数据湖概念以及数据湖产生的背景和价值
一、数据湖的概念
数据湖是一个集中式存储库,允许以任意规模存储所有结构化和非结构化数据。您可以按原样存储数据(无需先对数据进行结构化处理),并运行不同类型的分析 – 从控制面板和可视化到大数据处理、实时分析和机器学习,以指导做出更好的决策。
是构建在低成本分布式存储之上,提供更好事物和性能支持的统一数据存储系统。典型分层如下图所示:

- 最底层为存储层:一般依赖HDFS或者公有云存储(比如S3)保存数据;数据格式为开放格式,比如Parquet或者ORC;
- 中间层为数据表抽象层:它的关键作用在于提供了表格式的抽象,比如能够支持ACID;
- 最上层为计算层:基于表抽象层,可以扩展出不同的计算引擎,满足不同的计算需求。
可以看出,由于采用了HDFS或公有云存储,所以数据湖在保存数据上,具有低成本大容量的优点,并且能够保存多种多样的数据,比如结构化、半结构化和非结构化数据;另外,由于表抽象层的存在,保证了ACID事务支持,同时提供了良好的扩展能力,可以面向不同的计算需求对接不同的计算引擎。
二、数据湖产生的背景
1.互联网早期

在互联网早期,各个公司的数据量不大,而且比较单一,因此整个数据架构比较简单,主要是基于关系型数据库搭建。
关系型数据库提供了数据的收集、存储和分析,数据质量比较高,但是能够支撑的数据量有限。
2.互联网爆发
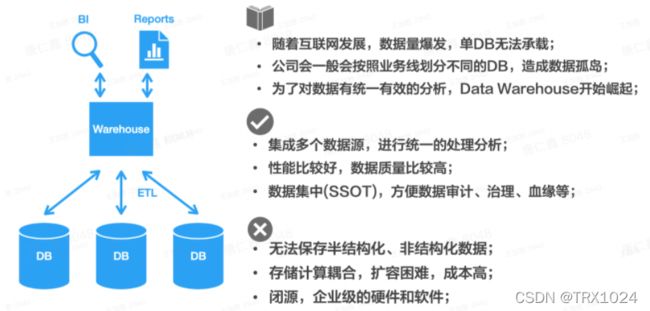
随着互联网的爆发,数据量爆发式增长,原有的数据架构开始暴露出问题:单个关系型数据库无法支撑庞大的数据量。
于是公司会按照业务线等方式,把数据进行拆分,不同的数据库保存不同的数据,比如分别保存订单数据、用户数据等。虽然这种方式在一定程度上解决了问题,但它同时引入了另外一个问题:数据孤岛。如果业务想跨数据库进行数据分析,会非常困难,这严重影响了数据的可用价值。
在这个背景下,数据仓库(Data Warehouse)开始崛起。数据仓库可以集成多个数据库的数据,进行统一的处理分析,从而解决数据孤岛问题。而且相比关系型数据库,数据仓库的查询性能更高,响应更快。通过这种集中的数据分析(Single Source of Truth),也可以更方便地对数据进行审计、治理等。
但同时数据仓库也存在各种各样的问题,其中很关键一点是成本相对较高,特别是保存数据量很大的话,会给公司带来比较大的成本压力。而且采用商业版数据仓库的话,由于技术闭源,且依赖特定的企业级服务器,会让公司和商业数仓背后的公司产生强绑定的风险,这些都是大公司所忌惮的。
3.Hadoop出现
这一切问题在Hadoop问世后都发生了重大转变,Hadoop脱胎于Google的“三驾马车”,借助Google的先进理念,再通过开源的方式提供给广大用户,可以说Hadoop由此成为了大数据分析的分水岭。企业从此有了一个很有吸引力的选型,从闭源昂贵的商业数仓,转向开源免费的Hadoop,而且Hadoop可以保存多种多样的数据,包括文本、图片、音视频等,这些都是数据仓库做不到的。
(1) Hadoop的核心特点:
- 低成本:部署在大量低成本服务器上
- 容错性:软硬件故障不会导致数据丢失,计算也可以重试
- 扩展性:可以存储海量数据
- 灵活性:可以保存丰富的数据类型
Hadoop的一大优势是低成本,很多时候更高的性能、更丰富的功能,远没有更低的成本对企业有吸引力。而且在低成本的优势之上,Hadoop提供了良好的容错性、扩展性,为不断涌现的数据提供了有力的存储和计算支撑。
(2) Hadoop的局限性
Hadoop的火热也引来了不少非议,数据库领域的人站出来职责Hadoop在“开历史的倒车”。以数据库领域的多年经验,有几条准则是很重要的:
- 数据一定要有Schema;但是Hadoop体系一开始是没有Schema概念的,一份数据的格式是什么,一般隐藏在代码中,或者写这份数据的人的脑子里,给其他人使用数据造成了很大的障碍。当然这个问题在Hive出现后已经很大地改观了。
- 高级别的访问语言(主要指SQL)很重要;在他们看来,写MapReduce代码太反人类了,跟写汇编似的,很多人搞不定。
除此之外,Hadoop还有一些数据库领域很关键的特性缺失了:
- 不支持事务:写入数据的作业如果挂了,可能会写入脏数据,被下游读取到。
- 数据和Schema可能不匹配:如果写入了不符合Schema的数据,下游在处理的时候就会有各种异常。
- 不支持索引、不支持更新……
4.Hadoop + Data Warehouse
Hadoop虽然存在这样那样的缺点,但是事实证明,它依然非常受欢迎,因为它确实解决了其他技术无法解决的问题。
那么如何解决Hadoop本身的缺陷呢,很简单,用户选择把Hadoop和数据仓库结合起来使用:
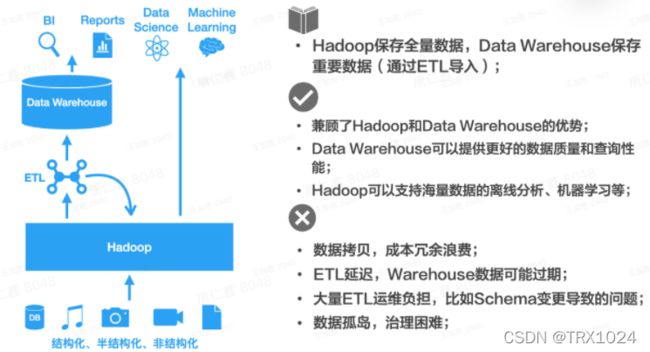
Hadoop以其大容量低成本的特性,保存最原始的数据,这部分数据比较全面,但是质量可能不是非常高。对于关键的数据,通过ETL处理后,导入到数据仓库中,提供更好的查询性能,提供更好的数据质量,支撑企业内部的BI和报表需求。
看起来很美好,但是可以看出又回到了早期存在的问题,数据孤岛问题。往往同一份数据在Hadoop和数据仓库中都有一份,除了造成数据冗余、成本浪费,还造成了数据产出口径不一致问题,应该以哪个系统的数据为准有时候说不清楚;另外,这种数据架构带来了运维上的困难,比如Schema的变更很容易导致ETL链路的各种问题,这些都严重影响了从数据到价值的转换效率。
三、数据湖的引入及价值
用户需要有这样一种系统,它既具备Hadoop的低成本大容量的优势,又具备数据仓库的ACID事务等能力。如果有一套技术方案能够支撑如上需求的话,那么就可以很大程度上解决Hadoop+Data Warehouse搭配使用带来的各种问题。
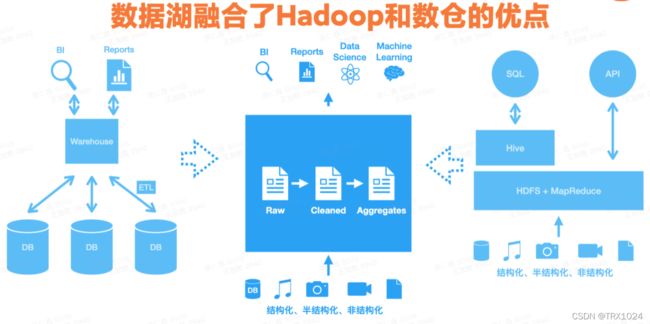
可以简单的认为,数据湖就是这样一种融合了Hadoop和数仓优势的技术。正如它的定义,它是构建在低成本分布式存储之上,提供更好的事物和性能支持的统一数据存储系统。
那是不是说就不需要数据仓库了呢,从短期来看是做不到的,对于性能要求比较高的查询等需求,依然需要数据仓库来解决。但是按照二八原则,如果80%的数据处理需求通过数据湖一套技术架构就能解决的话,就已经能够给业务带来很大的价值了;无论是在效率上还是成本上,都会带来很大的优势。至于长期,目前业界存在争议,有人偏向于长期共存,有人偏向于数据湖架构逐步统一市场,目前暂无定论(感兴趣的同学可以看一下来自a16z、Snowflake、Fishtown Analytics(dbt背后商业公司)等人的The Great Debate)。
1.数据湖与数据仓库对比
数据仓库是一个优化的数据库,用于分析来自事务系统和业务线应用程序的关系数据。事先定义数据结构和 Schema 以优化快速 SQL 查询,其中结果通常用于操作报告和分析。数据经过了清理、丰富和转换,因此可以充当用户可信任的“单一信息源”。
数据湖有所不同,因为它存储来自业务线应用程序的关系数据,以及来自移动应用程序、IoT 设备和社交媒体的非关系数据。捕获数据时,未定义数据结构或 Schema。这意味着您可以存储所有数据,而不需要精心设计也无需知道将来您可能需要哪些问题的答案。您可以对数据使用不同类型的分析(如 SQL 查询、大数据分析、全文搜索、实时分析和机器学习)来获得结果。
| 特性 | 数据仓库 | 数据湖 |
| 数据 | 来自事务系统、运营数据库和业务线应用程序的关系数据 | 来自 IoT 设备、网站、移动应用程序、社交媒体和企业应用程序的非关系和关系数据 |
| Schema | 设计在数据仓库实施之前(写入型 Schema) | 写入在分析时(读取型 Schema) |
| 性价比 | 更快查询结果会带来较高存储成本 | 更快查询结果只需较低存储成本 |
| 数据质量 | 可作为重要事实依据的高度监管数据 | 任何可以或无法进行监管的数据(例如原始数据) |
| 用户 | 业务分析师 | 数据科学家、数据开发人员和业务分析师(使用监管数据) |
| 分析 | 批处理报告、BI 和可视化 | 机器学习、预测分析、数据发现和分析 |
这是AWS给出的对比
传统的数据仓库工作方式是集中式的:业务人员给需求到数据团队,数据团队根据要求加工、开发成维度表,供业务团队通过BI报表工具查询或者业务分析系统展示。
数据湖是开放、自助式的:开放数据给所有人使用,数据团队更多是提供工具、环境供各业务团队使用,业务团队进行开发、分析。
和数据仓库不同的是,以前数据仓库都是先设计schema,然后灌入数据。数据湖的schema是随用随生成,随着分析场景不同而不同。
数据湖对于数据分析师来说对数据的操控性更强,但是要求也更高,不光懂业务,懂sql,懂数据,还要懂大数据处理技术,每个人都在处理自己需要的数据,会造成很多冗余数据存储和计算资源浪费,无法形成共性的可复用的数据层,这方面数仓是有益的补充。数据湖并不是为了颠覆数据仓库,是为了满足数仓无法满足的数据需求,二者是互补的。
2.基于Hive构建的传统数仓的局限性
- 数据运转效率低。数仓模型本身的研发与迭代成本比较高,生产速度赶不上需求速度,这就导致我们的创新想法落地、业务策略迭代等都会被按下暂停键;
- 端到端的数据变更困难。业务的快速迭代导致了基础数据 schema 频繁变更,而每次数据 schema 变更都需要变更数据仓库中的存量数据并且更新升级全链路,大大拖慢了业务的迭代效率
- 未提供较完善ACID语义支持。由于转储作业中断、INSERT OVERWRITE、Partition修改、Schema修改等相关变动,很难隔离对下游任务的影响;
- 近实时分析CDC数据困难。基于Hive构建的数仓对Update和Delete操作支持并不友好,往往需要额外的操作实现binlog数据的正确处理和分析;
- 机器学习流程更倾向于使用未加工的原始数据,通过特征提取和模型开发,用于模型在线推理;
- 难以提供近实时的报表。业务要求实现小时级或者分钟级的近实时报表。
参考文章:
官方文档
数据分析师应该了解的数据湖_数据社的博客-CSDN博客