【语义分割】SETR_Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformer
文章目录
-
- 一、主要思想
- 二、实现方法
- 三、实现效果
- 四、代码

一、主要思想
目前语义分割的方法中,主要是以FCN为主导的一系列基于encoder-decoder的方法,但这类方法在捕捉long-range信息上的能力较弱:
- 为了提高感受野,出现了 PSP/ASPP/attention等方法
- 这些方法主要利用了原图经过下采样后的特征图,也就是利用了高层信息来进行感受野的提升,缺乏了对低层信息的利用。
本文方法:
- 提出了一种完全使用transformer的语义分割方法
- 输入:将原图等分成固定大小的patch,形成一个 sequece of image patch,之后使用 linear embedding layer 来得到 a sequence of feature embedding vectors 作为transformer的输入
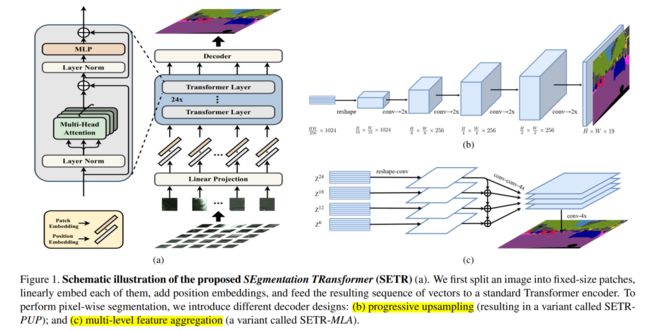
二、实现方法
1、将图片转化成序列化的patch:
将 x ∈ R H × W × 3 x\in R^{H\times W \times 3} x∈RH×W×3 切分成统一大小的 H 16 × W 16 \frac{H}{16} \times \frac{W}{16} 16H×16W,然后将这些patch拉平
2、线性投影: f : p → e ∈ R C f : p \to e \in R^C f:p→e∈RC
使用线性投影 f 将 patch 映射到一个 C 维的 embedding space,于是就从一个2维的图像得到了一个一维的序列
3、位置编码:
为了对每个patch的空间信息编码,作者给每个位置 i i i上的 patch 学习了一个特殊的位置编码 p i p_i pi,加到 e i e_i ei 上,来得到最终的输入 E = e 1 + p 1 , e 2 + p 2 , . . . , e l + p l E = {e_1+p_1, e_2+p_2,...,e_l+p_l} E=e1+p1,e2+p2,...,el+pl
4、Transformer:
Transformer 使用上述得到的 E 作为输入,则意味着其可以获得全局的感受野,解决 FCN 等方法感受野有限的问题。
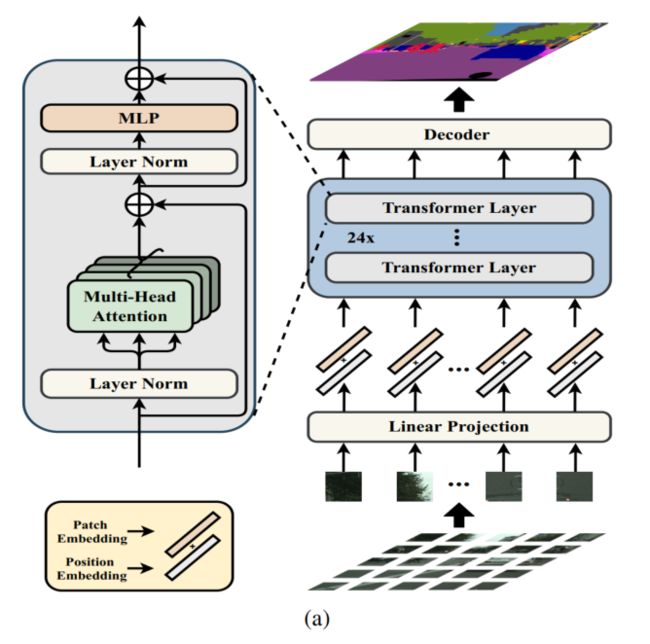
4、Decoder
Decoder的作用:生成和原图大小一致的2维分割结果
所以,这里需要把 encoder 的特征 Z 从 H W 256 \frac{HW}{256} 256HW reshape 成 H 16 × W 16 × C \frac{H}{16} \times \frac{W}{16} \times {C} 16H×16W×C。
方法一:Naive upsampling (Naive)
① 将transformer得到的特征 Z L e Z^{L_e} ZLe 映射到分割类别数(如cityscape就是19)
1x1 conv + sync batch norm (with relu) + 1x1 conv
② 使用双线性插值进行上采样,然后计算loss
方法二:Progressive UPsampling (PUP)
使用渐进上采样,使用卷积核上采样交替变换来实现,为了避免直接上采样多倍带来的误差,这个上采样方法每次只上采样2倍,也就是说如果要把大小为 H 16 × W 16 \frac{H}{16} \times \frac{W}{16} 16H×16W 的 Z L e Z^{L_e} ZLe 上采样到原图大小,需要进行4次操作。

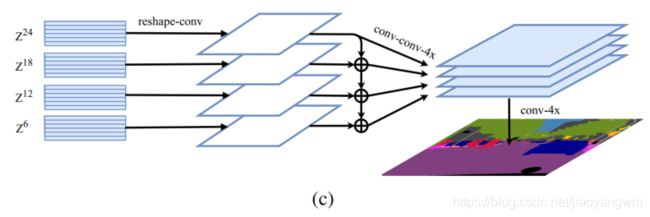
方法三:Multi-Level feature Aggregation(MLA)
使用多层特征聚合,也就是将跨层分布的特征 { Z m } ( m ∈ { L e m , 2 L e m , . . . , M L e m } ) \{Z^m\} (m \in \{\frac{L_e}{m}, 2\frac{L_e}{m},..., M\frac{L_e}{m}\}) {Zm}(m∈{mLe,2mLe,...,MmLe}) 作为输入(间隔步长为 L e m \frac{L_e}{m} mLe),输入到decoder中。
之后,部署了M个流(stream),每个着重注意一个layer,每个流内:
- 首先将encoder的特征 Z l Z_l Zl 从 2D ( H W 256 × C \frac{HW}{256} \times C 256HW×C) reshape 到 3D ( H 16 × W 16 × C \frac{H}{16} \times \frac{W}{16} \times C 16H×16W×C)
- 之后使用一个3层的网络 (kelnel size 1x1,3x3,3x3) :
- 在第一层和第三层通道数分别减半,且在第三层之后,使用双线性插值将特征图上采样4倍。
- 其次为了提高不同流之间的信息交互,作者在第一层之后引入了一个 top-down 的逐点相加的聚合机制,并在该相加操作后使用了一个 3x3 卷积
- 第三层之后,可以通过concat来把所有 stream 的特征融合起来,然后再使用双线性插值把特征图上采样 4 倍到原图大小。
5、Auxiliary loss:
每个 auxiliary loss 后面都跟一个 2 层的网络,作者在以下不同的 transformer layers 都加了 auxiliary loss:
- SETR-Naive ( Z 10 , Z 15 , Z 20 Z^{10},Z^{15},Z^{20} Z10,Z15,Z20)
- SETR-PUP ( Z 10 , Z 15 , Z 20 , Z 24 Z^{10},Z^{15},Z^{20},Z^{24} Z10,Z15,Z20,Z24)
- SETR-MLA ( Z 6 , Z 12 , Z 18 , Z 24 Z^{6},Z^{12},Z^{18},Z^{24} Z6,Z12,Z18,Z24)
三、实现效果
在 ADE20K 和 Pascal VOC 的效果对比:


在cityscape上的效果对比:
不同层的可视化:


四、代码
代码路径:https://github.com/fudan-zvg/SETR
框架:mmsegmentation
# 1、source 环境
source activate mmsegmentation
# 2、编译库路径
python setup develop.py

# config 文件
configs/SETR/
修改数据路径:
configs/_base_/dataset/cityscapes/py