【课程笔记】CS224N斯坦福自然语言处理
【更新中】CS224N斯坦福自然语言处理
- Lecture one
-
- Plan of lecture one
- Distributed representation of word vector
- Lecture Two
-
- More detail of word-embedding
-
- Tricks
- Glove
-
-
- Symbol Definition
-
- Lecture Three
-
- Binary word window classification
- Lecture Four
- 附录
-
- 常见单词统计
- 相关资源
Course Homepage: http://web.stanford.edu/class/cs224n/
Lecture one
2021.2.25
Plan of lecture one

Distributed representation of word vector
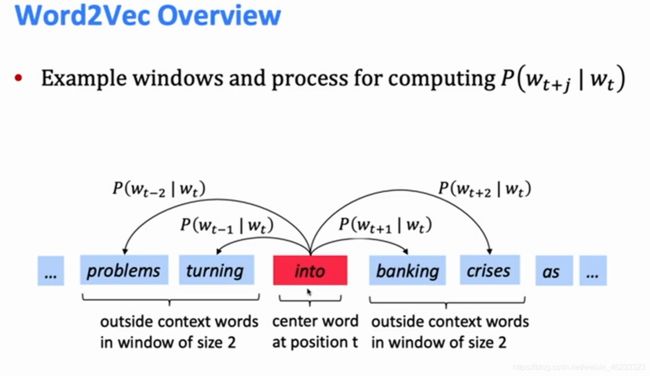
A word’s meaning is given by the words that frequentlt appear closed-by.
“You should know a word by the company it keeps.”——J. R. Firth
Loss function:

Finally:

Before is trainning method, then this is prediction method:

Use vectors’ dot multiply to calculate the simularity.
Now we need to calculate partial:

numerator is easy, look into denominator:
Use the chain rule:

Then move the derivative inside the sum:

Use the chain rule again:
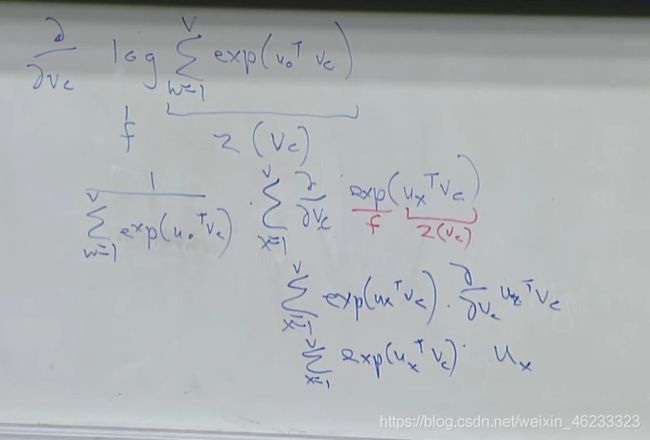
Finally:

Write it into a simple form:

It means it takes the “difference” between the expected context word and the actual context word that showed up.
This difference give us the slope as to whcih direction we should be walking changing the words.
Exercise one
Solution of Exercise one
Lecture Two

More detail of word-embedding
Tricks
- SGD is faster, and can bring in some noise, which is equal to normalize the function.
- Objective function is nonconvex, so it is very important to choose a good starting point.
- ∇ θ J t ( θ ) \nabla_{\theta} J_{t}(\theta) ∇θJt(θ) is very sparse! (Because only words in the window can be updated) So sometimes we use hashes or only update concerned rows in the matrix. Or we use Negative sampling transfer trhe probelm into binary classification.

The idea of SG and CBOW is:


Negative Sampling: Train binary logistic regressions for a true pair(center word and word in its context window) versus a couple of noise pairs(the center word paired with a random word)

Here, The capital Z is often used as a normalization term:
So this is saying if you want the probability distribution of words, is you work out this three quaters power of the count of the word for every word in the vocabulary and then these numbers you just sum them up over the vocabulary and it’ll be sum total andf we’re dividing by that. So we get a probability distribution.
(Notes: In this class, Z means teacher normalization term to turn things into probabliyies)
Glove
Symbol Definition
Reference
X i j : X_{ij}: Xij: For center word i i i, times of word j j j appearance.
X i : X_i: Xi: Times of word i i i appearance in full context.
P i , k = X i , k X i : P_{i,k}=\frac{X_{i,k}}{X_{i}}: Pi,k=XiXi,k:Frequency of word k k k appear in context of word i i i
ratio i , j , k = P i , k P j , k : \text { ratio }_{i, j, k}=\frac{P_{i, k}}{P_{j, k}}: ratio i,j,k=Pj,kPi,k: For different center word, the frequency of k k k appearance’s ratio.
Now we want to get function g:
P i , k P j , k = ratio i , j , k = g ( w i , w j , w k ) \frac{P_{i, k}}{P_{j, k}}=\text { ratio }_{i, j, k}=g\left(w_{i}, w_{j}, w_{k}\right) Pj,kPi,k= ratio i,j,k=g(wi,wj,wk)
The following is very curtness.
- Suppose g have ( w i − w j w_{i}-w_{j} wi−wj) because this function will finally get the difference between i i i and j j j
- g is a scalar so g maybe have ( ( w i − w j ) T w k \left(w_{i}-w_{j}\right)^{T} w_{k} (wi−wj)Twk)
- Let g just be the exp function: g ( w i , w j , w k ) = exp ( ( w i − w j ) T w k ) g\left(w_{i}, w_{j}, w_{k}\right)=\exp \left(\left(w_{i}-w_{j}\right)^{T} w_{k}\right) g(wi,wj,wk)=exp((wi−wj)Twk)
Finally:
P i , k P j , k = exp ( ( w i − w j ) T w k ) P i , k P j , k = exp ( w i T w k − w j T w k ) P i , k P j , k = exp ( w i T w k ) exp ( w j T w k ) \begin{aligned} \frac{P_{i, k}}{P_{j, k}} &=\exp \left(\left(w_{i}-w_{j}\right)^{T} w_{k}\right) \\ \frac{P_{i, k}}{P_{j, k}} &=\exp \left(w_{i}^{T} w_{k}-w_{j}^{T} w_{k}\right) \\ \frac{P_{i, k}}{P_{j, k}} &=\frac{\exp \left(w_{i}^{T} w_{k}\right)}{\exp \left(w_{j}^{T} w_{k}\right)} \end{aligned} Pj,kPi,kPj,kPi,kPj,kPi,k=exp((wi−wj)Twk)=exp(wiTwk−wjTwk)=exp(wjTwk)exp(wiTwk)
P i , j = exp ( w i T w j ) log ( X i , j ) − log ( X i ) = w i T w j log ( X i , j ) = w i T w j + b i + b j \begin{array}{c} P_{i, j}=\exp \left(w_{i}^{T} w_{j}\right) \\ \log \left(X_{i, j}\right)-\log \left(X_{i}\right)=w_{i}^{T} w_{j} \\ \log \left(X_{i, j}\right)=w_{i}^{T} w_{j}+b_{i}+b_{j} \end{array} Pi,j=exp(wiTwj)log(Xi,j)−log(Xi)=wiTwjlog(Xi,j)=wiTwj+bi+bj
The loss function is:
J = ∑ i , j N ( w i T w j + b i + b j − log ( X i , j ) ) 2 J=\sum_{i, j}^{N}\left(w_{i}^{T} w_{j}+b_{i}+b_{j}-\log \left(X_{i, j}\right)\right)^{2} J=i,j∑N(wiTwj+bi+bj−log(Xi,j))2
Add the weight item:
J = ∑ i , j N f ( X i , j ) ( v i T v j + b i + b j − log ( X i , j ) ) 2 f ( x ) = { ( x / x m a x ) 0.75 , if x < x max 1 , if x > = x max \begin{array}{c} J=\sum_{i, j}^{N} f\left(X_{i, j}\right)\left(v_{i}^{T} v_{j}+b_{i}+b_{j}-\log \left(X_{i, j}\right)\right)^{2} \\ f(x)=\left\{\begin{array}{ll} \left(x / x_{m a x}\right)^{0.75}, & \text { if } x
Here f ( x ) f(x) f(x) means the more frequnetly x x x appears, the higher weight it will have.
Lecture Three

Little new knowledge in this lecture.
Binary word window classification

Use the window of word to classifiy the center word:


With this bigger vector, we get:

Lecture Four

“In 2019, deeplearrning is still a kind of craft.”
I write the mtrix derivation skills here
附录
常见单词统计
zilch n. 零无价值的物品; 人名
Notation n. 符号;乐谱;计数法
Orthogonality n. 正交性
Determinant n. 决定因素;行列式 adj. 决定性的
相关资源
非常基础的SVD推导
矩阵求导术