实验——神经网络预测Fashion-MNIST数据集
文章目录
- 一 实验数据
- 二 实验要求
- 三 实验思路与代码
-
- 3.1 初始的设想
- 3.2 改进思路:矩阵运算
- 四 实验结果分析
- 参考:
一 实验数据
Fashion-MNIST数据集,数据集中包含 60000 张训练样本,10000 张测试 样本,可将训练样本划分为49000 张样本的训练集和1000 张样本的验证集,测 试集可只取1000 张测试样本。其中每个样本都是 28×28 像素的灰度照片,每 个像素点包括RGB三个数值,数值范围0 ~ 255,所有照片分属10个不同的类别。
灰度与像素值的关系:
-
图像的灰度化: 灰度就是没有色彩,RGB色彩分量全部相等。图像的灰度化就是让像素点矩阵中的每一个像素点都满足关系:R=G=B,此时的这个值叫做灰度值。如RGB(100,100,100)就代表灰度值为100,RGB(50,50,50)代表灰度值为50。
-
灰度值与像素值的关系: 如果对于一张本身就是灰度图像(8位灰度图像)来说,他的像素值就是它的灰度值,如果是一张彩色图像,则它的灰度值需要经过函数映射来得到。灰度图像是由纯黑和纯白来过渡得到的,在黑色中加入白色就得到灰色,纯黑和纯白按不同的比例来混合就得到不同的灰度值。R=G=B=255为白色,R=G=B=0为黑色,R=G=B=小于255的某个整数时,此时就为某个灰度值。
二 实验要求
-
用神经网络对给定的数据集进行分类,画出loss图,给出在测试集上的精确度;
-
不能使用 pytorch 等框架,也不能使用库函数,所有算法都要自己实现
-
神经网络结构图如下图所示:

-
整个神经网络包括 3 层——输入层,隐藏层,输出层。输入层有28x28x3个神经元,隐藏层有 50个神经元,输出层有 10 个神经元(对应 10 个类别)。
-
附加:可以试着修改隐藏层神经元数,层数,学习率,正则化权重等参数探究参数对实验结果的影响
三 实验思路与代码
实验要求设计一个三层的全连接神经网络,实现分类的功能。实验原理请见我的博客:神经网络基础与反向传播_Sunburst7的博客-CSDN博客
神经网络的每次迭代主要包括以下几个步骤:
- 传入训练图片灰度矩阵/数组
- 进行前馈运算,计算出输出层10个神经元预测的标签
- 与期望的标签计算Loss,更新隐含层(Hidden)到输出层(Output)的权值
- 计算隐含层的敏感度,更新输入层(Input)到隐含层的权值
- 传入测试图片灰度矩阵,进行预测。
- 统计
起初我的设计充满了面向对象的思想,导致在进行大数据集的运算时消耗时间很长,无法训练神经网络,受到参考【2】【3】【4】中博客的启发,改变思路,采用矩阵运算的思想成功训练出一个良好的神经网络。
3.1 初始的设想
我准备编写一个神经元类表示单个神经元,该神经元有以下属性,手绘原理图:

-
权值数组Weights:上一层与该神经元相连的所有神经元的权值
-
偏置Bias
-
输入值数组Inputs与输出值Output
-
激活函数
-
敏感度:定义可见实验原理博客
-
神经元类型Type:标识是输入层还是输出层还是隐含层神经元
每个神经元有两个函数,分别代表前馈与反向传播。
- 前馈:将输入值与权值进行向量的内积,加上偏置,在传入激活函数,输出最后的值
- 反向传播:对于输入层与输出层不同,利用传入的敏感度数组与权值数组更新自身的权值矩阵。
import numpy as np
def sigmoid(x):
if x>=0: #对sigmoid函数的优化,避免了出现极大的数据溢出
return 1.0/(1+np.exp(-x))
else:
return np.exp(x)/(1+np.exp(x))
class Neuron:
def __init__(self, weights, bias, ntype):
# 上一层与之相连的weights array
self.weights = weights
# 偏置 bias
self.bias = bias
# input array
self.inputs = 0
# 总的输出 z_k
self.output = 0
# 一个神经元的敏感度
self.sensitivity = 0.0
# 神经元的类型:Input Hidden Output
self.ntype = ntype
def __str__(self):
return "weights: \n"+str(self.weights)+"\nbias:\n"+str(self.bias)+"\ninputs:\n"+str(self.inputs)+"\noutput:\n"+str(self.output)+"\nsensitivity\n"+str(self.sensitivity)+"\ntype:\n"+str(self.ntype)
def feedForward(self, inputs:np.array):
"""
前馈
:param inputs: 输入的向量
:return:
"""
self.inputs = inputs
# weight inputs, add bias, then use the activation function
total = np.dot(self.weights, self.inputs) + self.bias
# 计算神经元的输出
# 如果是输入层,不需要带入激活函数f
if self.ntype == 'Input':
self.output = total
else:
self.output = sigmoid(total)
return self.output
def backPropagation(self ,eta ,tk ,sensitivities ,weights):
"""
反向传递更新权值
:param eta: 学习率
:param tk: 真实标签
:param sensitivities: 该神经元如果不是输出层,隐含层下一层所有神经元的敏感度
:param weights: 该神经元如果不是输出层,与该神经元相连的下一层的所有权值
:return:
"""
if self.ntype == 'Output':
# 计算f'(net)=f(net)*(1-f(net))
derivative_f = self.output*(1-self.output)
# 计算loss'(zk)=-(tk-zk)
derivative_loss = -(tk - self.output)
# 计算该神经元的敏感度 sensitivity = -f'(net)*loss'(zk)
self.sensitivity = -derivative_f*derivative_loss
# 更新权重
self.weights = self.weights + eta*self.sensitivity*np.array(self.inputs)
elif self.ntype == 'Hidden':
# 计算f'(net)=f(net)*(1-f(net))
derivative_f = self.output * (1 - self.output)
# 计算隐含层单元的敏感度 sensitivity = f'(net)*<下一层所有神经元的敏感度,该神经元与下一层相连的权重>
self.sensitivity = derivative_f*np.dot(sensitivities,weights)
# 更新权重
self.weights = self.weights + eta*self.sensitivity*np.array(self.inputs)
else:
return
再编写一个神经网络类构造三层神经元并进行feedForward与backPropagation的参数传递工作:
import numpy as np
import os
import gzip
from exp4.Neuron1 import Neuron
def sigmoid(x):
if x>=0: #对sigmoid函数的优化,避免了出现极大的数据溢出
return 1.0/(1+np.exp(-x))
else:
return np.exp(x)/(1+np.exp(x))
# 定义加载数据的函数,加载4个zip格式文件
def load_data(data_folder):
files = [
'train-labels-idx1-ubyte.gz', 'train-images-idx3-ubyte.gz',
't10k-labels-idx1-ubyte.gz', 't10k-images-idx3-ubyte.gz'
]
paths = []
for fname in files:
paths.append(os.path.join(data_folder,fname))
with gzip.open(paths[0], 'rb') as lbpath:
y_train = np.frombuffer(lbpath.read(), np.uint8, offset=8)
with gzip.open(paths[1], 'rb') as imgpath:
x_train = np.frombuffer(
imgpath.read(), np.uint8, offset=16).reshape(len(y_train), 28, 28)
with gzip.open(paths[2], 'rb') as lbpath:
y_test = np.frombuffer(lbpath.read(), np.uint8, offset=8)
with gzip.open(paths[3], 'rb') as imgpath:
x_test = np.frombuffer(
imgpath.read(), np.uint8, offset=16).reshape(len(y_test), 28, 28)
return (x_train, y_train), (x_test, y_test)
def makeTrueLabels(trueLabel):
"""
生成传递给输出层的期望标签数组
:param trueLabel:
:return:
"""
labels = []
for i in range(10):
if trueLabel == i:
labels.append(1)
else:
labels.append(0)
return labels
class NeuronNetwork:
def __init__(self,train_images,train_labels,test_images,test_labels):
self.inputLayer = []
self.hiddenLayer = []
self.outputLayer = []
self.train_images = train_images
self.train_labels = train_labels
self.test_images = test_images
self.test_labels = test_labels
# 从输入层到隐含层权值的初始化
initWeight_1 = np.random.uniform(-1/np.sqrt(784),1/np.sqrt(784),(50,784))
# 从隐含层到输出层权值的初始化
initWeight_2 = np.random.uniform(-1/np.sqrt(50),1/np.sqrt(50),(10,50))
# 偏置初始化
bias = np.random.normal(0,0.5,2)
# 初始化输入层
for i in range(784):
neuron = Neuron(1,0,ntype='Input')
self.inputLayer.append(neuron)
# 初始化隐藏层
for i in range(50):
neuron = Neuron(initWeight_1[i],bias[0],ntype='Hidden')
self.hiddenLayer.append(neuron)
# 初始化输出层
for i in range(10):
neuron = Neuron(initWeight_2[i],bias[1],ntype='Output')
self.outputLayer.append(neuron)
def iteration(self):
T = 0
N = 0
# 依次将60000章图片训练一边
for m in range(self.train_images.shape[0]):
# 输入层(784个神经元)的输出
y_i = []
# 对于每张图片的784个像素点
for row in range(self.train_images.shape[1]):
for col in range(self.train_images.shape[2]):
y_i.append(
self.inputLayer[28 * row + col].feedForward(inputs=np.array(train_images[m][row][col]))
)
# 隐藏层(50个神经元)的输出
y_h = []
for hidden_neuron in self.hiddenLayer:
y_h.append(hidden_neuron.feedForward(y_i))
# 输出层的标签:预测标签
y_o = []
for output_neuron in self.outputLayer:
y_o.append(output_neuron.feedForward(y_h))
# 进行预测,统计预测正误
forecastLabel = y_o.index(np.array(y_o).max())
if forecastLabel == train_labels[m]:
T+=1
else:
N+=1
# 期望值数组
trueLabels = makeTrueLabels(trueLabel=forecastLabel)
# 对输出层进行反向传播
output_sensitivities = [] # 输出层所有节点的敏感度
output_weights = [] # 输出层所有节点的权重
for i in range(10):
self.outputLayer[i].backPropagation(eta=0.1,tk=trueLabels[i],sensitivities=None,weights=None)
# 保存更新过的敏感度
output_sensitivities.append(self.outputLayer[i].sensitivity)
output_weights.append(self.outputLayer[i].weights)
# 对隐含层进行反向传播
for i in range(50):
# 隐含层每个神经元连接的10个输出层神经元的权值
linkedWeights = [arr[i] for arr in output_weights]
self.hiddenLayer[i].backPropagation(eta=0.1,tk=None,sensitivities=output_sensitivities,weights=linkedWeights)
return T, N
# 传入数据集
(train_images, train_labels), (test_images, test_labels) = load_data('')
train_images = train_images[0:500:1]
train_labels = train_labels[0:500:1]
"""
定义统计信息:
"""
n = 100
positive = []
negative = []
nn = NeuronNetwork(train_images=train_images,train_labels=train_labels,test_images=test_images,test_labels=test_labels)
for k in range(100):
T,N = nn.iteration()
positive.append(T)
negative.append(N)
该神经网络只能运行在少量的样本上,不能满足需要

3.2 改进思路:矩阵运算
之前思路中更新的过程太慢,每次都要一张一张图片传入,同时大量的对象也拖慢了运算的速度,因此我取消了神经元类,而在神经网络中保存两个矩阵,分别代表从输入层到隐含层与从隐含层到输出层的权值。

神经网络类通过输入层节点数、隐含层节点数、输出层节点数、学习率进行初始化,同时初始化两个权值矩阵以及一个偏置数组。
# 制作一个神经网络算法的类,其名为神经网络,相当于函数库,直接进行调用里面的函数即可。
class NeuralNetwork:
def __init__(self,inputNeurons,hiddenNeurons,outputNeurons,lr):
"""
神经网络构造方法
:param inputNeurons:输入层神经元个数
:param hiddenNeurons:隐含层神经元个数
:param outputNeurons:输出层神经元个数
:param lr:学习率
"""
self.iNeuron_num = inputNeurons
self.hNeuron_num = hiddenNeurons
self.oNeuron_num = outputNeurons
self.learnRate = lr # 学习率
self.f = lambda x: ssp.expit(x) # 设置激活函数f为Sigmod(x)激活函数
# 设置输入层与隐藏层直接的权重关系矩阵以及隐藏层与输出层之间的权重关系矩阵,初始值为正态分布
self.weights_i_h = np.random.normal(0.0, 1/np.sqrt(hiddenNeurons), (self.hNeuron_num, self.iNeuron_num))
self.weights_h_o = np.random.normal(0.0, 1/np.sqrt(hiddenNeurons), (self.oNeuron_num, self.hNeuron_num))
# 偏置初始化
self.bias = np.random.normal(0, 0.5, 2)
对输入的图片与标签进行两步处理:
-
归一化
- 对于图片将所有的灰度(0-255)全部映射到(0.01-0.99)上
- 对于每一个表示分类结果的标签(0-9)重新构造一个长度为10的数组,下标对应每个标签,若真实分类标签为8,则数组[7] = 0.99,其他位置的值为0.01,近似表示该图片真实标签的概率。
# 对60000张图片进行遍历 for i in range(60000): # 测试集的28*28矩阵转化为784的一维数组 img = train_images[i].reshape(train_images.shape[1]*train_images.shape[2]) # 进行归一化:除以255,再乘以0.99,最后加上0。01,保证所有的数据都在0.01到1.00之间 train_matrix[:,i] = (img/255.0)*0.99+0.01 # 建立准确输出结果矩阵,对应的位置标签数值为0.99,其他位置为0.01 # 第i张图片代表第i列,行数代表正确的标签 train_labels_matrix[train_labels[i],i] = 0.99 # 对10000章测试集图片进行处理 for i in range(10000): # 训练集的28*28矩阵转化为784的一维数组 test_img = test_images[i].reshape(test_images.shape[1] * test_images.shape[2]) # 更新输入到神经网络中的训练集矩阵 test_matrix[:,i] = (test_img/255.0)*0.99+0.01 # 建立准确输出结果矩阵,对应的位置标签数值为0.99,其他位置为0.01 test_label_matrix[test_labels[i],i] = 0.99 -
Reshape:将输入的图片灰度与标签从新组合

整个前馈的矩阵运算的过程如图:

BP的过程主要分为两个部分:
-
对于输出层到隐含层:
计算f'(net) = f(net)*(1-f(net)) 计算loss'(zk)=-(tk-zk) 计算对于每张图片该神经元的敏感度(10,60000): sensitivity = -f'(output_f_net)*loss'(zk) = (tk-zk)*f(output_f_net)*(1-f(output_f_net))[矩阵对应位置相乘] 更新权重:学习率*敏感度(10,60000) @ 50个隐含层层神经元的输出(60000,50) -
对于隐含层到输入层:
计算对于每张图片50个隐含层神经元的每一个神经元的从输出层传入的敏感度(50*60000): 输出层敏感度的加权和*f'(net) 更新权重
完整的训练过程如下:
def train(self,featuresMatrix,targetMatrix,iterateNum):
"""
神经网络一次训练
:param featuresMatrix: 784*60000的图片灰度矩阵 也是隐含层的输入
:param targetMatrix: 10*60000的期望值矩阵 tk
:param iterateNum: 迭代序号
:return: 返回训练正确率
"""
T = 0
N = 0
# 前馈 feedforward
# 隐藏层net(50*60000)计算
hidden_net = (self.weights_i_h @ featuresMatrix)+self.bias[0]
# 隐藏层输出f(hidden_net)
hidden_f_net = self.f(hidden_net)
# 输出层net(10*60000) 计算
output_net = (self.weights_h_o @ hidden_f_net)+self.bias[1]
# 输出层输出f(output_net) zk
output_f_net = self.f(output_net)
# 统计网络预测正确率
for imgIndex in range(60000):
# 返回输出层10个神经元最大值下标 与 预测标签
if output_f_net[:,imgIndex].argmax() == targetMatrix[:,imgIndex].argmax():
T+=1
else:
N+=1
print("第"+iterateNum+"次训练集迭代正确率:"+str(T/60000))
# 反向传播运算 backPropagation
# 对于输出层到隐含层
output_errors = targetMatrix - output_f_net
# 计算f'(net) = f(net)*(1-f(net))
# 计算loss'(zk)=-(tk-zk)
# 计算对于每张图片该神经元的敏感度(10,60000) sensitivity = -f'(net)*loss'(zk) = (tk-zk)*f(net)*(1-f(net))[矩阵对应位置相乘]
sensitivities = output_errors * output_f_net * (1.0 - output_f_net)
# 更新权重 学习率* 敏感度(10,60000) @ 50个隐含层层神经元的输出(60000,50)
self.weights_h_o += self.learnRate * (sensitivities @ hidden_f_net.T)
# 对于隐含层到输入层
# 计算对于每张图片50个隐含层神经元的每一个敏感度(50*60000) = 输出层敏感度的加权和*f'(net)
hidden_sensitivities = (self.weights_h_o.T @ sensitivities) * hidden_f_net * (1 - hidden_f_net)
# 更新权重
self.weights_i_h += self.learnRate * ( hidden_sensitivities @ featuresMatrix.T)
return T/60000
预测的过程就是进行一遍前馈的过程:
def test(self,testMatrix,targetMatrix,iterateNum):
"""
利用神经网络对训练集进行一次测试
:param testMatrix: 784*10000的灰度矩阵
:param targetMatrix: 10*10000的预测标签矩阵
:param iterateNum: 迭代序号
:return: 返回训练正确率
"""
T = 0
N = 0
# 前馈 feedforward
# 隐藏层net(50*60000)计算
hidden_net = (self.weights_i_h @ testMatrix) + self.bias[0]
# 隐藏层输出f(hidden_net)
hidden_f_net = self.f(hidden_net)
# 输出层net(10*60000) 计算
output_net = (self.weights_h_o @ hidden_f_net) + self.bias[1]
# 输出层输出f(output_net) zk
output_f_net = self.f(output_net)
# 统计网络预测正确率
for imgIndex in range(10000):
# 返回输出层10个神经元最大值下标 与 预测标签
if output_f_net[:, imgIndex].argmax() == targetMatrix[:, imgIndex].argmax():
T += 1
else:
N += 1
print("第" + iterateNum + "次测试集迭代正确率:" + str(T / 10000))
return T / 10000
调试与结果展示代码如下:
# 导入数据
(train_images, train_labels), (test_images, test_labels) = load_data('')
# 输出图片
# plt.imshow(train_images[0], cmap='Greys', interpolation='None')
# 初始化输入数据矩阵
train_matrix = np.zeros((784,60000))
test_matrix = np.zeros((784,10000))
# 初始化输出层期望值矩阵
train_labels_matrix = np.zeros((10,60000))+0.01
test_label_matrix = np.zeros((10,10000))+0.01
# 对60000张图片进行遍历
for i in range(60000):
# 测试集的28*28矩阵转化为784的一维数组
img = train_images[i].reshape(train_images.shape[1]*train_images.shape[2])
# 进行归一化:除以255,再乘以0.99,最后加上0。01,保证所有的数据都在0.01到1.00之间
train_matrix[:,i] = (img/255.0)*0.99+0.01
# 建立准确输出结果矩阵,对应的位置标签数值为0.99,其他位置为0.01
# 第i张图片代表第i列,行数代表正确的标签
train_labels_matrix[train_labels[i],i] = 0.99
# 对10000章测试集图片进行处理
for i in range(10000):
# 训练集的28*28矩阵转化为784的一维数组
test_img = test_images[i].reshape(test_images.shape[1] * test_images.shape[2])
# 更新输入到神经网络中的训练集矩阵
test_matrix[:,i] = (test_img/255.0)*0.99+0.01
# 建立准确输出结果矩阵,对应的位置标签数值为0.99,其他位置为0.01
test_label_matrix[test_labels[i],i] = 0.99
# 学习率
learn_rate = 0.000025
# 迭代次数
epochs = 100
# 初始化神经网络
nn = NeuralNetwork(784,50,10,learn_rate)
# 准确率数组
train_accuracy = []
test_accuracy = []
# 进行迭代
for i in range(epochs):
train_accuracy.append( nn.train(train_matrix,train_labels_matrix,str(i)) )
test_accuracy.append( nn.test(test_matrix,test_label_matrix,str(i)) )
# 画图
plt.plot(range(1,epochs+1),train_accuracy,'y')
plt.plot(range(1,epochs+1),test_accuracy,'g')
plt.legend(labels = ('train accuracy', 'test accuracy'), loc = 'lower right') # legend placed at lower right
plt.title("learn rate: "+str(learn_rate))
plt.xlabel('iteration')
plt.ylabel('accuracy')
plt.show()
四 实验结果分析
当学习率为0.1时,由于学习率过大导致更新的权重过大使得权重数组全为负值,继而在之后的迭代中计算激活能时是一个极大的复数,带入sigmod函数趋近于0,从而导致权值不再更新,正确率维持在0.1更新。


解决的方法是降低学习率,不让权值更新的过快,将学习率降低为0.000025时,迭代50次,整个模型有很大的优化:
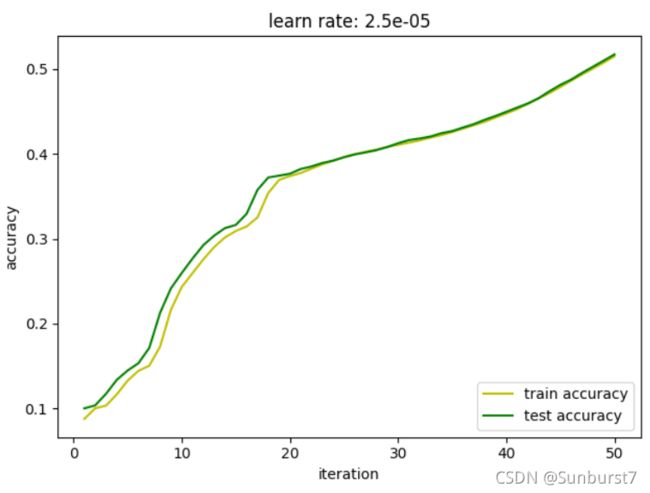
提高迭代次数至200次,预测正确率可以达到75%左右:

参考:
【1】神经网络基础与反向传播_Sunburst7的博客-CSDN博客
【2】识别MNIST数据集之(二):用Python实现神经网络_superCally的专栏-CSDN博客
【3】 用python创建的神经网络–mnist手写数字识别率达到98%_学习机器学习-CSDN博客_mnist手写数字识别python
【4】利用Python对MNIST手写数据集进行数字识别(初学者入门级)_仲子_real-CSDN博客_mnist手写数字识别python