Matching Networks for One Shot Learning 论文笔记
前言
人类可以从很少的样本中获取新的概念,比如一个小孩儿能从书中的一张图片知道什么是长颈鹿。但是对于深度学习系统来说,要学习一个新的类别需要成百上千的样本。因此对one-shot learning的研究就变得非常重要。什么是one-shot learning呢?也就是让系统能从很小一部分的带标记的样本中学习一个新类别。
深度学习一般需要较大型的数据集,当数据集变小时,会产生过拟合问题,数据增强和正则化技术虽然能够缓解过拟合,但不能完全解决这个问题。而且,就算使用数据增强和正则化,学习速度依然很慢,并且仍要基于较大的数据集,要使用SGD进行很多次的权重更新。作者认为,这主要是由于模型的参数化方面(parametric aspect),这些模型就是参数化模型(parametric model),即训练样本需要通过模型来缓慢地学习它的参数。
与参数化模型相反,非参数化模型(non-parametric model)允许新样本被快速地同化,即快速学习新样本。比如最近邻模型(nearest neighbors)不需要任何训练,它的性能取决于所选择的度量。本文的目标是将参数化模型和非参数化模型中的最佳特征结合起来,即快速获取新样本,同时对常见样本进行归纳。
本文的贡献有以下几个方面:
- 模型的提出:本文提出了Matching Nets(MN),它是一种神经网络,利用了attention和memory,从而能够快速地学习;
- 训练过程:本文的训练过程基于一个简单的机器学习原则,即测试和训练的条件必须匹配。也就是说,为了使MN能够快速学习,在训练网络时每个类别只有很少的样本,就和测试的时候一样,在测试的时候会提供一个新类别,而这个新类别中也只包含很少的样本。
- 为ImageNet和Omniglot上的one-shot learning实验设置了benchmark
模型的设计
本文提出了一种非参数化方法,用以处理one-shot learning,它基于以下两个部分:
- 本文的模型结构采用的是记忆增强的神经网络,给定一个支持集(support set) S S S,本文的模型为每个 S S S定义了一个函数 c s c_s cs(或分类器),即一个映射 S → c s ( ⋅ ) S \to c_s(\cdot) S→cs(⋅);
- 本文采用的训练策略是专门为了从支持集 S S S中进行one-shot learning
1. 模型结构
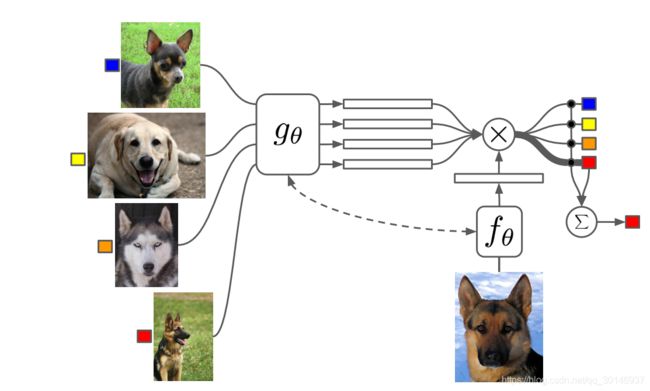
为神经网络结构附加external memory是一种有效的扩增方式,在这一类模型中,出现了一种神经注意力机制(neural attention mechanism),也就是通过访问存储有用信息的记忆矩阵(memory matrix)来处理任务。比如在seq2seq模型中,external memory用于对 P ( B ∣ A ) P(B|A) P(B∣A)进行建模,其中 A A A和 B B B都是序列;而在本文的MatchingNet中, A A A和 B B B是一个集合。
MatchingNet在训练时,能够为还没有被观察到的类别生成合理的测试标签,并且网络不需要任何的改变。具体来说就是:
- 训练过程:给定一个有 k k k个样本的支持集 S = { ( x i , y i ) } i = 1 k S=\lbrace(x_i,y_i) \rbrace^k_{i=1} S={(xi,yi)}i=1k,定义一个 S S S到分类器 c S ( x ^ ) c_S(\hat x) cS(x^)的映射,其中 x ^ \hat x x^是测试样本, c S ( x ^ ) c_S(\hat x) cS(x^)就是输出 y ^ \hat y y^的概率分布,也就是对 x ^ \hat x x^进行分类。将映射 S → c S ( x ^ ) S \to c_S(\hat x) S→cS(x^)定义为 P ( y ^ ∣ x ^ , S ) P(\hat y|\hat x,S) P(y^∣x^,S),该映射对每个未见过的测试样本 x ^ \hat x x^给出其标签 y ^ \hat y y^,该标签让 P P P得到最大值,也即 P P P是通过网络学到的参数。
- 测试过程:给定一个新的支持集 S ′ S^{'} S′,使用之前学到的由 P P P定义的参数化神经网络来为每个测试样本 x ^ \hat x x^预测标签 y ^ \hat y y^,即 P ( y ^ ∣ x ^ , S ′ ) P(\hat y|\hat x,S^{'}) P(y^∣x^,S′)
模型可以表示为:

其中 x i x_i xi和 y i y_i yi分别是支持集 S S S的样本和标签, a a a是一种注意力机制(attention mechanism),类似attention模型中的核函数。上式的 y ^ \hat y y^是一个新类的输出,它是支持集中标签的线性组合。
- 如果 a a a是 X × X X \times X X×X上的一个核,即 a a a作为核函数时,上式类似于一个核密度估计量,那么模型可近似为:DL做嵌入层,KDE做分类层;
- 如果根据某种距离度量,距离 x ^ \hat x x^最远的 x i x_i xi的注意力机制 a a a为0,即 a a a作为一个0-1函数时,上式相当于 k − b k-b k−b最近邻,模型可近似为:DL做嵌入层,KNN做分类层。
对于上式还有另一种解读:将注意力机制 a a a和memory y i y_i yi绑定到相应的 x i x_i xi上。在这种情况下,上式可以被理解为一种associative memory,即给定一个输入,然后指向支持集中的相应的样本,检索其标签。
上式不同于其它注意力记忆机制(attentional memory mechanism)的地方在于,它是非参数化的,即由 c S ( x ^ ) c_S(\hat x) cS(x^)定义的函数非常灵活,可以很容易地适应任何新的支持集。
2. attention kernal
等式(1)依赖于对注意力机制 a ( . , . ) a(.,.) a(.,.)的选择,它必须特定于分类器。最简单的形式是在余弦距离上使用softmax函数:
![]()
其中 f f f是嵌入函数,定义了如何对测试样本编码成向量, g g g也是嵌入函数,定义了如何对训练样本编码, c ( ⋅ ) c(\cdot) c(⋅)是余弦距离,用来计算两者之间的匹配度。上式对训练样本 x i x_i xi和测试样本 x ^ \hat x x^分别进行embedding,然后求内积(cosine),这就是文章提出的"matching",此时,模型的预测结果就是支持集中attention最多的图像的标签。
由等式(1)定义的分类器是有判别力的,给定一个支持集 S S S和样本 x ^ \hat x x^,对 x ^ \hat x x^来说,总能在支持集中找到一对儿 ( x ′ , y ′ ) ∈ S (x^{'},y^{'})\in S (x′,y′)∈S,与 x ^ \hat x x^相符合,因此输出 y y y就等于 y ′ y^{'} y′,也就是让 x ^ \hat x x^与标签为 y y y的样本对齐,和其它的不对齐,这种loss其实就是和NCA,triplet loss和margin nearest neighbor相关的。
3. 对训练集进行编码(对函数g的优化)
尽管通过 P ( ⋅ ∣ x ^ , S ) P(\cdot |\hat x,S) P(⋅∣x^,S)在整个支持集上做分类,但每个 x i x_i xi都独立于支持集 S S S中的其它元素通过 g ( x i ) g(x_i) g(xi)获得embedding,因此文章也将支持集 S S S作为输入,即 g g g变为 g ( x i , S ) g(x_i,S) g(xi,S),这样的话,作为整个支持集 S S S的函数, g g g也可以修改 x i x_i xi的嵌入方式。当某个元素 x j x_j xj非常接近 x i x_i xi时,改变 x i x_i xi的嵌入方式是很有用的。
g g g的结构是一个双向LSTM,这个双向LSTM的输入序列是 S S S中的各个样本 ( x 0 , x 1 , x 2 , . . . ) (x_0,x_1,x_2,...) (x0,x1,x2,...),也就是说把 S S S看成一个序列,然后对每个 x i x_i xi进行编码,公式如下,其中 g ′ ( x i ) g^{'}(x_i) g′(xi)是 x i x_i xi输入到神经网络时进行的一个原始编码:
![]()
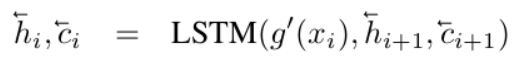
其中 h i h_i hi和 c i c_i ci都为LSTM的输出。
4. 对测试集进行编码(对函数f的优化)
支持集 S S S应该能够通过 f f f修改测试图像 x ^ \hat x x^的嵌入方式,也即支持集样本可以用来修改测试样本的embedding模型。这可以通过一个固定步数的LSTM和对支持集 S S S的attention模型来解决,公式如下,

其中 f ′ ( x ^ ) f^{'}(\hat x) f′(x^)只依赖测试样本自己的特征,作为LSTM的输入, K K K是LSTM的步数, g ( S ) g(S) g(S)是支持集 S S S的embedding,最后 f f f的编码结果为最后一步LSTM输出的隐状态。模型会忽略支持集 S S S中的一些样本。
训练策略
文章对imagenet进行的采样,制作了3种适合做one/few shot的数据集,其中miniImageNet,它包含100个类,每类600张图片,其中80个类用来训练,20类用来测试, 称为后续相关研究经常被采用的数据集。以5-way 5-shot为例。训练时,在80类中随机采样5个类,然后把这5类中的数据分成支持集 S S S和测试 B B B,训练MatchingNet模型来使得在 S S S条件下的 B B B的预测结果误差最小。测试时,在20个未被训练过的类中抽取5类,每类5张图,作为测试支持集 S ′ S^{'} S′。如下图所示,MatchNet方法相对原始的Inception模型能正确识别模型从未见过的轮胎和自行车。

参考
https://blog.csdn.net/mao_feng/article/details/78939864
https://zhuanlan.zhihu.com/p/32101204
https://blog.csdn.net/hustqb/article/details/83861134?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task