转自 FHNstephen的空间
后缀数组是处理字符串的有力工具。后缀数组是后缀树的一个非常精巧的替代品,它比后缀树容易编程实现,能够实现后缀树的很多功能而时间复杂度也并不逊色,而且它比后缀树所占用的内存空间小很多。可以说,后缀数组比后缀树要更为实用。自从拜读了罗穗骞大牛的WC2009论文《后缀数组——处理字符串的有力工具》后,经过若干星期的努力(中间有因某些原因而缓下来),终于把论文上面的练习题全部完成了,现在写写自己对后缀数组的理解和感悟。在看本笔记时,请不要忘记了,这是笔记,而教材是《后缀数组——处理字符串的有力工具》。
一:后缀数组的实现
1、定义:Suffix Array数组(SA数组)用于保存从小到大排好序之后的后缀。RANK名次数组用来保存后缀S[i..n]在所有后缀中是第几小的后缀。简单来说,SA数组表示的是“排第几的是谁”,RANK数组表示的是“你的排名是多少”。
2、求SA数组以及RANK数组的方法:详细的请转到罗穗骞大牛的论文,我的学习笔记重点不是要介绍这个。
3、对DA(倍增算法)的一些个人理解:由于我只学习了倍增算法,所以我只能谈谈我对它的理解。DC3算法我没有去研究....
DA算法我是根据罗穗骞的模板写的,根据自己的理解做了些许的小优化。我们现在来看看罗穗骞大牛的模板:
int wa[maxn],wb[maxn],wv[maxn],ws[maxn];
int cmp(int *r,int a,int b,int l)
{return r[a]==r[b]&&r[a+l]==r[b+l];}
void da(int *r,int *sa,int n,int m)
{
int i,j,p,*x=wa,*y=wb,*t;
for(i=0;i<m;i++) ws[i]=0;
for(i=0;i<n;i++) ws[x[i]=r[i]]++;
for(i=1;i<m;i++) ws[i]+=ws[i-1];
for(i=n-1;i>=0;i--) sa[--ws[x[i]]]=i;
for(j=1,p=1;p<n;j*=2,m=p)
{
for(p=0,i=n-j;i<n;i++) y[p++]=i;
for(i=0;i<n;i++) if(sa[i]>=j) y[p++]=sa[i]-j;
for(i=0;i<n;i++) wv[i]=x[y[i]];
for(i=0;i<m;i++) ws[i]=0;
for(i=0;i<n;i++) ws[wv[i]]++;
for(i=1;i<m;i++) ws[i]+=ws[i-1];
for(i=n-1;i>=0;i--) sa[--ws[wv[i]]]=y[i];
for(t=x,x=y,y=t,p=1,x[sa[0]]=0,i=1;i<n;i++)
x[sa[i]]=cmp(y,sa[i-1],sa[i],j)?p-1:p++;
}
return;
}
其实,我个人认为,对于这个算法以及代码,无需过分深入地理解,只需记忆即可,理解只是为了帮助记忆罢了。先解释变量:n为字符串长度,m为字符的取值范围,r为字符串。后面的j为每次排序时子串的长度。
for(i=0;i<m;i++) ws[i]=0;
for(i=0;i<n;i++) ws[x[i]=r[i]]++;
for(i=1;i<m;i++) ws[i]+=ws[i-1];
for(i=n-1;i>=0;i--) sa[--ws[x[i]]]=i;
这四行代码,进行的是对R中长度为1的子串进行基数排序。x数组在后面需要用到,所以先复制r数组的值。特别需要注意的是,第四行的for语句,初始化语句为i=n-1,如果写得不太熟练,很容易习惯性地写成i=0,我一开始就是。理解这是基数排序的最好方法,找个例子,自己推推....
for(p=0,i=n-j;i<n;i++) y[p++]=i;
for(i=0;i<n;i++) if(sa[i]>=j) y[p++]=sa[i]-j;
这两行代码,利用了上一次基数排序的结果,对待排序的子串的第二关键字进行了一次高效地基数排序。我们可以结合下面的图来理解:
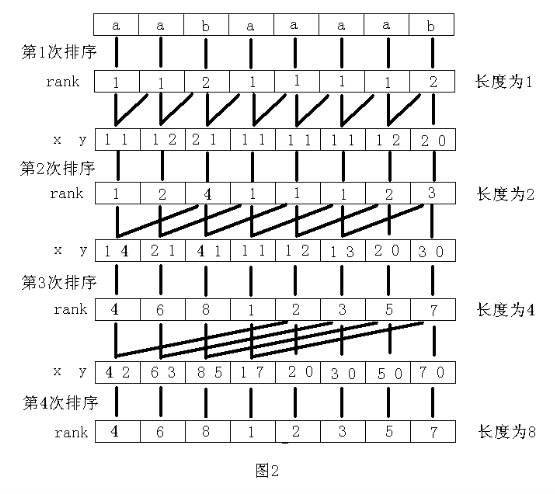
不难发现,除了第一次基数排序以外,之后的每次双关键字排序,设此次排序子串长度为j,则从第n-j位开始的子串,其第二关键字均为0,所以得到第一个for语句:for(p=0,i=n-j;i<n;i++) y[p++]=i;使用pascal的朋友们注意了,这里之所以是n-j位,是因为c++的字符串是从第0位开始表示的。这里,p暂时成为了一个计数变量。第二个语句的意义,分析上图也不难理解,这里留给朋友们你们自行思考啦。(不如说我懒...)
for(i=0;i<n;i++) wv[i]=x[y[i]];
for(i=0;i<m;i++) ws[i]=0;
for(i=0;i<n;i++) ws[wv[i]]++;
for(i=1;i<m;i++) ws[i]+=ws[i-1];
for(i=n-1;i>=0;i--) sa[--ws[wv[i]]]=y[i];
与一开始的4个for语句意义相同,基数排序。至于为什么wv[i]=x[y[i]],这个我想了蛮久没想通...硬记算了- -哪位朋友理解的希望能告诉我一声...
for(t=x,x=y,y=t,p=1,x[sa[0]]=0,i=1;i<n;i++)
x[sa[i]]=cmp(y,sa[i-1],sa[i],j)?p-1:p++;
这个for语句中的初始化语句里,完成了x数组和y数组的交换,用了指针的交换节约时间,简化代码。这里需要注意的是p和i的初始值都是1,不是0.其实如果记得后面的语句,不难看出它们的初始值不能为0,因为后面有i-1和p-1嘛。这个for语句的意义要结合cmp函数来理解。反正,你知道这里p的值表示的是此时关键字不同的串的数量就对了。当p=n的时候,说明所有串都已经排好序了(它们的排名都唯一确定)。所以,一开始的循环语句中,循环条件是(p<n)。
另外,在使用倍增算法前,需要保证r数组的值均大于0。然后要在原字符串后添加一个0号字符,具体原因参见罗穗骞的论文。这时候,若原串的长度为n,则实际要进行后缀数组构建的r数组的长度应该为n+1.所以调用da函数时,对应的n应为n+1.
二、后缀数组的应用--height数组
在介绍后缀数组的应用前,先介绍后缀数组的一个重要附属数组:height数组。
1、height 数组:定义height[i]=suffix(sa[i-1])和suffix(sa[i])的最长公
共前缀,也就是排名相邻的两个后缀的最长公共前缀。
height数组是应用后缀数组解题是的核心,基本上使用后缀数组解决的题目都是依赖height数组完成的。
2、height数组的求法:具体的求法参见罗穗骞的论文。对于height数组的求法,我并没有去深刻理解,单纯地记忆了而已...有兴趣的朋友可以去钻研钻研再和我交流交流
这里给出代码:
int rank[maxn],height[maxn];
void calheight(int *r,int *sa,int n)
{
int i,j,k=0;
for(i=1;i<=n;i++) rank[sa[i]]=i;
for(i=0;i<n;height[rank[i++]]=k)
for(k?k--:0,j=sa[rank[i]-1];r[i+k]==r[j+k];k++);
return;
}
3、一些注意事项:height数组的值应该是从height[1]开始的,而且height[1]应该是等于0的。原因是,因为我们在字符串后面添加了一个0号字符,所以它必然是最小的一个后缀。而字符串中的其他字符都应该是大于0的(前面有提到,使用倍增算法前需要确保这点),所以排名第二的字符串和0号字符的公共前缀(即height[1])应当为0.在调用calheight函数时,要注意height数组的范围应该是[1..n]。所以调用时应该是calheight(r,sa,n)而不是calheight(r,sa,n+1)。要理解清楚这里的n的含义是什么。
calheight过程中,对rank数组求值的for语句的初始语句是i=1而不是i=0的原因,和上面说的类似,因为sa[0]总是等于那个已经失去作用的0号字符,所以没必要求出其rank值。当然你错写成for (i=0..),也不会有什么问题。
三、后缀数组解题总结:
1、求单个子串的不重复子串个数。SPOJ 694、SPOJ 705.
这个问题是一个特殊求值问题。要认识到这样一个事实:一个字符串中的所有子串都必然是它的后缀的前缀。(这句话稍微有点绕...)对于每一个sa[i]后缀,它的起始位置sa[i],那么它最多能得到该后缀长度个子串(n-sa[i]个),而其中有height[i]个是与前一个后缀相同的,所以它能产生的实际后缀个数便是n-sa[i]-height[i]。遍历一次所有的后缀,将它产生的后缀数加起来便是答案。
代码及题解:
http://hi.baidu.com/fhnstephen/blog/item/68f919f849748668024f56fb.html
2、后缀的最长公共前缀。(记为lcp(x,y))
这是height数组的最基本性质之一。具体的可以参看罗穗骞的论文。后缀i和后缀j的最长公共前缀的长度为它们在sa数组中所在排位之间的height值中的最小值。这个描述可能有点乱,正规的说,令x=rank[i],y=rank[j],x<y,那么lcp(i,j)=min(height[x+1],height[x+2]...height[y])。lcp(i,i)=n-sa[i]。解决这个问题,用RMQ的ST算法即可(我只会这个,或者用最近公共祖先那个转化的做法)。
3、最长重复子串(可重叠)
要看到,任何一个重复子串,都必然是某两个后缀的最长公共前缀。因为,两个后缀的公共前缀,它出现在这两个后缀中,并且起始位置时不同的,所以这个公共前缀必然重复出现两次以上(可重叠)。而任何两个后缀的最长公共前缀为某一段height值中的最小值,所以最大为height值中的最大值(即某个lcp(sa[i],sa[i+1]))。所以只要算出height数组,然后输出最大值就可以了。
一道题目和代码:
http://hi.baidu.com/fhnstephen/blog/item/4ed09dffdec0a78eb801a0ba.html
4、最长重复不重叠子串 PKU1743
这个问题和3的唯一区别在于能否重叠。加上不能重叠这个限制后,直接求解比较困难,所以我们选择二分枚举答案,将问题转换为判定性问题。假设当时枚举的长度为k,那么要怎样判断是否存在长度为k的重复不重叠子串呢?
首先,根据height数组,将后缀分成若干组,使得每组后缀中,后缀之间的height值不小于k。这样分组之后,不难看出,如果某组后缀数量大于1,那么它们之中存在一个公共前缀,其长度为它们之间的height值的最小值。而我们分组之后,每组后缀之间height值的最小值大于等于k。所以,后缀数大于1的分组中,有可能存在满足题目限制条件的长度不小于k的子串。只要判断满足题目限制条件成立,那么说明存在长度至少为k的合法子串。
对于本题,限制条件是不重叠,判断的方法是,一组后缀中,起始位置最大的后缀的起始位置减去起始位置最小的后缀的起始位置>=k。满足这个条件的话,那么这两个后缀的公共前缀不但出现两次,而且出现两次的起始位置间隔大于等于k,所以不会重叠。
深刻理解这种height分组方法以及判断重叠与否的方法,在后面的问题中起到举足轻重的作用。
练习及题解:
http://hi.baidu.com/fhnstephen/blog/item/85a25b208263794293580759.html
5、最长的出现k次的重复(可重叠)子串。 PKU3261
使用后缀数组解题时,遇到“最长”,除了特殊情况外(如问题3),一般需要二分答案,利用height值进行分组。本题的限制条件为出现k次。只需判断,有没有哪一组后缀数量不少于k就可以了。相信有了我前面问题的分析作为基础,这个应该不难理解。注意理解“不少于k次”而不是“等于k次”的原因。如果理解不了,可以找个具体的例子来分析分析。
题目及题解:
http://hi.baidu.com/fhnstephen/blog/item/be7d15133ccbe7f0c2ce79bb.html
6、最长回文子串 ural1297
这个问题没有很直接的方法可以解决,但可以采用枚举的方法。具体的就是枚举回文子串的中心所在位置i。注意要分回文子串的长度为奇数还是偶数两种情况分析。然后,我们要做的,是要求出以i为中心的回文子串最长为多长。利用后缀数组,可以设计出这样一种求法:求i往后的后缀与i往前的前缀的最长公共前缀。我这里的表述有些问题,不过不影响理解。
要快速地求这个最长前缀,可以将原串反写之后接在原串后面。在使用后缀数组的题目中,连接两个(n个)字符串时,中间要用不可能会出现在原串中,不一样的非0号的字符将它们隔开。这样可以做到不影响后缀数组的性质。然后,问题就可以转化为求两个后缀的最长公共前缀了。具体的细节,留给大家自己思考...(懒...原谅我吧,都打这么多字了..一个多小时了啊TOT)
题目及题解:
http://hi.baidu.com/fhnstephen/blog/item/68342f1d5f9e3cf81ad576ef.html
7、求一个串最多由哪个串复制若干次得到 PKU2406
具体的问题描述请参考PKU2406.这个问题可以用KMP解决,而且效率比后缀数组好。
利用后缀数组直接解决本题也很困难(主要是,就算二分答案,也难以解决转变而成的判定性问题。上题也是),但可以同过枚举模板串的长度k(模板串指被复制的那个串)将问题变成一个后缀数组可以解决的判定性问题。首先判断k能否被n整除,然后只要看lcp(1,k+1)(实际在用c写程序时是lcp(0,k))是否为n-k就可以了。
为什么这样就行了呢?这要充分考虑到后缀的性质。当lcp(1,k+1)=n-k时,后缀k+1是后缀1(即整个字符串)的一个前缀。(因为后缀k+1的长度为n-k)那么,后缀1的前k个字符必然和后缀k+1的前k个字符对应相同。而后缀1的第k+1..2k个字符,又相当于后缀k+1的前k个字符,所以与后缀1的前k个字符对应相同,且和后缀k的k+1..2k又对应相同。依次类推,只要lcp(1,k+1)=n-k,那么s[1..k]就可以通过自复制n/k次得到整个字符串。找出k的最小值,就可以得到n/k的最大值了。
题目及题解:
http://hi.baidu.com/fhnstephen/blog/item/5d79f2efe1c3623127979124.html
8、求两个字符串的最长公共子串。Pku2774、Ural1517
首先区分好“最长公共子串”和“最长公共子序列”。前者的子串是连续的,后者是可以不连续的。
对于两个字符串的问题,一般情况下均将它们连起来,构造height数组。然后,最长公共子串问题等价于后缀的最长公共前缀问题。只不过,并非所有的lcp值都能作为问题的答案。只有当两个后缀分属两个字符串时,它们的lcp值才能作为答案。与问题3一样,本题的答案必然是某个height值,因为lcp值是某段height值中的最小值。当区间长度为1时,lcp值等于某个height值。所以,本题只要扫描一遍后缀,找出后缀分属两个字符串的height值中的最大值就可以了。判断方法这里就不说明了,留给大家自己思考...
题目及题解:
http://hi.baidu.com/fhnstephen/blog/item/8666a400cd949d7b3812bb44.html
http://hi.baidu.com/fhnstephen/blog/item/b5c7585600cadfc8b645aebe.html
9、重复次数最多的重复子串 SPOJ 687,Pku3693
难度比较大的一个问题,主要是罗穗骞的论文里的题解写得有点含糊不清。题目的具体含义可以去参考Pku3693.
又是一题难以通过二分枚举答案解决的问题(因为要求的是重复次数),所以选择朴素枚举的方法。先枚举重复子串的长度k,再利用后缀数组来求长度为k的子串最多重复出现多少次。注意到一点,假如一个字符串它重复出现2次(这里不讨论一次的情况,因为那是必然的),那么它必然包含s[0],s[k],s[2*k]...之中的相邻的两个。所以,我们可以枚举一个数i,然后判断从i*k这个位置起的长度为k的字符串能重复出现多少次。判断方法和8中的相似,lcp(i*k,(i+1)*k)/k+1。但是,仅仅这样会忽略点一些特殊情况,即重复子串的起点不在[i*k]位置上时的情况。这种情况应该怎么求解呢?看下面这个例子:
aabababc
当k=2,i=1时,枚举到2的位置,此时的重复子串为ba(注意第一位是0),lcp(2,4)=3,所以ba重复出现了2次。但实际上,起始位置为1的字符串ab出现次数更多,为3次。我们注意到,这种情况下,lcp(2,4)=3,3不是2的整数倍。说明当前重复子串在最后没有多重复出现一次,而重复出现了部分(这里是多重复出现了一个b)。如果我这样说你没有看懂,那么更具体地:
sa[2]=bababc
sa[4]=babc
lcp=bab
现在注意到了吧,ba重复出现了两次之后,出现了一个b,而a没有出现。那么,不难想到,可以将枚举的位置往前挪一位,这样这个最后的b就能和前面的一个a构成一个重复子串了,而假如前挪的一位正好是a,那么答案可以多1。所以,我们需要求出a=lcp(i*k,(i+1)*k)%n,然后向前挪k-a位,再用同样的方法求其重复出现的长度。这里,令b=k-a,只需要lcp(b,b+k)>=k就可以了。实际上,lcp(b,b+k)>=k时,lcp(b,b+k)必然大于等于之前求得的lcp值,而此时答案的长度只加1。没有理解的朋友细细体会下上图吧。
题目及题解:
http://hi.baidu.com/fhnstephen/blog/item/870da9ee3651404379f0555f.html
10.多个串的公共子串问题 PKU3294
首先将串连接起来,然后构造height数组,然后怎么办呢?
对,二分答案再判断是否可行就行了。可行条件很直观:有一组后缀,有超过题目要求的个数个不同的字符串中的后缀存在。即,假如题目要求要出现在至少k个串中,那么就得有一组后缀,在不同字符串中的后缀数大于等于k。
题目及题解:
http://hi.baidu.com/fhnstephen/blog/item/49c3b7dec79ec5e377c638f1.html
11、出现或反转后出现所有字符串中的最长子串 PKU1226
http://hi.baidu.com/fhnstephen/blog/item/7fead5020a16d2da267fb5c0.html
12、不重叠地至少两次出现在所有字符串中的最长子串 spoj220
http://hi.baidu.com/fhnstephen/blog/item/1dffe1dda1c98754cdbf1a35.html
之所以把两题一起说,因为它们大同小异,方法在前面的题目均出现过。对于多个串,连起来;反转后出现,将每个字符串反写后和原串都连起来,将反写后的串和原串看成同一个串;求最长,二分答案后height分组;出现在所有字符串中(反写后的也行),判断方法和10一样,k=n而已;不重叠见问题4,只不过这里对于每个字符串都要进行检验而已。
13、两个字符串的重复子串个数。 Pku3415
我个人觉得颇有难度的一个问题。具体的题目描述参看Pku3415。
大家可以移步到这:
http://hi.baidu.com/fhnstephen/blog/item/bf06d001de30fc034afb51c1.html
14、最后的总结
用后缀数组解题有着一定的规律可循,这是后缀的性质所决定的,具体归纳如下:
1、N个字符串的问题(N>1)
方法:将它们连接起来,中间用不会出现在原串中的,互不相同的,非0号字符分隔开。
2、无限制条件下的最长公共子串(重复子串算是后缀们的最长公共前缀)
方法:height的最大值。这里的无限制条件是对子串无限制条件。最多只能是两个串的最长公共子串,才可以直接是height的最大值。
3、特殊条件下的最长子串
方法:二分答案,再根据height数组进行分组,根据条件完成判定性问题。三个或以上的字符串的公共子串问题也需要二分答案。设此时要验证的串长度为len,特殊条件有:
3.1、出现在k个串中
条件:属于不同字符串的后缀个数不小于k。(在一组后缀中,下面省略)
3.2、不重叠
条件:出现在同一字符串中的后缀中,出现位置的最大值减最小值大于等于len。
3.3、可重叠出现k次
条件:出现在同一字符串中的后缀个数大于等于k。若对于每个字符串都需要满足,需要逐个字符串进行判断。
4、特殊计数
方法:根据后缀的性质,和题目的要求,通过自己的思考,看看用后缀数组能否实现。一般和“子串”有关的题目,用后缀数组应该是可以解决的。
5、重复问题
知道一点:lcp(i,i+k)可以判断,以i为起点,长度为k的一个字符串,它向后自复制的长度为多少,再根据具体题目具体分析,得出算法即可。