8.Paper小结——《VFL: A Verifiable Federated Learning withPrivacy-Preserving for Big Data...》
题目:《VFL: A Verififiable Federated Learning with Privacy-Preserving for Big Data in Industrial IoT》
——VFL:一种可验证的基于隐私的联邦学习
0.Abstract
由于大数据具有较强的分析能力,深度学习已被广泛应用于工业物联网中收集到的数据的建模。然而,对于隐私问题,传统的数据收集集中式学习并不适用于对训练集敏感的工业场景。近年来,联邦学习受到了广泛的关注,因为它只依赖梯度聚合而不访问训练集。但现有的研究表明,共享梯度仍然保留了训练集的敏感信息。更糟糕的是,恶意聚合服务器可能会返回伪造的聚合梯度。在本文中,我们提出了VFL,可验证的具有隐私保护的联邦学习。具体来说,我们使用拉格朗日插值来精心设置插值点,以验证聚合梯度的正确性。与现有方案相比,无论参与者数量如何,VFL的验证开销都保持不变。此外,我们使用致盲技术来保护参与者提交的梯度的隐私。如果n个参与者中的n-2不超过与聚合服务器串通,VFL可以保证其他参与者的加密梯度不会被倒置。实验结果验证了该VFL框架的实际性能,具有较高的精度和效率。
1.Introduction
深度学习渴望提高数据,特别是提高其准确性,因此在不同的企业和事业单位之间收集或共享工业数据是一种常见的做法。但这些共享的工业数据包含敏感信息[5]、[16]、[39],如账户信息、病例历史等。一旦这些数据被共享,客户端就不能限制使用它的目的。例如,在医疗保健系统中,患者最不愿意让未经授权的第三方访问他们的诊断。
此外,也有加强数据隐私以防止滥用它的趋势。2018年5月25日,欧盟执行了《通用数据保护条例》(GDPR)。它强制企业在隐私协议中使用明确的语言,并保留客户删除或撤回其数据的权利。事实上,这些法律要求数据以孤岛的形式存储。无法共享数据使得在不收集丰富的数据的情况下训练一个准确的模型非常困难。对于医疗机构,它们都只能在有限的本地数据上训练模型,该模型的准确性不高,甚至可能不适用于处理来自不同机构的输入,这些输入不属于训练模型学习到的数据特征分布。因此,隐私问题和立法为深度学习有效部署到大规模协作工业应用中提出了新的要求。
为了解决由法律造成的工业数据孤岛问题,并继续合法地利用它们,已经提出了一些安全的集中式深度学习方案。在这种方案中,收集到的数据被预先加密的[25],或用噪声[26]预掩蔽。然而,由于神经网络需要非线性计算,因此很难在加密的数据集[30],[23]上使用深度学习。然而,训练噪声的数据通常伴随着精度下降的权衡。此外,安全集中式深度学习的计算开销使得适用于常用的以实现高精度的大规模工业数据和深度模型结构极具挑战性。
除了安全的集中深度学习,谷歌还在2016年[7],[28]提出了一个分布式深度学习框架,[27],[28]。联邦学习只需要参与者共享他们的梯度来进行聚合,而不是直接共享本地化数据。其主要好处是在本地化数据不可访问时保护它们的隐私。与集中式深度学习相比,联邦学习避免了加密等训练集的处理,提高了效率。因此,联邦学习受到了学术界和工业界的广泛关注。
虽然联邦学习极大地减少了隐私泄露的表面,但它仍然面临着从根本上防止隐私泄露的挑战。Phong等人。[9]证明了聚合服务器可以通过数值方法逼近局部数据。Wang等人。[11]在聚合服务器上设计了mGAN-AI(生成对抗性网络)模型,以恢复目标参与者的原始图像。在明文中共享的梯度是造成这些隐私问题的主要原因。最近,人们提出了基于同态加密[35]的方案,其中梯度以密文的形式聚合。但是参与者使用相同的密钥,如果聚合服务器与任何参与者共谋以拥有该密钥,则密文就不再有意义。
除了隐私问题外,大多数方案在无意中忽略了对聚合结果[6]的正确性的验证。在某些非法利益的驱动下,聚合服务器可以减少聚合操作以节省计算成本[12],或伪造聚合结果以影响模型更新。更糟糕的是,好奇的聚合服务器可以小心地将精心制作的结果返回给参与者,以分析参与者上传数据的统计特征,并引诱参与者无意中暴露更敏感的信息[11]。因此,应始终考虑到对聚合结果的有效验证。
在本文中,我们提出了VFL,一种可验证的隐私保护联邦学习,以实现高效和安全的工业智能模型训练。具体来说,我们使用拉格朗日插值和致盲技术来实现安全的梯度聚集。同时,我们设计了一个有效的验证机制,其中参与者可以极大的概率检测伪造的结果。主要贡献:
- 基于拉格朗日插值的特性,提出了一种验证聚合结果正确性的验证机制。在我们的方案中,每个参与者都可以独立地、有效地检测到伪造的结果。与现有的方案相比,我们的验证机制的计算开销并没有随着参与者数量的增加而增加。我们的验证机制还要求减少对每个参与者的开销。
- 我们结合拉格朗日插值和致盲技术来实现梯度的安全聚集。联合模型和梯度不受聚合服务器的保护。此外,如果n个参与者与聚合服务器串通不超过n-2,VFL可以保证其他参与者的梯度不会被泄露。
- 我们为我们的方案提供了一个全面的安全分析,它证明了训练集和模型的安全性以及VFL框架的可验证性。我们使用多层感知器(MLP)在MNIST数据集上评估我们的方案。实验结果表明,该方案具有较高的准确性和效率,验证开销是参与者可以接受的。
2.Related Work
安全训练可分为集中式和分布式两类。在本节中,我们将相应地简要描述它们。
- 为了保护训练集的隐私,李等人[36],在云计算中提出了一种多密钥隐私保护的深度学习,实现了多密钥同态加密[42]和双解密机制[38]的转换,使服务器能够在密文集上对模型进行训练。
- 李等人。[8]使用同态加密和微分隐私技术在多个数据源上实现了朴素贝叶斯分类器。
- Xu等人[26],提出了一种差分隐私GAN方案,该方案通过添加精心设计的噪声,通过GANs实现不同的隐私。该方案根据训练任务生成合成数据,而不是直接使用真实的训练数据。
- Mohassel等人。[17]提出了基于ABY混合协议[32]和无意识传输[34]的SecureML系统,参与者将数据分割,分别发送到两个非共谋的服务器,通过安全多方计算实现随机梯度下降(SGD)算法。
- Agrawal等人。[21]利用了DNN训练的关键组成部分,在双方计算中改进了最先进的DNN训练,提高了集中训练的效率和准确性。
安全集中培训要求参与者提前处理训练集,如加密、添加噪声或分割,并对处理后的数据进行训练。然而,由于神经网络模型的复杂性,服务器对处理的数据训练效率低下。因此,安全的集中训练不适合大规模的工业应用。
- Shokri等人。[19]首先提出了协作深度学习框架,其中参与者共享梯度并异步更新模型。
- 谷歌将该框架扩展到并行场景,并提出了联邦学习[7]、[27]、[28],要求参与者同步上传梯度以进行聚合。这两种方案可以防止服务器直接访问训练集。现有研究显示,这仍可能导致[11]。
- Phone等人。[9]指出,训练集可以通过数值方法从梯度中恢复,并提出采用加性同态加密来实现安全聚合。
- 李等人。[10]利用一次性掩码技术改进了加性同态加密。培训者和引入的服务器辅助人员通过多个交互完成了对密码文集的训练。
- 周等人。[15]在物联网(物联网)上部署了联邦学习。该方案不仅保护了物联网设备的数据安全,而且还提高了训练效率和模型精度。
- Abadi等人。[29]提出了一种具有差分隐私的深度学习方案,其中参与者在梯度中加入拉普拉斯噪声以满足差分隐私。
虽然上述方案实现了安全的梯度聚合,但它们没有考虑对聚合结果的验证。 - Ma等人。[12]专注于可验证的联邦学习,他们利用双线性聚合签名[45]来验证聚合结果的正确性。然而,所有的参与者都必须加入验证过程。当参与者数量较多时,验证机制会导致成本较高。
- Xu等人。[22]采用同态哈希函数和Shamir秘密共享,实现了安全的梯度聚合和验证。该方案还支持参与者的下降,但不考虑保护模型。聚合服务器可以获得最终的模型,但在实际操作中,只有参与者拥有该模型的所有权。
- Zheng等人。[13]提出了Helen框架,该框架引入了一个安全的多方计算协议SPDZ[31]来验证结果,并采用多密钥同态加密对线性模型进行安全的协同训练。然而,它是专门为线性模型设计的,因此不支持用非线性层训练模型。
- Zhang等人。[37]利用哈希函数[44]和Paillier加密[43]来保护梯度,并验证聚合结果的正确性。但Paillier加密给参与者带来了很高的成本。而该方案的验证开销也随着参与者人数的增加而增加。
在安全的分布式训练方案中,很少有人考虑到联邦学习的可验证性。对于现有的可验证方案,它们在计算开销或所支持的模型类型方面存在局限性。因此,具有非线性模型支持的高效和可验证的联邦学习仍然是一个紧迫的问题。
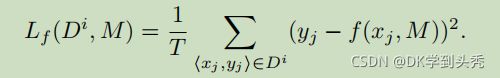
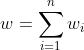 。
。
通过上述拉格朗日插值公式,我们可以得出结论,对于一个n度多项式函数,选择任意n个+1点都可以恢复函数表达式。
4.OUR PROPOSED VFL SCHEME
本节首先概述了VFL框架,然后详细介绍了其过程。
- PKG:PKG是为了初始化神经网络模型,生成密钥和参数,并将其分配给参与者。
- 参与者:我们的方案是为物联网构建的,参与者由一组终端设备播放:每个终端设备都包含少量数据或数据多样性较低。参与者的目标是通过联邦学习来合作训练高质量的神经网络模型。在每一轮联邦学习中,每个参与者都在本地训练模型,加密自己的梯度,并将其上传到聚合服务器。此外,他们还从聚合服务器接收聚合的密文,验证它的正确性,并更新模型。我们假设参与者是诚实和好奇的,这意味着他们将上传正确的梯度值。但是,一些参与者可能会与聚合服务器串通,以获得其他参与者的梯度。
- 聚合服务器:在每一轮联邦学习中,聚合服务器聚合上传的密文,然后将结果分发给每个参与者。我们认为聚合服务器是恶意的。它可能会试图通过接收到的渐变来窃取参与者的隐私信息,更糟糕的是,伪造聚合的密文以影响模型更新。
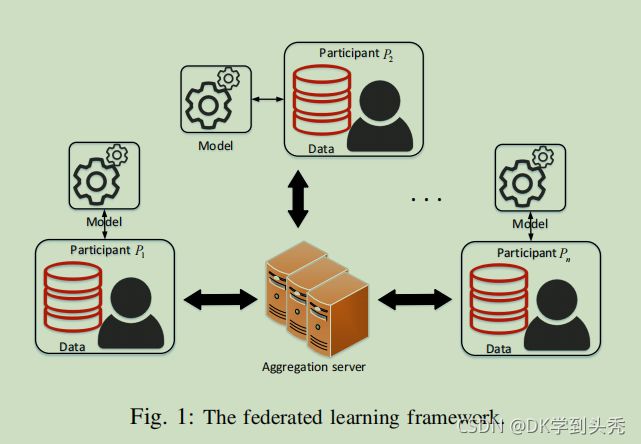
如图2。VFL的过程分为初始化阶段、模型训练阶段、聚合阶段、更新阶段四个阶段。我们在图3中给出了一个不同阶段的简单总结。而详细信息将推迟到下一节的下一节。在图3中红色部分表示初始化阶段,蓝色部分表示模型训练阶段,绿色部分为聚合阶段,紫色部分为更新阶段。
- 初始化阶段:PKG初始化联合模型,生成并分发密钥和参数给每个参与者。
- 模型训练阶段:n名参与者并行地对模型进行局部训练,并对计算出的梯度进行加密,然后将加密后的梯度上传到聚合服务器上进行聚合。
- 聚合阶段:聚合服务器聚合接收到的加密梯度,并将结果返回给所有参与者。
- 更新阶段:每个参与者首先验证结果的正确性。如果结果正确,他们将解密聚合的密文,并在本地更新模型。否则,中止更新。
-------------------------------------------------------------------
B. Initialization Phase
初始化阶段主要由PKG指导,它在局部生成参数并将其分配给每个参与者。为简单起见,我们假设有n个参与者由Pi(i∈N)表示,其中集合N={1,2,...,n}(n≥2)。在VFL框架中,PKG需要生成和分发以下参数。
- 根据参与者同意的神经网络结构,PKG随机生成一个学习率η并初始化模型参数m。此外,所有参与者得到m个正整数g1,g2,g2,...,gm是两两互素gcd(gi,gj)=1(i≠j),而且它们足够大,可以避免产生溢出错误,其中m(m≥3)是我们方案的安全参数。我们定义了
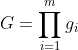 。这些参数将用于打包数据。
。这些参数将用于打包数据。 - PKG随机生成两个不交叉的常数序列{ai|i=1,2,...,m}和{bi|i=1,2,...,m}。这两个常数序列将被用作插值点来处理参与者的梯度。
- PKG将参数Ai(i∈N)和
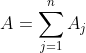 发送到Pi(i∈N),其中参数Ai和A的规格与参数M相同。在我们的方案中,参数A用于帮助参与者验证聚合结果的正确性。
发送到Pi(i∈N),其中参数Ai和A的规格与参数M相同。在我们的方案中,参数A用于帮助参与者验证聚合结果的正确性。 - PKG向每个参与者发送两个种子序列和相同的伪随机生成器PRG(·),其中Pi接收到的种子序列为
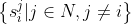 和
和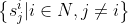 。显然,参与者Pi和Pj(i≠j)有两个相同的种子
。显然,参与者Pi和Pj(i≠j)有两个相同的种子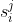 和
和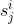 。这组参数将用于生成伪随机数来致盲参与者的梯度。
。这组参数将用于生成伪随机数来致盲参与者的梯度。

请注意,除了参数g1、g2、...,gm和G外,所有其他参数和伪随机生成器都对聚合服务器保密。
-------------------------------------------------------------------
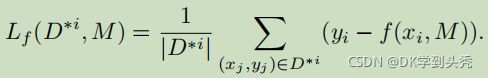


....
显然,由于包装的原因,[[wi]]的大小与wi相同。因此,我们的方案具有与原始的联邦学习[7]相同的通信开销。最后,参与者将他们的密文发送到聚合服务器。

在本文中,我们提出了一个隐私保护和可验证的工业智能联邦学习框架VFL。VFL框架 利用拉格朗日插值来设置插值点,这使每个参与者能够有效地验证聚合结果的正确性。 与现有的可验证的联邦学习方案相比,我们的真实验证机制的计算开销并没有随着参与者数量的增加而增加。同时,我们利用致盲技术来保护训练后的模型和参与者的私人梯度。如果n个参与者中的n-2不超过与聚合服务器串通,VFL可以保证其他参与者的加密梯度不会被倒置。在MNIST数据集上的实验结果表明,VFL在验证和总开销方面具有优势。在未来的工作中,我们计划研究更复杂的神经网络和具有更丰富的分类标签的数据。
总结:
本文用:
致盲技术------>保护训练后的模型和参与者的私人梯度
拉格朗日插值来设置插值点------>验证聚合结果的正确性
用CRT------>降维 压缩模型,减少通信开销