基于Seq2Seq的机器翻译-PyTorch
动手学深度学习笔记
- 一、机器翻译
-
- 1.下载和预处理数据集
- 2.构建词表
- 3.加载数据集
- 二、编码器-解码器架构
- 三、Seq2Seq
-
- 1.编码器
- 2.解码器
- 3.损失函数
- 4.训练
- 5.预测
- 6.预测序列的评估
一、机器翻译
机器翻译指将序列从一种语言自动翻译成另一种语言。
机器翻译的数据集与语言模型的数据集不同,它是是由源语言和目标语言的文本序列对组成的,因此两者数据集的预处理过程也不同。
1.下载和预处理数据集
下载一个双语句子对组成的“英-法”数据集,数据集中的每一行都是制表符分隔的文本序列对,序列对由英文文本序列和翻译后的法语文本序列组成。每个文本序列可以是一个句子,也可以是包含多个句子的一个段落。在这个将英语翻译成法语的机器翻译问题中,英语是源语言(source language),法语是目标语言(target language)。
import os
import torch
from d2l import torch as d2l
d2l.DATA_HUB['fra-eng'] = (d2l.DATA_URL + 'fra-eng.zip',
'94646ad1522d915e7b0f9296181140edcf86a4f5')
def read_data_nmt():
"""载入“英语-法语”数据集"""
data_dir = d2l.download_extract('fra-eng')
with open(os.path.join(data_dir, 'fra.txt'), 'r',
encoding='utf-8') as f:
return f.read()
def preprocess_nmt(text):
"""预处理“英语-法语”数据集"""
def no_space(char, prev_char):
return char in set(',.!?') and prev_char != ' '
# 使用空格替换不间断空格
# 使用小写字母替换大写字母
text = text.replace('\u202f', ' ').replace('\xa0', ' ').lower()
# 在单词和标点符号之间插入空格
out = [' ' + char if i > 0 and no_space(char, text[i - 1]) else char
for i, char in enumerate(text)]
return ''.join(out)
def tokenize_nmt(text, num_examples=None):
"""词元化“英语-法语”数据数据集"""
source, target = [], []
for i, line in enumerate(text.split('\n')):
if num_examples and i > num_examples:
break
parts = line.split('\t')
if len(parts) == 2:
source.append(parts[0].split(' '))
target.append(parts[1].split(' '))
return source, target
raw_text = read_data_nmt()
text = preprocess_nmt(raw_text)
source, target = tokenize_nmt(text)
2.构建词表
为源语言和目标语言构建两个词表,将出现次数少于2次的低频率词元视为相同的未知(“
src_vocab = d2l.Vocab(source, min_freq=2,
reserved_tokens=['' , '' , '' ])
3.加载数据集
语言模型中的序列样本都有一个固定的⻓度,无论这个样本是一个句子的一部分还是跨越了多个句子的一个片断。
通过截断(truncation)和 填充(padding)方式实现一次只处理一个小批量的文本序列。假设同一个小批量中的每个序列都应该具有相同的⻓度num_steps,如果文本序列的词元数目少于num_steps将在其末尾添加特定的“
def truncate_pad(line, num_steps, padding_token):
"""截断或填充文本序列"""
if len(line) > num_steps:
return line[:num_steps] # 截断
return line + [padding_token] * (num_steps - len(line)) # 填充
truncate_pad(src_vocab[source[0]], 10, src_vocab['' ])
定义函数可以将文本序列转换成小批量数据集用于训练。将特定的“
def build_array_nmt(lines, vocab, num_steps):
"""将机器翻译的文本序列转换成小批量"""
lines = [vocab[l] for l in lines]
lines = [l + [vocab['' ]] for l in lines]
array = torch.tensor(
[truncate_pad(l, num_steps, vocab['' ])
for l in lines])
valid_len = (array != vocab['' ]).type(torch.int32).sum(1)
return array, valid_len
定义函数返回数据迭代器,以及源语言和目标语言的两种词表。
def load_data_nmt(batch_size, num_steps, num_examples=600):
"""返回翻译数据集的迭代器和词表"""
text = preprocess_nmt(read_data_nmt())
source, target = tokenize_nmt(text, num_examples)
src_vocab = d2l.Vocab(source, min_freq=2,
reserved_tokens=['' , '' , '' ])
tgt_vocab = d2l.Vocab(target, min_freq=2,
reserved_tokens=['' , '' , '' ])
src_array, src_valid_len = build_array_nmt(source, src_vocab, num_steps)
tgt_array, tgt_valid_len = build_array_nmt(target, tgt_vocab, num_steps)
data_arrays = (src_array, src_valid_len, tgt_array, tgt_valid_len)
data_iter = d2l.load_array(data_arrays, batch_size)
return data_iter, src_vocab, tgt_vocab
尝试读取“英语-法语”数据集中的第一个小批量数据。
train_iter, src_vocab, tgt_vocab = load_data_nmt(batch_size=2, num_steps=8)
for X, X_valid_len, Y, Y_valid_len in train_iter:
print('X:', X.type(torch.int32))
print('X的有效长度:', X_valid_len)
print('Y:', Y.type(torch.int32))
print('Y的有效长度:', Y_valid_len)
break
小结
- 使用单词级词元化时的词表大小,将明显大于使用字符级词元化时的词表大小。为了缓解这一问题,我 们可以将低频词元视为相同的未知词元。
- 通过截断和填充文本序列,可以保证所有的文本序列都具有相同的⻓度,以便以小批量的方式加载。
二、编码器-解码器架构
机器翻译的输入和输出都是⻓度可变的序列。编码器-解码器(encoder-decoder) 这种架构就是专门为了处理变长输入输出而设计的。编码器 (encoder):将变长序列作为输入,并将其转换为固定形状的编码状态。解码器(decoder):将固定形状的编码状态映射到⻓度可变的序列。
- 编码器
import math
import collections
import torch
from torch import nn
from d2l import torch as d2l
class Encoder(nn.Module):
"""编码器-解码器架构的基本编码器接口"""
def __init__(self, **kwargs):
super(Encoder, self).__init__(**kwargs)
def forward(self, X, *args):
raise NotImplementedError
- 解码器
class Decoder(nn.Module):
"""编码器-解码器架构的基本解码器接口"""
def __init__(self, **kwargs):
super(Decoder, self).__init__(**kwargs)
def init_state(self, enc_outputs, *args):
raise NotImplementedError
def forward(self, X, state):
raise NotImplementedError
- 合并编码器和解码器
class EncoderDecoder(nn.Module):
"""编码器-解码器架构的基类"""
def __init__(self, encoder, decoder, **kwargs):
super(EncoderDecoder, self).__init__(**kwargs)
self.encoder = encoder
self.decoder = decoder
def forward(self, enc_X, dec_X, *args):
enc_outputs = self.encoder(enc_X, *args)
dec_state = self.decoder.init_state(enc_outputs, *args)
return self.decoder(dec_X, dec_state)
三、Seq2Seq
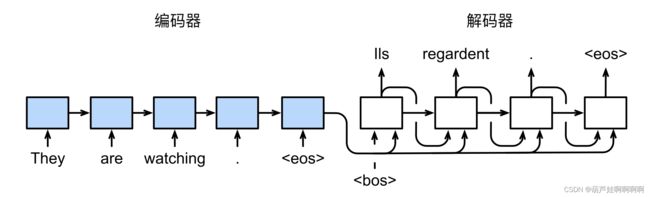
下图展示了如何在机器翻译中使用两个循环神经网络进行序列到序列学习:

循环神经网络编码器使用⻓度可变的序列作为输入,将其转换为固定形状的隐状态。为了连续生成输出序列的词元,独立的循环神经网络解码器是基于输入序列的编码信息和输出序列已经看⻅的或者生成的词元来预测下一个词元。
1.编码器
class Seq2SeqEncoder(Encoder):
"""用于序列到序列学习的循环神经网络编码器"""
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super(Seq2SeqEncoder, self).__init__(**kwargs)
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.GRU(embed_size, num_hiddens, num_layers, dropout=dropout)
def forward(self, X, *args):
# 输出'X'的形状:(batch_size,num_steps,embed_size)
X = self.embedding(X)
# 在循环神经网络模型中,第一个轴对应于时间步
X = X.permute(1, 0, 2)
# 如果未提及状态,则默认为0
output, state = self.rnn(X)
# output的形状:(num_steps,batch_size,num_hiddens)
# state[0]的形状:(num_layers,batch_size,num_hiddens)
return output, state
2.解码器
实现解码器时,直接使用编码器最后一个时间步的隐状态来初始化解码器的隐状态。(这要求使用循环神经网络实现的编码器和解码器具有相同数量的层和隐藏单元。)为进一步包含经过编码的输入序列的信息,上下文变量在所有的时间步与解码器的输入进行拼接。为了预测输出词元的概率分布,在循环神经网络解码器的最后一层使用全连接层来变换隐状态。
class Seq2SeqDecoder(Decoder):
"""用于序列到序列学习的循环神经网络解码器"""
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super(Seq2SeqDecoder, self).__init__(**kwargs)
self.embedding = nn.Embedding(vocab_size, embed_size)
# 因为拼接了上下文变量C和输入X,所以input_size = embed_size + num_hiddens
self.rnn = nn.GRU(embed_size + num_hiddens, num_hiddens, num_layers,
dropout=dropout)
self.dense = nn.Linear(num_hiddens, vocab_size)
def init_state(self, enc_outputs, *args):
return enc_outputs[1]
def forward(self, X, state):
# 输出'X'的形状:(batch_size,num_steps,embed_size)
X = self.embedding(X).permute(1, 0, 2)
# state[-1]:取最后一个隐藏层的输出
# 广播context,使其具有与X相同的num_steps,其他维度保持不变
context = state[-1].repeat(X.shape[0], 1, 1)
# 在embedding维度上拼接上下文变量C和输入X(而且batch_size和num_steps也不能拼)
X_and_context = torch.cat((X, context), 2)
output, state = self.rnn(X_and_context, state)
output = self.dense(output).permute(1, 0, 2)
# output的形状:(batch_size,num_steps,vocab_size)
# state[0]的形状:(num_layers,batch_size,num_hiddens)
return output, state
3.损失函数
在每个时间步,解码器预测了输出词元的概率分布。类似于语言模型,可以使用softmax来获得分布,并通过计算交叉熵损失函数来进行优化。但由于特定的填充词元被添加到序列的末尾,因此不同⻓度的序列可以以相同形状的小批量加载。但是,应该将填充词元的预测排除在损失函数的计算之外。
def sequence_mask(X, valid_len, value=0):
"""在序列中屏蔽不相关的项"""
maxlen = X.size(1)
# 广播torch.Size([1, X.size(1)]) < torch.Size([X.size(0), 1])
# 广播后 mask 和 X 的形状一样 torch.Size([X.size(0), X.size(1)])
mask = torch.arange(maxlen, dtype=torch.float32,
device=X.device)[None, :] < valid_len[:, None]
X[~mask] = value
return X
X = torch.tensor([[1, 2, 3], [4, 5, 6]])
sequence_mask(X, torch.tensor([1, 2]))
扩展softmax交叉熵损失函数来遮蔽不相关的预测。最初,所有预测词元的掩码都设置为1。一旦给定了有效⻓度,与填充词元对应的掩码将被设置为0。最后,将所有词元的损失乘以掩码,以过滤掉损失中填充词元产生的不相关预测。
class MaskedSoftmaxCELoss(nn.CrossEntropyLoss):
"""带遮蔽的softmax交叉熵损失函数"""
# pred的形状:(batch_size,num_steps,vocab_size)
# label的形状:(batch_size,num_steps)
# valid_len的形状:(batch_size,)
def forward(self, pred, label, valid_len):
weights = torch.ones_like(label)
weights = sequence_mask(weights, valid_len)
self.reduction='none'
unweighted_loss = super().forward(
pred.permute(0, 2, 1), label)
weighted_loss = (unweighted_loss * weights).mean(dim=1)
return weighted_loss
4.训练
训练过程中,序列开始词元(“
def train_seq2seq(net, data_iter, lr, num_epochs, tgt_vocab, device):
"""训练序列到序列模型"""
def xavier_init_weights(m):
if type(m) == nn.Linear:
nn.init.xavier_uniform_(m.weight)
if type(m) == nn.GRU:
for param in m._flat_weights_names:
if "weight" in param:
nn.init.xavier_uniform_(m._parameters[param])
net.apply(xavier_init_weights)
net.to(device)
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
loss = MaskedSoftmaxCELoss()
net.train()
animator = d2l.Animator(xlabel='epoch', ylabel='loss',
xlim=[10, num_epochs])
for epoch in range(num_epochs):
timer = d2l.Timer()
metric = d2l.Ac90cumulator(2) # 训练损失总和,词元数量
for batch in data_iter:
optimizer.zero_grad()
X, X_valid_len, Y, Y_valid_len = [x.to(device) for x in batch]
bos = torch.tensor([tgt_vocab['' ]] * Y.shape[0],
device=device).reshape(-1, 1)
dec_input = torch.cat([bos, Y[:, :-1]], 1) # 强制教学
Y_hat, _ = net(X, dec_input, X_valid_len)
l = loss(Y_hat, Y, Y_valid_len)
l.sum().backward() # 损失函数的标量进行“反向传播”
d2l.grad_clipping(net, 1)
num_tokens = Y_valid_len.sum()
optimizer.step()
with torch.no_grad():
metric.add(l.sum(), num_tokens)
if (epoch + 1) % 10 == 0:
animator.add(epoch + 1, (metric[0] / metric[1],))
print(f'loss {metric[0] / metric[1]:.3f}, {metric[1] / timer.stop():.1f} '
f'tokens/sec on {str(device)}')
在机器翻译数据集上,创建和训练一个循环神经网络“编码器-解码器”模型用于序列到序列的学习。
embed_size, num_hiddens, num_layers, dropout = 32, 32, 2, 0.1
batch_size, num_steps = 64, 10
lr, num_epochs, device = 0.005, 300, d2l.try_gpu()
train_iter, src_vocab, tgt_vocab = d2l.load_data_nmt(batch_size, num_steps)
encoder = Seq2SeqEncoder(len(src_vocab), embed_size, num_hiddens, num_layers,
dropout)
decoder = Seq2SeqDecoder(len(tgt_vocab), embed_size, num_hiddens, num_layers,
dropout)
net = d2l.EncoderDecoder(encoder, decoder)
train_seq2seq(net, train_iter, lr, num_epochs, tgt_vocab, device)
5.预测
为了采用一个接着一个词元的方式预测输出序列,每个解码器当前时间步的输入都将来自于前一时间步的预测词元。与训练类似,序列开始词元(“
def predict_seq2seq(net, src_sentence, src_vocab, tgt_vocab, num_steps,
device, save_attention_weights=False):
"""序列到序列模型的预测"""
# 在预测时将net设置为评估模式
net.eval()
src_tokens = src_vocab[src_sentence.lower().split(' ')] + [
src_vocab['' ]]
enc_valid_len = torch.tensor([len(src_tokens)], device=device)
src_tokens = d2l.truncate_pad(src_tokens, num_steps, src_vocab['' ])
# 添加批量轴
enc_X = torch.unsqueeze(
torch.tensor(src_tokens, dtype=torch.long, device=device), dim=0)
enc_outputs = net.encoder(enc_X, enc_valid_len)
dec_state = net.decoder.init_state(enc_outputs, enc_valid_len)
# 添加批量轴
dec_X = torch.unsqueeze(torch.tensor(
[tgt_vocab['' ]], dtype=torch.long, device=device), dim=0)
output_seq, attention_weight_seq = [], []
for _ in range(num_steps):
Y, dec_state = net.decoder(dec_X, dec_state)
# 使用具有预测最高可能性的词元,作为解码器在下一时间步的输入
dec_X = Y.argmax(dim=2)
pred = dec_X.squeeze(dim=0).type(torch.int32).item()
# 保存注意力权重
if save_attention_weights:
attention_weight_seq.append(net.decoder.attention_weights)
# 一旦序列结束词元被预测,输出序列的生成就完成了
if pred == tgt_vocab['' ]:
break
output_seq.append(pred)
return ' '.join(tgt_vocab.to_tokens(output_seq)), attention_weight_seq
6.预测序列的评估
- BLEU是一种常用的评估方法,它通过测量预测序列和标签序列之间的n元语法的匹配度来评估预测。
def bleu(pred_seq, label_seq, k):
"""计算BLEU"""
pred_tokens, label_tokens = pred_seq.split(' '), label_seq.split(' ')
len_pred, len_label = len(pred_tokens), len(label_tokens)
score = math.exp(min(0, 1 - len_label / len_pred))
for n in range(1, k + 1):
num_matches, label_subs = 0, collections.defaultdict(int)
for i in range(len_label - n + 1):
label_subs[' '.join(label_tokens[i: i + n])] += 1
for i in range(len_pred - n + 1):
if label_subs[' '.join(pred_tokens[i: i + n])] > 0:
num_matches += 1
label_subs[' '.join(pred_tokens[i: i + n])] -= 1
score *= math.pow(num_matches / (len_pred - n + 1), math.pow(0.5, n))
return score
- 利用训练好的循环神经网络“编码器-解码器”模型,将几个英语句子翻译成法语,并计算BLEU的最终结果。
engs = ['go .', "i lost .", 'he\'s calm .', 'i\'m home .']
fras = ['va !', 'j\'ai perdu .', 'il est calme .', 'je suis chez moi .']
for eng, fra in zip(engs, fras):
translation, attention_weight_seq = predict_seq2seq(
net, eng, src_vocab, tgt_vocab, num_steps, device)
print(f'{eng} => {translation}, bleu {bleu(translation, fra, k=2):.3f}')