TaskTracker节点上的内存管理器
Hadoop平台的最大优势就是充分地利用了廉价的PC机,这也就使得集群中的工作节点存在一个重要的问题——节点所在的PC机内存资源有限(这里所说的工作节点指的是TaskTracker节点),执行任务时常常出现内存不够的情况,如:堆溢出错误;同时,该PC机也可能部署了其它集群的工作节点。针对这个问题,Hadoop专门在TaskTracker节点内部设计了一个后台线程——任务内存管理器(TaskMemoeryManagerThread),来管理工作节点使用的内存。其核心思想就是:一方面监控每一个正在执行的任务所占用的内存量,当某一个任务所占用的内存超过它所设置的最大使用内存时,就kill掉这个任务;另一方面也统计TaskTracker节点当前使用内存的总量,当这个总量超过管理员设置的内存上限值时,它就会选择一些合适的任务kill掉,以使得该工作节点使用的内存总量总是低于这个阈值。这个内存管理组件是可开关的,意思就是说如果TaskTracker节点设置的内存的使用上限值,则TaskTracker节点在其内部就会开启这个管理组件,否则,TaskTracker节点就不会开启这个管理组件。当我们部署的Hadoop集群与其它的集群共享硬件平台时,往往需要为集群中的工作节点配置内存使用上限制。另外,如果我们的Hadoop集群独享硬件平台的话,笔者也建议设置这个内存使用上限值,以便TaskTracker节点可以开启内存管理器,其原因将会在下面详细讲到。
首先来看看如何给一个TaskTracker节点设置内存使用上限?这个上限值totalMemoryAllottedForTasks通过该节点上设置的可同时执行的Map/Reduce任务最大数量和执行每一个Map/Reduce任务可使用的最大内存来确定,其具体计算如下:
- public static final long DISABLED_MEMORY_LIMIT = -1L;
- static final String MAPRED_CLUSTER_MAP_MEMORY_MB_PROPERTY = "mapred.cluster.map.memory.mb";
- static final String MAPRED_CLUSTER_REDUCE_MEMORY_MB_PROPERTY = "mapred.cluster.reduce.memory.mb";
- maxCurrentMapTasks = conf.getInt("mapred.tasktracker.map.tasks.maximum", 2);
- maxCurrentReduceTasks = conf.getInt("mapred.tasktracker.reduce.tasks.maximum", 2);
- mapSlotMemorySizeOnTT = fConf.getLong( JobTracker.MAPRED_CLUSTER_MAP_MEMORY_MB_PROPERTY, JobConf.DISABLED_MEMORY_LIMIT);
- reduceSlotSizeMemoryOnTT = fConf.getLong(JobTracker.MAPRED_CLUSTER_REDUCE_MEMORY_MB_PROPERTY, JobConf.DISABLED_MEMORY_LIMIT);
- totalMemoryAllottedForTasks = maxCurrentMapTasks * mapSlotMemorySizeOnTT + maxCurrentReduceTasks * reduceSlotSizeMemoryOnTT;
首先必须强调的是,TaskTracker节点的内存管理器所监控的内存使用量指的是JVM实例使用的内存(JVM进程是该工作节点为执行分配的Map/Reduce任务而开启)。当一个TaskTracker节点设置了内存使用上限值时,它就会在启动的时候开启这个内存管理器TaskMomeryManagerThread,显然,TaskMomeryManagerThread是一个后台工作线程,它的工作流程如下:
- public void run() {
- LOG.info("Starting thread: " + this.getClass());
- while (true) {
- // Print the processTrees for debugging.
- if (LOG.isDebugEnabled()) {
- StringBuffer tmp = new StringBuffer("[ ");
- for (ProcessTreeInfo p : processTreeInfoMap.values()) {
- tmp.append(p.getPID());
- tmp.append(" ");
- }
- LOG.debug("Current ProcessTree list : " + tmp.substring(0, tmp.length()) + "]");
- }
- //监控新添加的任务
- synchronized (tasksToBeAdded) {
- processTreeInfoMap.putAll(tasksToBeAdded);
- tasksToBeAdded.clear();
- }
- //取消对已完成任务的监控
- synchronized (tasksToBeRemoved) {
- for (TaskAttemptID tid : tasksToBeRemoved) {
- processTreeInfoMap.remove(tid);
- }
- tasksToBeRemoved.clear();
- }
- long memoryStillInUsage = 0;
- //计算正在节点上执行的任务所占用的内存总和
- for (Iterator<Map.Entry<TaskAttemptID, ProcessTreeInfo>> it = processTreeInfoMap.entrySet().iterator(); it.hasNext();) {
- Map.Entry<TaskAttemptID, ProcessTreeInfo> entry = it.next();
- TaskAttemptID tid = entry.getKey();
- ProcessTreeInfo ptInfo = entry.getValue();
- try {
- String pId = ptInfo.getPID();
- // Initialize any uninitialized processTrees
- if (pId == null) {
- // get pid from pid-file
- pId = getPid(ptInfo.pidFile);
- if (pId != null) {
- // PID will be null, either if the pid file is yet to be created
- // or if the tip is finished and we removed pidFile, but the TIP
- // itself is still retained in runningTasks till successful
- // transmission to JT
- // create process tree object
- ProcfsBasedProcessTree pt = new ProcfsBasedProcessTree(pId);
- LOG.debug("Tracking ProcessTree " + pId + " for the first time");
- ptInfo.setPid(pId);
- ptInfo.setProcessTree(pt);
- }
- }
- // End of initializing any uninitialized processTrees
- if (pId == null) {
- continue; // processTree cannot be tracked
- }
- LOG.debug("Constructing ProcessTree for : PID = " + pId + " TID = " + tid);
- ProcfsBasedProcessTree pTree = ptInfo.getProcessTree();
- pTree = pTree.getProcessTree(); // get the updated process-tree
- ptInfo.setProcessTree(pTree); // update ptInfo with proces-tree of
- // updated state
- long currentMemUsage = pTree.getCumulativeVmem();
- // as processes begin with an age 1, we want to see if there
- // are processes more than 1 iteration old.
- long curMemUsageOfAgedProcesses = pTree.getCumulativeVmem(1);
- long limit = ptInfo.getMemLimit();
- LOG.info("Memory usage of ProcessTree " + pId + " :" + currentMemUsage + "bytes. Limit : " + limit + "bytes");
- //检查当前任务所占用的内存是否超过了它所设置的最大内存使用量
- if (isProcessTreeOverLimit(tid.toString(), currentMemUsage, curMemUsageOfAgedProcesses, limit)) {
- // Task (the root process) is still alive and overflowing memory.
- // Clean up.
- String msg = "TaskTree [pid=" + pId + ",tipID=" + tid + "] is running beyond memory-limits. Current usage : " + currentMemUsage + "bytes. Limit : " + limit + "bytes. Killing task.";
- LOG.warn(msg);
- taskTracker.cleanUpOverMemoryTask(tid, true, msg);
- //kill掉当前正在执行的任务,由于它的内存使用超过限制.
- pTree.destroy();
- it.remove();
- LOG.info("Removed ProcessTree with root " + pId);
- } else {
- // Accounting the total memory in usage for all tasks that are still
- // alive and within limits.
- memoryStillInUsage += currentMemUsage;
- }
- } catch (Exception e) {
- // Log the exception and proceed to the next task.
- LOG.warn("Uncaught exception in TaskMemoryManager " + "while managing memory of " + tid + " : " + StringUtils.stringifyException(e));
- }
- }
- //如果内存使用总量超过设置的上限值则组要kill合适的正在执行的任务
- if (memoryStillInUsage > maxMemoryAllowedForAllTasks) {
- LOG.warn("The total memory in usage " + memoryStillInUsage + " is still overflowing TTs limits " + maxMemoryAllowedForAllTasks + ". Trying to kill a few tasks with the least progress.");
- killTasksWithLeastProgress(memoryStillInUsage);
- }
- // Sleep for some time before beginning next cycle
- try {
- LOG.debug(this.getClass() + " : Sleeping for " + monitoringInterval + " ms");
- Thread.sleep(monitoringInterval);
- } catch (InterruptedException ie) {
- LOG.warn(this.getClass() + " interrupted. Finishing the thread and returning.");
- return;
- }
- }
从上面的代码可以看出,TaskMemoeryManagerThread的工作流程很简单,它每隔monitoringIntervalms 就会统计一次正在运行的任务所占用的系统总内存,如果该TaskTracker节点当前正在执行的任务占用的总内存超过设置的阈值,内存管理器就会kill掉一些正在执行的任务,以保证内存使用总量低于这个阈值。不过,在统计之前,它需要加上新运行的任务,删除已经运行完了的任务。Task内存使用量的统计间隔时间monitoringInterval是通过TaskTracker节点的配置文件来设置的,对应的配置项为:mapred.tasktracker.taskmemory.monitoring-interval。这里就有一个问题了,TaskTracker节点是把每一个Map/Reduce任务交给对应的一个JVM实例来执行的,那么内存管理器是如何准确的获取到这些JVM进程的内存使用量的?
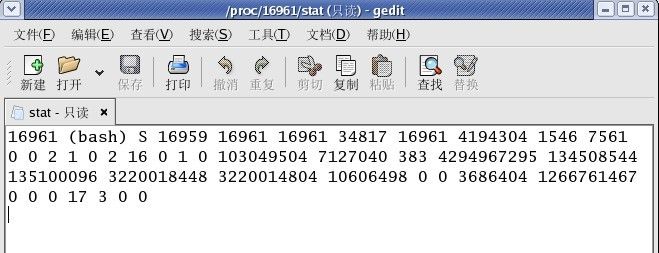
首先,TaskTracker节点在开启一个JVM实例来运行一个Map/Reduce任务时,会得到这个JVM实例的进程Id号;然后,它会把这个Map/Reduce任务实例和对应的JVM进程Id号一起交给TaskMemoeryManagerThread来管理和监控。我们知道,在Linux操作系统中,进程的相关信息(如cpu使用率,内存使用量)都存储在/proc/*/stat目录下,例如,进程Id号为16961的进程相关信息存放在文件/proc/16961/stat中(如下图所示)。而TaskMemoeryManagerThread正是通过读取并解析这个文件来获取该进程的内存使用量。另外,Linux系统中有进程树的概念,即一个进程可以创建若干个进程,这样就可能存在这样的情况,JVM实例在执行Task的时候可能创建了子进程,所以,为了统计准确就为每一个JVM进程创建了一个进程树使得在计算一个任务耗费的内存时可以加上它所有孙子进程占用的内存了。
再来谈一下为什么要建议给一个TaskTracker节点配置内存上限值以便其开启内存管理器。如果一个TaskTracker节点不开启内存管理器的话,那么默认的,每一个JVM实例可无节度地使用内存,直至达到系统的总内存容量(可能还包括虚拟内存)。这样的情况经常会使得JVM实例抛出运行时堆溢出错误,同时发生错误的JVM实例可能运行的Task即将完成,这无疑会严重地影响Job的执行效率。但如果一个TaskTracker节点开启了内存管理器,则当它使用的内存总量达到设置的上限值,它会选择一些合适的任务kill掉来保证那些进度大的任务避免发生内存不够的错误,这个选择策略如下:
1).第一优先选择Reduce任务;
2).第二优先选择进度小的任务。
话又说回来,一个不会开启子进程的任务所能使用的内存上限最终取决于系统分配给对应的JVM实例的内存总量,为了解决一些特殊的作业内存限制问题,Hadoop在Job级别开放了一个设置参数来配置运行该作业任务的JVM内存分配,该配置项为:mapred.child.java.opts,值的形式如:–Xms256m –Xmx256m –Xmn64m。
笔者在研究Hadoop-0.20.2.0版本的时候发现了一个有关TaskTracker节点内存管理器的bug:当TaskTracker节点接到JobTracker节点的重启命令之后,会关闭一系列的相关组件,然后再初始化并重启这些组件,但如果TaskTracker节点配置了内存管理器之后,它在TaskTracker节点的重启之前不会被关闭,但在重启之后TaskTracker又会重新创建一个内存管理器,由于内存管理器对应一个后台线程,所以就使得系统中同时有多个存活的内存管理器。
[转]http://blog.csdn.net/xhh198781/article/details/7446686