pytorch_lesson16.1 OpenCV索贝尔算子/拉普拉斯算子调用+pytorch中构建cnn+复现经典模型(LeNet5+AlexNet)
提示:仅仅是学习记录笔记,搬运了学习课程的ppt内容,本意不是抄袭!望大家不要误解!纯属学习记录笔记!!!!!!
文章目录
- 一、计算机视觉 ≠ 卷积神经网络
- 二、从卷积到卷积神经网络
-
- 1 图像的基本表示
- 2 OpenCV令像素变化来改变图像
- 3 卷积操作
- 4 卷积遇见深度学习
-
- 4.1 通过学习寻找卷积核
- 4.2 权重共享,参数骤减
- 4.3 稀疏交互,提取更深层的特征信息
- 三、在PyTorch中构筑卷积神经网络
-
- 1 二维卷积层nn.Conv2d
-
- 1.1 卷积核尺寸kernel_size
- 1.2 卷积的输入与输出:in_channels,out_channels,bias
- 1.3 特征图的尺寸:stride,padding,padding_mode
-
- stride
- Padding,Padding_mode
- 2 池化层nn.MaxPool & nn.AvgPool
- 3 Dropout2d与BatchNorm2d
- 四、复现经典模型
-
- 1 复现经典模型LeNet5
- 2 复现经典模型AlexNet
pip install opencv-contrib-python -i https://pypi.mirrors.ustc.edu.cn/simple/
通过该命令在终端下载opencv库,导入库import cv2,如果没有报错就说明安装成功了
一、计算机视觉 ≠ 卷积神经网络
在过去十年,人们常常认为计算机视觉是以深度学习和卷积神经网络(Convolutional Neural Networks, CNN)为核心研究领域。事实上,早在深度学习兴起之前,计算机视觉就是一个理论成熟、 内容繁多的跨学科领域。
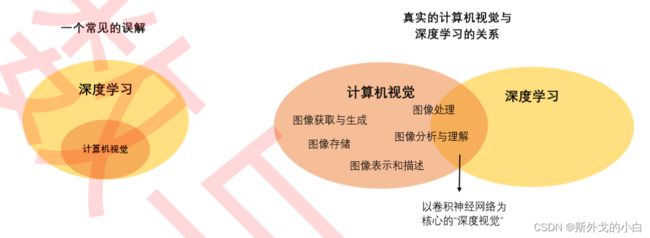
计算机视觉有完备的知识体系,它的内容包括了摄像设备性能、成像原理等图像获取和生成技术、也包 括视频特效、3D、图像复原等早就被广泛应用的视频/图像处理技术,同时还包括图像分割、图像识别 等让计算机分析、理解图像的技术。其中,图像处理也叫做“图像特征提取”,这项技术高度依赖数学、 几何、光学等基础学科,与信号处理等学科有较多交叉,是计算机视觉中非常关键的领域。21世纪初, 从事计算几何、计算机图形学、图像处理、普通成像、机器人等工作的研究人员或技术人员都需要学习 计算机视觉丰富的经典理论,直到今天,许多视觉项目也是从“硬件自动采集图像”开始。
在人工智能兴起之后,人们发现传统计算机视觉中图像处理、图像分析领域的许多工作都可以由神经网 络来完成,并且当数据量和计算资源足够时,神经网络往往能比传统方法取得更好的效果(As always)。于是人工智能与计算机视觉的交叉学科深度视觉诞生了,它是使用深度学习相关的技术、让 计算机从图像或图像序列中获取信息并理解其信息的学科。而其中最令人瞩目的研究成果就是以卷积神 经网络为核心的一系列模型架构。因此,包括我们的课程在内的众多计算机视觉课程,应该被称之为“深 度视觉”课程才对。
但令人惊讶的是,在卷积神经网络压倒性的效果和性能下,行业并没有放弃传统计算机视觉,整个行业 的人才标准也偏向于视觉人才与人工智能人才的融合,而不是传统视觉人才被“替代”。如今,计算机视觉工程师都必须掌握神经网络,但同时,也还是需要学习传统视觉相关的内容,而只使用深度学习方 法、不使用传统计算机视觉方法的企业和研究机构并不太多。
深度视觉没有彻底颠覆计算机视觉,主要原因有两个:
1、深度视觉训练成本太高,而传统视觉方法成本。不是每个企业都能够满足深度学习算法对数据、 算力的要求。数据量越大、网络层数越深,模型的效果也就越好,但同时所需要的训练和研发成本也会 越高。世界上大部分的企业都无法支持这样的投入(也因此算法岗在全球的数量都远远不及开发岗 多)。
2、深度视觉算法的进步和提升,需要传统视觉理论的支持。深度学习算法本身是黑箱,深度视觉领域又因为“过于年轻”所以理论基础不足,因此当网络层数非常深时,我们只能孜孜不倦、日以继夜得通过尝试来优化网络,但这又需要很高的训练成本和很长的训练时间。当成本不足、理论不清晰、又必须优化 网络时,我们常常从传统计算机视觉的理论中获得启发。实际上,深度学习领域许多非常关键的创新都 来源于学者对于其他研究领域的借鉴,比如,卷积神经网络中的卷积操作,就是传统视觉中常用的图像 处理技术。
二、从卷积到卷积神经网络
1 图像的基本表示
深度视觉是处理图像的学科,因此我们需要从图像本身开始说起。每张图像都是以一个三维 Tensor或者三维矩阵表示,其三个维度分别是(高度 height,宽度 width,通道 channels)。高度和宽度往往排列在一起,一般是先高后宽的顺序,两者共同决定图像的尺寸大小。
这张图的shape是(1707, 2506, 3)
如上图,高度 1707为则说明图像在竖直方向有1707个像素点(有1707列),同理宽度则代表水平方向的像素点数目 (有2560行),因此如上的孔雀图总共有1707*2560 = 4,369,920个像素点。
通道是单独的维度,通常排在高度宽度之后,但也有可能是排在第一位。它决定图像中的轮廓、线条、 色彩,基本决定了图像中显示的所有内容,尤其是颜色,因此又叫做色彩空间(color space)。
通道的理解:例如,自然界中的颜色都是由“三原色”红黄蓝构成的,将红色和蓝色混在一起会得到紫色,将红 色和黄色混在一起会得到橙色,白色的阳光可以经由三棱镜分解成七彩的光谱等等。计算机的世界中的 颜色也是由基本颜色构成的,在计算机的世界里,用于构成其他颜色的基础色彩,就叫做“通道”。
我们最常用的三种基本颜色是红绿蓝(Red, Green, Blue, 简写为RGB),所以最常用的通道就是RGB通 道。我们通过将红绿蓝混在一起,创造丰富的色彩。例如,上面的孔雀图,其实是下面三张红、绿、蓝 三色的图像叠加而成。

在通道的每一个像素点上,都有[0,255]之间的整数值,这些整数值代表了“该通道上颜色的灰度”。在图 像的语言中,“灰度”就是明亮程度。数字越接近255,就代表颜色明亮程度越高,越接近通道本身的颜 色,数字越接近0,就代表颜色的明亮程度越弱,也就是越接近黑色。(仔细观察孔雀脖子的部分,孔雀 脖子在图像上是蓝色的,这种蓝色主要由蓝色通道和绿色通道构成,几乎没有任何红色通道的元素,因 此在红色通道的图片中,孔雀脖子几乎都是黑的。)
在图像的矩阵中,我们可以使用索引找出任意像素的三个通道上的颜色的明度,例如,对于第0行、第0 列的样本而言,可以看到一个三列的矩阵,这三列就分别代表着红色、绿色、蓝色的像素值。当三个值都不为0时,这个像素在三个通道上都有颜色。相对应的,最纯的红色会显示为(255,0,0),最纯的蓝色就 会显示为(0,0,255),绿色可以此类推。当像素值为(0,0,0)时,这个像素点就为黑色,当像素值为 (255,255,255),像素点就为白色。通道上像素的灰度,也就是矩阵中的值几乎100%决定了图像会呈现 出什么样子。
灰度通道:灰度在计算机视觉中是指“明暗程度”,而不是指“灰色”,因而灰度通道也不是指图像是灰色的通道,而是只有一种颜色的通道,同理,灰度图像是只有一个通道的图像。所以RGB通道中的任意一个 通道单独拿出来之后,都可以用灰度(明暗)来显示。就像我们在Fashion-MNIST数据集中所见到的, 灰度图像的shape最后一列为1,索引出来的值中只有一个数字,这个数字就是这种唯一颜色的明度。当 你看见图像的通道数为1,无论可视化之后图像显示什么视觉颜色,它都只是表示单一颜色的明度而已。 (没有人怀疑过为什么fashion-MNIST中的图绘制出来是黄绿色的吗?你现在了解,其实蓝绿色也只是明度的一种表示)。

RGB色彩空间:数字世界最常见的彩色通道,分别表示红、绿、蓝三种电子成像的基本颜色。
CMYK色彩空间:用于彩色打印机成像的通道,由青色(Cyan)、品红(Magenta)、黄色(Yellow)和黑色(Black)构成,因此是四维通道,在图像结构中会显示为(高度,宽度,4)。
HSV(或HSL)色彩空间:HSV通道是为人们描述和解释颜色而创建的,H代表色相,S代表饱和度,V代表亮度。
以上三种空间可以自由切换(会产生数据损失),在OpenCV中也有支持切换的函数可以调用。在计算 机视觉中,我们可能遇见各种通道类型的图片,当我们需要对图像进行特定操作时,我们必须了解这些通道并了解如何在他们之间进行转换。
另一种非常常见的色彩空间是RGBA,它也拥有四维通道,分别是(红色,绿色,蓝色,透明度 alpha)。透明度alpha的取值范围在0-1之间。当一个像素的RGB显示为(0,255,0)时,则说明这个像素里 是明度最高的绿色,但加上透明度之后,色彩就会变得“透明”。RGBA可以提供更丰富的色彩样式,让图像的色彩变得更加绚丽。
2 OpenCV令像素变化来改变图像
import cv2
import numpy as np
import matplotlib.pyplot as plt
#读取计算机中的图像
img = cv2.imread('blue-peacock.jpg')
#openCV默认读取后的图像通道是BGR,而因此我们需要先转换图像通道的顺序
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
#也可以使用步长为-1的逆序索引来进行转换
#img = img[:, :, ::-1]
#查看图片的结构
print(img.shape)
#(1707, 2560, 3)
#展示图片
plt.figure(dpi=150)
plt.imshow(img)
plt.axis("off")
plt.show()

图片数据是由uint8类型来保护的。
#unit8类型对图片数据的保护
a = np.array([0, 1, 255], dtype='uint8')
print(a)
#[ 0 1 255]
print(a+10)
#[10 11 9]
通过上面的结果我们可以看出,在unit8数据下,线性变换不是单调的,而是循环的。但我们不希望图像像素是循环的!当我们对图像进行调整时,我们可以允许它因为太暗所以变黑,因为太亮所 以变白,但不能允许它因为“太亮了超出数字范围,于是变黑”,这不符合我们对图像的认知逻辑。
因此,在进行任何线性变换之前,都需要将uint8替换掉,我们可以由以下操作:
img = img * 1.0
#或者将图片像素进行归一化处理
img = img/255
print(img.dtype)
#float64
首先,图像的格式会从uint8变为float64,不再受到uint8类型的限制,可以允许负数、小数、超出255的整数,这让图像的变化变得单调,我们在进行线性变换时不用“小心翼翼”了 (当然,这并不代表我们不需要把数字控制在[0,255]内了,为了让图像显示正常,我们将会使用np.clip来 控制图像的像素)。
其次,图像的计算会变得更快 但需要注意的是,float64将不能够在被OpenCV进行转换或其他处理 因此,只有当我们需要手动操作图像的像素时,我们才会使用归一化处理。
现在我们在图像上做一些改变。之前我们说过,像素值越接近255,就表示图像的“明度”越高,像素值越 越接近0,就表示图像会变得越暗,当我们对图像归一化后,像素值越接近1就越亮,越接近0就越暗。 所以我们可以通过对像素值做线性变换,来调整图像的“明暗”程度。
img = img/255
print(img.dtype)
#float64
#调亮画面
img_ = np.clip(img + 100/255, 0, 1) #np.clip是一个可以抹掉范围外值的函数
plt.figure(dpi=100)
plt.imshow(img_)
plt.axis('off')
plt.show()

#调暗画面
img_ = np.clip(img - 100/255,0,1)
plt.figure(dpi=100)
plt.imshow(img_)
plt.axis('off')
plt.show()

#让画面更鲜艳
img_ = np.clip(img*2, 0, 1) #原本就很大的值会增长得更快,因此原本就很鲜艳的颜色会变得更加鲜 艳,增加对比度
plt.figure(dpi=100)
plt.imshow(img_)
plt.axis('off')
plt.show()

我们还可以将图像切换到其他色彩空间,来调整色相和饱和度,比如:
import cv2
import numpy as np
import matplotlib.pyplot as plt
#读取计算机中的图像
img = cv2.imread('blue-peacock.jpg')
#OpenCV默认读取后的图像通道是BGR,为了调整饱和度,我们直接将通道转换为HSV
img_hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
h, s, v = cv2.split(img_hsv)
#这里分解出的是uint8,要在uint8上进行数值操作则必须先更换为浮点数
h += np.clip(s*1.0+100,0,255).astype("uint8") # 色相
#s += np.clip(s*1.0+100,0,255).astype("uint8") # 饱和度
#v += np.clip(s*1.0+100,0,255).astype("uint8") # 亮度
final_hsv = cv2.merge((h, s, v))
#为了绘图,这里是转回RGB,而不是BGR
img_s = cv2.cvtColor(final_hsv, cv2.COLOR_HSV2RGB)
plt.figure(dpi=100)
plt.imshow(img_s)
plt.axis('off')
plt.show()

img_hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
h, s, v = cv2.split(img_hsv)
#这里分解出的是uint8,要在uint8上进行数值操作则必须先更换为浮点数
#h += np.clip(s*1.0+100,0,255).astype("uint8") # 色相
s += np.clip(s*1.0+100,0,255).astype("uint8") # 饱和度
#v += np.clip(s*1.0+100,0,255).astype("uint8") # 亮度
final_hsv = cv2.merge((h, s, v))
#为了绘图,这里是转回RGB,而不是BGR
img_s = cv2.cvtColor(final_hsv, cv2.COLOR_HSV2RGB)
plt.figure(dpi=100)
plt.imshow(img_s)
plt.axis('off')
plt.show()

#OpenCV默认读取后的图像通道是BGR,为了调整饱和度,我们直接将通道转换为HSV
img_hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
h, s, v = cv2.split(img_hsv)
#这里分解出的是uint8,要在uint8上进行数值操作则必须先更换为浮点数
#h += np.clip(s*1.0+100,0,255).astype("uint8") # 色相
#s += np.clip(s*1.0+100,0,255).astype("uint8") # 饱和度
v += np.clip(s*1.0+100,0,255).astype("uint8") # 亮度
final_hsv = cv2.merge((h, s, v))
#为了绘图,这里是转回RGB,而不是BGR
img_s = cv2.cvtColor(final_hsv, cv2.COLOR_HSV2RGB)
plt.figure(dpi=100)
plt.imshow(img_s)
plt.axis('off')
plt.show()

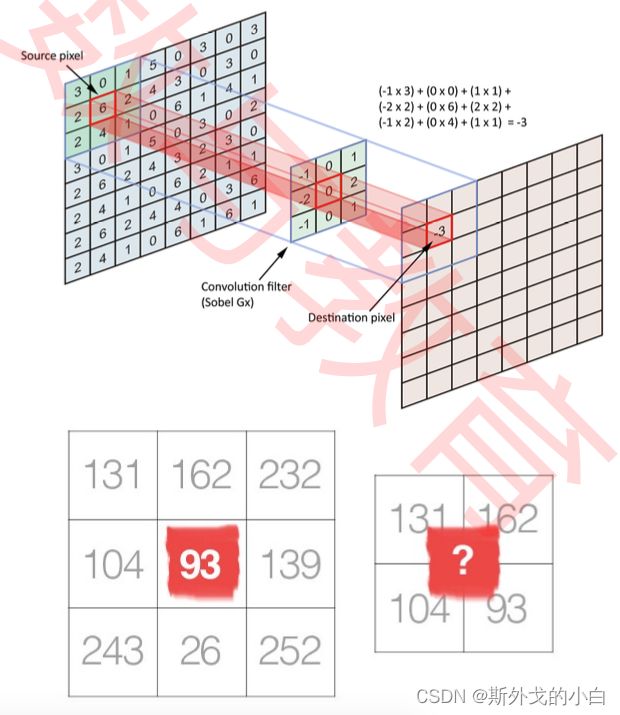
3 卷积操作

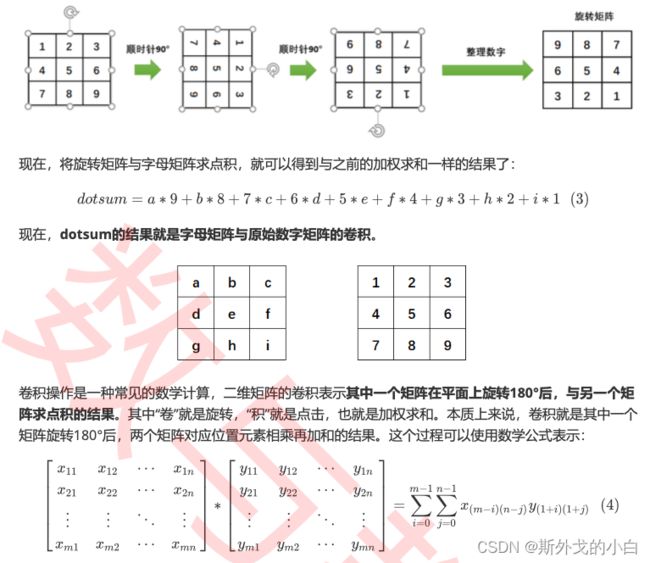


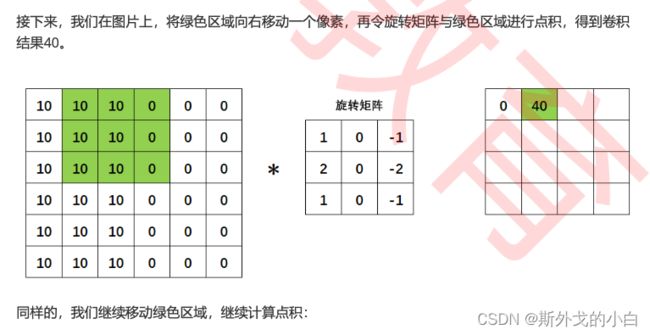

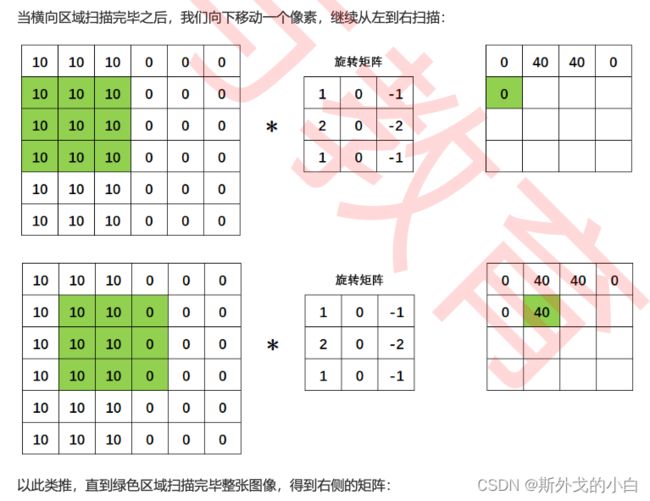

边缘检测是卷积操作的一个常见应用,我们所使用的权重矩阵其实是纵向的索贝尔算子(Sobel Operator),用于检测纵向的边缘,我们也可以使用横向的索贝尔算子,以及拉普拉斯算子来检测边 缘。在OpenCV当中我们可以很容易地实现这个操作:
import cv2
from matplotlib import pyplot as plt
img = cv2.imread('edge detection.png') #索贝尔等经典卷积操作在灰度图像上表现更好,因此我们将图像导入时就转化为灰度图像
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
#两种经典算子:拉普拉斯与索贝尔
laplacian = cv2.Laplacian(img,cv2.CV_64F,ksize=5) #cv2.CV_64F是opencv中常常使用的一种数据格式,在这里输入之后可以保证输出数据是uint8类型
sobelx = cv2.Sobel(img,cv2.CV_64F,1,0,ksize=5) #横向的索贝尔,旋转矩阵为5X5
sobely = cv2.Sobel(img,cv2.CV_64F,0,1,ksize=5) #纵向的索贝尔,旋转矩阵为5X5
plt.figure(dpi=300)
plt.subplot(2,2,1)
plt.imshow(img,cmap = 'gray')
plt.title('Original')
plt.axis('off')
plt.subplot(2,2,2)
plt.imshow(laplacian,cmap = 'gray')
plt.title('Laplacian')
plt.axis('off')
plt.subplot(2,2,3)
plt.imshow(sobelx,cmap = 'gray')
plt.title('Sobel X')
plt.axis('off')
plt.subplot(2,2,4)
plt.imshow(sobely,cmap = 'gray')
plt.title('Sobel Y')
plt.axis('off')
plt.show()
事实上,就连OpenCV中的sobel和Laplacian函数都没有进行“旋转”,而是直接定义了旋转后矩阵。或许 是最初的研究者尝试了“卷积”操作,就这样流传下来,或许是原始权重矩阵的逻辑可能来源于某些理 论,不旋转将会使边缘检测失效,但在今天的计算机视觉技术中,尤其是深度学习中,大部分时候我们 都不再进行“旋转”这个步骤了。甚至在许多卷积相关的讲解中,会直接忽略旋转这个步骤,导致许多人 无法理解“卷积”的“卷”从何而来。
4 卷积遇见深度学习
在边缘检测的例子中,我们看到拉普拉斯和索贝尔算子的检测是很明显的。但是,如果使用我们之前导入的孔雀图像,就会发现边缘检测的效果有些糟糕。
这是因为,sobel和拉普拉斯算子对边缘抓取的程度较轻(从图像处理的原理上来看, 他们只求取了图像上的一维导数,因此效果不够强),这样的抓取对于横平竖直的边缘、以及色彩差异 较大的边缘有较好的效果,对于孔雀这样色彩丰富、线条和细节非常多的图像,这两种算子就不太够用 了。所以在各种边缘检测的例子中,如果你仔细观察原图,你就会发现原图都是轮廓明显的图像。
这说明,不同的图像必须使用不同的权重进行特征提取,同时,我们还必须加深特征提取的深度。那什 么样的图像应该使用什么样的权重呢?如何才能够提取到更深的特征呢?同时,如果过去的研究中提出 的算子都不奏效,应该怎么找到探索新权重的方案呢?即便有效地实现了边检检测、锐化、模糊等操 作,就能够提升最终分类算法的表现吗?其实不然。这些问题困扰计算机视觉工程师许久,即便在传统 视觉中,我们已提出了不少对于这些问题的解决方案,但从一劳永逸的方向来考虑,如果计算机自己能 够知道应该使用什么算子、自己知道应该提取到什么程度就好了。此时,深度学习登场了。
4.1 通过学习寻找卷积核
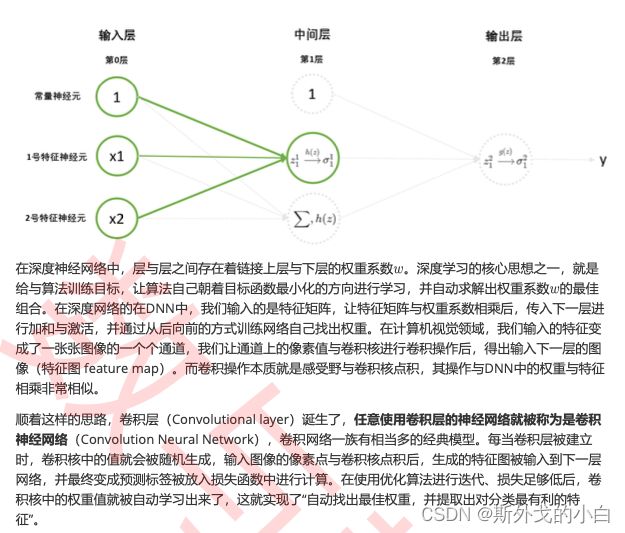
4.2 权重共享,参数骤减
深度学习的模型总是需要大规模计算和训练来达到商业使用标准,计算量一直都是深度学习领域的痛, 而巨大的计算量在很多时候都与巨量参数有关。在卷积神经网络诞生之前,人们一直使用普通全连接的 DNN来训练图像数据。对于一张大小中等,尺寸为(600,400)的图像而言,若要输入全连接层的DNN, 则需要将像素拉平至一维,在输入层上就需要600*400 = 24万个神经元,这就意味着我们需要24万个参 数来处理这一层上的全部像素。如果我们有数个隐藏层,且隐藏层上的神经元个数达到10000个,那 DNN大约需要24亿个参数( 个)才能够解决问题。
然而,卷积神经网络却有“参数共享”(Parameter Sharing)的性质,可以令参数量骤减。一个通道虽然 可以含有24万个像素点,但图像上每个“小块”的感受野都使用相同的卷积核来进行过滤。卷积神经网络 要求解的参数就是卷积核上的所有数字,所以24万个像素点共享卷积核就等于共享参数。假设卷积核的 尺寸是5x5,那处理24万个像素点就需要25个参数。假设卷积中其他需要参数层也达到10000个,那 CNN所需的参数也只有25万。由于我们还没有介绍卷积神经网络的架构,因此这个计算并不是完全精 确,但足以表明卷积有多么节省参数了。参数量的巨大差异,让卷积神经网络的计算非常高效。在第一 堂课时我们说到,深度学习近二十多年的发展,都围绕着“让模型计算更快、让模型更轻便”展开,从全 连接到卷积就是一个很好的例子。预测效果好,且计算量小,这是卷积神经网络在计算机视觉领域大热的原因之一。
4.3 稀疏交互,提取更深层的特征信息
在CNN中,我们都是以“层”或者“图”、“通道”这些术语来描述架构,但 其实CNN中也有神经元。在任何神经网络中,一个神经元都只能够储存一个数字。所以在CNN中,一个 像素就是一个神经元(实际上就是我们在类似如下的视图中看到的每个正方形小格子)。很容易理解, 输入的图像/通道上的每个小格子就是输入神经元,feature map上的每个格子就是输出神经元。在DNN 中,上层的任意神经元都必须和下层的每个神经元都相连,所以被称之为“全连接”(fully connected),但在CNN中,下层的一个神经元只和上层中被扫描的那些神经元有关,在图上即表示 为,feature map上的绿格子只和原图上绿色覆盖的部分有关。这种神经元之间并不需要全链接的性质 被称为稀疏交互(Sparse Interaction)。人们认为,稀疏交互让CNN获得了提取更深特征的能力。

三、在PyTorch中构筑卷积神经网络
1 二维卷积层nn.Conv2d
CLASS torch.nn.Conv2d (in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode=‘zeros’)
1.1 卷积核尺寸kernel_size
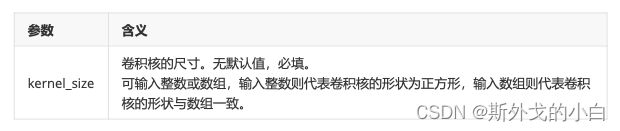

1.2 卷积的输入与输出:in_channels,out_channels,bias
除了kernel_size之外,还有两个必填参数:in_channels与out_channels。简单来说:in_channels是 输入卷积层的图像的通道数或上一层传入特征图的数量,out_channels是指这一层输出的特征图的数量。
在一次扫描中,无论图像本身有几个通道,卷积核会扫描全部通道之后,将扫描结果加和为一张 feature map。所以,一次扫描对应一个feature map,无关原始图像的通道数目是多少,所以 out_channels就是扫描次数,这之中卷积核的数量就等于输入的通道数in_channels x 扫描次数 out_channels。

import torch
from torch import nn
#假设一组数据
#还记得吗?虽然默认图像数据的结构是(samples, height, width, channels) #但PyTorch中的图像结构为(samples, channels, height, width),channels排在高和宽前面 #PyTorch中的类(卷积)无法读取channels所在位置不正确的图像
data = torch.ones(size=(10,3,28,28)) #10张尺寸为28*28的、拥有3个通道的图像
conv1 = nn.Conv2d(in_channels = 3,out_channels = 6, kernel_size = 3)
#全部通道的扫描值被合并,6个卷积核形成6个featuremap
conv2 = nn.Conv2d(in_channels = 6,out_channels = 4 ,kernel_size = 3) #conv3 = nn.Conv2d(in? out?)
#通常在网络中,我们不会把参数都写出来,只会写成: #conv1 = nn.Conv2d(3,6,3)
#查看一下通过卷积后的数据结构 conv1(data).shape
conv2(conv1(data)).shape #尝试修改一下conv2的in_channels,看会报什么错?
conv2 = nn.Conv2d(in_channels = 10,out_channels = 4,kernel_size = 3) conv2(conv1(data))

1.3 特征图的尺寸:stride,padding,padding_mode
stride
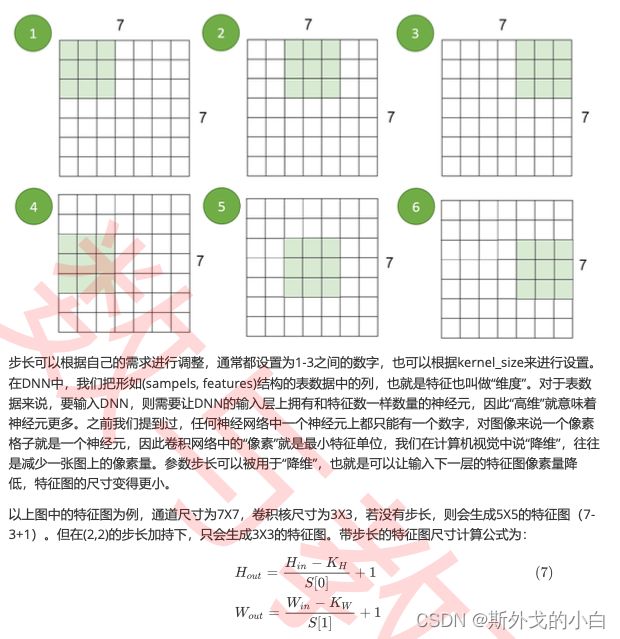
经过卷积操作之后,新生成的特征图的尺寸往往是小于 上一层的特征图的。在之前的例子中,我们使用3X3的卷积核在6X6大小的通道上进行卷积,得到的特征 图是4X4。如果在4X4的特征图上继续使用3X3的卷积核,我们得到的新特征图将是2X2的尺寸。最极端 的情况,我们使用1X1的卷积核,可以得到与原始通道相同的尺寸,但随着卷积神经网络的加深,特征 图的尺寸是会越来越小的。
对于一个卷积神经网络而言,特征图的尺寸非常重要,它既不能太小,也不能太大。如果特征图太小, 就可能缺乏可以提取的信息,进一步缩小的可能性就更低,网络深度就会受限制。如果特征图太大,每 个卷积核需要扫描的次数就越多,所需要的卷积操作就会越多,影响整体计算量。同时,卷积神经网络 往往会在卷积层之后使用全连接层,而全连接层上的参数量和输入神经网络的图像像素量有很大的关系 (记得我们之前说的吗?全连接层需要将像素拉平,每一个像素需要对应一个参数,对于尺寸600X400 的图片需要2.4* 个参数),因此,在全连接层登场之前,我们能够从特征图中提取出多少信息,并且 将特征图的尺寸、也就是整体像素量缩小到什么水平,将会严重影响卷积神经网络整体的预测效果和计 算性能。也因此,及时了解特征图的大小,对于卷积神经网络的架构来说很有必要。
Padding,Padding_mode

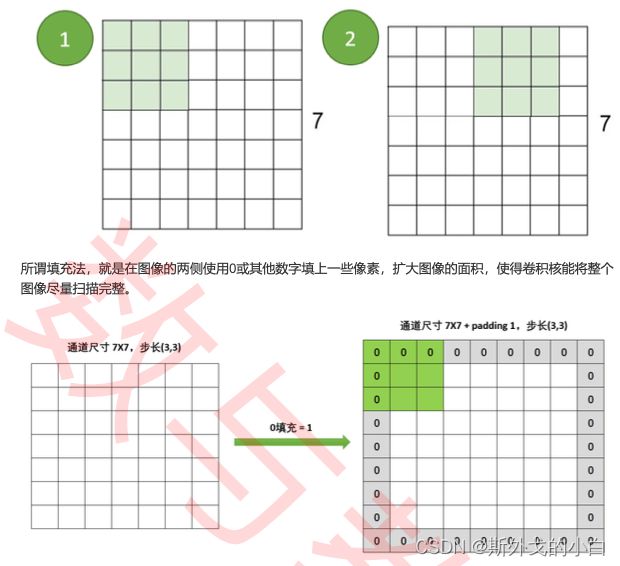

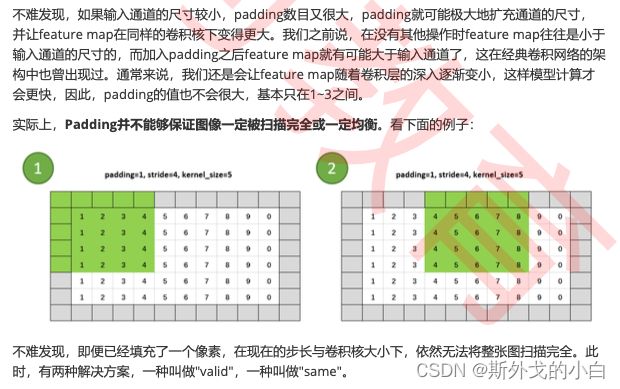

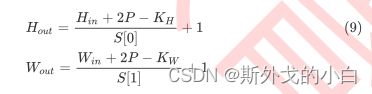
padding操作会影响通道的大小,因此padding也会改变feature map的尺寸,当padding中输入的值为p时,特征图的大小具体如下:
import torch
import torch.nn as nn
#记住我们的计算公式
#(H + 2p - K)/S + 1
#(W + 2p - K)/S + 1 #并且卷积网络中,默认S=1,p=0
data = torch.ones(size=(10,3,28,28)) #10张尺寸为28*28的、拥有3个通道的图像
conv1 = nn.Conv2d(3,6,3) #这一层输出的feature map结构应该是?
conv2 = nn.Conv2d(6,4,3) #这一层呢?输入数据为conv1的结果
conv3 = nn.Conv2d(4,16,5,stride=2,padding=1) #现在加上步长和填充,输入数据为conv2的结果 conv4 = nn.Conv2d(16,3,5,stride=3,padding=2)
print(conv1(data).shape)
#torch.Size([10, 6, 26, 26])
#conv1,输入结构28*28 #(28 + 0 - 3)/1 + 1 = 26 #验证一下
#conv2,输入结构26*26 #(26 + 0 - 3)/1 + 1 = 24 #验证 conv2(conv1(data)).shape
#conv3,输入结构24*24
#(24 + 2 - 5)/2 + 1 = 11,扫描不完全的部分会被舍弃 conv3(conv2(conv1(data))).shape
#conv4,输入结构11*11
#(11 + 4 - 5)/3 + 1 = 4.33,扫描不完全的部分会被舍弃 conv4(conv3(conv2(conv1(data)))).shape
2 池化层nn.MaxPool & nn.AvgPool
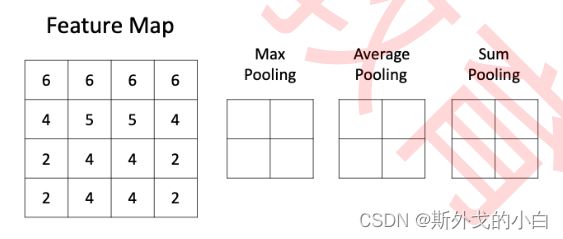
池化层也有核,但它的核没有值,只有尺寸。在上图之中,池化核的尺寸就是(2,2)。池化核的移动也有 步长stride,但默认步长就等于它的核尺寸,这样可以保证它在扫描特征图时不出现重叠。当然,如果 我们需要,我们也可以设置参数令池化核的移动步长不等于核尺寸,在行业中这个叫“Overlapping Pooling”,即重叠池化,但它不是非常常见。通常来说,对于特征图中每一个不重叠的、大小固定的矩 阵,池化核都按照池化的标准对数字进行计算或筛选。在最大池化中,它选出扫描区域中最大的数字。 在平均池化中,它对扫描区域中所有的数字求平均。在加和池化中,它对扫描区域中所有的数字进行加和。

data = torch.ones(size=(10,3,28,28))
conv1 = nn.Conv2d(3,6,3) #(28 + 0 - 3)/1 + 1 = 26
conv3 = nn.Conv2d(6,16,5,stride=2,padding=1) # (26 + 2 - 5)/2 +1 = 12
pool1 = nn.MaxPool2d(2) #唯一需要输入的参数,kernel_size=2,则默认使用(2,2)结构的核
# (12 + 0 - 2)/2 + 1 =6
#验证一下 pool1(conv3(conv1(data))).shape
与卷积不同,池化层的操作简单,没有任何复杂的数学原理和参数,这为我们提供了精简池化层代码的 可能性。通常来说,当我们使用池化层的时候,我们需要像如上所示的方法一样来计算输出特征图的尺 寸,但PyTorch提供的“Adaptive”相关类,允许我们输入我们希望得到的输出尺寸来执行池化:
data = torch.ones(size=(10,3,28,28))
conv1 = nn.Conv2d(3,6,3) #(28 + 0 - 3)/1 + 1 = 26
conv3 = nn.Conv2d(6,16,5,stride=2,padding=1) # (26 + 2 - 5)/2 +1 = 12
pool1 = nn.AdaptiveMaxPool2d(7) #输入单一数字表示输出结构为7x7,也可输入数组
print(pool1(conv3(conv1(data))).shape)
torch.szie(10,6,7,7)
除了能够有效降低模型所需的计算量、去除冗余信息之外,池化层还有特点和作用呢?
1、提供非线性变化。卷积层的操作虽然复杂,但本质还是线性变化,所以我们通常会在卷积层的后面增 加激活层,提供ReLU等非线性激活函数的位置。但池化层自身就是一种非线性变化,可以为模型带来一 些活力。然而,学术界一直就池化层存在的必要性争论不休,因为有众多研究表明池化层并不能提升模 型效果(有争议)。
2、有一定的平移不变性(有争议)。 3、池化层所有的参数都是超参数,不涉及到任何可以学习的参数,这既是优点(增加池化层不会增加参
数量),也是致命的问题(池化层不会随着算法一起进步)。
4、按照所有的规律对所有的feature map一次性进行降维,feature map不同其本质规律不然不同,使 用同样的规则进行降维,必然引起大估摸信息损失。
不过,在经典神经网络架构中,池化层依然是非常关键的存在。如果感兴趣的话,可以就池化与卷积的 交互相应深入研究下去,继续探索提升神经网络效果的可能性。
3 Dropout2d与BatchNorm2d
Dropout与BN是神经网络中非常经典的,用于控制过拟合、提升模型泛化能力的技巧,在卷积神经网络 中我们需要应用的是二维Dropout与二维BN。对于BN我们在前面的课程中有深入的研究,它是对数据 进行归一化处理的经典方法,对于图像数据,我们所需要的类如下:
CLASS torch.nn.BatchNorm2d (num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
BN2d所需要的输入数据是四维数据(第一个维度是samples),我们需要填写的参数几乎只有 num_features一个。在处理表数据的BatchNorm1d里,num_features代表了输入bn层的神经元个 数,然而对于卷积网络来说,由于存在参数共享机制,则必须以卷积核/特征图为单位来进行归一化,因 此当出现在卷积网络前后时,BatchNorm2d所需要输入的是上一层输出的特征图的数量。例如:
data = torch.ones(size=(10,3,28,28)) conv1 = nn.Conv2d(3,32,5,padding=2)
bn1 = nn.BatchNorm2d(32)
bn1(conv1(data)).shape
#不会改变feature map的形状
#输入其他数字则报错
#bn1 = nn.BatchNorm2d(10)
同时,BN层带有 beta和gamma参数,这两个参数的数量也由特征图的数量决定。例如,对有32张特征图的数据 进行归一化时,就需要使用32组不同的 和 参数,总参数量为特征图数 * 2 = 64。
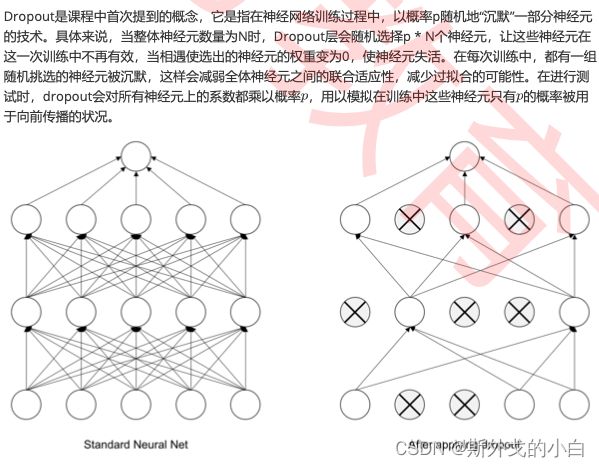
对于卷积神经网络来说,我们需要使用的类是Dropout2d,唯一需要输出的参数是p,其输入数据同样 是带有samples维度的四维数据。不过在卷积中,Dropout不会以神经元为单位执行“沉默”,而是一次性 毙掉一个通道。因此,当通道总数不多时,使用Dropout或Dropout中的p值太大都会让CNN丧失学习能 力,造成欠拟合。通常来说,使用Dropout之后模型需要更多的迭代才能够收敛,所以我们总是从 p=0.1,0.25开始尝试,最多使用p=0.5,否则模型的学习能力会出现明显下降。
CLASS torch.nn.Dropout2d (p=0.5, inplace=False)
data = torch.ones(size=(10,1,28,28))
conv1 = nn.Conv2d(1,32,5,padding=2)
dp1 = nn.Dropout2d(0.5)
dp1(conv1(data)).shape #不会改变feature map的形状
Dropout层本身不带有任何需要学习的参数,因此不会影响参数量。
四、复现经典模型
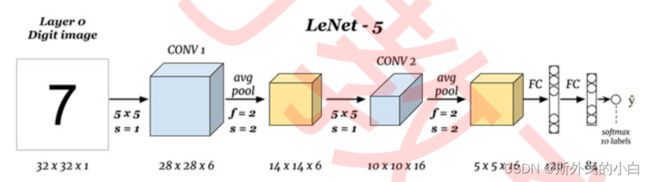
这个架构就是著名的LeNet5架构,它在1998年被LeCun等人在论文《Gradient-Based Learning Applied to Document Recognition》中正式提出,它被认为是现代卷积神经网络的奠基者。在LeNet5 被提出后,几乎所有的卷积网络都会连用卷积层、池化层与全连接层(也就是线性层)。现在,这已经 成为一种非常经典的架构:卷积层作为输入层,紧跟激活函数,池化层紧跟在一个或数个卷积+激活的结 构之后。在卷积池化交替进行数次之后,转向线性层+激活函数,并使用线性层结尾,输出预测结果。由 于输入数据结构的设置,以上架构图中的网络可能与论文中有一些细节上的区别(论文见下载资料), 在其他教材中,你或许会见到添加了更多卷积层、或添加了更多池化层的相似架构,这些都是根据 LeNet的核心思想“卷积+池化+线性”来搭建的LeNet5的变体。
1 复现经典模型LeNet5
import torch
import torch.nn as nn
from torch.nn import functional as F
data = torch.ones(10, 1, 32, 32)
class Model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 6, 5) #32-5+1=28
self.pool1 = nn.AvgPool2d(2) #28/2 = 14
self.conv2 = nn.Conv2d(6, 16, 5) #14+0-5 + 1=10
self.pool2 = nn.AvgPool2d(2) #10/2 = 5
self.liearn1 = nn.Linear(5*5*16, 120)
self.liearn2 =nn.Linear(120, 84)
def forward(self, x):
x = torch.tanh(self.conv1(x))
x = self.pool1(x)
x = torch.tanh(self.conv2(x))
x = self.pool2(x)
x = x.view(-1, 5*5*16)
x = torch.tanh(self.liearn1(x))
output = F.softmax(self.liearn2(x), dim=1)
return output
net = Model()
net(data)
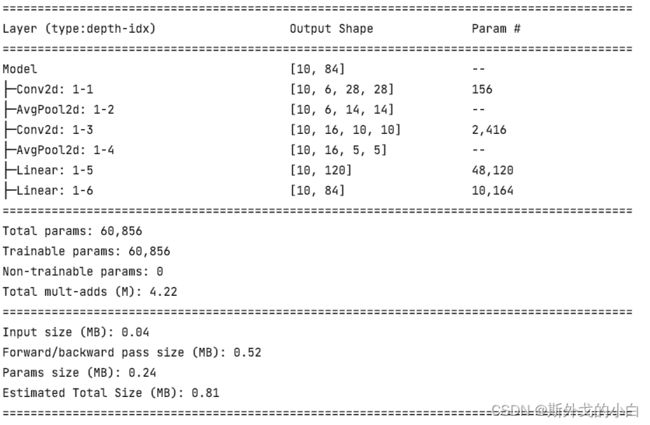
from torchinfo import summary
net = Model()
summary(net, input_size=(10 ,1, 32, 32))
2 复现经典模型AlexNet

和只有6层(包括池化层)的LeNet5比起来,AlexNet主要做出了如下改变:
1、相比之下,卷积核更小、网络更深、通道数更多,这代表人们已经认识到了图像数据天生适合于多次 提取特征,“深度”才是卷积网络的未来。LeNet5是基于MNIST数据集创造,MNIST数据集中的图片尺寸 大约只有30*30的大小,LeNet5采用了5x5的卷积核,图像尺寸/核尺寸大约在6:1。而基于ImageNet 数据集训练的AlexNet最大的卷积核只有11x11,且在第二个卷积层就改用5x5,剩下的层中都使用3x3 的卷积核,图像尺寸/核尺寸至少也超过20:1。小卷积核让网络更深,但也让特征图的尺寸变得很小, 为了让信息尽可能地被捕获,AlexNet也使用了更多的通道。小卷积核、多通道、更深的网络,这些都 成为了卷积神经网络后续发展的指导方向。
2、使用了ReLU激活函数,摆脱Sigmoid与Tanh的各种问题。
3、使用了Dropout层来控制模型复杂度,控制过拟合。
4、引入了大量传统或新兴的图像增强技术来扩大数据集,进一步缓解过拟合。
5、使用GPU对网络进行训练,使得“适当的训练“(proper training)成为可能。
除此之外,在原论文中,作者Alex Krizhevsky还提出了其他创新,例如,他们使用了overlap pooling的 技术——一般的池化层在进行扫描的时候,都是步幅 >= 核尺寸,而在AlexNet中,池化层中的步幅是小 于核尺寸的,这就让池化过程中的扫描区域出现重叠(overlap),根据论文所示,这个技术可以缓解过 拟合。从以上这些点,很容易看出为什么AlexNet对于卷积神经网络而言如此地重要,它几乎从算法、 算力、数据、架构技巧等各个方面影响了现代卷积神经网络地发展。AlexNet之后,ImageNet竞赛上就 很少看到传统视觉算法的身影了。当然,竞赛环境与工业环境有极大的区别,在实际落地的过程中,深 度学习还受到各种限制,因此传统方法依然很关键。
现在,让我们在PyTorch中来复现AlexNet的架构:
import torch
import torch.nn as nn
from torchinfo import summary
data = torch.ones(10, 3, 227, 227)
class model(nn.Module):
def __init__(self):
super(model, self).__init__()
self.conv1 = nn.Conv2d(3, 96, 11, stride=4) #(227-11)/4+1 = 55
self.pool1 = nn.MaxPool2d(kernel_size=3, stride=2) #(55-3)/2 +1 = 27
self.conv2 = nn.Conv2d(96, 256, 5, padding=2) #(27+2*2-5)/1 +1 = 27
self.pool2 = nn.MaxPool2d(kernel_size=3, stride=2) #(27-3)/2 + 1= 13
self.conv3 = nn.Conv2d(256, 384, 3, padding=1) #(13+2-3) +1 = 13
self.conv4 = nn.Conv2d(384, 384, 3, padding=1) #13
self.conv5 = nn.Conv2d(384, 256, 3, padding=1) #13
self.pool3 = nn.MaxPool2d(kernel_size=3, stride=2) #(13-3)/2 +1 =6
self.fc1 = nn.Linear(6*6*256, 4096)
self.drop1 = nn.Dropout(0.5)
self.fc2 = nn.Linear(4096, 4096)
self.drop2 = nn.Dropout(0.5)
self.fc3 = nn.Linear(4096, 1000)
self.output = nn.Softmax(dim=1)
def forward(self, x):
x = torch.relu(self.conv1(x))
x = self.pool1(x)
x = torch.relu(self.conv2(x))
x = self.pool2(x)
x = torch.relu(self.conv3(x))
x = torch.relu(self.conv4(x))
x = torch.relu(self.conv5(x))
x = self.pool3(x)
x = x.reshape(-1, 6*6*256)
x = torch.relu(self.fc1(x))
x = self.drop1(x)
x = torch.relu(self.fc2(x))
x = self.drop2(x)
output = self.output(x)
return output
net = model()
net(data)
summary(net, input_size=(10, 3, 227, 227))

