显示出更优越的性能。自2015年以后, 随着深度学习技术的广泛应用,人们开始将深度学习技术用于目标跟踪。
- 模型更新:模型更新主要是更新观测模型,以适应目标表观的变化,防止跟踪过程发生漂移。模型更新没有一个统一的标准,通常认为模型的表观连续变化,所以常常会每一帧都更新一次模型。但是目标的过去表现对跟踪器仍然很重要,连续更新可能会丢失过去的表观信息,引入过多的噪声,因此利用长短期更新相结合的方式可以解决这一问题。
- 集成方法:集成方法有利于提高模型的预测精度,也常常被视为一种提高跟踪准确率的有效手段。可以把集成方法笼统的划分为两类,(1)在多个预测结果中选一个最好的,(2)利用所有的预测加权平均。
单目标跟踪的分类

图片来源:https://zhuanlan.zhihu.com/p/106048100?utm_source=wechat_session
1.经典目标跟踪方法(2010年以前)
- Meanshift(均值漂移算法):基于概率密度分布的方法,使目标的搜索一直沿着概率梯度上升的方向,迭代收敛到概率分布的局部峰值上。每一个像素值代表了输入图像上对应点属于目标对象的概率,适用于目标的色彩模型和背景差异较大的情形。但是,其不能解决目标的遮挡问题并且不能适应运动目标的的形状和大小变化等。
- 卡尔曼滤波(Kalman Filter):对目标的运动建模,估计目标在下一帧的位置。该方法是认为物体的运动模型服从高斯模型,来对目标的运动状态进行预测,然后通过与观测模型进行对比,根据误差来更新运动目标的状态。
- 粒子滤波(Particle Filter):基于粒子分布统计,定义一种相似性度量来确定粒子与目标的匹配程度。搜索过程随机撒一定分布的粒子,计算相似度,在可能的目标位置上下一帧加入更多粒子,防止目标跟丢。
- 基于特征点的光流跟踪:提取特征点,计算下一帧特征点的光流匹配点。在跟踪过程中不断补充新的特征点,删除置信度不佳的特征点。基于特征的方法不断地对目标主要特征进行定位和跟踪,对目标大的运动和亮度变化具有鲁棒性。存在的问题是光流通常很稀疏,而且特征提取和精确匹配也十分困难。
参考链接:
[1] MeanShift 目标跟踪
[2] 无人驾驶汽车系统入门(一)——卡尔曼滤波与目标追踪
[3] 粒子滤波初探(一)利用粒子滤波实现视频目标跟踪的大致流程
[4] 计算机视觉–光流法(optical flow)简介
2.相关滤波(Correlation Filter,CF)
相关滤波的方法起源于信号处理领域,相关性用于表示两个信号之间的相似程度,通常用卷积表示相关操作。基本思想:寻找一个滤波模板,让下一帧图像与滤波模板做卷积操作,响应最大的区域则是预测的目标。
- MOSSE (Minimum Output Sum of Squared Error Filter):《Visual Object Tracking using Adaptive Correlation Filters》是CVPR 2010提出的,可以说是最早将correlation filter用于目标跟踪的论文,为了简化计算,将时域卷积转化为频域相乘。
- KCF (Kernelized Correlation Filter):2014年提出的《High-speed tracking with kernelized correlation filters》论文,使用目标周围区域的循环矩阵采集正负样本,并利用其在傅里叶空间可对角化的性质,大大降低了运算量,使算法满足实时性的要求。
- DSST (Discriminative Scale Space Tracker):2014年提出的《Accurate Scale Estimation for Robust Visual Tracking》对MOSSE做了改进,能够处理尺度变化,在 VOT 2014 Benchmark中排名第一。作者将目标跟踪看成目标中心平移和目标尺度变化两个独立的问题:将灰度特征替换为HOG特征训练平移相关滤波,负责检测目标中心,样本中每个像素点计算28维融合特征(1维原始灰度+27维hog);尺度相关滤波提取33种不同尺度下的样本。
- SAMF (Scale Adaptive & Multiple Features):《A Scale Adaptive Kernel Correlation Filter Tracker with Feature Integration》是在ECCV 2014 workshop上提出来的,是在KCF的基础上改进的,采用多特征(灰度\Hog\CN(color namespace))融合,并且采用多尺度搜索策略。
参考链接:
[1] Correlation Filter in Visual Tracking系列一:Visual Object Tracking using Adaptive Correlation Filters 论文笔记
3.基于深度学习的跟踪方法(Deep Learning,DL)
由于卷积特征能输出更强的表达,因此初期将其输出特征直接应用,优于HOG或CN特征,但是也带来了计算量的增加。分类(检测)任务关心的是区分类间差异,忽视类内的区别;而目标跟踪则是区分特定目标与背景,抑制同类目标。由于两个任务存在本质区别,因此分类数据集上预训练的网络可能并不完全适用于目标跟踪。
(1) 基于预训练深度特征的跟踪模型
- C-COT(Continuous Convolution Operator):《Beyond Correlation Filters: Learning Continuous Convolution Operators for Visual Tracking》是Martin Danelljan在ECCV 2016提出的跟踪算法,并取得了VOT 2016比赛的第一名。论文针对DCF(Discriminative Correlation Filter)最初仅限于单分辨率特征图,需要将所有特征图采样到公共分辨率,而不能具有不同空间分辨率的多个卷积层融合的特征。深层的卷积特征具有判别性,是较高级的视觉信息;浅层包含底层特征,更有利于定位。所以作者提出了一种新型的连续方程,通过一个联合学习框架融合具有不同空间分辨率的多个卷积层,连续域的置信度分数能够实现准确的亚像素定位。
- ECO(Efficient Convolution Operator):继C-COT之后Martin Danelljan为了提升跟踪算法的速度和精度,在CVPR 2017发表了《ECO: Efficient Convolution Operators for Tracking》。作者认为,1)DCF性能提升主要是因为特征强大,但是高维度特征导致训练参数急剧上升,复杂模型容易造成过拟合。提出了因式分解卷积算子,将卷积滤波器构建为基础滤波器的线性组合。2)由于依赖迭代优化算法,DCF方法都需要存储一个很大的训练样本集,但实际资源有限,所以会常常丢弃时间久的样本,以保持合理的内存占用,但会造成模型对最近出现的变化过拟合。提出样本产生模型,降低训练样本的数量。3)大多数DCF方法都是连续的学习方式,在每一帧都更新模型,使得对突然的变化存在过敏反应。提出高效的模型更新策略,使用高斯混合模型,改进速度和鲁棒性。
(2) 基于离线训练深度特征的跟踪模型
- DLT(Deep Learning Tracker):NaiYan Wang在NIPS 2013《Learning A Deep Compact Image Representation for Visual Tracking》提出的,是第一个把深度模型运用在单目标跟踪任务上的跟踪算法,先使用栈式降噪自编码器(SDAE),在Tiny Images dataset的大规模自然图像数据集上进行无监督的离线训练,获取物体的表征能力。在线跟踪部分取离线SDAE的encoding部分,叠加Sigmoid分类层组成了分类网络,利用正负样本对分类网络进行微调。在当前帧采用粒子滤波方式提取一批候选patch,置信度最高的成为最终预测目标。
- MDNet(Multi-Domain):《Learning Multi-Domain Convolutional Neural Networks for Visual Tracking》提出的算法获得了VOT 2015比赛的第一名,动机在于现有的预训练好的网络很大,因为他们主要针对的任务比如目标检测、分类、分割等,要分出很多类别的目标。而在跟踪问题中,一个网络只需要分两类:目标和背景,目标一般都相对比较小,因此大的网络,会增加计算负担。所以,作者为了使CNN提取到视频跟踪数据的共性,采用多域学习的训练方式,每一个mini-batch的构成是从某一视频中随机采8帧图片,在其上随机采32个正样本和96个负样本,固定时间间隔做一次网络更新。
- GOTURN(Generic Object Tracking Using Regression Networks):《 Learning to Track at 100 FPS with Deep Regression Networks》是在ECCV 2016提出的第一个做到100 FPS的深度学习跟踪算法,通过CNN直接回归的方式得到目标位置。该方法通过离线训练带标签的视频和图像来更有效跟踪目标物体,测试时只需要在网络上前向传播,不需要fine-tuning。
- SiamFC:《Fully-Convolutional Siamese Networks for Object Tracking》是2016年提出的,动机是解决神经网络实时跟踪的问题。由于卷积网络先进行离线训练,在线跟踪时需要利用随机梯度下降法(SGD)微调网络权重,从而使速度下降,无法实时跟踪。作者利用全卷积孪生网络进行相似性学习,使用目标检测的ILSVRC数据集训练,再把模型从ImageNet Video域推广到其他视频跟踪数据集域,线上的跟踪过程只需推理即可。
- SiamRPN:《High Performance Visual Tracking with Siamese Region Proposal Network》是商汤在CVPR2018上提出的,孪生候选区域生成网络(Siamese region proposal network),简称Siamese-RPN,包含用于特征提取的孪生子网络和候选区域生成网络,其中候选区域生成网络包含分类和回归两条支路,借鉴了目标检测的RPN结构。在跟踪阶段将跟踪任务构造出局部单目标检测任务,作者预先计算孪生子网络中的模板支路(第一帧),并且将它构造成一个检测支路中区域提取网络里面的一个卷积层,用于在线跟踪。
(3) 相关滤波融入深度学习框架的跟踪模型
- CFNet:《End-to-end representation learning for Correlation Filter based tracking》是发表在CVPR2017的,该跟踪算法与其baseline(SiamFC)较为相似,也是将目标对象的特征表示与搜索区域的特征表示进行比较,搜索区域通过提取窗口(以先前估计的位置为中心,面积为目标区域的4倍),得分最高的位置为目标新位置。作者首先提出了将CF改写成可微分的神经网络层,进而和特征提取网络整合到一起从而实现end-to-end的优化,本文在每一帧计算一个新模板,将其跟之前的模板用滑动平均相结合,从而实时更新。
- ATOM:Martin Danelljan在CVPR2019提出的《ATOM: Accurate Tracking by Overlap Maximization》将跟踪任务分成了两部分:a classification task & an estimation task。前者是粗略地将提取的图像块分为前景和背景,得到粗略的目标位置;后者是通过一个bbox来预测目标的状态。之前CF类跟踪器可以根据最大响应判别目标最可能存在的位置,但不能完全估计目标,比如尺度。而目标的精确估计需要大量的先验信息,例如形变的目标难以单靠跟踪的图像信息进行估计。因此作者参考SiamRPN的离线训练,并且结合在线训练,从IoU-Net改善重合度的角度,使得预测的bbox不仅跟得上,还能很好的框住目标物体。
- DiMP:《Learning Discriminative Model Prediction for Tracking》是Martin的团队在ICCV2019的一篇oral。作者提出现有的孪生模型存在缺陷:(1)仅预测目标的特征模板,却没有集成背景信息,所以具有有限的判别能力,这对于区分场景中的相似目标至关重要;(2)对于不在离线训练集中的目标,这种学习相似性的方法不一定可靠,导致较差的泛化能力;(3)孪生网络没有提供强有力的模板更新策略。因此针对上述三点,DiMP将初始化好的filter结合目标区域的背景信息进行优化,并且结合最速梯度算法加快滤波器的优化。整体网络和ATOM一样分为两个部分:分类+回归,bbox的部分同样利用了IoU-Net。
单目标跟踪的benchmark
结合近10个CVPR2019单目标跟踪papers,得到的主要评价数据集为以下13个:OTB-2013,OTB-2015,VOT2014,VOT15,VOT16,VOT2017,VOT18,UAV123,TrackingNet,LaSOT,Need for Speed (NFS),Temple-Color,ALOV++。其中,使用率最高的为OTB,VOT,UAV123,TrackingNet,LaSOT。
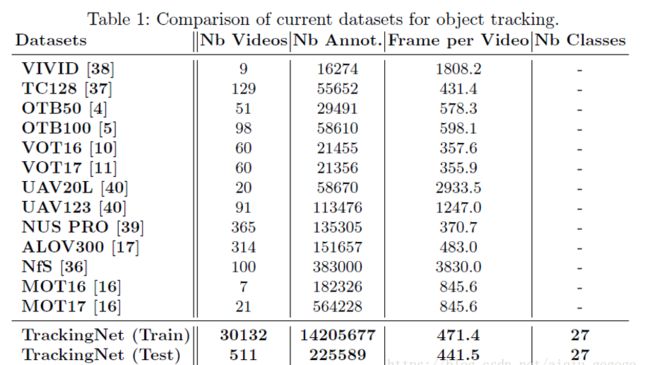
下面对主要数据集情况进行简单描述。
-
OTB:数据集包括50帧的序列和100帧的序列,其中50帧序列的数据集是2013年提出来的,100帧的数据集是2015年提出来的,所以OTB50也叫OTB2013,OTB100也叫OTB2015。OTB100包含25%的灰度数据集,该数据集的特点是人工标注的groundtruth,用9个属性手动标记测试序列,代表了视觉跟踪中具有挑战性的问题。
相关的数据集和测试代码库官网下载:
http://cvlab.hanyang.ac.kr/tracker_benchmark/
OTB50百度云下载地址:
链接:https://pan.baidu.com/s/1rqIX9Eaz6pGPsnbZgDAerw 密码:heyo
OTB100百度云下载地址:
链接:https://pan.baidu.com/s/1TC6BF9erhDCENGYElfS3sw 密码:9x8q
注:OTB100中包含了OTB50中的所有视频 -
VOT:每年都会更新,60个序列,都是彩色序列,分辨率也普遍较高。官网http://www.votchallenge.net/challenges.html
-
UAV:UAV123的数据集,是一个专门场景的数据集,都是用无人机拍摄,特点是背景干净,视角变化较多,包含123个视频,总大小在13.5G左右。
数据集主页:https://ivul.kaust.edu.sa/Pages/Dataset-UAV123.aspx
百度网盘:https://pan.baidu.com/share/init?surl=hQCIjEx5VCZ455IL-Z6y3Q 密码:7lwk,其中包含5个压缩包,一起解压就行。 -
TrackingNet:用于目标跟踪的超大数据集,包含3万+个视频以及1420万个标注框,ECCV2018目标跟踪方面的论文,专为目标跟踪设计。论文全名:《TrackingNet: A Large-Scale Dataset and Benchmark for Object Tracking in the Wild》
官方网站:https://tracking-net.org -
LaSOT:单目标跟踪高质量数据集LaSOT,1400个视频包含70个类别,每个类别包含20个序列,每个序列平均2512帧,可以生成大约352万个高质量的边界框注释。论文《LaSOT: A High-quality Benchmark for Large-scale Single Object Tracking》详细阐述了LaSOT数据集的构造原理和评估方法,被收录于CVPR2019。
官方主页:https://cis.temple.edu/lasot/
参考博文:
[1] 目标跟踪综述
[2] 目标跟踪算法综述