聚类算法——基于密度的聚类算法DBSCAN
1.DBSCAN算法名词概念
邻域(Eps):以给定对象为圆心,半径内的区域为该对象的邻域
核心对象:对象的邻域内至少有MinPts(设定的阈值)个对象,则该对象为核心对象
边界对象:对象的领域小于MinPts个对象,但是在某个核心对象的邻近域中
离群点(噪声):对象的领域小于MinPts个对象,且不在某个核心对象的邻域中
直接密度可达:如果a是核心对象,b在a的邻域内,则a到b是直接密度可达
密度可达:a到b是直接密度可达,b到c是直接密度可达,则a到c是密度可达
密度相连:a到b是密度可达,a到c也是密度可达,则b到c是密度相连的
2.DBSCAN算法步骤:
1.输入两个参数:邻域半径(Eps),邻域密度阈值(MinPts)
2.找一个未访问的点
3.如果该点是核心点,访问所有从该点密度可达的点,形成一个簇
4.如果该点是边界点,跳出循环,寻找下一个点
3.DBSCAN算法例题
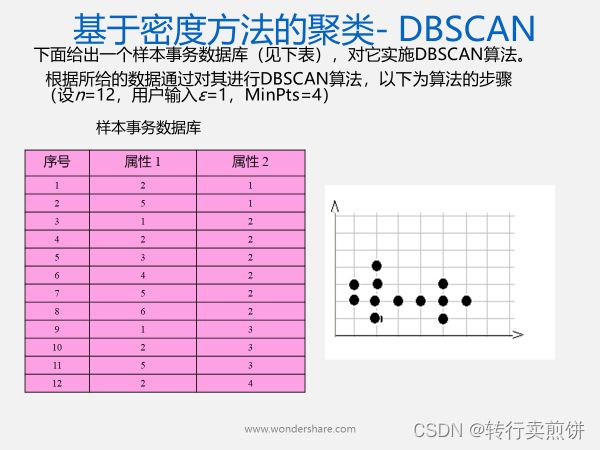
DBSCAN聚类过程:
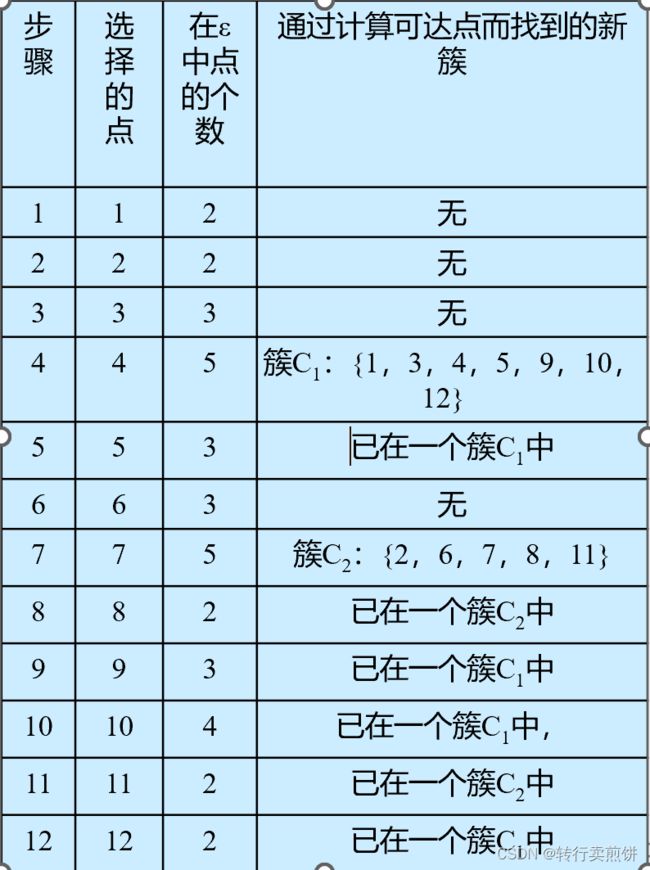
第 1 步,在数据库中选择一点 1 ,由于在以它为圆心的,以 1 为半径的圆内包含 2 个点 ,因此它不是核心点,选择下一个点。
第 2 步,在数据库中选择一点 2 ,由于在以它为圆心的,以 1 为半径的圆内包含 2 个点,因此它不是核心点,选择下一个点。
第 3 步,在数据库中选择一点 3 ,由于在以它为圆心的,以 1 为半径的圆内包含 3 个点,因此它不是核心点,选择下一个点。
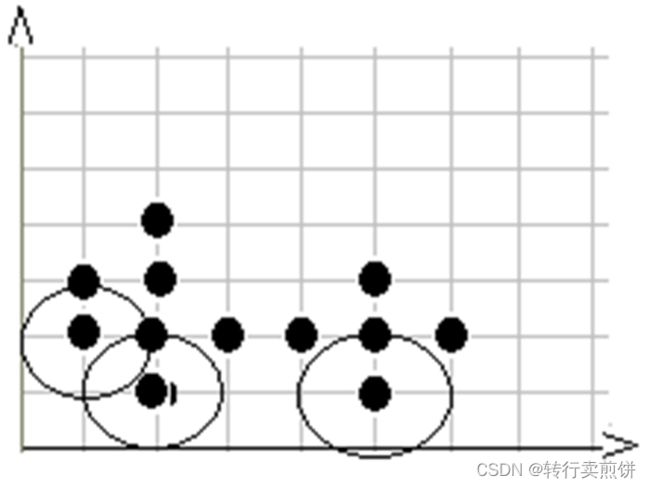
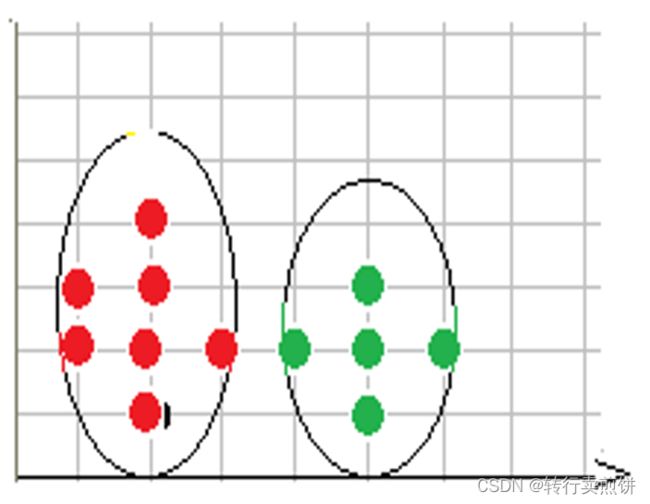
第 4 步,在数据库中选择一点 4 ,由于在以它为圆心的,以 1 为半径的圆内包含 5 个点,因此它是核心点,寻找从它出发可达的点 ,聚出的新类C1{1 , 3 , 4 , 5 , 9 , 10 , 12} ,选择下一个点。
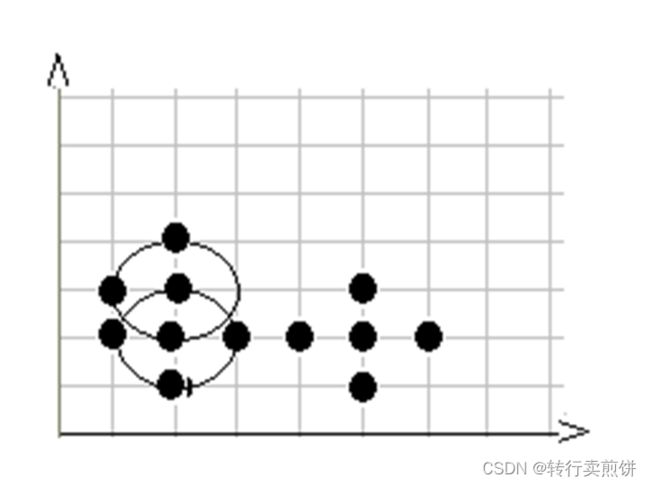
第 5 步,在数据库中选择一点 5 ,已经在簇 1 中,选择下一个点。
第6 步,在数据库中选择一点 6 ,由于在以它为圆心的,以 1 为半径的圆内包含 3 个点,因此它不是核心点,选择下一个点。
第7步,在数据库中选择一点7,由于在以它为圆心的,以1为半径的圆内包含5个点,因此它是 核心点,寻找从它出发可达的点,聚出的新类C2{2,6,7,8,11},选择下一个点。
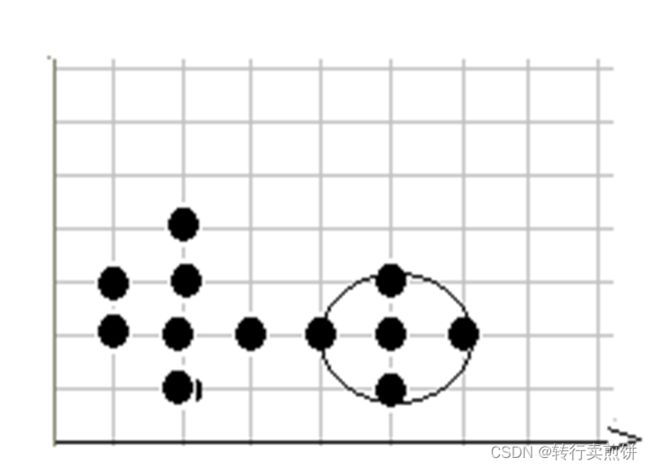
第 8 步,在数据库中选择一点 8 ,已经在簇 2 中,选择下一个点。
第 9 步,在数据库中选择一点 9 ,已经在簇 1 中,选择下一个点。
第 10 步,在数据库中选择一点 10 ,已经在簇 1 中,选择下一个点。
第 11 步,在数据库中选择一点 11 ,已经在簇 2 中,选择下一个点。
第 12 步,选择 12 点,已经在簇 1 中,由于这已经是最后一点所有点都以处理,程序终止。