机器学习----聚类算法
1、聚类算法介绍
1.1 聚类算法在现实中的应用
-
用户画像,广告推荐,搜索引擎的流量推荐,恶意流量识别
-
基于位置信息的商业推送,新闻聚类,筛选排序
-
图像分割,降维,识别;离群点检测;信用卡异常消费;发掘相同功能的基因片段
1.2 聚类算法的概念
聚类算法:
一种典型的无监督学习算法,主要用于将相似的样本自动归到一个类别中。
在聚类算法中根据样本之间的相似性,将样本划分到不同的类别中,对于不同的相似度计算方法,会得到不同的聚类结果,常用的相似度计算方法有欧式距离法。
1.3 聚类算法和分类算法(knn)最大区别
聚类算法是无监督的学习算法,而分类算法属于监督的学习算法。
2、Sklearn实现KMeans聚类
2.1 api介绍
sklearn.cluster.KMeans(n_clusters=8)
参数: n_clusters:开始的聚类中心数量 整型,n_clusters=8,生成的聚类数,即产生的质心(centroids)数。
方法: estimator.fit(x) estimator.predict(x) estimator.fit_predict(x)计算聚类中心并预测每个样本属于哪个类别,相当于先调用fit(x),然后再调用predict(x)
2.2 案例
1、创建数据集
import matplotlib.pyplot as plt
from sklearn.datasets.samples_generator import make_blobs
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
# 创建数据集
# X为样本特征,Y为样本簇类别, 共1000个样本,每个样本2个特征,共4个簇,
# 簇中心在[-1,-1], [0,0],[1,1], [2,2], 簇方差分别为[0.4, 0.2, 0.2, 0.2]
X, y = make_blobs(n_samples=1000, n_features=2, centers=[[-1, -1], [0, 0], [1, 1], [2, 2]],
cluster_std=[0.4, 0.2, 0.2, 0.2],
random_state=9)
# 数据集可视化
plt.scatter(X[:, 0], X[:, 1], marker='o')

2、使用k-means进行聚类,并使用silhouette_score(轮廓系数)评估
model = KMeans(n_clusters=2, random_state=9)
y_pred = model.fit_predict(X)
# 分别尝试n_cluses=2\3\4,然后查看聚类效果
plt.scatter(X[:, 0], X[:, 1], c=y_pred)
plt.show()
# 用轮廓系数评估的聚类分数
silhouette_score(X, y_pred)
# 0.6435178953651656
3、聚类原理详解
3.1 距离的度量(相似性度量)
Euclidean Distance(欧式距离) 定义:

其他距离衡量:余弦值(cos), 相关度 (correlation), 曼哈顿距离 (Manhattan distance)
曼哈顿距离:纽约曼哈顿的街区比较平整,我们从P1起点到P2起点,首先横向跨越三个街区,在纵向跨越2个街区就达到P2点了。
3.2 Kmean算法原理
3.2.1 K-means算法详解
K-几个聚类中心,Mean-均值,每次迭代的时候使用均值方式迭代
-
K : 初始中心点个数(计划聚类数)
-
means:求中心点到其他数据点距离的平均值
Clustering 中的经典算法,数据挖掘十大经典算法之一
算法接受参数 k ;然后将事先输入的n个数据对象划分为 k个聚类以便使得所获得的聚类满足:同一聚类中的对象相似度较高;而不同聚类中的对象相似度较小。
算法思想:
以空间中k个点为中心进行聚类,对最靠近他们的对象归类。通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果

算法终止条件:迭代次数/簇中心变化率/最小平方误差和SSE
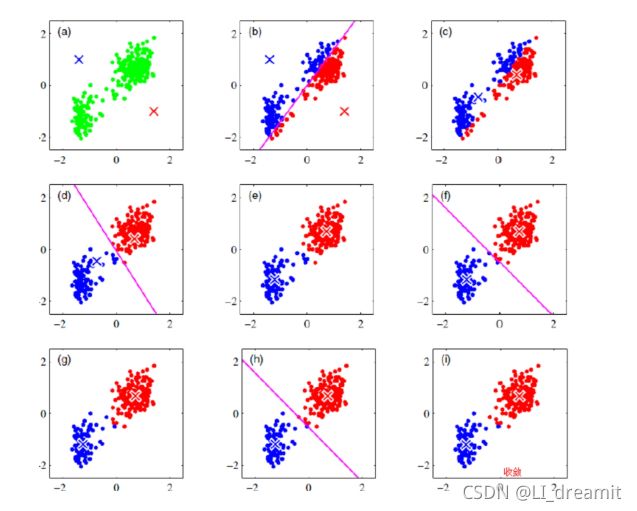
算法核心步骤梳理:
计算距离---归类-----计算均值---距离----归类----均值----距离--.........
(1)求解第i个样本xi到达第j个聚类中心的距离,选择j最小的值赋值给第i个样本的标记值。
(2)对于属于第j个样本的所有的xj求均值,作为第j个样本的新的聚类中心,聚类中心改变了,重新计算标记信息,标记变了重新计算距离。
算法流程巩固:
输入:k, data[n];
(1) 选择k个初始中心点,例如c[0]=data[0],…c[k-1]=data[k-1];
(2) 对于data[0]….data[n], 分别与c[0]…c[k-1]比较,假定与c[i]差值最少,就标记为i;
(3) 对于所有标记为i点,重新计算c[i]={所有标记为i的data[j]之和}/标记为i的个数;
(4) 重复(2)(3),直到所有c[i]值的变化小于给定阈值。
3.2.2 K-Mean性能评价指标
1、SSE误差平方和
SSE表示数据样本与它所属的簇中心之间的距离(差异度)平方之和。直观的来说,SSE越小,表示数据点越接近它们的中心,聚类效果越好。因为对误差取了平方,更加重视那些远离中心的点。
2、肘部法

(1)对于n个点的数据集,迭代计算k from 1 to n,每次聚类完成后计算每个点到其所属的簇中心的距离的平方和;
(2)平方和是会逐渐变小的,直到k==n时平方和为0,因为每个点都是它所在的簇中心本身。
(3)在这个平方和变化过程中,会出现一个拐点也即“肘”点,下降率突然变缓时即认为是最佳的k值。在决定什么时候停止训练时,肘形判据同样有效,数据通常有更多的噪音,在增加分类无法带来更多回报时,我们停止增加类别。
3、轮廓系数
结合了聚类的凝聚度(Cohesion)和分离度(Separation),用于评估聚类的效果:

目的:内部距离最小化,外部距离最大化
计算样本i到同簇其他样本的平均距离ai,ai 越小样本i的簇内不相似度越小,说明样本i越应该被聚类到该簇。
计算样本i到最近簇Cj 的所有样本的平均距离bij,称样本i与最近簇Cj 的不相似度,定义为样本i的簇间不相似度:bi =min{bi1, bi2, ..., bik},bi越大,说明样本i越不属于其他簇。
求出所有样本的轮廓系数后再求平均值就得到了平均轮廓系数。
平均轮廓系数的取值范围为[-1,1],系数越大,聚类效果越好。
簇内样本的距离越近,簇间样本距离越远
3.2.3 K-Mean算法特点
优点:速度快,简单
对处理大数据集,该算法保持可伸缩性和高效率
当簇近似为高斯分布时,它的效果较好。
空间复杂度o(N),时间复杂度o(IKN)(N为样本点个数,K为中心点个数,I为迭代次数)
缺点:最终结果跟初始点选择相关,容易陷入局部最优,需直到k值
-
k均值算法中k是实现给定的,这个k值的选定是非常难估计的。
-
k均值的聚类算法需要不断地进行样本分类调整,不断地计算调整后的新的聚类中心,当数据量大的时候,算法开销很大。
-
k均值是求得局部最优解的算法,所以对于初始化时选取的k个聚类的中心比较敏感,不同点的中心选取策略可能带来不同的聚类结果。比如实际分类5类的情况却只进行了3均值的聚类。
-
对噪声点和孤立点数据敏感。
-
KMeans一般是其他聚类方法的基础算法,如谱聚类。
4. 聚类分析案例
4.1 聚类分析案例1:年龄与收入人群聚类
# 年龄与收入分群
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 加载数据
ageinc_df=pd.read_csv('data/ageinc.csv')
ageinc_df.info()
ageinc_df.describe()
# 数据标准化
#(收入-收入均值)/收入标准差
ageinc_df['z_income']=(ageinc_df['income']-ageinc_df['income'].mean())/ageinc_df['income'].std()
#(年龄-年龄均值)/年龄标准差
ageinc_df['z_age']=(ageinc_df['age']-ageinc_df['age'].mean())/ageinc_df['age'].std()
ageinc_df.describe()
# 数据可视化
sns.scatterplot(x='income',y='age',data=ageinc_df)
#将群体分成3层
#用标准化的收入与年龄来拟合模型
from sklearn.cluster import KMeans
model =KMeans(n_clusters=3,random_state=10)
model.fit(ageinc_df[['z_income','z_age']])
# 为用户打上标签
ageinc_df['cluster']=model.labels_
# 查看用户的分群情况
ageinc_df.head(50)
# 将分群结果可视化
sns.scatterplot(x='age',y='income',hue='cluster',data=ageinc_df)
4.2 聚类分析案例2:顾客数据聚类分析
# 导入数据并查看数据情况
import pandas as pd
airbnb=pd.read_csv('data/airbnb.csv')
airbnb.info()
airbnb.head()
# 单变量分析
airbnb.describe()
# 发现年龄最小是2最大是2014,属于数据异常,进行数据清洗,这里保留用户年龄在18-70岁之间的群体
airbnb=airbnb[airbnb['age']<=70]
airbnb=airbnb[airbnb['age']>=18]
airbnb.age.describe()
# 日期数据处理
#将注册日期转变为日期时间格式
airbnb['date_account_created']=pd.to_datetime(airbnb['date_account_created'])
airbnb.info()
#将年份从中提取出来,将2019 -注册日期的年份,并生成一个新的变量year_since_account_created
airbnb['year_since_account_created']=airbnb['date_account_created'].apply(lambda x: 2019-x.year)
airbnb.year_since_account_created.describe()
# 计算用户第一次预定到2019年的时间
airbnb['date_first_booking']=pd.to_datetime(airbnb['date_first_booking'])
airbnb['year_since_first_booking']=airbnb['date_first_booking'].apply(lambda x:2019-x.year)
airbnb.year_since_first_booking.describe()
# 选择五个变量,作为分群的维度
airbnb_5=airbnb[['age','web','moweb','ios','android']]
# 数据标准化,使用sklearn中预处理的scale
from sklearn.preprocessing import scale
x=pd.DataFrame(scale(airbnb_5))
# 使用cluster建模
from sklearn.cluster import KMeans
# 尝试分为3类
model=KMeans(n_clusters=3,random_state=10)
model.fit(x)
# 提取标签,查看分类结果
airbnb_5['cluster']=model.labels_
airbnb_5.head(10)
# 模型评估与优化
#使用groupby'函数,评估各个变量维度的分群效果
airbnb_5.groupby(['cluster'])['age'].describe()
airbnb_5.groupby(['cluster'])['ios'].describe()
# 使用silhouette_score,评估模型效果
from sklearn.metrics import silhouette_score #调用sklearn的metrics库
x_cluster = model.fit_predict(x) #个体与群的距离
score = silhouette_score(x,x_cluster) #评分越高,个体与群越近;评分越低,个体与群越远
score
centers=pd.DataFrame(model.cluster_centers_)
centers.to_csv('center_3.csv')
# 将群体分为5组
model=KMeans(n_clusters=5,random_state=10)
model.fit(x)
centers=pd.DataFrame(model.cluster_centers_)
centers.to_csv('center_5.csv')
