2020 中科院 CVPR : Context-Aware Attention Network for Image-Text Retrieval
0.摘要
跨模态检索主要依赖于图像文本对的联合嵌入学习和相似度度量,以往的研究很少同时考虑模态间的语义联系和单一模态的语义相关性,本方法简称CAAN,通过聚合全局上下文选择性地关注关键片段,即同时利用全局模态间的对齐和单一模态内的联系来挖掘潜在语义关系,考虑图像与句子在检索过程中的相互作用,单一模态内的相关性是由区域-单词对齐的二阶注意度得到的,而不是直观地比较原始特征之间的距离。实验在Flickr30K和MS-COCO上进行。
1.介绍
在描述一个目标图像时,人们倾向于经常引用突出的物体,并描述它们的属性和动作。基于这种观察,一些方法将图像中的区域和句子中的单词映射到一个潜在空间,并探索它们之间的对齐。虽然验证了探索区域-单词对应关系的有效性,但他们忽略了每个地方片段的不同重要性。最近,基于注意力的方法已经开始采取不同的方式关注特定区域和单词,并在图像文本检索任务中显示出非常有前景的结果。SCAN是一种典型的基于来自另一种模态的片段来确定片段重要性的算法,目的是发现完整的区域-单词对齐。然而,它忽略了单个模态片段之间的语义关联(共有或专有属性、类别、场景等)。此外,一些研究者提出了使用预先训练的神经场景图生成器学习视觉关系特征或基于模态内关系消除无关片段的方法,在一定程度上缓解了SCAN的上述问题。
然而,大多数基于注意力的方法忽略了一个单词或一个区域在不同的全局语境中可能有不同的语义。具体来说,全局语境指的是两种模态之间(跨模态语境)的相互作用和对齐,以及单一模态下的语义总结和关联(intra-modal上下文)。如下图所示,人们有时会根据图片中的对象之间的关系自动总结高级语义概念(如水果),有时在图片中分别描述每个物体(如菠萝、香蕉、橘子)。因此,同时考虑模态内和模态间的上下文,在适应各种上下文的情况下进行图文双向检索是有利的。

(说明了不同语境下的自适应检索过程。一幅图像用两个不同的句子进行注释。(a)中用绿色标记的区域对应左边句子中的“水果”。然而,它们对应于右边句子中的“菠萝”、“香蕉”和“橘子”,在(b)中分别用蓝色、黄色和红色标出。)
为了解决上述问题,我们首先提出了一个统一的上下文感知注意网络(CAAN),它可以基于全局上下文选择性地关注局部片段。它将图像文本检索作为一个注意过程,将模态间注意(发现单词-区域对之间所有可能的对齐)和模态内注意(学习单个模态片段的语义关联)结合起来。利用上下文感知的注意,该模型可以同时执行图像辅助的文本注意和文本辅助的视觉注意。因此,为片段分配的注意力分数聚合了上下文信息
我们进一步提出基于语义的注意(semantic -based Attention, SA)来探索潜在的模态内相关性,而不是直观地使用基于特征的相似性。我们基于语义的注意被表述为区域-单词对齐的二级注意,它明确地考虑了形态之间的相互作用,有效地利用区域-词关系来推断单一形态下的语义关联(比如水果和香蕉)。在检索过程中,图像文本对中的综合上下文可以直接影响彼此的响应计算。因此,它根据给定的上下文实现了实际的自适应匹配。
综上所述,该论文工作的主要贡献如下:
1.我们提出了一个统一的上下文感知注意网络,可以从全局的角度根据给定的上下文自适应地选择信息片段,包括单一模态的语义关联以及区域和单词之间可能的对齐。
2.我们提出了基于语义的注意来捕捉潜在的模态内相关性。它是区域词对齐的可解释二级注意。
3.我们在两个基准数据集Flickr30K[46]和MS-COCO[24]上对我们提出的模型进行了评估,并取得了较好的结果。
2.相关方法
现有的图像文本检索方法要么将完整的图像和完整的句子嵌入到共享空间中,要么考虑局部片段之间的潜在对应关系。最近的一些方法进一步采用了关注机制,聚焦于最重要的局部片段。
2.1.跨模态检索
基于全局嵌入的方法。
一个常见的解决方案是学习图像和句子的联合嵌入。最近的作品集中在目标函数的设计上。虽然这些方法已经取得了一定的成功,但由于缺乏对图像和句子之间的细粒度相互作用的详细理解,图像-文本检索仍然具有挑战性。
基于局部片段的方法
与上述方法不同的是,许多工作都致力于解决基于局部片段的图像文本检索问题。在本文中,我们采用相同的基于局部片段的策略,在更细的层次上考虑图像和文本的内容,而不是使用粗略的概述。
2.2.注意力机制
注意力机制近年来得到了广泛的应用,由于其强大的功能,人们在图像文本检索中提出了许多基于注意的方法。
3.方法
在本节中,我们将概述我们提出的上下文感知注意网络(CAAN)。如下图所示,给定一个图像-文本对,我们首先将图像中的区域和句子中的单词嵌入到共享空间中。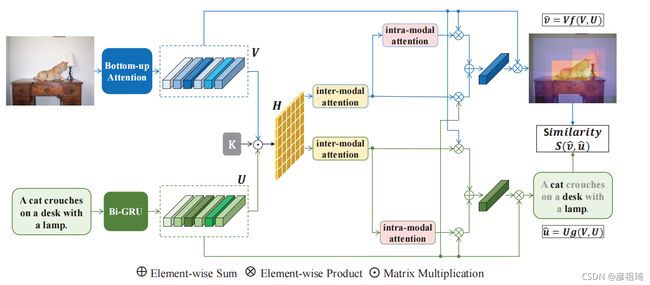
(我们提出的情境感知注意网络(CAAN)的模型。它由三个模块组成,(a)图像中的区域提取和编码句子中的单词,(b)适应动态全局上下文的上下文感知注意,(c)具有双向排序损失的最终表示的联合优化。)
具体地说,利用自底向上的注意力来生成图像区域及其表示。同时,我们根据句子的上下文在句子中编码单词。在关联模块中,我们对提取的局部片段特征进行上下文感知的注意网络,这能捕获在区域-单词对中的语义对齐,和单一模态中的语义联系。最后,对模型使用图像-文本匹配损失进行训练。接下来,我们将从以下几个方面详细介绍我们提出的方法:1)视觉表示,2)文本表示,3)用于全局上下文聚合的上下文感知注意网络,4)优化图像-文本检索的目标函数。
3.1.视觉表示
对于一幅图像,我们观察到人们倾向于频繁地提及突出的物体,描述他们的行为和属性等。我们不再从像素级图像中提取全局CNN特征,而是关注局部区域,并利用自底向上的注意力。我们利用Faster R-CNN模型结合ResNet-101分两个阶段检测每幅图像中的目标和其他显著区域,这是在Visual Genome[18]上预先训练的。在第一阶段,模型使用带有IoU阈值的贪婪非最大抑制来选择排名靠前的方框方案,在第二阶段中,通过平均池卷积层得到这些方框的特征。这些特性用于预测实例类和属性类,以及改进边界框。对于每个区域i, xi表示2048维的原始均值池卷积特征。最后的特征vi通过xi的线性映射转化为d维向量,如下所示:
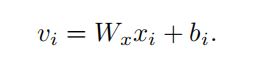
因此,目标图像v可以表示为所选择的具有最高类检测置信度的roi的一组特征。
3.2.文本表示
为了发现区域-单词的对应关系,将句子中的词映射到与图像区域相同的d维空间。不再单独处理每个单词,我们考虑一次性对单词及其上下文进行编码。给定独热编码W = {w1, ..., wm}表示一个句子中输入的m个单词,我们首先把它们嵌入到一个300维向量通过单词嵌入层,xi=We*wi,这里We是一个学习的端到端的参数矩阵。然后我们将向量xi输入双向GRU,写法为:

分别表示正向和反向的隐藏状态,最后词嵌入ui是双向隐藏状态的平均值,它收集了以单词wi为中心的上下文:
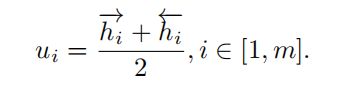
3.3.上下文注意力
3.3.1.Formulation
注意机制的目的是关注相应任务中最相关的信息,而不是平等地使用所有可获得的信息。我们首先提供了一个针对跨模态检索问题设计的注意机制的一般公式。对于图像v和文本u,它们的特征映射分别为V = [v1, ..., vn]和U = [u1, ..., um]。
我们将图像-文本检索的注意过程定义为:
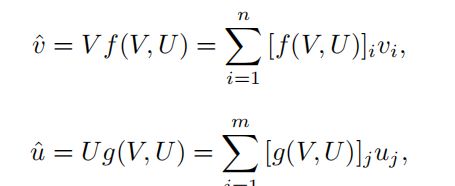
其中f(·)和g(·)是注意函数,分别计算每个局部片段vi和uj的分数 。最终得到的图像和文本特征vˆ和uˆ作为局部片段的加权和。我们计算目标图像和文本的区域-单词对之间的相似性。相似矩阵H为:
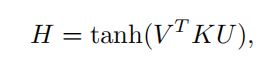

其中K∈Rd×d是权矩阵。Attentive Pooling Networks基于每个片段的重要性表示为其与另一种形态的片段的最大相似性的假设,执行列方向和行方向的最大池化层。当f(V, U)在H上应用逐行max池操作后成为softmax计算时,它是所提出的注意过程的替代版本。此外,我们不仅计算相似度矩阵,而且利用它作为一个特征来预测注意力映射。更具体地说,片段的重要性得分由所有相关片段决定,考虑到单个模态中的模态内相关性和所有区域-词对之间的模态间对齐。基于考虑,区域归一化注意函数f(V, U)可表示为:
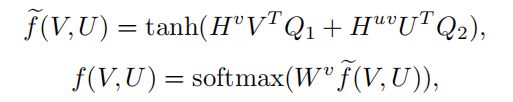
其中Wv∈Rz是一个投影向量。Q1、Q2 ∈ Rd×z是参数矩阵(做维数融合)。Hv∈Rn×n是捕获区域模态内相关性的注意矩阵。Huv∈Rn×m是单词到区域重新加权的注意矩阵。同理,单词的归一化注意函数g(V, U)为:
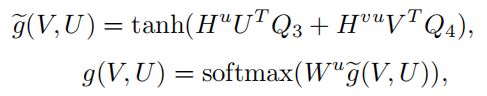
Q3、Q4 ∈Rd×z和Wu∈Rz是可以学习的参数。设计的注意功能f(V, U)和g(V, U)根据全局语境选择性地关注信息片段,同时应用了模态间注意和模态内注意。
3.3.2跨模态注意Huv,Hvu
矩阵H计算局部区域-词对的相似度。我们将相似性阈值设为零,并将其归一化以获得对齐分数。单词到区域的注意力Huv公式如下
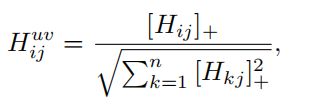
其中[x]+≡max(0, x)。词到区域注意矩阵Huv中的每个元素Hi,j uv代表了局部片段区域vi和词uj的相对成对对应关系。相似地,区域到词的注意Hvu计算为:
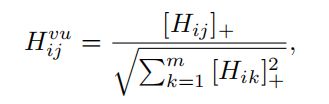
Huv和Hvu都通过对齐区域和单词来推断图像和句子之间的精细相互作用。
3.3.3模态内注意Hv,Hu
接下来,将讨论两个版本的Hv和Hu,它从两个不同的角度模拟了模态内相关性。
基于特征的关注(FA)
测量模态内相关性的一个自然选择是计算特征相似度。即模态内注意矩阵Hv和Hu可定义为:
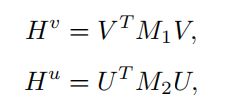
其中M1, M2∈Rd×d是学习到的权重参数 ,当它们等于单位矩阵时,Hv和Hu中的元素表示局部片段之间以单一模态的点积相似性。一个学过的矩阵和它的转置的矩阵乘积是另一个版本,它将U投射到一个新的空间。它不仅允许计算出的模态内注意矩阵表示归一化特征之间的余弦相似度,而且还保留了模型的容量。但是,它忽略了模态中的语义总结(模态上下文)因不同的查询而不同。因此,单模态片段间的语义关联挖掘应采用交互方式进行。
基于语义的关注(SA)
考虑到检索过程中两种模态之间的相互作用和信息传递,我们提出了基于语义的注意,以探索基于区域-词关系的模态内关联。我们使用可解释的跨模态对齐的二级注意。SA的详细过程如下图所示。

(详细说明了基于语义的模态内注意过程。模态内亲和矩阵Hv和Hu分别用于捕获潜在的区域与区域和词与词的关系。它们是通过充分利用跨模态对齐来计算的。)
模态内注意矩阵Hv和Hu定义为:

其中norm(·)表示对输入向量进行l2归一化运算。
作为跨模态注意矩阵Huv的第i行,Huvi.对于给定的vi对于所有词被认为是词到区域的亲和分布或者响应向量。它度量了vi与整个单词特征集{u1, ..., um}的距离,因此,每个元素Hv ij是两个区域-词响应向量Huv i和Huv j的余弦相似度。模态内注意矩阵Hv计算任意两个亲和分布的成对关系。

(可见L2范式归一化之后,X*YT就是两个向量的余弦相似度)
模态内总结和关联在检索过程中与全局上下文相关,并隐含统计信息和语义信息,例如共存、依赖和联系。当两个区域vi和vj对同一句话有相似的反应时,它们被认为是高度相关的一对。因此,SA在相对于区域vj分配注意分数的过程中,更多地关注区域vi。它综合考虑了两种反应的相似性,模拟了两种模态之间的片段的相似度的运动的关系。
综上所述,自适应模态内注意过程是由全局语义信息驱动的。它需要基于给定的上下文而不是原始的上下文无关的特征来区分语义。
3.4.目标函数
基于铰链的双向排序损失是目前图文检索中最常用的目标函数,其表达式为:

其中m是边际约束, (ˆv, uˆ−)和(ˆv−,uˆ)是负对,S(·)是一个匹配函数,我们在实验中将其定义为内积。目标函数试图将正的图像-文本对拉近并把负的拉远。

(理解Hinge Loss (折页损失函数、铰链损失函数)_Du_Shuang的博客-CSDN博客)
尽管在跨模态任务中得到了广泛的应用,但由于随机三联体采样过程,它存在着高冗余和收敛速度慢的问题。为了提高计算效率,通常采用具有最难负的双向排序损失,而不是在一个小批中对所有负对进行求和。它关注的是最坚硬的样本,也就是最接近正数对的负样本。给定一个正数对(ˆv, uˆ),最难的负数是这样表述的:
![]()
![]()
arg max f(x): 当f(x)取最大值时,x的取值
arg min f(x):当f(x)取最小值时,x的取值
因此,具有最难负的双向排序损失记为:
