RISC-V详细介绍
文章目录
- RISC-V指令集介绍
-
- 什么是RISC-V
- RISC-V诞生的背景
-
- ISA霸权
- 摩尔定律的穷途末路
- 穷困潦倒的学者
- 不断增长的指令数量
- RISC-V架构设计思想
-
- 如何设计一个好的ISA
- RISC-V之RV32I
-
- 四个典型特点
- RISC-V之乘除法指令
-
- 指令格式
- 用乘法代替常数除法
- RISC-V之RV64
- RISC-V的特权架构
-
- 机器模式
- 监管者模式
- 扩展指令集
- AI中涉及的运算操作
-
- 机器学习
- 深度学习
- 现有的AI指令集或其他底层解决方案
-
- TPU解决方案
- X86
- 现有AI芯片
- 现有AI软件与芯片设计关系详解
- 参考资料
RISC-V指令集介绍
什么是RISC-V
RISC-V(发音为“risk-five”)是一个基于精简指令集(RISC)原则的开源指令集架构(ISA)。
与大多数指令集相比,RISC-V指令集可以自由地用于任何目的,允许任何人设计、制造和销售RISC-V芯片和软件。虽然这不是第一个开源指令集,但它具有重要意义,因为其设计使其适用于现代计算设备(如仓库规模云计算机、高端移动电话和微小嵌入式系统)。设计者考虑到了这些用途中的性能与功率效率。该指令集还具有众多支持的软件,这解决了新指令集通常的弱点。
该项目2010年始于加州大学伯克利分校,但许多贡献者是该大学以外的志愿者和行业工作者。
RISC-V指令集的设计考虑了小型、快速、低功耗的现实情况来实做,但并没有对特定的微架构做过度的设计。
简而言之,RISC-V是一个ISA
RISC-V诞生的背景
ISA霸权
微处理器的开放指令集有望重塑计算,并引入新的、更强大的功能。
现代计算机依靠许多元件来提供高速和高性能,但是很少有比一台精简的指令集计算机(通常称为RISC)发挥更大作用的了。尽管指令集体系结构(ISA)具有不同的形状和形式-并且它支持多种系统和设备-但存在一个共同点,与复合指令集计算机(CISC)相比,RISC允许微处理器以更少的每指令周期(CPI)运行。
当然,ISA是计算的核心。加州大学伯克利分校计算机科学教授、ACM A.M.图灵奖获得者戴夫·帕特森(Dave Patterson)说:“这是允许硬件和软件进行通信的基本词汇,他差不多算是创造了这个术语,并开发了早期的RISC计算模型。在过去的几十年里,英特尔和ARM这两大实体基本上控制了ISA。他们的专利微处理器可以从笔记本电脑到云服务器,从智能手机到物联网(IoT)设备的所有设备运行。如今,很难找到没有英特尔或ARM处理器的计算设备。
摩尔定律的穷途末路
RISC-V的推出与半导体行业的其他重大变化不谋而合。CMOS晶体管的缩放速度正在放缓,这已不是秘密。即使最近在设计上取得了突破,将密度和性能提升到了新的水平,戈登·摩尔(Gordon Moore)关于每两年将晶体管倍增的长期预测——“摩尔定律”(Moore’s Law)也不再成立。随着半导体进展缓慢,而性能需求持续增长,设计更先进的计算设备和燃料创新的能力受到威胁。Patterson解释说:“向前看,逻辑路径是为应用领域的微处理器上的基本指令集添加扩展。”。
RISC-V的吸引力是不可否认的。一个通用的ISA意味着ISA的不同实现和用例可以利用相同的核心软件堆栈,从而最小化移植到编译器、操作系统和其他软件的工作。RISC- v的主要优点不是它是RISC的一个新的变种或迭代,而是它是一个开放的ISA。因此,人们期望该模型将产生将RISC-V置于商业地图上所需的软件堆栈。然而,与此同时,也有一种担忧,即给用户改变ISA的能力将导致RISC-V软件生态系统的分裂。
穷困潦倒的学者
Asanovíc和Patterson于2010年开始在伯克利的并行计算实验室(Par Lab)研究第五代RISC指令集。该项目的诞生源于对专有ISA缺乏灵活性的失望。Patterson回忆说:“我们无法做一些我们想做的重新搜索。两人瞄准了一个长期存在的行业问题:无法为特定目的定制芯片。这项倡议是基于他们自己的需要。“由于我们无法获得英特尔或ARM使用或修改其专有指令集的许可,我们决定为自己的研究开发自己的指令集,并帮助其他学者的研究。”
不断增长的指令数量
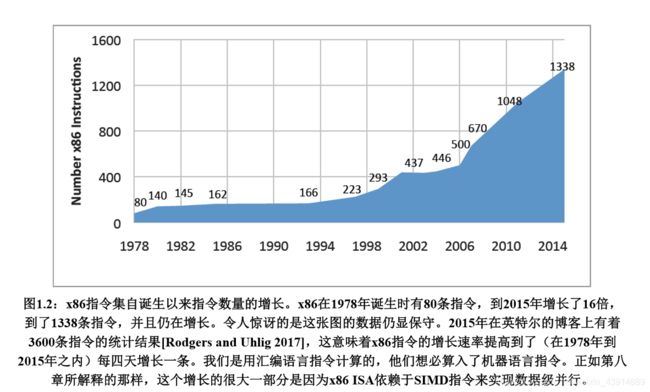
RISC-V架构设计思想
如何设计一个好的ISA
在介绍 RISC-V 这个 ISA 之前,了解计算机架构师在设计 ISA 时的基本原则和必须做 出的权衡是有用的。如下的列表列出了七种衡量标准。页边放置了对应的七个图标,以突 出显示 RISC-V 在随后章节中应对它们的实例。(印刷版的封底有所有图标的图例。)
⚫ 成本(美元硬币)
⚫ 简洁性(轮子)
⚫ 性能(速度计)
⚫ 架构和具体实现的分离(分开的两个半圆)
⚫ 提升空间(手风琴)
⚫ 程序大小(相对的压迫着一条线的两个箭头)
⚫ 易于编程/编译/链接(儿童积木“像 ABC 一样简单”)
RISC-V的不同寻常之处,除了在于它是最近诞生的和开源的以外,还在于:和几乎所 有以往的ISA不同,它是模块化的。它的核心是一个名为RV32I的基础ISA,运行一个完整 的软件栈。RV32I是固定的,永远不会改变。这为编译器编写者,操作系统开发人员和汇 编语言程序员提供了稳定的目标。模块化来源于可选的标准扩展,根据应用程序的需要, 硬件可以包含或不包含这些扩展。这种模块化特性使得RISC-V具有了袖珍化、低能耗的特 点,而这对于嵌入式应用可能至关重要。RISC-V编译器得知当前硬件包含哪些扩展后,便 可以生成当前硬件条件下的最佳代码。惯例是把代表扩展的字母附加到指令集名称之后作 为指示。例如,RV32IMFD将乘法(RV32M),单精度浮点(RV32F)和双精度浮点 (RV32D)的扩展添加到了基础指令集(RV32I)中。
RISC-V之RV32I
RV32I 基础指令集的一页图形表示。对于每幅图,将有下划线的字母从左到 右连接起来,即可组成完整的 RV32I 指令集。对于每一个图,集合标志{}内列举了指令的 所有变体,变体用加下划线的字母或下划线字符_表示。特别的,下划线字符_表示对于此 指令变体不需用字符表示。例如,下图表示了这四个 RV32I 指令:slt,slti,sltu,sltiu:

四个典型特点
首先,指令只有六种格式,并且所有的指令都是 32 位长,这简化了指令解码。ARM-32, 还有更典型的 x86-32 都有许多不同的指令格式,使得解码部件在低端实现中偏昂贵,在中 高端处理器设计中容易带来性能挑战。
第二,RISC-V 指令提供三个寄存器操作数,而不是 像 x86-32 一样,让源操作数和目的操作数共享一个字段。当一个操作天然就需要有三个不 同的操作数,但是 ISA 只提供了两个操作数时,编译器或者汇编程序程序员就需要多使用 一条 move(搬运)指令,来保存目的寄存器的值。
第三,在 RISC-V 中对于所有指令,要 读写的寄存器的标识符总是在同一位置,意味着在解码指令之前,就可以先开始访问寄存 器。在许多其他的 ISA 中,某些指令字段在部分指令中被重用作为源目的地,在其他指令 中又被作为目的操作数(例如,ARM-32 和 MIPS-32)。因此,为了取出正确的指令字 段,我们需要时序本就可能紧张的解码路径上添加额外的解码逻辑,使得解码路径的时序 更为紧张。
第四,这些格式的立即数字段总是符号扩展,符号位总是在指令中最高位。这 意味着可能成为关键路径的立即数符号扩展,可以在指令解码之前进行。
下图显示了六种基本指令格式,分别是:用于寄存器-寄存器操作的 R 类型指令,用 于短立即数和访存 load 操作的 I 型指令,用于访存 store 操作的 S 型指令,用于条件跳转操 作的 B 类型指令,用于长立即数的 U 型指令和用于无条件跳转的 J 型指令。
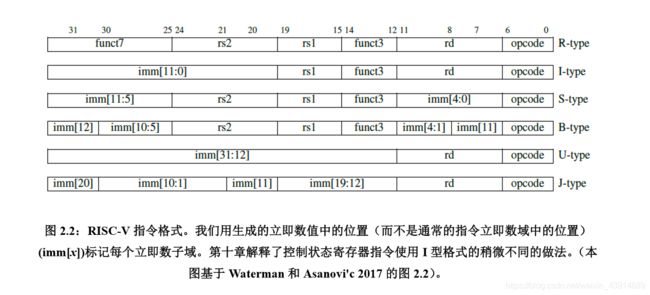
解释说明:四种基础指令格式 R/I/S/U
imm:立即数
rs1:源寄存器1
rs2:源寄存器2
rd:目标寄存器
opcode:操作码

RISC-V之乘除法指令
指令格式
RV32M 具有有符号和无符号整数的除法指令:divide(div)和 divide unsigned(divu),它们将 商放入目标寄存器。在少数情况下,程序员需要余数而不是商,因此 RV32M 提供 remainder(rem)和 remainder unsigned(remu),它们在目标寄存器写入余数,而不是商。
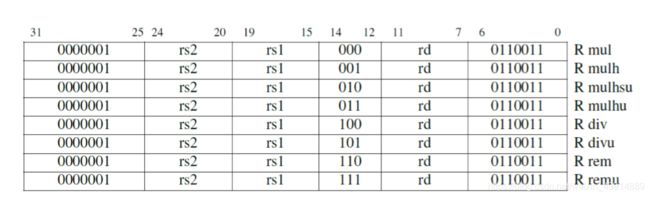 为了正确地得到一个有符号或无符号的 64 位积,RISC-V 中带有四个乘 法指令。要得到整数 32 位乘积(64 位中的低 32 位)就用 mul 指令。要得到高 32 位,如果 操作数都是有符号数,就用 mulh 指令;如果操作数都是无符号数,就用 mulhu 指令;如 果一个有符号一个无符号,可以用 mulhsu 指令。在一条指令中完成把 64 位积写入两个 32 位寄存器的操作会使硬件设计变得复杂,所以 RV32M 需要两条乘法指令才能得到一个完整 的 64 位积。
为了正确地得到一个有符号或无符号的 64 位积,RISC-V 中带有四个乘 法指令。要得到整数 32 位乘积(64 位中的低 32 位)就用 mul 指令。要得到高 32 位,如果 操作数都是有符号数,就用 mulh 指令;如果操作数都是无符号数,就用 mulhu 指令;如 果一个有符号一个无符号,可以用 mulhsu 指令。在一条指令中完成把 64 位积写入两个 32 位寄存器的操作会使硬件设计变得复杂,所以 RV32M 需要两条乘法指令才能得到一个完整 的 64 位积。
用乘法代替常数除法
对许多微处理器来说,整数除法是相对较慢的操作。如前述,除数为 2 的幂次的无符号 除法可以用右移来代替。事实证明,通过乘以近似倒数再修正积的高 32 位的方法,可以优 化除数为其它数的除法。例如,图 4.3 显示了 3 为除数的无符号除法的代码。

- 先把数装到t0里面
- addi是立即数与寄存器的数相加, t0-1365放回t0
- a0和t0相乘(无符号)
- 立即数→移,也就是a1右移1位
也就是说从数值上来讲,可以通过乘法代替常数除法
RISC-V之RV64
尽管 RV64I 有 64 位地址且默认数据大小为 64 位,32 位字仍然是程序中的有效数据类 型。因此,RV64I 需要支持字,就像 RV32I 需要支持字节和半字一样。更具体地说,由于寄 存器现在是 64 位宽,RV64I 添加字版本的加法和减法指令:addw,addiw,subw。这些指 令将计算结果截断为 32 位,结果符号扩展后再写入目标寄存器。 RV64I 也包括字版本的移 位指令(sllw,slliw,srlw,srliw,sraw,sraiw),以获得 32 位移位结果而不是 64 位移 位结果。要进行 64 位数据传输,RV64 提供了加载和存储双字指令:ld,sd。最后,就像 RV32I 中有无符号版本的加载单字节和加载半字的指令,RV64I 也有一个无符号版本的加载 字:lwu。 出于类似的原因,RV64 需要添加字版本的乘法,除法和取余指令:mulw,divw,divuw, remw,remuw。为了支持对单字及双字的同步操作,RV64A 为其所有的 11 条指令都添加 了双字版本。
由于版本众多,这里只选择有代表性的来了解
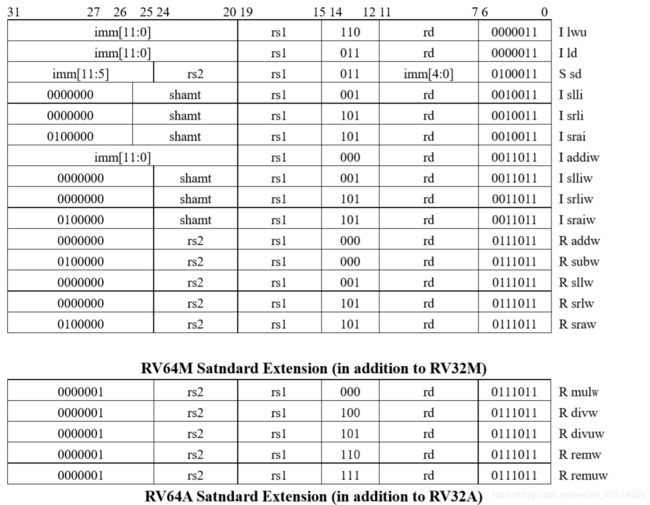 RV64F 和 RV64D 添加了整数双字转换指令,并称它们为长整数,以避免与双精度浮点 数据混淆:fcvt.l.s,fcvt.l.d,fcvt.lu.s,fcvt.lu.d,fcvt.s.l,fcvt.s.lu,fcvt.d.l,fcvt.d.lu. 由于整数 x 寄存器现在是 64 位宽,它们现在可以保存双精度浮点数据,因此 RV64D 增加了 两个浮点指令:fmv.x.w 和 fmv.w.x.
RV64F 和 RV64D 添加了整数双字转换指令,并称它们为长整数,以避免与双精度浮点 数据混淆:fcvt.l.s,fcvt.l.d,fcvt.lu.s,fcvt.lu.d,fcvt.s.l,fcvt.s.lu,fcvt.d.l,fcvt.d.lu. 由于整数 x 寄存器现在是 64 位宽,它们现在可以保存双精度浮点数据,因此 RV64D 增加了 两个浮点指令:fmv.x.w 和 fmv.w.x.
这里暂时不讲解压缩指令
RISC-V的特权架构
到目前为止,本书主要关注 RISC-V 对通用计算的支持:我们引入的所有指令都在用 户模式(应用程序的代码在此模式下运行)下可用。本章介绍两种新的权限模式:运行最 可信的代码的机器模式(machine mode),以及为 Linux,FreeBSD 和 Windows 等操作系统 提供支持的监管者模式(supervisor mode)。这两种新模式都比用和模式有着更高的权限, 这也是本章标题的来源。有更多权限的模式通常可以使用权限较低的模式的所用功能,并 且它们还有一些低权限模式下不可用的额外功能,例如处理中断和执行 I/O 的功能。处理 器通常大部分时间都运行在权限最低的模式下,处理中断和异常时会将控制权移交到更高 权限的模式。 嵌入式系统运行时(runtime)和操作系统用这些新模式的功能来响应外部事件,如网 络数据包的到达;支持多任务处理和任务间保护;抽象和虚拟化硬件功能等。鉴于这些主 题的广度,为此而编撰的全面的程序员指南会是另外一本完整的书。但我们的这一章节旨 在强调 RISC-V 这部分功能的亮点。
机器模式
机器模式(缩写为 M 模式,M-mode)是 RISC-V 中 hart(hardware thread,硬件线 程)可以执行的最高权限模式。在 M 模式下运行的 hart 对内存,I/O 和一些对于启动和配 置系统来说必要的底层功能有着完全的使用权。因此它是唯一所有标准 RISC-V 处理器都 必须实现的权限模式。实际上简单的 RISC-V 微控制器仅支持 M 模式。这类系统是本节的 重点。
机器模式最重要的特性是拦截和处理异常(不寻常的运行时事件)的能力。RISC-V 将 异常分为两类。
一类是同步异常,这类异常在指令执行期间产生,如访问了无效的存储器 地址或执行了具有无效操作码的指令时。
另一类是中断,它是与指令流异步的外部事件, 比如鼠标的单击。RISC-V 中实现精确例外:保证异常之前的所有指令都完整地执行了,而 后续的指令都没有开始执行(或等同于没有执行)。
图 10.3 列出了触发标准例外的原因。
在 M 模式运行期间可能发生的同步例外有五种:
⚫ 访问错误异常 当物理内存的地址不支持访问类型时发生(例如尝试写入 ROM)。
⚫ 断点异常 在执行 ebreak 指令,或者地址或数据与调试触发器匹配时发生。 ⚫ 环境调用异常 在执行 ecall 指令时发生。
⚫ 非法指令异常 在译码阶段发现无效操作码时发生。
⚫ 非对齐地址异常 在有效地址不能被访问大小整除时发生,例如地址为 0x12 的 amoadd.w
有三种标准的中断源:软件、时钟和外部来源。软件中断通过向内存映射寄存器中存 数来触发,并通常用于由一个 hart 中断另一个 hart(在其他架构中称为处理器间中断机 制)。当实时计数器 mtime 大于 hart 的时间比较器(一个名为 mtimecmp 的内存映射寄存 器)时,会触发时钟中断。外部中断由平台级中断控制器(大多数外部设备连接到这个中 断控制器)引发。
监管者模式
更复杂的 RISC-V 处理器用和几乎所有通用架构相同的方式处理这些问题:使用基于 页面的虚拟内存。这个功能构成了监管者模式(S 模式)的核心,这是一种可选的权限模 式,旨在支持现代类 Unix 操作系统,如 Linux,FreeBSD 和 Windows。S 模式比 U 模式权 限更高,但比 M 模式低。与 U 模式一样,S 模式下运行的软件不能使用 M 模式的 CSR 和 指令,并且受到 PMP 的限制。本届介绍 S 模式的中断和异常,下一节将详细介绍 S 模式 下的虚拟内存系统。 默认情况下,发生所有异常(不论在什么权限模式下)的时候,控制权都会被移交到 M 模式的异常处理程序。但是 Unix 系统中的大多数例外都应该进行 S 模式下的系统调 用。M 模式的异常处理程序可以将异常重新导向 S 模式,但这些额外的操作会减慢大多数 异常的处理速度。因此,RISC-V 提供了一种异常委托机制。通过该机制可以选择性地将中 断和同步异常交给 S 模式处理,而完全绕过 M 模式。
S 模式提供了一种传统的虚拟内存系统,它将内存划分为固定大小的页来进行地址转 换和对内存内容的保护。启用分页的时候,大多数地址(包括 load 和 store 的有效地址和 PC 中的地址)都是虚拟地址。要访问物理内存,它们必须被转换为真正的物理地址,这通 过遍历一种称为页表的高基数树实现。页表中的叶节点指示虚地址是否已经被映射到了真 正的物理页面,如果是,则指示了哪些权限模式和通过哪种类型的访问可以操作这个页。
扩展指令集
目前官方提供的risc-v扩展指令集有如下几个(确定将会实现的)
11.1 “B”标准扩展:位操作 …
11.2 “E”标准扩展:嵌入式 …
11.3 “H”特权态架构扩展:支持管理程序(Hypervisor) …
11.4 “J”标准扩展:动态翻译语言 …
11.5 “L”标准扩展:十进制浮点 …
11.6 “N”标准扩展:用户态中断 …
11.7 “P”标准扩展:封装的单指令多数据(Packed-SIMD)指令 …
11.8 “Q”标准扩展:四精度浮点 …
目前根据已经开源的设计方案,大多专注于B/J/Q/L指令的相关扩展
阿里平头哥文档
AI中涉及的运算操作
机器学习
- 矩阵的转置、求逆运算
- 矩阵的切片与扩张
- 矩阵的乘法,点积,内积,外积,元素积
- 矩阵的加法,求和(包括求元素的平方和),L1,L2正则化
- 取指数与对数(逻辑回归,信息熵等)
- 标准化、归一化操作
深度学习
- 线性层:矩阵的外积
- 卷积层:矩阵的内积
- 池化层:求矩阵平均值(求和),或求最大值
- 残差网络,GoogleNet等,矩阵拼接
- 随机梯度下降,keep prob:随机值生成
- 压缩解压缩
- 加密解密(MAC运算等)# 5,6两个点涉及大整数操作以及优化,质数生成
- 张量、矢量、标量的运算
现有的AI指令集或其他底层解决方案
TPU解决方案
在TPU中,它使用若干条指令来完成矩阵的乘法运算,其中使用Read_Host_Memory来从主存中读取数据至通用缓存(Unified Buffer)中;使用Read_Weights来将权重读取至矩阵单元中。在进行矩阵运算时,使用MatrixMultiply或Convolve来进行矩阵乘法。最后使用Write_Host_Memory来将数据写回主存中。但是在TPU中,它的矩阵乘法对操作数的尺寸存在限制,在MatrixMultiply或Convolve中,其限制操作数为B256 与256256,若矩阵尺寸大与此值,则不太方便直接使用TPU进行运算;若矩阵尺寸小于此值,则需要先对多余部分填充0后再进行计算。
X86
在X86_64中,其在AVX、AVX2等指令集中提供了VMULPS、VMULPD、VADDPS、VADDPD等一系列SIMD指令,这些指令可以使用一条指令来完成多组数据的运算。在矩阵乘法等应用中,数据之间没有相互依赖性,因此可以使用SIMD指令来提高运算效率。
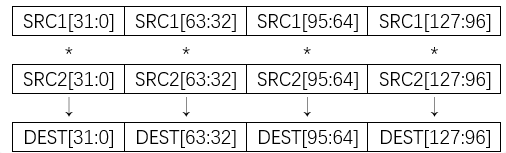
VMULPS指令示意图
与TPU相比,AVX至运算数据的尺寸上没有太多的限制,即使数据的规模较大,也可以拆分为多交指令执行。但这也造成AVX指令集的并行化程度一般不高,通常一条指令只能处理4-8条数据,效率远不如TPU等专门双击的架构,在人工智能的应用上仍然难以满足需要。
现有AI芯片
现有的AI芯片,比如寒武纪的产品为了AI的运算也做了大量适配,比如构建大量的乘法器用来在一个周期内并行处理多个乘法操作,相应地指令集也会向着这个方向进行优化,如华为Ascend 系列AI芯片,内置的都是运算密集型CISC指令集来为AI运算做优化。但是这种设计模式的功耗以及设计的繁琐程度都很高,所以集成AI优化的RISC-V应该在保持灵活小巧的基础上对矩阵运算等AI领域常见的基本数学运算做优化,对机器学习和深度学习有一个泛化支持,虽然速度可能没CISC那么高,但是可以保持其精简以及自由拓展的特点。
现有AI软件与芯片设计关系详解
本例以 Hanguang AI为例子,主要内容来自官方文档
HanGuang Al是阿里巴巴-迖摩院旗下平头哥半导体有限公司开发的入工智能芯片软件开发包J 巨前主要服务于业界领先的含光800人工智能推理芯片。 使用HanGuang Al在含光800芯片上开发深度学习应用可以获得言吞吐量和低延迟的高性能体验。
HanGuang Al软件架构如下所示
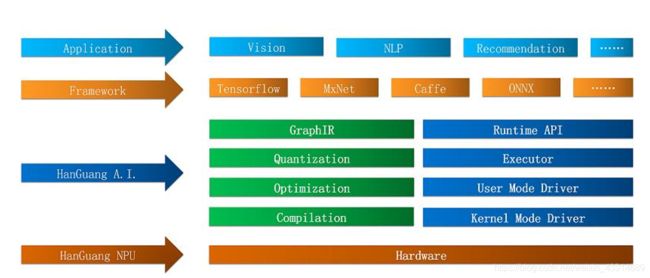

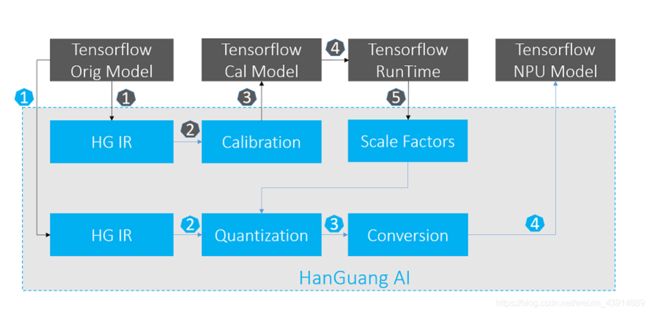
可以看到,当前AI软件的主要工作还是分为了3个大部分,其中和AI芯片设计打交道的主要是量化、编译过程。
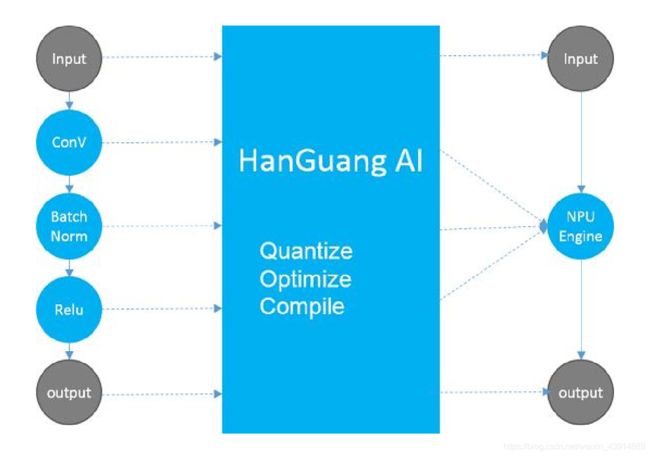 所以在设计是重点关注算子的底层编译实现,也就是说通过算子的提取计算代替传统的分析方法是一种高效运用在工业界的方法。
所以在设计是重点关注算子的底层编译实现,也就是说通过算子的提取计算代替传统的分析方法是一种高效运用在工业界的方法。
参考资料
In-Datacenter Performance Analysis of a Tensor Processing Unit
https://arxiv.org/ftp/arxiv/papers/1704/1704.04760.pdf
含光800软件介绍.pdf