紧凑的深度特征表示
紧凑的深度表示:在计算机视觉中,来自深度神经网络的视觉嵌入得到了广泛的应用。为了实现紧凑表示和判别表示,现有的方法可以分为两类。第一个分类是在训练前设计小嵌入层的深度模型,其他分类则是在训练的深度学习模型上添加一系列降维/二值化层(如哈希和PCA)。对于第一类,[1]的工作探讨了在深度人脸识别模型中改变嵌入层大小的影响,通过裁剪CNN架构,可以通过更小的嵌入尺寸获得更好的图像检索性能。对于第二类,[2]的作者对预训练的CNN的顶层表示应用PCA压缩,以在许多图像检索数据集上实现最先进的精度。
1. Small-size embedding[1]
尽管最近在人脸识别领域取得了重大进展,但大规模有效地实现人脸验证和识别对当前的方法提出了严重的挑战。在本文中,我们提出了一个被称为FaceNet的系统,它直接学习从人脸图像到一个紧凑的欧几里得空间的映射,其中距离直接对应于人脸相似度的度量。一旦产生了这个空间,就可以很容易地使用标准技术实现任务,如人脸识别、验证和聚类,使用FaceNet嵌入作为特征向量。我们的方法使用一个经过训练的深度卷积网络来直接优化嵌入本身,而不是像以前的深度学习方法那样使用中间瓶颈层。
1.1 模型
FaceNet使用了一个深度卷积网络。我们讨论了两种不同的核心架构:Zeiler&Fergus风格的网络和最近的Inception类型的网络。这些网络使用混合层,并行运行几个不同的卷积层和池化层,并连接它们的响应。我们发现,这些模型可以将参数的数量减少多达20倍,并有可能减少类似性能所需的失败次数。
给定模型细节,并将其视为黑盒(见图2),我们方法最重要的部分是整个系统的端到端学习。为此,我们采用了三联体损失,它直接反映了我们想要在人脸验证、识别和聚类中实现的目标。

1.2 Triplet Loss
嵌入的方法用 f ( x ) ∈ R d f(x)\in R^d f(x)∈Rd表示。它将一个图像x嵌入到一个d维的欧几里得空间中。此外,我们将这种嵌入约束为在d维超球面上,即 ∣ ∣ f ( x ) ∣ ∣ 2 = 1 ||f(x)||_2=1 ∣∣f(x)∣∣2=1。
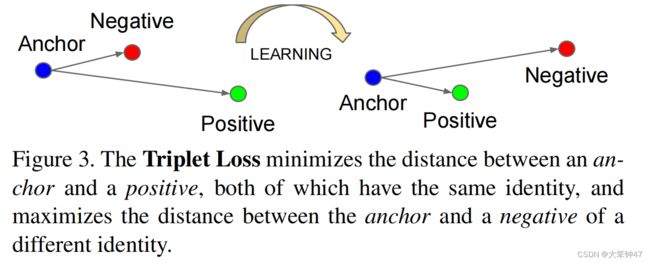
在这里,我们希望确保一个特定人的图像 x i a x_i^a xia(anchor)更接近同一个人的所有其他图像 x i p x_i^p xip(positive),而不是任何其他人的任何图像 x i n x_i^n xin(negative)。这一点如图3所示。
所以,我们的约束是:
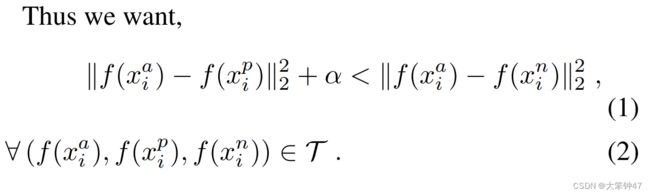
Loss函数为:
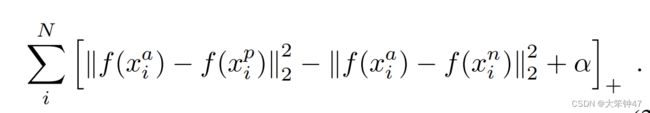
该文探究内容:
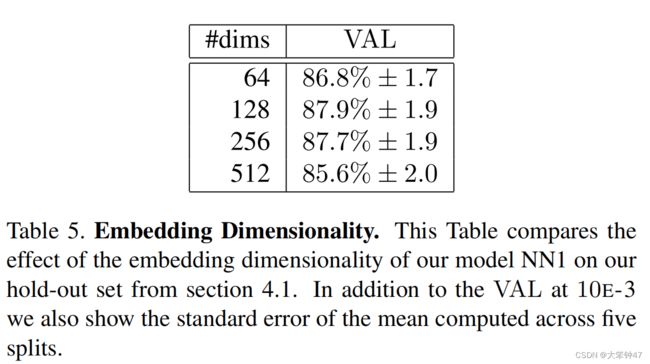
1.3.1 Embedding Dimensionality
我们探索了不同的嵌入维度,并选择了128维作为最后的压缩维度。
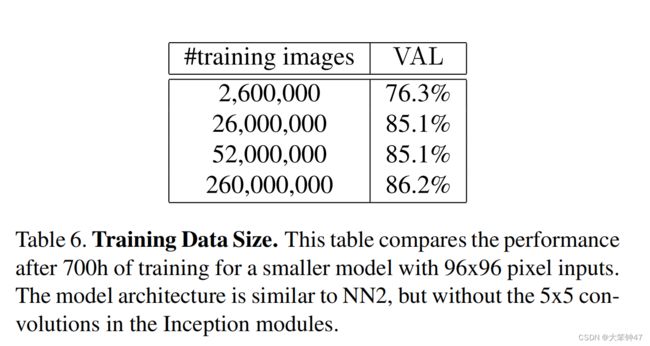
1.3.2 Amount of training data
表6显示了大量训练数据的影响
1.4 结论
该文提供了一种直接学习嵌入欧几里得空间的人脸验证。这使得它有别于其他使用CNN瓶颈层,或者需要额外的后处理,如连接多模型和PCA,以及SVM分类
2. dimension-reduction/binarization layers[2]
- 神经网络最后一层往往携带高层次的信息。在本文中,我们研究了这些描述符(神经代码 Neural code)在图像检索应用中的使用。
- 我们进一步评估了经过压缩的神经编码的性能,并表明一个简单的PCA压缩提供了非常好的压缩效果,在许多数据集上提供了较先进的准确性。
- 结果表明,在匹配照片对的数据集上训练的映射矩阵进一步提高了pca压缩神经代码的性能。
2.1 使用预训练好的神经编码
有趣的是,CNN的不同层在图片检索中的相对性能是不同的,并且在标准检索数据集上的最佳性能是通过全连接层层次结构中间的特征来实现的。如下图,每个高维向量( L 5 , L 6 , L 7 L^5,L^6,L^7 L5,L6,L7)都代表了输入图像的一个深度描述符(一个神经编码)。
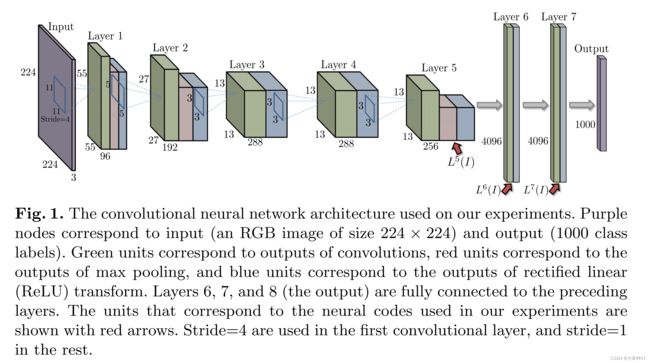
神经编码的良好性能证明了它们的普遍性,因为我们训练网络的任务(即图像网络类分类)与我们所考虑的检索任务有很大的不同。
表1的中间部分给出了用经过ILSVRC类训练的网络产生的神经编码的结果。所有的结果都是在l2归一化的神经编码上使用l2-距离获得的。我们给出了每一个第5、6、7层对应的结果。我们还尝试了第8层的输出(对应于ILSVRC类概率,因此与之前使用类概率作为描述符的工作密切相关),但是它的表现要差得多.
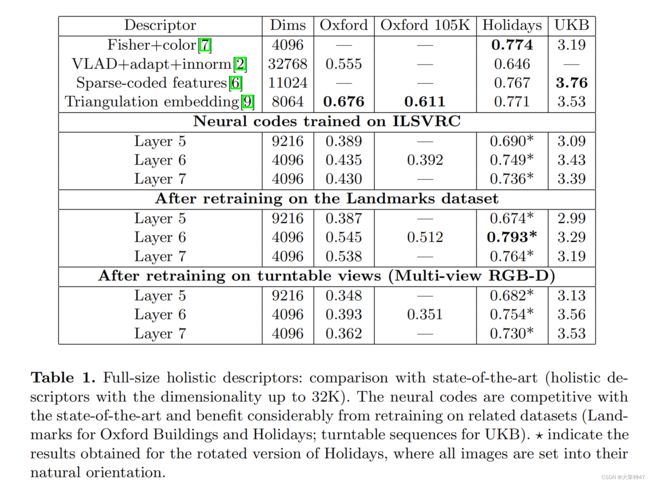
在所有的层中,第6层表现最好,但是它并不是对于所有的查询图片结果都是好的(见图2和图3)。尽管如此,使用简单的代码组合(如和或连接)获得的结果比单独使用L6代码更差,而且我们实验过的更复杂的非线性组合规则只给出了微小的改进。
总的来说,使用L6代码获得的结果是较好的,但并不优于最先进的结果。然而,考虑到ILSVRC分类任务和这里所考虑的检索任务之间的差异,它们的强大表现是显著的。
2.2 重新训练的神经代码
提高神经代码性能的一个简单的想法是在数据集上用与测试时考虑的数据集更相关的图像统计数据和类来重新训练卷积体系结构。
然后,我们使用收集到的数据集,使用与ILSVRC相同的架构来训练CNN(除了我们将输出节点数更改为672个)。我们用原始的ILSVRC CNN初始化了我们的模型(同样除了最后一层)。除此之外,训练过程与原始网络相同。
结果:
表1给出了在地标类数据集上重新训练的网络产生的神经编码的效果。正如预期的那样,相对于原始神经编码的性能差异与地标照片和特定检索数据集之间的相似性有关。

在其他序列上的重训练。在对地标集合进行重训练后,UKB数据集上的性能会下降。这反映了UKB数据集中的类,它们对应于不同小对象的多个室内视图,更类似于ILSVRC中的某些类而不是地标性的图片。为了证实这一点,我们进行了第二次再训练实验,其中我们使用了多视图RGB-D数据集,其中包含300个家庭对象的不同视图。我们在这个包含60,000张图像的数据集上重新训练网络(同样,由ILSVRC CNN初始化)。我们再次观察到(表1),随着UKB的准确性,再训练提高了相关数据集的检索性能,从3.43提高到3.56。在不相关的数据集(Oxford,Oxford-105k)上的性能下降。
2. 3 压缩的神经编码
由神经代码引起的PCA压缩的退化比由其他整体描述符引起的退化要小得多。这使得神经编码的使用对于大规模检索应用程序特别有吸引力,其中描述符的内存占用通常是主要的瓶颈。
由于我们实验中的神经代码是高维的(例如L6的4096维),尽管不如其他先进的整体描述符高维,它们如何进行有效压缩的问题就出现了。在本节中,我们将评估针对这种压缩的两种不同策略。首先,我们研究了常见的基于pca的压缩如何降低神经编码的效率。一个重要的发现是,这种退化是相当好的。其次,我们评估了一个更复杂的基于映射矩阵降维的程序。我们的评估集中在L6层上,因为神经编码在第六层的性能始终优于其他层。
2.3.1 PCA compression
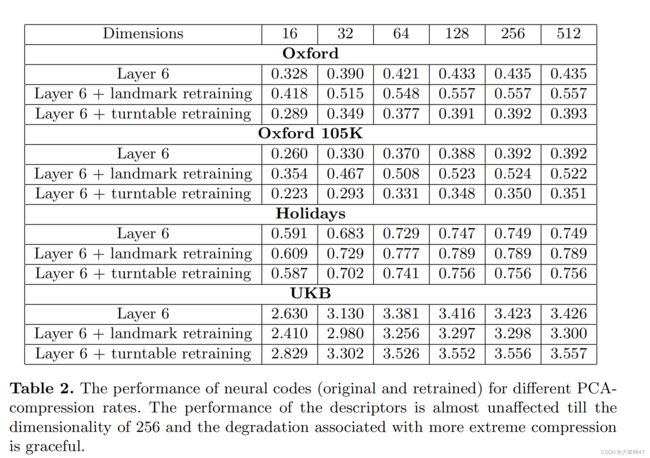
我们首先评估不同版本的神经编码在PCA压缩后到不同的维度的性能(表2)。在这里,对10万张Landmark数据集图像进行了PCA处理。
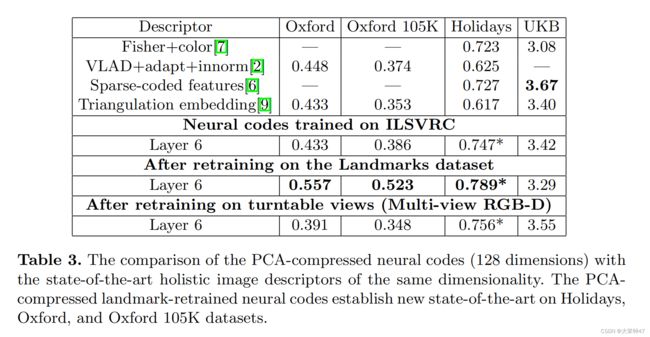
不同PCA压缩率下的神经编码L6的质量如表2所示。总的来说,PCA的工作得出奇地好。因此,神经编码可以被压缩到256维,甚至是128维,几乎没有任何质量损失。再训练代码的优势在所有压缩率中仍然存在。表3进一步比较了压缩到128个维度的不同的整体描述符,因为在之前的几个作品中已经选择了这个维度来进行比较。对于Oxford和Holiday数据集,在Landmark数据集训练的神经编码提供了一个新的最先进的低维全局描述符。
2.3.2 Discriminative dimensionality reduction
在本节中,我们进一步执行映射矩阵降维通过学习低秩投影矩阵w。学习的目标是在图片含有相同物体时减少他们的神经编码距离,反之,则加大距离,从而排除造成不准确性的其他因素,如视角的变化。
给定一个匹配对数据集,我们通过学习线性投影矩阵W。在大压缩率(D=16,32)的实验中,我们投影了原始的4096维代码。对于维数D=64,128,我们观察到由于W内存在大量参数而存在显著的过拟合。在这种情况下,我们首先进行pca压缩得到1024维编码,然后针对初步压缩的1024维编码来学习映射矩阵W。
我们表4比较了针对Oxford数据集的非再训练代码的两种压缩策略(PCA和特征降维)的结果。可以看出,对于极端压缩的16维编码,通过映射的方式降维可以获得最大的收益。我们还评估了在地标数据集上重新训练的神经代码的降维能力。然而,在这种情况下,我们没有观察到任何额外的改善,可能原因是由于网络再训练和映射降维采用重叠的训练数据进行。

2.4 结论
首先,正如预期的那样,神经编码即使使用训练过的分类任务CNN,比如训练数据集和检索数据集相差很大,但是效果表现得也很好。不出所料,当CNN在与检索数据集更相关的照片上进行再训练时,这种性能可以进一步提高。有趣的是,也许出乎意料的是,最好的性能不是在网络的顶部,而是在低于输出两个级别的层。即使在CNN对相关图像进行了重新训练后,这种效果仍然存在。我们推测,这是因为非常顶层的层对分类任务进行了太多的调整,而底层对有害因素没有获得足够的不变性。
我们还研究了压缩神经代码的性能,其中普通PCA或PCA与映射矩阵降维的组合会导致非常短的编码,具有非常好的(最先进的)性能。一个重要的结果是,PCA对神经编码性能的影响远远小于vlad、Fisher向量或三角测量嵌入。一种可能的解释是,通过网络传递图像会丢弃许多与分类(和检索)无关的信息。因此,与基于无监督聚合的表示相比,来自更深层次的基于cnn的神经代码保留了更少的(无用的)信息。因此,PCA压缩更适用于神经编码压缩。
参考
[1]F. Schroff, D. Kalenichenko, and J. Philbin, “Facenet: A unified embedding for face recognition and clustering,” in Proceedings of the IEEE
Conference on Computer Vision and Pattern Recognition, 2015, pp. 815–
823.
[2]A. Babenko, A. Slesarev, A. Chigorin, and V. Lempitsky, “Neural
codes for image retrieval,” in European conference on computer vision.
Springer, 2014, pp. 584–599.