写在前面
机器学习强基计划聚焦深度和广度,加深对机器学习模型的理解与应用。“深”在详细推导算法模型背后的数学原理;“广”在分析多个机器学习模型:决策树、支持向量机、贝叶斯与马尔科夫决策、强化学习等。
本期目标:实现这样一个效果

1.什么是线性模型
线性模型的假设形式是属性权重、偏置与属性的线性组合,即

称为广义线性模型(generalized linear model),其中g(⋅)称为联系函数(link function)。
广义线性模型本质上仍是线性的,但通过g(⋅)进行非线性映射,使之具有更强的拟合能力,类似神经元的激活函数。例如对数线性回归(log-linear regression)是g(⋅)=ln(⋅)时的情形,此时模型拥有了指数逼近的性质。
线性模型的优点是形式简单、易于建模、可解释性强,是更复杂非线性模型的基础。
2.感知机概述
感知机(Perceptron)是最简单的二分类线性模型,也是神经网络的起源算法,如图所示。

y=w^Tx^是 Rd空间的一条直线,因此感知机实质上是通过训练参数w^改变直线位置,直至将训练集分类完全,如图所示,或者参考文章开头的动图。

3.手推感知机原理
机器学习强基计划的初衷就是搞清楚每个算法、每个模型的数学原理,让我们开始吧!
感知机的损失函数定义为全体误分类点到感知机切割超平面的距离之和:

对于二分类问题y∈{−1,1},则误分类点的判断方法为
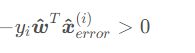

这在二分类问题中是个很常用的技巧,后面还会遇到这种等效形式。
从而损失函数也可简化为下面的形式以便于求导:
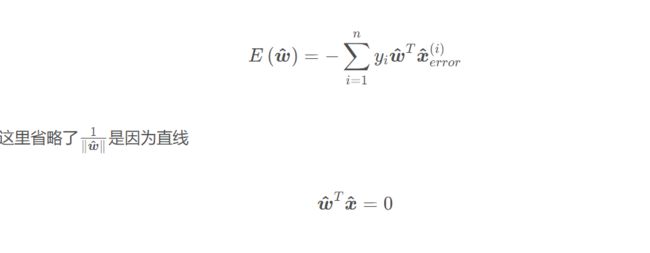
方程两边同时乘以系数都成立,所以直线系数 w^可以随意缩放,这里可令|w^|=1
若采用梯度下降法进行优化(梯度法可参考图文详解梯度下降算法的原理及Python实现),则算法流程为:

4.Python实现
4.1 创建感知机类
class Perceptron:
def __init__(self):
self.w = np.mat([0,0]) # 初始化权重
self.b = 0 # 初始化偏置
self.delta = 1 # 设置学习率为1
self.train_set = [[np.mat([3, 3]), 1], [np.mat([4, 3]), 1], [np.mat([1, 1]), -1]] # 设置训练集
self.history = [] # 训练历史
4.2 更新权重与偏置
def update(self,error_point):
self.w += self.delta*error_point[1]*error_point[0]
self.b += self.delta*error_point[1]
self.history.append([self.w.tolist()[0],self.b])
4.3 判断误分类点
def judge(self,point):
return point[1]*(self.w*point[0].T+self.b)
4.4 训练感知机
def train(self):
flag = True
while(flag):
count = 0
for point in self.train_set:
if(self.judge(point)<=0):
self.update(point)
else:
count += 1
if(count == len(self.train_set)):
flag = False
4.5 动图可视化
def show():
print("参数w,b更新过程:",perceptron.history)
anim = animation.FuncAnimation(fig, animate, init_func=init, frames=len(perceptron.history),
interval=1000, repeat=False,blit=True)
plt.show()
5.总结
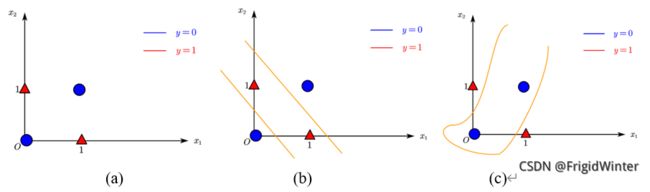
感知机最大的缺陷在于其线性,单个感知机只能表达一条直线,即使是如图(a)所示简单的异或门样本,都无法进行分类。对此有两种解决方式:
通过多条直线,即多层感知机(Multi-Layer Perceptron, MLP)进行分类,如图(b)所示;在线性加权的基础上引入非线性变换,如图(c)所示。
到此这篇关于图文详解感知机算法原理及Python实现的文章就介绍到这了,更多相关Python感知机算法内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!