【深度学习】-Imdb数据集情感分析之模型对比(1)-RNN
【深度学习】-Imdb数据集情感分析之模型对比(1)-RNN
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
-
- 【深度学习】-Imdb数据集情感分析之模型对比(1)-RNN
- 前言
- 一、IMDB数据集是什么(为什么使用IMDB数据集)?
-
- 1.IMDB数据集介绍
- 2.查看数据
- 二、使用RNN模型训练
-
- 1.RNN算法介绍
- 2.数据处理思路介绍
- 3.构建神经网络
- 导入影评数据
- 数据预处理
- 构建神经网络模型
- 训练模型
- 可视化结果
- 评估模型的准确率
- 总结
- 参考资料
前言
至今,越来越多的人在网络上抒发对一些人物和事物的情绪,表达不同的观点。特别是随着网络技术的不断发展,出现博客、微博、论坛等众多的网络平台为网络用户提供了更宽阔的平台来交流信息、表达意见。往往这些在线评论的文本信息不仅蕴含着用户的情感态度,也蕴含着巨大的商业价值,其反应了社会集体的情感状态,与此同时情感在人类决策时扮演着重要地位。因此,在线评论不仅成为商家识别用户对产品需求、喜好的重要信息来源和提高市场竞争力的有效信息,而且也为其他用户提供了有效了解产品的手段和反应产品好坏的“晴雨表”。
本项目将用户评论信息与评分评价信息相结合,使用文本情感分析的方法,以IMDB电影数据集作为语料源,运用几大深度学习模型对影评进行分析。通过分别构建RNN(循环神经网络)模型、TextCNN(文本分类)模型、LSTM(长短期记忆型神经网络)模型以及CNN-LSTM混合模型,进行不断训练,对比分析各个模型预测用户参与电影的评论中评论倾向的准确率,预测时长,总结出预测效果最好及最差的深度学习模型。
一、IMDB数据集是什么(为什么使用IMDB数据集)?
1.IMDB数据集介绍
全球最大的电影数据库网站IMDB,作为全球最具有权威的评论网站之一,它对电影的评价对一部电影的好坏以及人们对这部电影的选择与认知起着非常重要的作用,而以人工的方法很难应对海量的评论信息的收集和处理,情感分析技术随之产生。此外,我们运用深度学习对文本情感分析的研究在当下电影产业时代具有重要作用:该网站每年评出的电影TOP100名单包含了各种老片和新片,因为它并非根据电影的票房情况、奖项收获等客观绩效来衡量,而是根据影迷的访问流量和打分来衡量。
数据集地址:http://ai.stanford.edu/~amaas/data/sentiment/
2.查看数据
IMDB数据集是个著名的开源数据集,这里我们可以直接下载。下载好的目录打开如下:
![]()
分为正负情感两个文件夹,另还有1万个不等的子文件
子文件的内容就是我们所需要的影评数据了
数据集中,共有5w条文本,test集和train集各半,每个集合中,pos和neg也是各半。注:本文只用tranin集25000条文本进行训练。
二、使用RNN模型训练
1.RNN算法介绍
详细原理不多做介绍,我们从基础的神经网络中知道,神经网络包含输入层、隐层、输出层,通过激活函数控制输出,层与层之间通过权值连接。激活函数是事先确定好的,那么神经网络模型通过训练“学“到的东西就蕴含在“权值“中。

本文我们将使用RNN(循环神经网络)对电影评论进行情感分析,结果为positive或negative,分别代表积极和消极的评论。至于为什么使用RNN而不是普通的前馈神经网络,是因为RNN能够存储序列单词信息,得到的结果更为准确。这里我们将使用一个带有标签的影评数据集进行训练模型。
2.数据处理思路介绍
其实,Tensorflow.keras 自带了IMDB的已经进行很好的预处理的数据集,可以一行代码下载,不需要进行任何的处理就可以训练,而且效果比较好。但是,这样就太没意思了。在真实场景中,我们拿到的都是脏脏的数据,我们必须自己学会读取、清洗、筛选、分成训练集测试集。而且,从我自己的实践经验来看,数据预处理的本事才是真本事,模型都好搭,现在的各种框架已经让搭建模型越来越容易,但是数据预处理只能自己动手。所有往往实际任务中,数据预处理花费的时间、精力是最多的,而且直接影响后面的效果。
另外,我们要知道,对文本进行分析,首先要将文本数值化。因为计算机不认字的,只认数字。所以最后处理好的文本应该是数值化的形式。而Tensorflow.keras自带的数据集全都数值化了,而它并不提供对应的查询字典让我们知道每个数字对应什么文字,这让我们只能训练模型,看效果,无法拓展到其他语料上,也无法深入分析。综上,我上面推荐的数据集,是原始数据集,都是真实文本,当然,为了方便处理,也已经被斯坦福的大佬分好类了。但是怎么数值化,需要我们自己动手。
3.构建神经网络
导入影评数据
导入下载好的数据集,把正负样例分别集成为总的集合。
from keras.datasets import imdb
from keras.preprocessing import sequence
from keras.preprocessing.text import Tokenizer
import re
re_tag = re.compile(r'<[^>]+>')
def rm_tags(text):
return re_tag.sub('', text)
import os
def read_files(filetype):
path = "data/aclImdb/"
file_list=[]
positive_path=path + filetype+"/pos/"
for f in os.listdir(positive_path):
file_list+=[positive_path+f]
negative_path=path + filetype+"/neg/"
for f in os.listdir(negative_path):
file_list+=[negative_path+f]
print('read',filetype, 'files:',len(file_list))
all_labels = ([1] * 12500 + [0] * 12500)
all_texts = []
for fi in file_list:
with open(fi,encoding='utf8') as file_input:
all_texts += [rm_tags(" ".join(file_input.readlines()))]
return all_labels,all_texts
数据预处理
构建神经网络的第一步是将数据处理成合适的格式
其次,我们去除文本中的html标签以及一些赘余的字符串。
我们可以写几个模块,等会调用就可以了。
from keras.datasets import imdb
from keras.preprocessing import sequence
from keras.preprocessing.text import Tokenizer
import re
re_tag = re.compile(r'<[^>]+>')
def rm_tags(text):
return re_tag.sub('', text)
import os
def read_files(filetype):
path = "D:\train_data\aclImdb\aclImdb\train"
file_list=[]
positive_path=path + filetype+"/pos/"
for f in os.listdir(positive_path):
file_list+=[positive_path+f]
negative_path=path + filetype+"/neg/"
for f in os.listdir(negative_path):
file_list+=[negative_path+f]
print('read',filetype, 'files:',len(file_list))
all_labels = ([1] * 12500 + [0] * 12500)
all_texts = []
for fi in file_list:
with open(fi,encoding='utf8') as file_input:
all_texts += [rm_tags(" ".join(file_input.readlines()))]
return all_labels,all_texts
嵌入层需要传入整数类型的数据,因此我们需要将单词编码为整数类型。最简单的方法是创建一个从单词到整数的映射的字典。然后将影评的单词映射位数字,期间我们必须保证影评数字一致,然后我们才能将每条评论转换为整数传入网络。
# 读文件
y_train,train_text=read_files("train")
y_test,test_text=read_files("test")
# 建立单词和数字映射的字典
token = Tokenizer(num_words=3800)
token.fit_on_texts(train_text)
#将影评的单词映射到数字
x_train_seq = token.texts_to_sequences(train_text)
x_test_seq = token.texts_to_sequences(test_text)
# 让所有影评保持在380个数字
x_train = sequence.pad_sequences(x_train_seq, maxlen=380)
x_test = sequence.pad_sequences(x_test_seq, maxlen=380)
构建神经网络模型
首先创建一个模块,给他添加一个embedding层,以及一个dropout参数,再加入一个简单的RNN层,添加激活函数等,详细不多做说明,如下图:
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation
from keras.layers.embeddings import Embedding
from keras.layers.recurrent import SimpleRNN
model = Sequential()
model.add(Embedding(output_dim=32,
input_dim=3800,
input_length=380))
model.add(Dropout(0.25))
model.add(SimpleRNN(units=16))
model.add(Dense(units=256,activation='relu' ))
model.add(Dropout(0.25))
model.add(Dense(units=1,activation='sigmoid' ))
model.summary()
训练模型
给模型输入数据进行划分
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
train_history =model.fit(x_train, y_train,batch_size=100,
epochs=10,verbose=2,
validation_split=0.2)
开始训练
Epoch 1/10
- 96s - loss: 0.4641 - accuracy: 0.7878 - val_loss: 0.4561 - val_accuracy: 0.8022
Epoch 2/10
- 87s - loss: 0.3381 - accuracy: 0.8629 - val_loss: 0.5485 - val_accuracy: 0.7526
Epoch 3/10
- 84s - loss: 0.3924 - accuracy: 0.8249 - val_loss: 0.9150 - val_accuracy: 0.4028
Epoch 4/10
- 84s - loss: 0.3396 - accuracy: 0.8560 - val_loss: 0.2696 - val_accuracy: 0.9126
Epoch 5/10
- 84s - loss: 0.2728 - accuracy: 0.8897 - val_loss: 0.6617 - val_accuracy: 0.7958
Epoch 6/10
- 84s - loss: 0.2355 - accuracy: 0.9082 - val_loss: 0.6959 - val_accuracy: 0.7584
Epoch 7/10
- 83s - loss: 0.1903 - accuracy: 0.9313 - val_loss: 0.8196 - val_accuracy: 0.7458
Epoch 8/10
- 83s - loss: 0.1533 - accuracy: 0.9428 - val_loss: 0.8930 - val_accuracy: 0.6998
Epoch 9/10
- 83s - loss: 0.1763 - accuracy: 0.9313 - val_loss: 1.1092 - val_accuracy: 0.5342
Epoch 10/10
- 83s - loss: 0.1419 - accuracy: 0.9485 - val_loss: 1.1138 - val_accuracy: 0.6904
可视化结果
import matplotlib.pyplot as plt
def show_train_history(train_history,train,validation):
plt.plot(train_history.history[train])
plt.plot(train_history.history[validation])
plt.title('Train History')
plt.ylabel(train)
plt.xlabel('Epoch')
plt.legend(['train', 'validation'], loc='upper left')
plt.savefig('1.png')
plt.show()
show_train_history(train_history,'acc','val_acc')
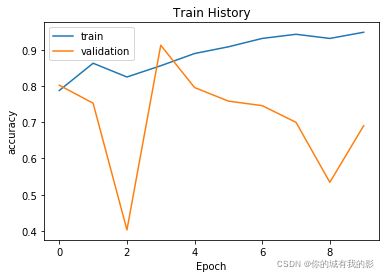

评估模型的准确率
scores = model.evaluate(x_test, y_test, verbose=1)
总结
结果还是不错的,最终测试集上准确率也在94.85%,训练时长约为830s,稍微比较慢。
参考资料
https://www.oreilly.com/content/perform-sentiment-analysis-with-lstms-using-tensorflow/
https://zhuanlan.zhihu.com/p/63852350
https://blog.csdn.net/qq_34464926/article/details/81701190