超大规模的产业实用语义分割数据集PSSL与预训练模型开源啦!
语义分割作为最“精细”的计算机视觉任务,与目标检测、图像分类等技术相比,需对每个像素点进行分类。如在无人驾驶领域中,需要精确分割出行人、车辆及其他道路环境相关物体,进而根据此类信息进行精准避障;在医疗领域,需通过对病灶形状大小的精准掌握,才能对病情进行定性分析;在影视领域的特效制作场景,对于人像抠图的精细要求甚至达到了发丝级别,因此针对精细化分类任务的语义分割技术在以上场景上都发挥了关键的作用。
市面上语义分割技术数据集通常仅覆盖通用场景且数据量在千级左右,而真实业务中场景多变,在不额外加入大量数据的情况下,基于通用数据集训练的模型在产业实践中的分割效果往往不达标。
为了解决上述产业痛点,飞桨语义分割开发套件PaddleSeg发布了120+万张ImageNet伪标签分割数据集PSSL[5](Pseudo Semantic Segmentation Labels)并且实现在五大下游任务(CamVid,VOC-A,VOC-C,ADE20K, Cityscapes)上mIoU提高了1-5%不等。同时,PaddleSeg开放了完整的预训练模型及策略,缓解了小样本带来的模型精度不达标的问题,目前相关成果已在Machine Learning期刊发表,欢迎大家查阅~

- 数据集及模型下载链接:
https://github.com/PaddlePaddle/PaddleSeg
★ 记得Star收藏 ★
防止走丢又实时关注更新
(https://mmbiz.qpic.cn/mmbiz_png/sKia1FKFiafggkHYlAgYRWvfESbqLjLVAq3Oaibfa0r9K9L6RN8nD6QUuNrSbtlU9t7OdsXxP3Yxdibs0iaPWfgCrtQ/640?wx_fmt=png)]
下面具体看看PSSL数据集与预训练模型策略到底是如何发挥作用的吧!
****PSSL
语义分割伪标签分割数据集****
PSSL是具有120+万张和1000类别的语义分割伪标签数据集,伪标签指的则是区别于手动标注,由模型自动生成的标签,而PSSL是由百度自研的可解释性算法自动生成。目前常见的语义分割数据集有Pascal VOC, ADE20K, Cityscapes等,它们的样本数量约为5千到2万,类别约为19到80。而PSSL具有120+万的样本数和1000的类别,是常见数据集的近百倍,因此PSSL数据集具有数量更多、类别更丰富的优势,能克服产业实践中场景多样化带来的挑战。
同时,构建语义分割数据集时往往会遇到标注难度大、制作成本高等困难,而PSSL以其自动生成的特性,能够很好地解决上述困难,维持数据集制作成本与质量之间的平衡。
那么PSSL数据集究竟是如何制作的呢?
有研究[1,2]显示,分类模型其实是识别到了物体的语义信息的,不过需要用一些可解释性算法来提取这些语义信息。那我们是否可以利用分类模型和可解释性算法,来自动构建一个分割数据集呢?毕竟,飞桨有超过100个分类模型[3]和一整套可解释性算法开源工具库[4]呢。单个模型的解释结果有时并不完美,于是我们使用百度自研的Consensus可解释性算法[2],从飞桨中挑选了20个准确性较高的分类模型,将它们的解释结果进行融合,得到噪声更小的语义信息。我们以此对ImageNet训练集里所有的图片进行语义提取,得到了120+万张图片的语义分割伪标签PSSL。
 单个模型与Consensus解释结果(最右)示意图
单个模型与Consensus解释结果(最右)示意图
借助PSSL来进行预训练,可以提升模型和分割效果,满足产业实践中对分割精度的要求。目前我们仅验证了PSSL对分割任务在mIoU指标上的提升[5],但是基于PSSL预训练效果非常鲁棒的特性,我们相信对于更多模型和更广泛任务,使用PSSL都会有提升。
预训练方法的改善
语义分割网络通常包含分类、分割两个模块,传统的语义分割预训练过程仅针对分类网络进行了初始化,未加载分割模块的预训练权重,然而分割模块设计上通常较为复杂,包含的参数量较多,一旦缺少分割模块的先验知识,将会导致下游任务的微调训练会非常困难,进而影响分割模型效果的提升。
如下图所示,对比于传统方式仅初始化分类模块,PSSL全新预训练策略则是在预训练阶段将分割模块也一起进行训练,进而降低下游任务的训练难度。
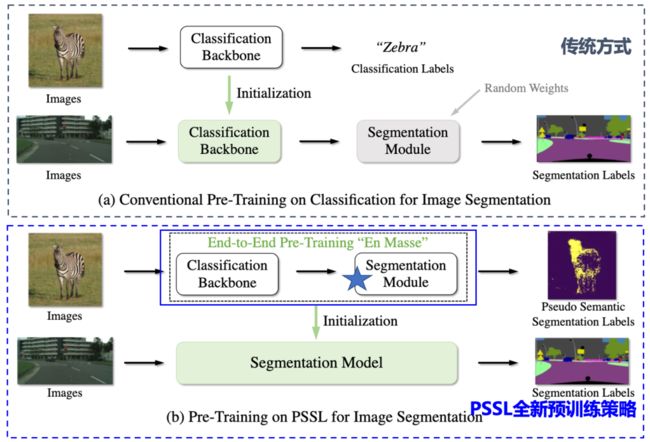
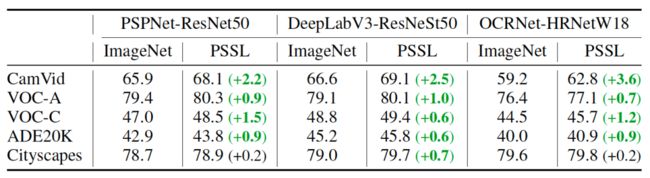
不仅如此,预训练完成后,无需修改代码,开发者直接加载预训练权重即可对下游任务进行预测。下表展示了三种模型应用全新预训练策略在PSSL数据集上的训练结果,可以看出,三种模型在五类下游任务上mIoU均得到了明显的提升。
** 成果开源
惊喜尽在PaddleSeg**
免费使用PSSL数据集
使用所在机构/公司的官方邮件系统,说明所在机构/公司的信息、使用数据集的目的,发送邮件至[email protected]
训练好的预训练模型
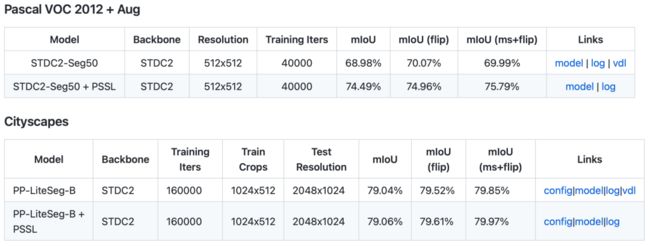
在最新版的PaddleSeg中,我们也提供了训练好的模型和训练过程记录,方便开发者省去预训练的过程。
- 模型链接:
https://github.com/PaddlePaddle/PaddleSeg/tree/release/2.6/configs/pssl
利用PSSL数据集和这种预训练方式,不管什么模型、什么数据,分割效果还能再提升1~5个点。这完全就是免费的午餐呀!
预训练教程全开放
当然,想要自己预训练的小伙伴我们也不拦着。预训练代码、PSSL数据集都已准备好,惊喜就在PaddleSeg,欢迎来试用。
- 参考链接:
https://github.com/PaddlePaddle/PaddleSeg/tree/release/2.6/configs/pssl#optional-pretraining
总而言之,PaddleSeg新增的PSSL数据集与预训练模型助力全面提升分割模型在下游任务上的性能,使得分割任务的产业落地更加简单!
引用:
[1] Zhou, B., Khosla, A., Lapedriza, A., Oliva, A., & Torralba, A. (2015). Learning Deep Features for Discriminative Localization. arXiv preprint arXiv:1512.04150.
[2] Li, X., Xiong, H., Huang, S., Ji, S., & Dou, D. (2021). Cross-model consensus of explanations and beyond for image classification models: An empirical study. arXiv preprint arXiv:2109.00707.
[3] https://github.com/PaddlePaddle/PaddleClas.
[4]https://github.com/PaddlePaddle/InterpretDL.
[5] Li, X., Xiong, H., Liu, Y., Zhou, D., Chen, Z., Wang, Y., & Dou, D. (2022). Distilling ensemble of explanations for weakly-supervised pre-training of image segmentation models. Machine Learning, 1-17.
关注【飞桨PaddlePaddle】公众号
获取更多技术内容~