Alexnet_经典的CNN模型架构-LeNet、AlexNet、VGG、GoogleLeNet、ResNet
本文将引入 ImageNet图像数据库,并介绍以下几种经典的CNN模型架构:
LeNet、AlexNet、VGG、GoogleLeNet、ResNet
1.ImageNet介绍
ImageNet是一个包含超过1500万幅手工标记的高分辨率图像的数据库,大约有22000个类别。该数据 WordNet库组织类似于的层次结构,其中每个领域叫同义词集合。每个同义词集合都是 ImageNet层次结构中的一个节点。每个节点都包含超过500幅图像。
ImageNet大规模视觉识别挑战赛(ILSVRC)成立于2010年,旨在提高大规模目标检测和图像分类的最新技术。
在对 ImageNet概览之后,我们现在来看看不同的CNN模型架构。
2.LeNet

2010年,在 ImageNet挑战赛也称为 ILSVRC2010)中出现了一个CNN架构—— LeNet5,由 Yann Lecun创建。该网络以一个32×32的图像作为输入,然后进入卷积层(C1),接着进入子采样层(S2),目前子采样层被池化层取代。然后是另一个卷积层序列(C3),跟着是一个池化层(即子采样层)(S4)最后,有三个全连接层,包括最后的输出层(OUTPUT)。该网络用于邮局的邮政编码识别。从那以后,在这个比赛的助力下,每年都会引入不同的CNN架构。 LeNet5网络架构如图1所示。我们可以得出以下几点:
网络输入是一个32×32的灰度图像。
实现的架构是CONY层,其次是池化层和一个全连接层。
CONY层滤波器大小是5×5,步长为1
3. AlexNet架构
CNN架构的第一次突破发生在2012年。获奖的CNN架构名叫 AlexNet。它是由多伦多大学的 Alex Krizhevsky和他的教授 Jeffry Hinton开发.
在第一次运行中,该网络使用ReLU激活函数和0.5概率的 dropout来对抗过拟合。如图2所示,架构中使用了一个标准化层,但是由于该网络使用了大量的数据增强,因此在实践中不再使用该标准化层。虽然有更精确的网络可用,但由于 AlexNet相对简单的网络结构和较小的深度, AlexNet在今天仍然广泛使用。比如计算机视觉。
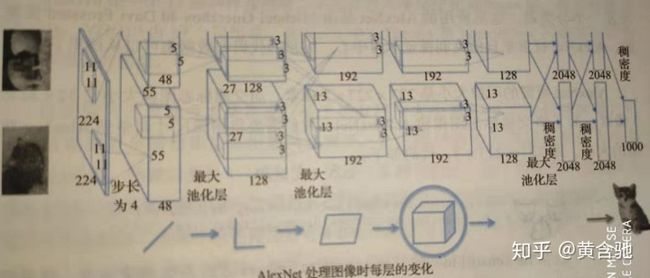
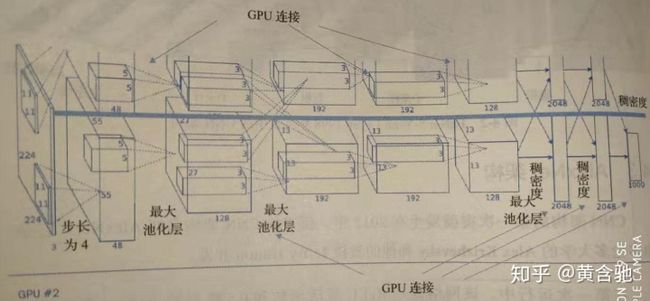
可能由于当时GPU连接间的处理限制, AlexNet使用两个单独的GPU在 ImageNet数据库上执行训练,如图3所示。
基于 AlexNet的交通标志分类器
在本例中,我们将使用迁移学习进行特征提取,并基于一个德国交通标志数据集开发一个分类器。这里所用的 AlexNetMichael是由 Guerzhoy和 Davi Frossard实现的, AlexNet权重来自伯克利视觉学习中心。完整的代码和数据集可以从这里下载。 AlexNet所需的图像大小是227×227×3像素,而交通标志图像大小是32×32×3像素。为了将交通标志图像输入 Alex Net,我们需要将图像尺寸调整到 AlexNet期望的大小,即227x227×3,代码如下
original_image我们可以借助 TensorFlow的tf.image. resize_images方法来做到这一点。这里的另一个问题是, AlexNet是在 ImageNet数据集上进行训练的,该数据集有1000类图像。因此,我们将用一个包含43个神经元的分类层来代替这个层。为此,计算出最后一个全连接层的输出大小,因为全连接层是一个2D形状,所以最后一个元素是输出的大小。fc7.get_shape.as_list()[-1]可以做到。最后将此数据与交通标志数据集的类别数量结合起来,可以得到最终全连接层的形状: shape=(getshape.aslist[-],43)。如下代码是在 TensorFlow中定义全连接层的标准方法。最后,使用 softmax计算概率大小:
#Refer AlexNet implementation code, returns last fully connected layer
4 .VGGNet架构
2014年 ImageNet挑战赛的亚军是来自牛津大学视觉几何团队的VGGNet.这个卷积网络是一个简单而优雅的架构,只有7.3%的误差率。它有两个版本:VGG16和 VGG19.
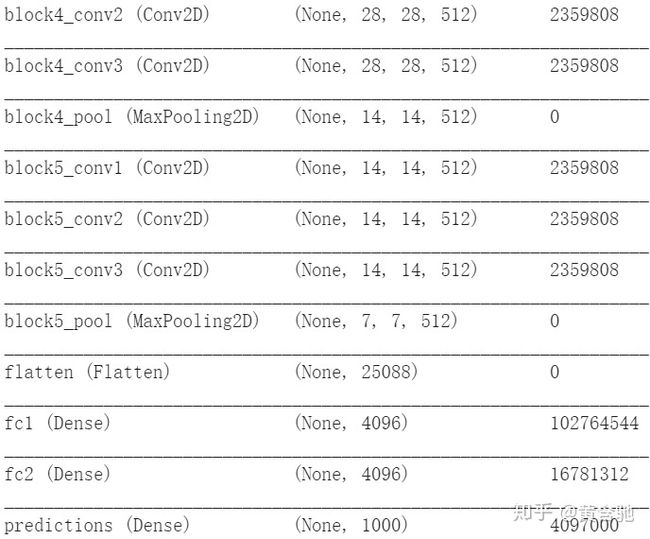
VGG16是一个16层的神经网络,不包括最大池化层和 softmax层。因此被称为VGG16。VGG19由19个层组成,在 Keras中, Theano和 TensorFlow后端都有一个预先训练好的模型。
这里的关键设计考虑是深度。基于所有层中大小为3x3的卷积滤波器,可以通过添加更多的卷积层来增加网络深度。这个模型的输入图像的默认大小是224×224×3。图像以步长1、填充值1通过一系列卷积层。整个网络中的卷积大小都是3×3。最大池化层以步长2通过2×2的窗口滑动,然后是另一个卷积层,后面是三个全连接层。前两个全连接层各有4096个神经元,第三个全连接层有1000个神经元,主要负责分类。最后一层是 softmax层。VGG16使用一个较小的3×3卷积窗口,相比之下, AlexNet的11×11卷积窗口要大得多。所有隐含层构建过程都使用relu激活函数。VGGNet架构如下所示:
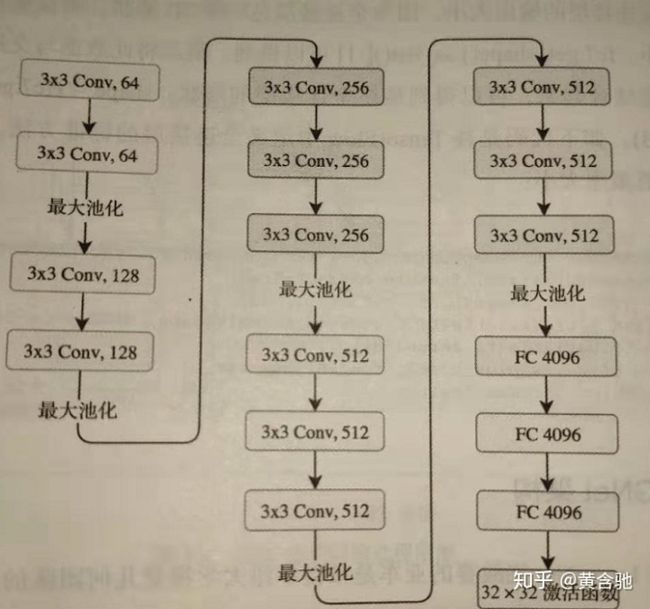
由于小的3×3卷积滤波器,使得 VGGNet深度增加。该网络的参数数量约为1.4亿个,大部分来自于第一个全连接层。在现代架构中, VGGNet的全连接层被全局平均池化(GAP)层替代,以最小化参数数量。
另一个观察结果是,滤波器的数量随着图像大小的减小而增加。
VGG16图像分类代码示例
Keras应用程序模块有预先训练的神经网络模型,以及在 ImageNet上预先训练的权重。这些模型可以直接用于预测、特征提取和调优。
①我在colab上运行的代码,先在谷歌图片上随便找一张dolphin照片下载到本地,然后通过以下代码上传照片到colab
from google.colab import files
uploaded = files.upload()
②搭建模型和训练模型、预测图片类别
#import VGG16 network model and other necessary libraries

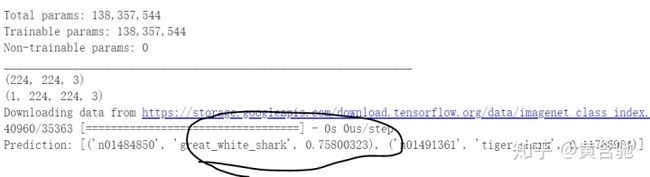
预测结果为大白鲨和虎鲨的结合,勉强过关嘿嘿嘿~
第一次执行上述代码时, Keras将自动下载并缓存架构权重到磁盘目录~/.keras/models中。这样后续的运行将更快。
5. GoogLeNet架构
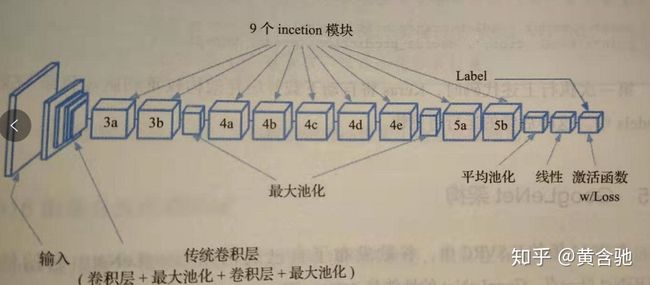
在2014年 ILSVRC的中,谷歌发布了自己的网络 GoogLeNet它的性能比 VGGNet好一点, GoogLeNet的性能是6.7%,而 VGGNet的性能是7.3%(这里性能指的是误差率)。GoogLeNet最吸引人之处在于它的运行速度非常快,主要原因是由于它引入了一个叫 inception模块的新概念,从而将参数数量减少到500个,是 AlexNet的1/12。同时它的内存和功耗也都更低。
GoogLeNet有22层,所以它是一个非常深的网络。添加的层数越多,参数的数量就越多,而且网络很可能出现过拟合。同时计算量将会更大,因为滤波器的线性增加将会导致计算量的二次方增大。所以设计人员使用了 inception模块和GAP。因为后全连接层容易过拟合,因此在网络末端将使用GAP替代全连接层。GAP没有需要学习或优化的参数。
5.1架构洞察
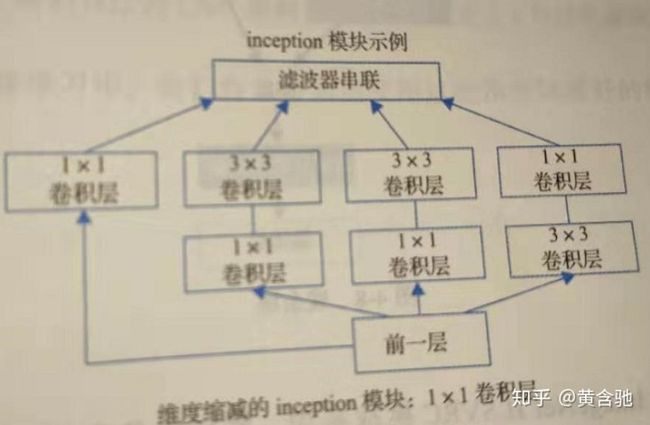
与前面架构不同, GoogLeNet设计人员没有选择特定的滤波器大小,而是将大小为1×1、3×3和5×5的所有三个滤波器和3×3的最大池化层都应用到同一个补丁中,并连接到单个输出向量中。
使用1×1的卷积会减少计算量,因为在昂贵的3×3和5×5卷积下计算量会增加。在昂贵的3×3和5×5卷积之前使用的是带有ReLU激活函数的1×1卷积。
在 GoogLeNet中, inception模块一个叠着一个这种堆叠允许我们修改每个模块而不影响后面的层。例如,你可以增加或减少任何一层的宽度。如图5所示。
深度网络在反向传播过程中也会遇到所谓的梯度消失问题。通过在中间层添加辅助分类器可以避免这种情况。此外,在训练过程中,中间层的损失将乘以因子0.3计入总损失。
由于全连接层容易出现过拟合,所以用GAP层来替代。平均池化不排除使用 dropout,这是一种在深度神经网络中克服过拟合的正则化方法。 GoogLeNet在60之后添加一个线性层和一个GAP层,通过运用转移学习技术来帮助其他层滑动自己的分类器。
5.2inception模块示例
6 .ResNet架构
一定深度后,向前反馈 convNet添加额外层会导致更高的训练误差和验证误差。性能只会随着层的增加而增加到一定深度,然后会迅速下降。在 ResNet(残差网络)论文中,作者认为这种低度拟合未必是由梯度消失问题导致的,因为当使用批处理标准化技术时也会发生这种情况。因此,他们增加了一个新的概念叫残余块。如图6所示。 ResNet团队向网络中添加了可以跳过卷积层的连接。

提示
ResNet使用标准的convNet,并添加每次可以跳过多个卷积层的连接。每条支路都有一个残余块。
在2015年的 ImageNet ILSVRC挑战赛中,胜出的是来自微软的 ResNet,误差率为3.57%。在某种意义上, ResNet就是VGG结构反复重复后更深的网络。与 VGGNet不同, ResNet有不同的深度,比如34层、50层、101层和152层。与8层的 AlexNet、19层的 VGGNet和22层的 GoogLeNet相比, ResNet多达152层 ResNet架构是一堆残余快。其主要思想是通过向神经网络添加连接来跳过多个层。每个残余块都有3×3的卷积层。在最后一个卷积层之后,添加一个GAP层。只有一个全连接层可以对1000个类别进行分类。 ResNet有不同的深度变体,例如基于 ImageNet数据集的34、50、101和152层。对于一个较深层次的网络,比如超过50层,它将使用 bottleneck特性来提高效率。本网络不使用 dropout。
需要注意的其他网络架构包括:
·网络中的网络。
·超越ResNet
·分形网络,一种没有残余的超深神经网络。
7本章小结
在这一章,我们学习了不同的CNN架构。这些模型是预先训练好的已存在的模型,且在网络架构上有所不同。每个网络都是为解决特定架构的问题而设计的。所以,这里我们描述了它们的架构差异。
我们还理解了我们自己的CNN架构(如第3章所定义)与这些高级架构的区别。在下一篇文章迁移学习中,我们将学习如何使用这些预先训练好的模型进行迁移学习。
参考资料:
1.Practical Convolutional Neural Networks: Implement advanced deep learning models using Python Paperback 王彩霞译
2.https://github.com/huanghanchi/Practical-Convolutional-Neural-Networks/blob/master/Chapter04/CNN_1.py