深度强化学习CS285 lec10-lec12(记得看LQR基础知识)
CS285 Model-Based RL
- 概述
- 一、最优控制与规划(Optimal Control and Planning)
-
- 1.1 问题分类
- 1.2 解决方法
-
- 1.2.1 随机优化方法 Stochastic Optimization(Continuous action)
- 1.2.2 蒙特卡洛树搜索 MCTS(Discrete Action)
- 1.2.3 LQR Framework
- 二、MBRL Without Policy Learning
-
- 2.1 Factors That Matters
- 2.2 MBRL算法概述
- 2.3 Uncertainty-Aware Dynamics Model
-
- 2.3.1 Types of Uncertainty
- 2.3.2 Estimate Model Uncertainty
- 2.4 Complex Observations
- 三、Model-Based Policy Learning
-
- 3.1 Model-Based RL With model
- 3.2 Backprop Gradient (Path-Wise Gradient)
- 3.3 Model-free RL With a Model
-
- 3.3.1 Dyna Algorithm
- 3.3.2 Gernal Dyna-style Algorithm
- 3.4 Simpler polices than NN
-
- 3.4.1 Local Policy
- 3.4.2 Combined Policy With Guided Policy Search
- 参考资料
- 补充
概述
之前lecture的RL算法,称作Model-free,其优化目标称为standard RL objective如下:
θ ∗ = arg max θ E τ ∼ p θ ( τ ) [ ∑ t r ( s t , a t ) ] p θ ( τ ) = p ( s 1 ) ∏ t = 1 T π θ ( a t ∣ s t ) p ( s t + 1 ∣ s t , a t ) \begin{aligned} \theta^*=\argmax_\theta E_{\tau\sim p_\theta(\tau)}\Big[\sum_tr(s_t,a_t)\Big]\\ p_\theta(\tau)=p(s_1)\prod_{t=1}^T\pi_\theta(a_t|s_t)p(s_{t+1}|s_t,a_t) \end{aligned} θ∗=θargmaxEτ∼pθ(τ)[t∑r(st,at)]pθ(τ)=p(s1)t=1∏Tπθ(at∣st)p(st+1∣st,at)
对策略policy参数求微分时,忽略了 p ( s t + 1 ∣ s t , a t ) p(s_{t+1}|s_t,a_t) p(st+1∣st,at),是standard-RL中的特点,基于采样的轨迹样本 τ \tau τ来进行值估计 Q ( s , a ) Q(s,a) Q(s,a),或者策略梯度PG更新,得到策略 π θ ( a t ∣ s t ) \pi_\theta(a_t|s_t) πθ(at∣st),这个过程并没有对环境建模,靠的是环境反馈的监督信号 r ( s , a ) r(s,a) r(s,a)。直观理解,一个agent的学习过程完全靠的是trial and error,眼前的路一抹黑,做对了继续做,做错就改,只接受对环境反馈的奖励信息去臆测,而没有对环境感知甚至认知的学习,这样的学习有点”学而不思“,但又因为不受imperfect环境模型的约束,而更flexible,能学到非常好的policy,只是没法将这些策略之间可能性的联系捕捉,缺点就是需要更多的样本。
而Model-Based,就是对环境建立一个model, p ( s ′ ∣ s , a ) p(s'|s,a) p(s′∣s,a),利用对环境的感知进行规划(planning)、预测(prediction)、控制(control)。可以利用model进行最优控制(optimal control),或者在model中辅助policy的学习。下面章节安排为:
- 第一章最优控制:有了dynamics model后,怎么去做规划planning?
- 第二章MBRL : 如何学习dynamics model,会遇到哪些困难,怎么克服?
- 第三章Policy Learning with MBRL:怎么通过dynamics model去学习一个policy?为什么需要学习policy?会遇到哪些困难,该如何克服?
一、最优控制与规划(Optimal Control and Planning)
1.1 问题分类
划分维度有两个,一个是环境的反馈方式分为open-loop与closed loop,另一个是环境的dynamics类型分为deterministic与stochastic
- 环境反馈方式
- Open-Loop 开环

Agent知道环境的初始状态 s 1 s_1 s1,输出一个动作序列 a 1 , . . . , a T a_1,...,a_T a1,...,aT进行control,中间不接受环境的new state反馈,寻找一个最优动作序列,使得 ∑ r ( s t , a t ) \sum r(s_t,a_t) ∑r(st,at)最大,假设dynamics是deterministic的,问题描述为:
a 1 , a 2 , . . . , a T = arg max a 1 , a 2 , . . . , a T ∑ t = 1 T r ( s t , a t ) s . t s t + 1 = f ( s t , a t ) a_1,a_2,...,a_T=\argmax_{a_1,a_2,...,a_T}\sum_{t=1}^Tr(s_t,a_t)\\ s.t\quad s_{t+1}=f(s_t,a_t) a1,a2,...,aT=a1,a2,...,aTargmaxt=1∑Tr(st,at)s.tst+1=f(st,at)
如果dynamics是stochastic的,那问题描述为:
a 1 , . . . , a T = arg max a 1 , . . . , a T E s ′ ∼ p ( s ′ ∣ s , a ) [ ∑ t = 1 T r ( s t , a t ) ∣ a 1 , . . . , a T ] p ( s 1 , s 2 , . . . , s T ∣ a 1 , . . . , a T ) = p ( s 1 ) ∏ t = 1 T p ( s t + 1 ∣ s t , a t ) a_1,...,a_T=\argmax_{a_1,...,a_T}E_{s'\sim p(s'|s,a)}\Big[\sum_{t=1}^Tr(s_t,a_t)\Big|a_1,...,a_T\Big]\\ p(s_1,s_2,...,s_T|a_1,...,a_T)=p(s_1)\prod_{t=1}^Tp(s_{t+1}|s_t,a_t) a1,...,aT=a1,...,aTargmaxEs′∼p(s′∣s,a)[t=1∑Tr(st,at)∣∣∣a1,...,aT]p(s1,s2,...,sT∣a1,...,aT)=p(s1)t=1∏Tp(st+1∣st,at)
因为当动作序列 a 1 , a 2 , . . . , a T a_1,a_2,...,a_T a1,a2,...,aT选定后,deterministic的dynamics时,当在状态 s t s_t st时,下一状态 s t + 1 s_{t+1} st+1是确定的,因此就不需要Expected Reward;而stochastic的dynamics的话,当在状态 s t s_t st时,即使动作序列 a t a_t at也给定,但下一状态还是不确定的,因此当前的 r ( s t , a t ) r(s_t,a_t) r(st,at)需要Expected Reward;
- Closed-Loop 闭环

闭环,一般有两种,第一种是Model-free的,Agent自身有一个policy π ( a ∣ s ) \pi(a|s) π(a∣s);第二种是Model-Based的规划控制,Agent接受到环境的初始状态 s 1 s_1 s1后,agent通过planning,根据自身模拟的stochastic dynamics model采样预测下一状态 s 2 s_2 s2,最大化reward后给出一个可能的动作序列 a 1 , a 2 , . . . , a T a_1,a_2,...,a_T a1,a2,...,aT,执行 a 1 a_1 a1后,观察来自环境真实的 s 2 s_2 s2,可以选择做调整即replan,也可以选择按照原来的plan执行,这时agent不仅可以根据真实环境的state来调整自己的dynamics model,也可以引入MPC(Model Predictive Control)来选择replan与否。
stochastic closed-loop 的问题描述为:
π ∗ = arg max π E τ ∼ p ( τ ) [ ∑ t r ( s t , a t ) ] = arg max π E a ∼ π ( a ∣ s ) , s ′ ∼ p ( s ′ ∣ s , a ) [ ∑ t r ( s t , a t ) ] p ( s 1 , . . . , s T , a 1 , . . . , a T ) = p ( s 1 ) ∏ t = 1 T π ( a t ∣ s t ) p ( s t + 1 ∣ s t , a t ) \begin{aligned} \pi^*&=\argmax_\pi E_{\tau\sim p(\tau)}\Big[\sum_t r(s_t,a_t)\Big]\\ &=\argmax_\pi E_{a\sim\pi(a|s),s'\sim p(s'|s,a)}\Big[\sum_t r(s_t,a_t)\Big]\\ p(s_1,...,&s_T,a_1,...,a_T)=p(s_1)\prod_{t=1}^T \pi(a_t|s_t)p(s_{t+1}|s_t,a_t) \end{aligned} π∗p(s1,...,=πargmaxEτ∼p(τ)[t∑r(st,at)]=πargmaxEa∼π(a∣s),s′∼p(s′∣s,a)[t∑r(st,at)]sT,a1,...,aT)=p(s1)t=1∏Tπ(at∣st)p(st+1∣st,at)
闭环deterministic的dynamics model比较简单,因为下一状态是确定的,而环境又不断给到真实反馈,所以拟合起来十分简单,此处省略。
1.2 解决方法
1.2.1 随机优化方法 Stochastic Optimization(Continuous action)
首先介绍一种只适合open-loop planning的随机优化方法,一般用于连续的动作。给定初始状态 s 1 s_1 s1
- random shooting method (guess&check)
思想:随机选择几组动作,从中选出使性能指标最好的一组。
- 随机选择一些动作 a 1 , . . . , a T a_1,...,a_T a1,...,aT
- Run拟合好的dynamics model s t + 1 = f ( s t , a t ) s_{t+1}=f(s_t,a_t) st+1=f(st,at)
- 计算reward ∑ t r ( s t , a t ) \sum_tr(s_t,a_t) ∑tr(st,at)或者损失 J ( a 1 , a 2 , . . . , a T ) J(a_1,a_2,...,a_T) J(a1,a2,...,aT)
- 从中选择最高的reward或者损失最低的动作序列 a 1 , . . . , a T a_1,...,a_T a1,...,aT
- Cross Entropy Method (CEM)
思想:假设动作序列服从某一先验分布,通过数据后验更新,来拟合较优轨迹服从的分布
- 假设动作序列 A i = a 1 i , a 2 i , . . . , a T i A^i={a_1^i,a_2^i,...,a_T^i} Ai=a1i,a2i,...,aTi服从多元分布,如高斯分布 A ∼ N ( u , Σ ) A\sim N(u,\Sigma) A∼N(u,Σ)
- 评估这些动作序列 J ( A 1 ) , J ( A 2 ) , . . . , J ( A n ) J(A_1),J(A_2),...,J(A_n) J(A1),J(A2),...,J(An)
- 排序后,选择使损失最低的M条动作序列 M = J ( A i ) , J ( A i + 1 ) , . . . , J ( A i + M − 1 ) M=J(A_i),J(A_{i+1}),...,J(A_{i+M-1}) M=J(Ai),J(Ai+1),...,J(Ai+M−1)
- 利用该M条动作序列的mean和variance更新高斯分布 A A A的参数,重复该过程
- Covariance Matrix Adaptation Evolution Strategy (CMA-ES)
思想:通过进一步调整CEM中的更新时的步长参数与协方差矩阵的参数,使得参数调整沿好的搜索方向进行搜索的概率增大。
CMA-ES是CEM的进一步细化,是目前进化策略ES中应用最多的算法之一。假设动作序列同样服从高斯分布 A ∼ N ( m t , σ t 2 C t ) A\sim N(m_t,\sigma_t^2C_t) A∼N(mt,σt2Ct),将每个动作序列建模成:
A i = m t + σ t y i , y i ∼ N ( 0 , C t ) A_i=m_t+\sigma_ty_i,y_i\sim N(0,C_t) Ai=mt+σtyi,yi∼N(0,Ct) y i y_i yi被建模成一个搜索方向,由协方差矩阵的特征分解得到 C t = B D 2 B T C_t=BD^2B^T Ct=BD2BT,于是有 y i = B D z i , z i ∼ N ( 0 , I ) y_i=BDz_i,z_i\sim N(0,I) yi=BDzi,zi∼N(0,I)。
稍微回顾一下协方差矩阵:多元正态分布的概率密度是由协方差矩阵的特征向量矩阵 B B B控制旋转(rotation),特征值的根号对角矩阵 D D D控制尺度(scale),详情可见协方差矩阵的分解.
CMA-ES对均值 m t m_t mt的更新是对选出来的M个值加权求和与CEM相差无几:
m t + 1 = ∑ i M w i A i m_{t+1}=\sum_i^Mw_iA_i mt+1=i∑MwiAi不同之处在于对协方差矩阵 C t C_t Ct的更新,更新原理是构造进化路径,并增大沿成功搜索方向 y i y_i yi的方差,即增大沿这些方向采样的概率.
具体公式原理可参见协方差自适应调整进化策略
小总结一下:上述shooting methods都比较简单,并行起来计算速度也快,其中CMA-ES有点类似于CEM with momentum,是逐步升级的算法。但都有一个共同的缺点,就是当一个动作的维度dimension增大时,搜索空间也极具增大,需要限制在35个随机变量以下。
1.2.2 蒙特卡洛树搜索 MCTS(Discrete Action)
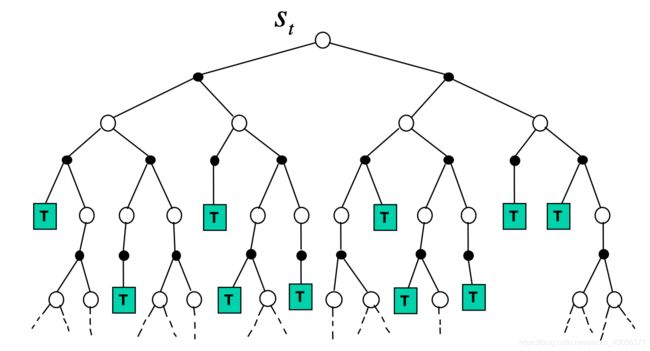
当动作是离散的时候,已经有了一个dynamics model, p ( s ′ ∣ s , a ) p(s'|s,a) p(s′∣s,a)或者 s t + 1 = f ( s t , a t ) s_{t+1}=f(s_t,a_t) st+1=f(st,at),于是就可以通过tree search,利用model进行planning。MCTS的planning主要分成四个模块:
- Selection:对于已经知道状态seen state下的所有actions,按照UCB(Upper Confidence Bound)的原则去选取动作。
- Expansion:对于已经知道状态seen state的下的有未探索过的动作action时,Expand这个state的该action分支
- Simulation:当进入一个全新状态的state,即 V ( n e w s t a t e ) = 0 V(new state)=0 V(newstate)=0,可以不使用UCB来选动作了,采用random policy吧
- Backpropagation:探索到一个终结状态后,更新Selection与Expansion中状态的value与state visits.
因为知道了dynamics model后,就知道了state node之间的转移,构建一个新的tree进行plan就好了,结合如下伪代码加强理解MCTS的思想:
function MCTS_sample(state)
state.visits++
if all children of state expanded:
next_state = UCB_sample(state)
winner = MCTS_sample(next_state)
else:
if some children of state expanded:
next_state = expand(random unexpanded child)
else:
next_state = state
winner = random_playout(next_state)
update_value(state,winner)
UCB(Upper Confidence Bound) :
a t = arg max a [ Q t ( a ) + c l n N t N t ( a ) ] a_t=\argmax_a \Big[Q_t(a)+c\sqrt{\frac{lnN_t}{N_t(a)}}\Big] at=aargmax[Qt(a)+cNt(a)lnNt]
Q t ( a ) Q_t(a) Qt(a)为value estimate, c c c为可调整的超参数, N N N为当前action node的父结点的访问次数, N t ( a ) N_t(a) Nt(a)为在父节点的状态下,选择动作 a a a次数。
UCB的评分原则是:
- 该动作的分数,随着该动作访问次数的增大而减小(鼓励explore)
- 该动作的分数,随着node value Q t ( a ) Q_t(a) Qt(a)的增大而增大(即exploit)
- 总是会探索完所有的action,不然 N t ( a ) = 0 N_t(a)=0 Nt(a)=0,分数无穷大哦~(这就是为啥MCTS适合是离散动作的)
更详细的讲解可以参考这篇paper MCTS Tutorial,非常详细~
A Survey of Monte Carlo Tree Search Methods
1.2.3 LQR Framework
之前的解决方法,stochastic optimization是随机优化连续动作的轨迹,MCTS是通过估计状态值,学习得一个plan tree,然后再search的,是一个离散动作轨迹的优化,这都称作shooting method,只顾着优化action,寻得最优动作序列,问题表述如下:
min u 1 , … , u T c ( x 1 , u 1 ) + c ( f ( x 1 , u 1 ) , u 2 ) + ⋯ + c ( f ( f ( … ) … ) , u T ) \begin{array}{l} {\min _{\mathbf{u}_{1}, \ldots, \mathbf{u}_{T}} c\left(\mathbf{x}_{1}, \mathbf{u}_{1}\right)+c\left(f\left(\mathbf{x}_{1}, \mathbf{u}_{1}\right), \mathbf{u}_{2}\right)+\cdots+c\left(f(f(\ldots) \ldots), \mathbf{u}_{T}\right)} \end{array} minu1,…,uTc(x1,u1)+c(f(x1,u1),u2)+⋯+c(f(f(…)…),uT)
而使用梯度信息的方法,称作collocation method,是一个带约束的优化问题,不止优化action,还连同state一起优化,问题表述如下:
min u 1 , … , u T , x 1 , … , x T ∑ t = 1 T c ( x t , u t ) s.t. x t = f ( x t − 1 , u t − 1 ) \min _{\mathbf{u}_{1}, \ldots, \mathbf{u}_{T}, \mathbf{x}_{1}, \ldots, \mathbf{x}_{T}} \sum_{t=1}^{T} c\left(\mathbf{x}_{t}, \mathbf{u}_{t}\right) \text { s.t. } \mathbf{x}_{t}=f\left(\mathbf{x}_{t-1}, \mathbf{u}_{t-1}\right) u1,…,uT,x1,…,xTmint=1∑Tc(xt,ut) s.t. xt=f(xt−1,ut−1)
具体的解决方法参见上一篇文章LQR Framework的基础知识。
二、MBRL Without Policy Learning
2.1 Factors That Matters
- dynamics model的模型结构选择问题,如高斯结构、深度网络、高斯过程等等
- 如何衡量dynamics model中的Uncertainty?如何在model中操作这个不确定性?
- 如何面对复杂的状态?比如一张图片,难道一个transition ( s , a , s ′ ) (s,a,s') (s,a,s′)中的 s s s对应一张图片?那也太高维度了吧=。=
- 这一章要围绕的就是,怎么学好这个dynamics model
2.2 MBRL算法概述

MRBL0.5算法找一个不错的policy,收集transition data到一个Dataset中,然后就可以进行dynamics model的拟合,拟合好后直接用plan。这种拟合dynamics model的算法与一开始介绍的lec1-lec4中的imitation learning很像,等同于behavioral cloning。因此会有一个distribution mismatch的问题。所以很自然地借鉴DAgger的解决办法,于有了以下MBRL1.0的算法:

MBRL1.0相当于把plan过程中与环境交互的transition作为新样本,回炉再造dynamics,那现在是不是可以了?
当dynamics model拟合得一般的时候,agent连续利用 s t + 1 = f ( s t , a t ) s_{t+1}=f(s_t,a_t) st+1=f(st,at)预测下一状态,选出动作序列 a 1 , a 2 , . . . a T a_1,a_2,...a_T a1,a2,...aT时,会出现compound error的现象,只要model有一点点瑕疵,不断利用其预测下一状态会往糟糕的方向越走越远,因此希望能恰当的时候进行replan,并选择适当的视野horizon,即plan几个动作,比如plan太长动作序列会有coupound error,plan视野太短,又过于短视,容易陷进local minima。下面就是引入了Model Predictive Control进行replan的MBRL1.5算法,已经是一个能work的算法了。

这样应该就比较理想了,但在ICRA2018上一篇Nagabandi的论文,做实验后发现,咦,为什么model-based的表现这么差呢?尽管样本利用率比起model-free确实高不少。很自然想法,可以在model-based train好的policy做model-free的初始化,再用model-free算法继续train,类似于Fine tune。
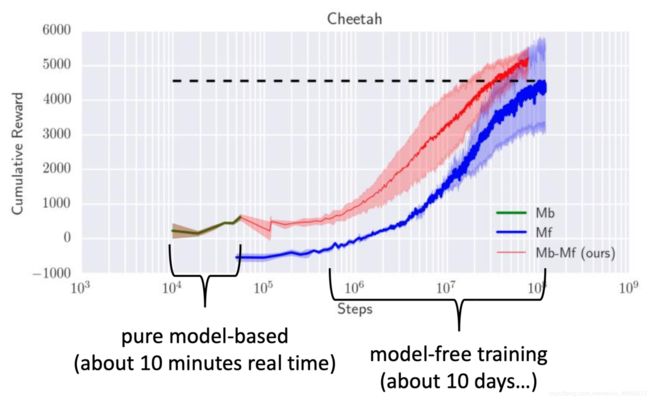
很可能的原因是,dynamics model过拟合了,遇到一些没见过的状态,不知所措,比如 s 1 → s 3 → s 5 s_1\rightarrow s_3 \rightarrow s_5 s1→s3→s5其中 s 1 , s 5 s_1,s_5 s1,s5都很熟悉,完全可以预测到下一状态,但 s 3 s_3 s3没见过呀,只能瞎走了;也有可能是受到了不确定性的困扰,导致不知所措,原地踏步,呜呜呜。
何为受到不确定性Uncertainty的困扰呢?
2.3 Uncertainty-Aware Dynamics Model
2.3.1 Types of Uncertainty
- Model Uncertainty
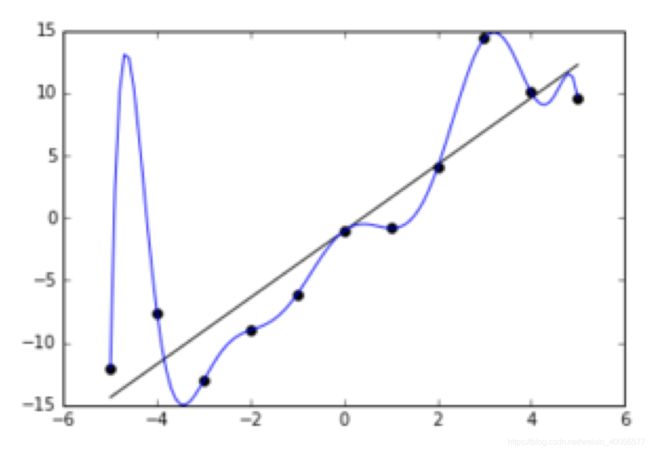
最需要考虑的是来自模型的Uncertainty。比如上图中,x轴为轨迹点 τ \tau τ,y轴为该轨迹的奖励信号 R ( τ ) R(\tau) R(τ),本来真实的轨迹是一条横线,但由于选择的dynamics model太容易过拟合了,现有的数据样本完美过拟合,本来在x轴(-5,0)的位置对应的轨迹是低的,但模型拟合得过高,而优化目标是max这个reward,这就是为什么model-based效果一般的原因。很自然地,将优化目标中的max reward改成Uncertainty中Expected Reward,会比较好。当reward的mean大,Variance大的时候,鼓励去探索,但当reward的mean小,Variance小的时候,就可以有效避免一些极其糟糕的状态,比如从悬崖cliff掉下去这个极端情况。 - Data Uncertainty
数据的不确定性主要源于噪声noise,次要因素,在环境中增加随机噪声,或者在数据中加点随机噪声都能减轻这个uncertainty的影响。
那应该怎么解决Model Uncertainty的问题呢?有没有适用于RL中Dynamics Model的Penalty term呢?这个应该有,但还没寻找相关文献看实验效果,先留着。PPT中提到另一种solution,就是去估计模型中的Uncertainty,即Uncertainty-aware Dynamics Model.
2.3.2 Estimate Model Uncertainty
如何衡量Model Uncertainty?通常,我们通过最大似然法进行估计,利用数据Data去估计模型参数 θ \theta θ,通过贝叶斯公式,选择一组使似然函数最大的参数。
arg max θ p ( θ ∣ D ) = arg max θ p ( D ∣ θ ) \argmax_\theta p(\theta|D)=\argmax_\theta p(D|\theta) θargmaxp(θ∣D)=θargmaxp(D∣θ)
衡量Uncertainty的关键就在于,选择参数的分布,而不是一组使似然函数最大的参数,即 p ( θ ∣ D ) p(\theta|D) p(θ∣D),如下面贝叶斯网络BNN所示:
-
Bayesian Neural Network

估计目标是 p ( θ ∣ D ) p(\theta|D) p(θ∣D),是分布,预测的时候:
p ( s t + 1 ∣ s t , a t ) = ∫ p ( s t + 1 ∣ s t , a t , θ ) p ( θ ∣ D ) d θ p(s_{t+1}|s_t,a_t)=\int p(s_{t+1}|s_t,a_t,\theta)p(\theta|D)d\theta p(st+1∣st,at)=∫p(st+1∣st,at,θ)p(θ∣D)dθ对估计好的参数分布中的每个可能组合 θ \theta θ,对确定的dynamics model进行求和,这在计算上是intractable的,因此一般需要通过近似:
∫ p ( s t + 1 ∣ s t , a t , θ ) p ( θ ∣ D ) d θ ≈ 1 N ∑ i p ( s t + 1 ∣ s t , a t , θ i ) \int p(s_{t+1}|s_t,a_t,\theta)p(\theta|D)d\theta\approx \frac{1}{N}\sum_i p(s_{t+1}|s_t,a_t,\theta_i) ∫p(st+1∣st,at,θ)p(θ∣D)dθ≈N1i∑p(st+1∣st,at,θi)
这种做法缺点就是,需要多个网络近似,无论是复杂度还是空间开销都提升了几倍,因此一般 N ≤ 10 N \leq10 N≤10,称作Bootstrap Ensemble,如下。 -
Bootstrap Ensemble
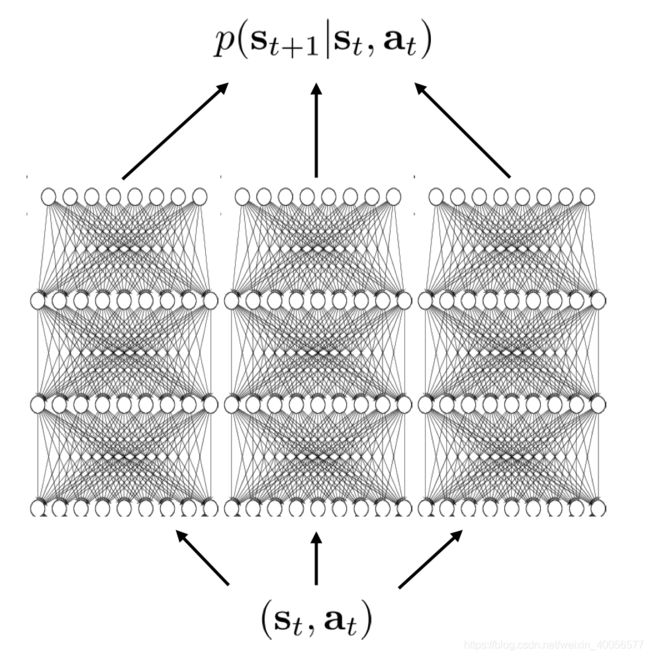
train多个不同的网络,一种方式是利用独立的数据子集分别train单独的网络,train的方式很多样。另一种也可是将多个网络做Knowledge Distillation到一个网络中,各种teacher,克服时空间复杂度增长的问题,这应该很好做,不知是否有paper尝试过用到deep RL里来看效果。
其实还可以有高斯过程GP与变分推断Variational Inference来衡量Uncertainy,其它方式可参见两篇Paper。
Weight Uncertainty in Neural Networks 2015 ICML
Concrete Dropout 2017 NIPS
还有一些关于Deep Dynamics Model的Paper:
- Deep Reinforcement Learning in a Handful of Trials using
Probabilistic Dynamics Models 2018 NIPS - Sample-Efficient Reinforcement Learning with Stochastic
Ensemble Value Expansion 2018 NIPS
2.4 Complex Observations
当接收的信息是image的时候,由于维度过高,不能像之前那样直接把simple observation当作state了。需要为observation建立一个映射mapping,将obervation转换到state空间。在MDP中state可以理解为是对环境的完全抽象,即假设了state包含所需要知道的完整信息,这个称作state abstraction。state estimation需要将高维度的observation转成低维度的state,相当于对observation做了一个projection 到state latent space。
回顾比较完整的MDP过程,定义:
- dynamics model p ( s t + 1 ∣ s t , a t ) p(s_{t+1}|s_t,a_t) p(st+1∣st,at):下一状态的分布
- observation model p ( o t ∣ s t ) p(o_t|s_t) p(ot∣st):状态 s t s_t st上出现观测值 o t o_t ot的概率(image reconstruction)
- reward model p ( r t ∣ s t , a t ) p(r_t|s_t,a_t) p(rt∣st,at):执行状态动作后,奖励服从的分布
以上model是确定值deterministic 或者 服从分布的随机值stochastic均可

我们看看这个latent space的过程具体是怎样的。
之前拟合dynamics model时,第 i i i个轨迹的一个transition样本为 ( s t i , a t i , s t + 1 i ) (s^i_t,a_t^i,s_{t+1}^i) (sti,ati,st+1i),输入是 s t i s_t^i sti,label是 s t + 1 i s_{t+1}^i st+1i,对数log似然目标是:
max ϕ 1 N ∑ i = 1 N ∑ t = 1 T l o g p ϕ ( s t + 1 i ∣ s t i , a t i ) \max_{\phi}\frac{1}{N}\sum_{i=1}^N\sum_{t=1}^Tlogp_\phi(s_{t+1}^i|s_t^i,a_t^i) ϕmaxN1i=1∑Nt=1∑Tlogpϕ(st+1i∣sti,ati)
但现在state是不知道的,需要从observation学习映射,但dymaics的input与label是 ( s t , s t + 1 ) (s_t,s_{t+1}) (st,st+1)。因此先从observation与action的所有历史信息中学习transition的联合分布 ( s t , s t + 1 ) (s_t,s_{t+1}) (st,st+1):
( s t , s t + 1 ) ∼ p ( s t , s t + 1 ∣ o 1 : T , a 1 : T ) (s_t,s_{t+1})\sim p(s_t,s_{t+1}|o_{1:T},a_{1:T}) (st,st+1)∼p(st,st+1∣o1:T,a1:T)
目标变为:
max ϕ 1 N ∑ i = 1 N ∑ t = 1 T E ( s t , s t + 1 ) ∼ p ( s t , s t + 1 ∣ o 1 : T , a 1 : T ) l o g p ϕ ( s t + 1 i ∣ s t i , a t i ) \max_{\phi}\frac{1}{N}\sum_{i=1}^N\sum_{t=1}^TE_{(s_t,s_{t+1})\sim p(s_t,s_{t+1}|o_{1:T},a_{1:T})}logp_\phi(s_{t+1}^i|s_t^i,a_t^i) ϕmaxN1i=1∑Nt=1∑TE(st,st+1)∼p(st,st+1∣o1:T,a1:T)logpϕ(st+1i∣sti,ati)
还有个小问题, p ( s t , s t + 1 ∣ o 1 : T , a 1 : T ) p(s_t,s_{t+1}|o_{1:T},a_{1:T}) p(st,st+1∣o1:T,a1:T)学得只是如何将observation映射成state dynamics,而环境dynamics依靠的是真实state之间的转移,如何保证observation学的state一定就好的呢?
因此还需要observation model,即 p ( o t ∣ s t ) p(o_t|s_t) p(ot∣st),MLE这个似然,使习得的state reconstruct出来的observation确实也和image observation很相似。因此现在目标变为:
max ϕ 1 N ∑ i = 1 N ∑ t = 1 T E ( s t , s t + 1 ) ∼ p ( s t , s t + 1 ∣ o 1 : T , a 1 : T ) [ l o g p ϕ ( s t + 1 i ∣ s t i , a t i ) + l o g p ϕ ( o t i ∣ s t i ) ] \max_{\phi}\frac{1}{N}\sum_{i=1}^N\sum_{t=1}^TE_{(s_t,s_{t+1})\sim p(s_t,s_{t+1}|o_{1:T},a_{1:T})}\Big[logp_\phi(s_{t+1}^i|s_t^i,a_t^i)+logp_\phi(o_t^i|s_t^i)\Big] ϕmaxN1i=1∑Nt=1∑TE(st,st+1)∼p(st,st+1∣o1:T,a1:T)[logpϕ(st+1i∣sti,ati)+logpϕ(oti∣sti)]
现在需要处理Encoder,这里假设最简单的情形,复杂的后续再说。
- 独立性假设 p ( s t , s t + 1 ∣ o 1 : T , a 1 : T ) = p ( s t ∣ o 1 : T , a 1 : T ) p ( s t + 1 ∣ o 1 : T , a 1 : T ) p(s_t,s_{t+1}|o_{1:T},a_{1:T})=p(s_t|o_{1:T},a_{1:T})p(s_{t+1}|o_{1:T},a_{1:T}) p(st,st+1∣o1:T,a1:T)=p(st∣o1:T,a1:T)p(st+1∣o1:T,a1:T)
- 学习一个 q ψ ( s t ∣ o 1 : T , a 1 : T ) q_\psi(s_t|o_{1:T},a_{1:T}) qψ(st∣o1:T,a1:T)来近似这个分布 p ( s t ∣ o 1 : T , a 1 : T ) p(s_t|o_{1:T},a_{1:T}) p(st∣o1:T,a1:T)
- 假设 s t s_t st只condition on o t o_t ot,即 q ψ ( s t ∣ o t ) q_\psi(s_t|o_t) qψ(st∣ot)
- q ψ ( s t ∣ o t ) q_\psi(s_t|o_t) qψ(st∣ot)是deterministic encoder,即等价于让 s t = g ψ ( o t ) s_t=g_\psi(o_t) st=gψ(ot)
于是优化目标变为:
max ϕ , ψ 1 N ∑ i = 1 N ∑ t = 1 T [ l o g p ϕ ( g ψ ( o t i ) ∣ g ψ ( o t i ) , a t i ) + l o g p ϕ ( o t i ∣ g ψ ( o t i ) ) ] \max_{\phi,\psi}\frac{1}{N}\sum_{i=1}^N\sum_{t=1}^T\Big[logp_\phi\Big(g_\psi(o_t^i)|g_\psi(o_t^i),a_t^i\Big)+logp_\phi(o_t^i|g_\psi(o_t^i))\Big] ϕ,ψmaxN1i=1∑Nt=1∑T[logpϕ(gψ(oti)∣gψ(oti),ati)+logpϕ(oti∣gψ(oti))]
如果算上reward model,最终优化目标为:
max ϕ , ψ 1 N ∑ i = 1 N ∑ t = 1 T [ l o g p ϕ ( g ψ ( o t i ) ∣ g ψ ( o t i ) , a t i ) + l o g p ϕ ( o t i ∣ g ψ ( o t i ) ) + l o g p ϕ ( r t i ∣ g ψ ( o t i ) , a t i ) ] \max_{\phi,\psi}\frac{1}{N}\sum_{i=1}^N\sum_{t=1}^T\Big[logp_\phi\Big(g_\psi(o_t^i)|g_\psi(o_t^i),a_t^i\Big)+logp_\phi(o_t^i|g_\psi(o_t^i))+logp_\phi(r_t^i|g_\psi(o_t^i),a_t^i)\Big] ϕ,ψmaxN1i=1∑Nt=1∑T[logpϕ(gψ(oti)∣gψ(oti),ati)+logpϕ(oti∣gψ(oti))+logpϕ(rti∣gψ(oti),ati)]
最终算法流程为:

可改进之处很多,都在encoder的假设情况中,这算法假设了一个deterministic and one observation的encoder,最丰富可扩展成dependent,stochastic,multiple observations的encoder。
其实引入了latent state的方案与VAE,Variational AutoEncoder差不多,VAE各种变种与优化技巧,均可借鉴)
放两篇参考论文:
E2C:Embed To Control 2015 NIPS(locally linear来近似处理non-linear dynamics,deep generative model 来生成latent space中的state vector)
SOLAR: Deep Structured Representations for Model-Based Reinforcement Learning ICML 2019(通过inferring simple dynamics and cost models来得到image的robust representation)
三、Model-Based Policy Learning
3.1 Model-Based RL With model
上面说完怎么train一个dynamics model,train好后就可以用Optimal Control中的trajectory optimization的方法进行planning了,根据dynamics model去得最优轨迹。这章主要说的是,尽管有dynamics model,但有一些痛点促使我们希望用这个第二章辛苦train好的model去辅助policy的学习。比如对于dynamics非常复杂的环境,即使历经千辛万苦train好这个接近完美的dynamics model,却因为环境comlicated and stochastic dynamics的原因,planning的算法并不能得出最优轨迹,陷入了sub-optimal。通过dynamics model来learn这个model的方式,主要有
- 通过Backprop Gradient从model到update policy
- 使用model来产生样本 ( s , a , s ′ , r ) (s,a,s',r) (s,a,s′,r),避免与真实环境交互获得 s ′ s' s′
- 将Non-linear Dynamics 用多个Locally linear Dynamics Model近似,Train出local Policy,再通过Supervised Learning将多个local policy combine成一个experssive的global policy a.k.a Guided Policy Search.
3.2 Backprop Gradient (Path-Wise Gradient)

(基本RL中每个module,都分deterministic与stochastic)
每个batch更新dynamics model的时候,从reward开始经过dynamics model将gradient backprop回policy中。于是目标梯度为:
∇ θ J ( θ ) = d r 1 d s 1 + d r 2 d s 2 d s 2 d a 1 d a 1 d s 1 + d r 3 d s 3 d s 3 d a 2 d a 2 d s 2 d s 2 d a 1 d a 1 d s 1 + ⋯ \nabla_\theta J(\theta)=\frac{dr_1}{ds_1}+\frac{dr_2}{ds_2}\frac{ds_{2}}{da_{1}}\frac{da_1}{ds_1}+\frac{dr_3}{ds_3}\frac{ds_{3}}{da_{2}}\frac{da_2}{ds_2}\frac{ds_{2}}{da_{1}}\frac{da_1}{ds_1}+\cdots\\ ∇θJ(θ)=ds1dr1+ds2dr2da1ds2ds1da1+ds3dr3da2ds3ds2da2da1ds2ds1da1+⋯
所以简化表述成:
∇ θ J ( θ ) = ∑ t = 1 T d r t d s t ∏ t ′ = 2 t d s t ′ d a t ′ − 1 d a t ′ − 1 d s t ′ − 1 \nabla_\theta J(\theta)=\sum_{t=1}^T\frac{dr_t}{ds_t}\prod_{t'=2}^t\frac{ds_{t'}}{da_{t'-1}}\frac{da_{t'-1}}{ds_{t'-1}} ∇θJ(θ)=t=1∑Tdstdrtt′=2∏tdat′−1dst′dst′−1dat′−1
其中 d s t ′ d a t ′ − 1 \frac{ds_{t'}}{da_{t'-1}} dat′−1dst′为dynamics model的gradient, d a t ′ − 1 d s t ′ − 1 \frac{da_{t'-1}}{ds_{t'-1}} dst′−1dat′−1为policy gradient。可以看到这结构的策略梯度更新类似于long horizon的RNN或LSTM,经过多个Jacobi矩阵相乘,很容易出现vanishing gradient或exploding gradient的现象,具体而言就是连续相乘的多个Jacobi矩阵的特征值大于1或小于1,过多的时候,梯度要么就太大爆炸explode了,要么就是太小消失vanish了。
解决办法就是要维持这些Jacobi矩阵相乘时的特征值在1附近徘徊。只是有点麻烦而已,但也不是不行,有人也在做这个工作,具体可以参见下面两篇paper。
- PILCO ICML 2011
- PIPPS ICML 2018
在reparameterization gradient的基础上,PIPPS中设计了一种total propagation algorithm,利用一个single backwards pass来等同于到一个union如 s t + 1 = f ( s t , a t ) 的 s_{t+1}=f(s_t,a_t)的 st+1=f(st,at)的所有pathwise derivative。
3.3 Model-free RL With a Model
3.3.1 Dyna Algorithm

特点:Online Q-learning algorithm that performs model-free RL with a model
重点说明:
- Q-update 在lec5-lec9中为 r + m a x a ′ Q ( s ′ , a ′ ) − Q ( s , a ) r+max_{a'}Q(s',a')-Q(s,a) r+maxa′Q(s′,a′)−Q(s,a),此处由于有了拟合的model,可以去掉Q值over-estimation的问题,可以算期望了!
- 第6步的sample,相当于off-policy从buffer中随机取样,使Q值可以看到diverse state而不是一条轨迹上的highly correlated的state
- 第5步的repeat,类似于fitted Q-iteration,是对现有dynamics model p ^ ( s ′ ∣ s , a ) \hat p(s'|s,a) p^(s′∣s,a)与reward model r ^ ( s , a ) \hat r(s,a) r^(s,a)的稳定性拟合,用于提高算法的稳定性
3.3.2 Gernal Dyna-style Algorithm
基于上述Dyna算法,下面是Dyna-style算法扩展的抽象形态:

说明:第4步中把Dyana中的 ( s , a ) (s,a) (s,a)拆开了,从而引入了选择action的多样性,第7步将online Q扩展了,使其可用多种model-free RL算法。
服从该Dyna-Style的paper有:
- Continuous Deep Q-Learning with Model-based Acceleration 2016 jmlr
- Sample-Efficient Reinforcement Learning with Stochastic Ensemble Value Expansion 2018 NIPS(提出STEVE,主要是减缓imperfect dynamics model使性能下降的问题)
- When to Trust Your Model: Model-Based Policy Optimization 2019 NIPS
3.4 Simpler polices than NN
基本想法Divide and Conquer:将一个global policy如expressive的DNN分解成多个local policy,对local policy进行学习,再combine成一个global policy。
不用受long RNN梯度消失爆炸困扰的Backprop gradient,也不用受训练中imperfect dynamics model影响很大的General-Dyna算法,尝试通过LQR framework来实现Divide and Conquer。
3.4.1 Local Policy
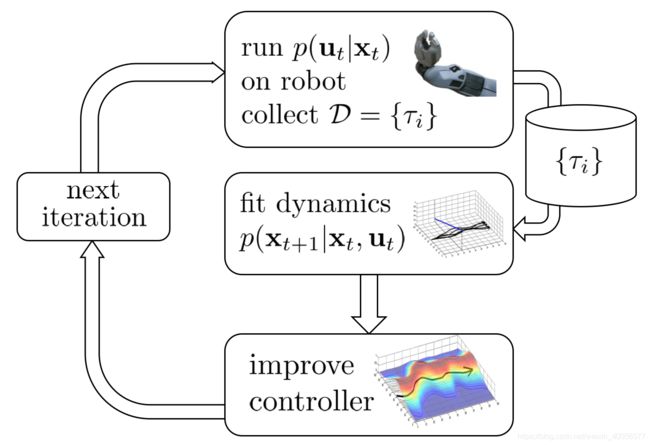
回顾LQR framework
- 假设是stochastic的dynamics,先拟合local的dynamics model,则有:
p ( x t + 1 ∣ x t , u t ) = N ( f ( x t , u t ) , Σ ) f ( x t , u t ) ≈ d f d x t x t + d f d u t u t = A t x t + B t u t p ( x t + 1 ∣ x t , u t ) = N ( A t x t + B t u t , Σ ) p(x_{t+1}|x_t,u_t)=N(f(x_t,u_t),\Sigma)\\ f(x_t,u_t) \approx \frac{df}{dx_t}x_t+\frac{df}{du_t}u_t=A_tx_t+B_tu_t\\ p(x_{t+1}|x_t,u_t)=N(A_tx_t+B_tu_t,\Sigma) p(xt+1∣xt,ut)=N(f(xt,ut),Σ)f(xt,ut)≈dxtdfxt+dutdfut=Atxt+Btutp(xt+1∣xt,ut)=N(Atxt+Btut,Σ)
train local dynamics model的样本为 { ( x t , u t , x t + 1 ) i } \{(x_t,u_t,x_{t+1})_i\} {(xt,ut,xt+1)i},可以采用Linear Regression,也可以升级版Bayesian Linear Regression+自己喜欢的先验分布prior(DNN,GP,GMM) - iLQR输入一条初始化轨迹 x ^ t \hat x_t x^t, u ^ t \hat u_t u^t,Backward Pass时就知道了控制律 u t = K t ( x t − x ^ t ) + k t + u ^ t u_t=K_t(x_t-\hat x_t)+k_t+\hat u_t ut=Kt(xt−x^t)+kt+u^t,这就是图中的conroller p ( u t ∣ x t ) p(u_t|x_t) p(ut∣xt),可选择如下:
- p ( u t ∣ x t ) = δ ( u t = u ^ t ) p(u_t|x_t)=\delta(u_t=\hat u_t) p(ut∣xt)=δ(ut=u^t)
- p ( u t ∣ x t ) = δ ( u t = K t ( x t − x ^ t ) + k t + u ^ t ) p(u_t|x_t)=\delta(u_t=K_t(x_t-\hat x_t)+k_t+\hat u_t) p(ut∣xt)=δ(ut=Kt(xt−x^t)+kt+u^t)
- p ( u t ∣ x t ) = N ( K t ( x t − x ^ t ) + k t + u ^ t , Σ t ) , Σ t = Q u t , u t − 1 p(u_t|x_t)=N(K_t(x_t-\hat x_t)+k_t+\hat u_t,\Sigma_t),\Sigma_t=Q_{u_t,u_t}^{-1} p(ut∣xt)=N(Kt(xt−x^t)+kt+u^t,Σt),Σt=Qut,ut−1
以上便可训练得到一个local controller 的 p ( u t ∣ x t ) p(u_t|x_t) p(ut∣xt)即local policy的 π ( a t ∣ s t ) \pi(a_t|s_t) π(at∣st)。
那会不会有问题呢?肯定有的,在于将Non-linear stochastic dynamics强行用linear dynamics approximate的那一部分 f ( x t , u t ) ≈ d f d x t x t + d f d u t u t f(x_t,u_t) \approx \frac{df}{dx_t}x_t+\frac{df}{du_t}u_t f(xt,ut)≈dxtdfxt+dutdfut=。=
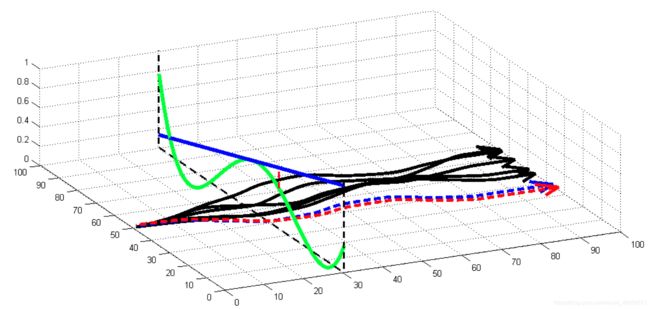
解释一下这个图:有箭头的线为一条trajectory,绿色波形的线为真实Non-linear dynamics的 f ( x t , u t ) f(x_t,u_t) f(xt,ut),蓝色的线为local linear approximate的controller控制器 d f d x t x t + d f d u t u t \frac{df}{dx_t}x_t+\frac{df}{du_t}u_t dxtdfxt+dutdfut。
黑色轨迹 τ ^ \hat\tau τ^在approximately local linear dynamics基础上训练出来的控制器controller蓝色线,如果遇到与黑色轨迹 τ ^ \hat\tau τ^相差较远的轨迹 τ \tau τ,则controller就会失效,导致性能local policy不准。
那怎么办呢?
像TRPO一样,只要让新轨迹 τ \tau τ与旧轨迹 τ ˉ \bar\tau τˉ之间在一定范围内接近即可。公式描述如下:
p ( τ ) = p ( x 1 ) ∏ t = 1 T p ( u t ∣ x t ) p ( x t + 1 ∣ x t , u t ) p ( u t ∣ x t ) = N ( K t ( x t − x ^ t ) + k t + u ^ t , Σ t ) p(\tau)=p(x_1)\prod_{t=1}^Tp(u_t|x_t)p(x_{t+1}|x_t,u_t)\\ p(u_t|x_t)=N(K_t(x_t-\hat x_t)+k_t+\hat u_t,\Sigma_t) p(τ)=p(x1)t=1∏Tp(ut∣xt)p(xt+1∣xt,ut)p(ut∣xt)=N(Kt(xt−x^t)+kt+u^t,Σt)
优化问题变为:
min p ( τ ) ∑ t = 1 T E p ( x t , u t ) [ c ( x t , u t ) ] s . t D K L ( p ( τ ) ∣ ∣ p ˉ ( τ ) ) ≤ ϵ \min_{p(\tau)}\sum_{t=1}^TE_{p(x_t,u_t)}\Big[c(x_t,u_t)\Big]\\s.t \quad D_{KL}(p(\tau)||\bar p(\tau))\leq\epsilon p(τ)mint=1∑TEp(xt,ut)[c(xt,ut)]s.tDKL(p(τ)∣∣pˉ(τ))≤ϵ
Learning Neural Network Policies with Guided Policy Search under Unknown Dynamics 2014 NIPS
细节在这篇文章里, p ( τ ) 、 p ˉ ( τ ) p(\tau)、\bar p(\tau) p(τ)、pˉ(τ)为新控制器的轨迹分布与旧控制器的轨迹分布,下面公式表述一下:
p ( τ ) = p ( x 1 ) ∏ t = 1 T p ( u t ∣ x t ) p ( x t + 1 ∣ x t , u t ) p ˉ ( τ ) = p ( x 1 ) ∏ t = 1 T p ˉ ( u t ∣ x t ) p ( x t + 1 ∣ x t , u t ) p(\tau)=p(x_1)\prod_{t=1}^Tp(u_t|x_t)p(x_{t+1}|x_t,u_t)\\ \bar p(\tau)=p(x_1)\prod_{t=1}^T\bar p(u_t|x_t)p(x_{t+1}|x_t,u_t) p(τ)=p(x1)t=1∏Tp(ut∣xt)p(xt+1∣xt,ut)pˉ(τ)=p(x1)t=1∏Tpˉ(ut∣xt)p(xt+1∣xt,ut)
D K L ( p ( τ ) ∣ ∣ p ˉ ( τ ) ) = E p ( τ ) [ l o g p ( τ ) p ˉ ( τ ) ] = E p ( τ ) [ l o g p ( τ ) − l o g p ˉ ( τ ) ] = E ( x t , u t ) ∼ p ( τ ) [ ∑ t = 1 T ( l o g p ( u t ∣ x t ) − l o g p ˉ ( u t ∣ x t ) ) ] = ∑ t = 1 T [ E p ( x t , u t ) l o g p ( u t ∣ x t ) + E p ( x t , u t ) [ − l o g p ˉ ( u t ∣ x t ) ] ] = ∑ t = 1 T [ E p ( x t ) E p ( u t ∣ x t ) l o g p ( u t ∣ x t ) + E p ( x t , u t ) [ − l o g p ˉ ( u t ∣ x t ) ] ] = ∑ t = 1 T [ − E p ( x t ) [ H ( p ( u t ∣ x t ) ) ] + E p ( x t , u t ) [ − l o g p ˉ ( u t ∣ x t ) ] ] = ∑ t = 1 T E p ( x t ) [ H [ p , p ˉ ] − H [ p ] ] = ∑ t = 1 T E p ( x t , u t ) [ − l o g p ˉ ( u t ∣ x t ) − H [ p ( u t ∣ x t ) ] ] \begin{aligned} D_{KL}(p(\tau)||\bar p(\tau))&=E_{p(\tau)}\Big[log\frac{p(\tau)}{\bar p(\tau)}\Big]\\ &=E_{p(\tau)}\Big[logp(\tau)-log\bar p(\tau)\Big]\\ &=E_{(x_t,u_t)\sim p(\tau)}\Big[\sum_{t=1}^T\Big(logp(u_t|x_t)-log\bar p(u_t|x_t)\Big)\Big]\\ &=\sum_{t=1}^T\Big[E_{p(x_t,u_t)}logp(u_t|x_t)+E_{p(x_t,u_t)}\big[-log\bar p(u_t|x_t)\big]\Big]\\ &=\sum_{t=1}^T\Big[E_{p(x_t)}E_{p(u_t|x_t)}logp(u_t|x_t)+E_{p(x_t,u_t)}\big[-log\bar p(u_t|x_t)\big]\Big]\\ &=\sum_{t=1}^T\Big[-E_{p(x_t)}\big[H\big(p(u_t|x_t)\big)\big]+E_{p(x_t,u_t)}\big[-log\bar p(u_t|x_t)\big]\Big]\\ &=\sum_{t=1}^TE_{p(x_t)}\Big[H[p,\bar p]-H[p]\Big]\\ &=\sum_{t=1}^TE_{p(x_t,u_t)}\big[-log\bar p(u_t|x_t)-H[p(u_t|x_t)]\big] \end{aligned} DKL(p(τ)∣∣pˉ(τ))=Ep(τ)[logpˉ(τ)p(τ)]=Ep(τ)[logp(τ)−logpˉ(τ)]=E(xt,ut)∼p(τ)[t=1∑T(logp(ut∣xt)−logpˉ(ut∣xt))]=t=1∑T[Ep(xt,ut)logp(ut∣xt)+Ep(xt,ut)[−logpˉ(ut∣xt)]]=t=1∑T[Ep(xt)Ep(ut∣xt)logp(ut∣xt)+Ep(xt,ut)[−logpˉ(ut∣xt)]]=t=1∑T[−Ep(xt)[H(p(ut∣xt))]+Ep(xt,ut)[−logpˉ(ut∣xt)]]=t=1∑TEp(xt)[H[p,pˉ]−H[p]]=t=1∑TEp(xt,ut)[−logpˉ(ut∣xt)−H[p(ut∣xt)]]
min p ∑ t = 1 T E p ( x t , u t ) [ c ( x t , u t ) − λ l o g p ˉ ( u t ∣ x t ) − λ H ( p ( u t ∣ x t ) ) ] − λ ϵ \min_p\sum_{t=1}^TE_{p(x_t,u_t)}\Big[c(x_t,u_t)-\lambda log\bar p(u_t|x_t)-\lambda H(p(u_t|x_t))\Big]-\lambda\epsilon pmint=1∑TEp(xt,ut)[c(xt,ut)−λlogpˉ(ut∣xt)−λH(p(ut∣xt))]−λϵ
最后一步是因为可以固定新旧控制器的初始状态 p ( x t ) p(x_t) p(xt),然后用拉格朗日乘子法,转为无约束的优化问题,利用Dual Gradietn Descent进行优化。
3.4.2 Combined Policy With Guided Policy Search
将上述多个local policy通过supervised learning combine 到一个Network表示的global policy中。

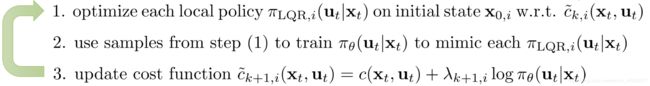
细节可参考:End-to-End Training of Deep Visuomotor Policies 2016 jmlr
参考资料
Medium:Jonathan-Hui Model-Based RL
CS285 lec10-lec12 PPT
中原一点红的知乎
补充
- 最后的Guided Policy Search算法细节在那篇paper中,还没来得及看,看完梳理逻辑后再填充。
- RL中间涉及到的高斯过程、Dual Gradient Descent等随机过程、最优化内容,找时间写一篇基础补上
- 关于所引论文阅读后,在后面相应填补一些精炼的内容。
- 不定期回来再修改一下表述、逻辑。