《模式识别》学习笔记(四)
前言
《模式识别》学习笔记主要参照哈尔滨工业大学出版社出版的《模式识别(第2版)》一书的内容,主要用于自己复习,如有侵权请速联系。
由于本人先自我学习的《数据挖掘与分析》和《机器学习》,所以在学习《模式识别》之前对此概念没有一个足够的认识,感觉《模式识别》讲述的可能是数据挖掘中的关联规则模式,与《机器学习》中的内容不搭边。但简单翻看一遍后便有了新的感悟,我们在人工智能领域所涉及到的所有项目,其实都可以归结为“模式识别”项目,例如,图像分类,自然语言处理等。而《机器学习》侧重于对数学概念的解析,《模式识别》侧重于整个工程方面的架构解析——前者偏向理论细节,后者偏向实践过程。
在这打一波广告,个人感觉哈工大出版社出版的《模式识别(第二版)》一书写的确实好,主要是读的很舒服,而且书中配套有代码,加深了对概念的理解。
往期目录
《概率论与数理统计》学习笔记(一)
《概率论与梳理统计》学习笔记(二)
《模式识别》学习笔记(一)
《模式识别》学习笔记(二)
《模式识别》学习笔记(三)
第七章 统计分类器及其学习
线性判别函数分类器和非线性判别函数分类器,这些分类器的共同点是通过对训练样本集的学习构造一个能够将不同类别样本区分开的判别函数,根据判别函数的输出来决定待识别模式属于哪个类别,这类方法所采用的模型一般被称作判别式模型。本章将要介绍另外一类被称作产生式模型的方法,这类方法不是直接构造能够区分不同类别的判别函数,而是考察观察到的待识模式由不同类别所产生的概率,根据不同类别产生出待识模式的概率大小来决定它的类别属性。
首先,可以将描述待识模型的特征矢量x看作是一个随机矢量。每次输入到分类器的特征矢量是不同的,即使是根据同一类别的两个不同模式所生成的特征矢量,一般来说也不会是一样的。虽然属于同一类别的特征适量是不同的,但它们的分布是有一定规律的。每个类别样本的分布情况可以看作是通过一次随机试验所得到的观察值,待识别的特征矢量可能属于任何一个类别,因此样本所属的类别w也可以看作是一个随机变量。只不过w只是有限的n个取值,是一个离散的随机变量。产生式模型方法对待识别模式x的判别,依据的是每一个类别产出矢量x的概率,哪个类别更有可能性产生出x,就将x判别为哪个类别。
一、贝叶斯决策理论
(一)常用的概率表示形式
1、类先验概率P(wi)
先验概率是类别wi发生的概率,因为分类器只能将样本x分为c个类别中的某一个类被,因此有
![]()
如果关于待识模式本身没有任何信息,在没有生成特征矢量x的情况下,仍然要对气进行分类,那么只能根据每个类别的先验概率进行判别,哪个类别的先验概率最大就认为待识模式属于哪个类别。例如在水果识别的例子中,如果识别系统不适用摄像机拍摄每个输入水果的图像,让计算机直接猜它是桃子还是句子。在这种情况下,只能估计一下今年果园中的两种水果大致的产量,哪一种的数量多(先验概率大),那么就将待识别的水果判别未这一类,只有这样才能够使得“猜”对的可能性更大。
2、后验概率P(wi|x)
显然,仅仅依靠每个类别的先验概率进行分类,对实际问题来说是没有什么意义的。模式识别系统总是要获取一些待识模型自身的信息,生成特征矢量x,这种情况下就可以在一直特征矢量x的条件下来分析各个类别发生概率的大小了。所以说,模式识别系统进行分类时依据的不是类别的系那样爱侣而是后验概率,看到了模式特征之后每个类别的概率。
3、类条件概率密度
分类器所需要按照后验概率的大小进行分类,然而实际情况是后验概率往往无法直接得到,能够得到的是每个类别的先验概率和每个类别的类条件概率密度函数。
先验概率描述的是关于识别问题中每个类别的先验知识,哪个类别发生的可能性更大,可以根据训练样本集中各类样本所占的比例进行估计。类条件概率密度描述的是每一个类别样本的分布情况,类条件概率密度可以用属于每个类别的训练样本来估计。
将后验概率、先验概率和类条件概率联系在一起的是贝叶斯公式:
![]()
p(x)是样本x发生的先验概率密度。
后面的分析中会看到p(x)在分类器的构建中是可以忽略的。
贝叶斯分类器是根据输入模式x的后验概率大小进行分类的,将其判别为后验概率最大的类别,而在实际计算中则是根据贝叶斯公式将后验概率转化为先验概率和类条件概率密度的乘积。
(二)最小错误率准则贝叶斯分类器
从前面的分析可以看出,分类器应该根据每个类别后验概率P(wi|x)的大小来判别待识别样本x的类别属性。按照上述方式进行分类,可以识别的错误率最小。如果希望分类器识别的错误率最小,就应该将x判别为后验概率最大的一个类别,即
如果i=argmaxP(wj|x),则判别x∈wi
由于后验概率无法直接计算,因此需要使用贝叶斯公式由先验概率和类条件概率密度来间接计算,而由于计算每个类别的后验概率时p(x)是相同的,我们直接提取出固定的因子1/p(x),更新上式得到:
如果i=argmaxg(x)=p(x|wi)P(wj),则判别x∈wi
(三)最小平均风险准则贝叶斯分类器
大多数的模式识别应用中,是以最小错误率为准则建立的贝叶斯分类器,然而对于某些问题来说这样的准则并不合适。这是因为每次误判所带来的后果并不一样,有一些类别的样本被误判的后果非常严重,而另一些类别被误判的后果并不十分严重。对于误判结果重视的识别问题,不仅需要考虑识别的结果是否准确,同时还需要考虑做出每一次判断所带来的风险。
因此,在解决这些问题的时候,首先需要根据实际情况引入一组“风险值”来评估将某类样本误识为另一个类别所要付出的代价,令lamda ij为将wi类样本判别为wj类的代价或风险,如果分类器将待识模型识别为wj类,而x的真实类别属性可能是w1到wn的任何一个,做出这个判别的平均风险是每个类别样本被分类为wj所带来的风险经由后验概率加权求和之后的结果。
二、高斯分布贝叶斯分类器
贝叶斯分类器依据类条件概率密度p(x|wi)和先验概率P(wi)来判别样本x的类别属性,因此在构建分类器时需要估计出每个类别的先验概率,并且确定类条件概率密度。作为类条件概率密度的“概率模型”可以有很多种形式,这需要根据解决的具体问题来确定。高斯分布由于其形式简单、易于分析,并且在很多实际应用中能够取得较好的识别效果,因此常常被用来作为贝叶斯分类器的概率模型。
(一)高斯分布的判别函数
高斯分布就是正态分布,单变量的高斯分布公式为:
![]()
其中均值 和方差
和方差 为高斯分布的参数。
为高斯分布的参数。
通过第一章我们知道:gi(x)= p(x|wi)P(wi),为了方便运算,我们将对公式进行转为对数判别函数,同时将高斯密度函数带入,得到:
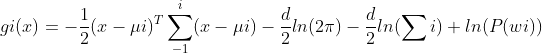
下面我们讨论几种特殊情况:
1、协方差等于方差,P(wi)=1/c
这种情况下,每个类比的先验概率相同,协方差矩阵为相同的对角矩阵,且主对角线元素均为方差,不同的只有均值矢量miu i。因此,上式改为:
![]()
2、协方差矩阵相同
这种情况中,每个类别的先验概率不同,分布的均值不同,只有协方差矩阵相同但不是对角矩阵。
这时,上式退化为:
gi(x) = wi x + wi0
(具体过程我也没弄明白,但是用到了协方差矩阵是对称矩阵的概念)
即这时的贝叶斯分类器转变为了线性分类器,对应于扩展感知器算法的判别函数,wi时每个线性判别函数的权值矢量,wi0则是只与类别有关的常数项。
(二)朴素贝叶斯分类器
想要使用贝叶斯分类器得到较好表现的条件是每个类别符合高斯分布,并且能够估计出高斯分布均值矢量和协方差矩阵,这就要求样本的特征维数要足够大。所以,朴素贝叶斯分类器的提出就是用来解决多特征、少样本贝叶斯分类的问题。
朴素贝叶斯分类器的一个基本假设是所有特征在类别已知的条件下是相互独立的,在构建分类器时,需要逐个估计出每个类别的训练样本在每一维特征上的分布,就可以得到每个类别的条件概率密度,大大减少了需要估计参数的数量。长话短说,最后化简完得到公式:

miu ij 是第i类样本在j维特征上的均值
sigma ij^2 是相应的方差
(三)改进的二次判别函数
一般情况下,高斯分布贝叶斯分类器的判别函数是(一)中所述那种二次函数,在判别函数中需要计算每个类别协方差矩阵的逆矩阵,前文中总是认位协方差矩阵的逆矩阵是存在的,然而实际情况并不是这样的,当特征恶的维数d很大时,同一类别的训练样本可能只是分布在特征空间中的一个子空间,特征之间存在着相关性,由这些样本计算的协方差矩阵是一个奇异矩阵,并不存在逆矩阵;即使协方差矩阵不是奇异矩阵,也有可能接近于奇异矩阵,对应的行列式值非常小,逆矩阵的计算会非常不稳定。
为了提高二次判别函数分类器的计算稳定性,并且减少计算和存储的复杂度,提出了改进的二次判别函数(MQDF)方法。MQDF将二次判别函数与主成分分析结合,首先计算每个类别协方差矩阵的特征值分解,保留大的特征值对应的主要成分部分,化简小的特征值部分的计算。
三、概率密度函数的参数估计
(一)最大似然估计
在参数估计法中,虽然知道了概率密度函数的形式,但是具体的分布函数还是未知的。即使知道来自同一个高斯分布,但这个高斯分布也可能在任意的位置,具有任意的宽度。只有确定了高斯分布的均值和方差之后,蔡锷能够真正得到具体的概率密度函数。参数估计的核心就是要估计出概率密度函数。
最大似然估计的目标是要从所有可能的分布中,寻找一个最有可能产生出训练样本集的分布,也就是要找到一组“最优”的参数,使得由这组参数所确定的分布最有可能产生出所有的训练样本。
(二)高斯混合模型
到目前为止,都是以每个类别的样本满足高斯分布为例来介绍的贝叶斯分类准则和类条件概率密度函数的参数估计。高斯分布贝叶斯分类器能够适用于任意的模式分类问题吗?答案显然是否定的。高斯分布只是概率密度函数的一种选择,实际问题是千差万别的,每个类别的样本都可能呈现出不同的分布形式,只有估计出每个类别的概率密度函数才能够保证贝叶斯分类的准确率。当希望使用参数估计的方法学习贝叶斯分类器时,设计者所面临的第一个问题可能就是每个类别的样本来自于怎样的分布?如何确定类条件概率密度函数的形式?
而高斯混合模型就是一种在没有先验知识的条件下“通用”的参数模型,因为可以证明,在满足一定 的条件下高斯混合模型能够以任意的精度逼近任意的概率密度函数。高斯混合模型是由K个高斯分布的线性组合构成的,其中每一个高斯分布也被称为是一个分量。高斯混合模型的学习,同样需要使用最大似然估计的方法来估计参数,但是过程要比高斯分布复杂的多。这时我们会采用“期望最大化算法(EM)”来估计GMM(高斯混合模型)的参数。
(三)期望最大算法
初始化参数 1,设置收敛精度
1,设置收敛精度 ,迭代次数t=0;
,迭代次数t=0;
循环:t<-t+1:
E步:根据![]() 来计算Q
来计算Q
M步:![]()
直到满足收敛条件![]() -
-![]() >
>
(四)隐含马尔可夫模型
到目前为止,我们介绍的各种识别和分类方法所针对的都是以特征适量方式描述的模式,但是在有些实际问题中,模式是以序列形式出现的。例如基因序列,消费者的一系列购买行为等。还有一些模式具有明显的时间延迟性,例如在语音识别和人体行为识别中,声音和人体的动作都是发生在一个时间段内,如果将这个时间段内的音频或者视频信号采用特定矢量的方式描述,就会损失掉信号的先后次序变化信息。对于有时间延迟性的模式,一种常用的描述方法是将信号华为为一系列短的时间段,在每一个时间段提取信号的特征,并将这些特征连接形成一个特征矢量序列,这样就可以有效地描述信号在不同时间段内的变化信息。如果希望采用贝叶斯分类器识别以序列形式出现的模式,就需要构建描述序列的概率密度函数,计算每个类别产生出需要识别序列的概率密度,隐含哈尔科夫模型就是一种常用的序列概率密度描述模型。马尔可夫模型还引申出了隐含马尔可夫模型。从隐含马尔可夫模型又能延伸出估值问题,解码问题和学习问题。
四、概率密度函数的非参数估计
1、parzen窗方法:根据训练样本数n来决定体积V
2、近邻法:根据训练样本n来决定R中包含的样本数k