nanodet阅读:(3)Loss计算及推理部分
一、前言
loss的计算是一个AI工程代码的核心之一,nanodet的损失函数与yolo v3/5系列有很大不同,具体见Generalized Focal Loss,说实话一开始看这个损失函数博客,没看明白,后来看完代码才看懂,作者虽然简单讲了一下,但是讲的很到位,结合代码来看,一目了然。损失函数源代码较为复杂,各种调用、各种变换,看的头疼。为此整理了一份流程图,简单参考一下。
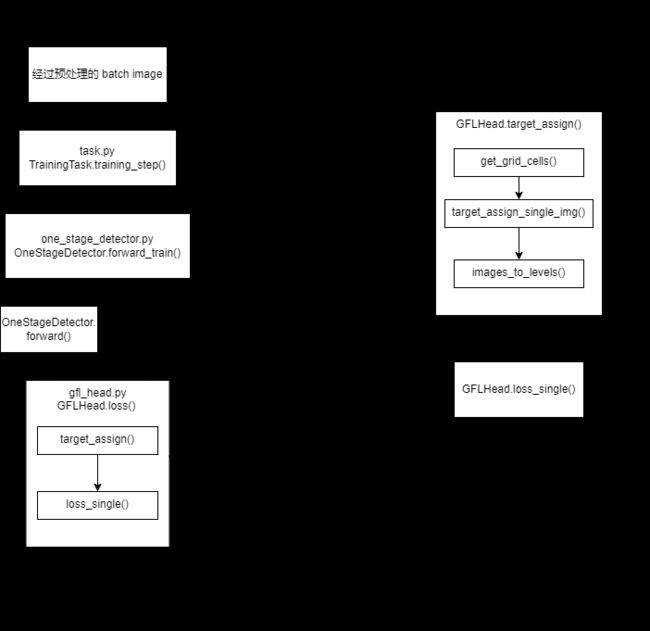
二、正文
loss部分代码较多,全部贴出来反而会妨碍阅读,欲详细了解的,去看代码注释吧——loss函数主体代码、gfocal_loss代码。下文大致讲讲loss的组成及相关细节。
nanodet的loss分为两种——GIOU loss和gfocal_loss,后者可细分为quality focal loss与distribution focal loss。其中GIOU loss与distribution focal loss对应模型的目标bbox输出,quality focal loss对应模型的目标类别输出。
1.GIOU loss
GIOU loss很常见了,预测的bbox值与相匹配的gt bbox标签做损失函数输入。先说说预测的bbox值怎么来的。
class Integral(nn.Module):
def __init__(self, reg_max=16):
super(Integral, self).__init__()
self.reg_max = reg_max # 7
self.register_buffer(
"project", torch.linspace(0, self.reg_max, self.reg_max + 1) # 返回一维 tensor = [0, 1, 2, 3, ... reg_max]
)
# input x.shape = (N, 4 * (reg_max + 1))
def forward(self, x):
x = F.softmax(x.reshape(-1, self.reg_max + 1), dim=1) # softmax 之后,数据就是 (0, 1)之间了
x = F.linear(x, self.project.type_as(x)).reshape(-1, 4) # 与 self.project 做矩阵相乘,返回 (0, reg_max) 之间的数
return x
模型输出的原始bbox值,先经softmax变换为一组概率值。为什么用概率来表示bbox位置呢,按照李翔大佬的说法:在复杂场景中,边界框的表示具有很强的不确定性,而用概率来衡量一个事物的不确定性,是很合适的。如下图所示,概率值与reg_max数组做点积输出的值就是anchor中心与bbox某一条边的预测距离。在拿anchor中心坐标加减前面的预测距离就得到了熟悉的bbox预测坐标。
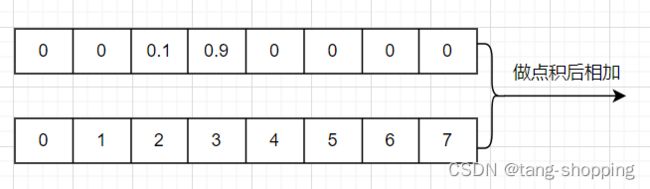
上图的结果为2 x 0.1 + 3 x 0.9 = 2.9,该数值就是anchor中心到bbox某条边的距离。
然后就可以拿该预测bbox值与gt bbox值做损失函数计算了。
loss_bbox = self.loss_bbox(
pos_decode_bbox_pred, # 预测的 bbox 左上右下角点坐标, (pos_num, 4)
pos_decode_bbox_targets, # bbox 左上右下角点坐标标签, (pos_num, 4)
weight=weight_targets, #
avg_factor=1.0, #
)
2.gfocal_loss
① distribution focal loss
这个函数与上面的GIOU loss一样,都是用来优化bbox的。首先要说句,pred与label的shape不一致。此处的label是用anchor中心坐标减去对应gt bbox四条边得到的,即anchor中心到gt bbox四条边的距离(距离的取值范围是 0 - reg_max,feature map 坐标系下)。明显可知,label是个连续值,而 distribution focal loss实质上是用了交叉熵损失函数(F.cross_entropy博客),交叉熵损失函数的标签是离散值。
# pred.shape = (N * 4, (reg_max + 1))
# label.shape = (N * 4, )
def distribution_focal_loss(pred, label):
dis_left = label.long() # label 是个小数,这里是将其整数部分赋给 dis_left
dis_right = dis_left + 1 # label 处于 dis_left 与 dis_right 两个整数之间
weight_left = dis_right.float() - label # label 与其右界的差值,label越靠近 dis_left,该值越大
weight_right = label - dis_left.float() # label 与其左界的差值,label越靠近 dis_right,该值越大
# F.cross_entropy,它对输入的 pred 会先做softmax、log,再求损失。dis_left是正类别的序号,不是一个one-shot数组。
# 让 label 被两个交叉熵函数给拉扯,使其处于 dis_left 与 dis_right 两个整数之间
loss = (
F.cross_entropy(pred, dis_left, reduction="none") * weight_left
+ F.cross_entropy(pred, dis_right, reduction="none") * weight_right
)
return loss
这个疑惑用文字描述不清晰,看图说话吧。假设label = 3.5,其左边界为3,右边界为4,以左右边界为label,左右边界同时做交叉熵损失,再利用相应的权重(weight_left, weight_right)来调节,让网络学习到label的大小。
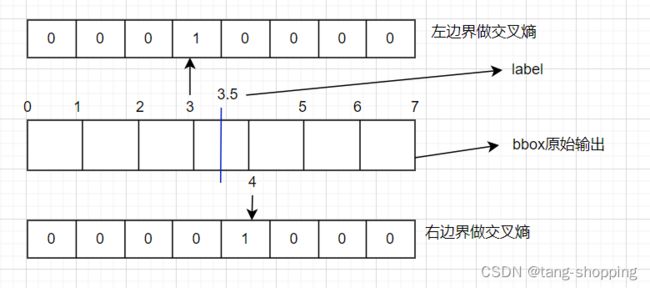
如果模型学到位了,那么label = 3.5的理想bbox输出(已经做了softmax)如下图。
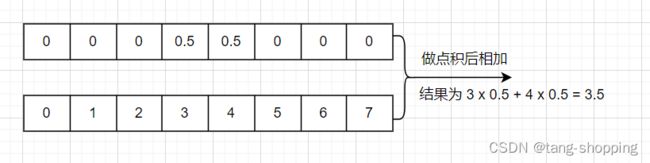
② quality focal loss
代码中的pred是所有anchor对应的类别概率值,以coco为例,类别数是80,则pred.shape为[batch * h * w, 80],被sigmoid映射到0-1之间,再与label做二元交叉熵损失。
在quality focal loss里,类别的标签不再是0/1这种"硬"标签(离散值),而是其相应bbox与对应ground truth bbox的iou值这种软标签(连续值)。这点比较新颖,如果不熟悉,先看看李翔大佬的博客——大白话 Generalized Focal Loss,以及里面一些概率分布介绍的博客。在此也大致讲一下,iou值的取值范围是[0, 1],与概率是一样的,此外iou值还能体现bbox的质量,一举两得。
def quality_focal_loss(pred, target, beta=2.0):
assert (len(target) == 2), """target for QFL must be a tuple of two elements, including category label and quality label, respectively"""
# label denotes the category id, score denotes the quality score
label, score = target # bbox 类别标签及 bbox 与 bbox 标签的 IOU 值,此处被称为 质量值
# negatives are supervised by 0 quality score
pred_sigmoid = pred.sigmoid() # [batch * h * w, 80]
scale_factor = pred_sigmoid
zerolabel = scale_factor.new_zeros(pred.shape)
loss = F.binary_cross_entropy_with_logits(
pred, zerolabel, reduction="none"
) * scale_factor.pow(beta)
# FG cat_id: [0, num_classes -1], BG cat_id: num_classes
bg_class_ind = pred.size(1)
pos = torch.nonzero((label >= 0) & (label < bg_class_ind), as_tuple=False).squeeze(
1
)
pos_label = label[pos].long()
# positives are supervised by bbox quality (IoU) score
scale_factor = score[pos] - pred_sigmoid[pos, pos_label] # 差值做权值因子,二者差距越大,权值越大,在线难例挖掘
loss[pos, pos_label] = F.binary_cross_entropy_with_logits( # 对应类别处做交叉熵损失
pred[pos, pos_label], score[pos], reduction="none" # 类别的标签是 IOU 值,且标签是动态的
) * scale_factor.abs().pow(beta)
loss = loss.sum(dim=1, keepdim=False)
return loss
顺便说说,F.binary_cross_entropy_with_logits的公式,加深理解与记忆,另外也可以看看这篇博客。
input = torch.Tensor([0.96, -0.2543])
# 下面 target 数组中,
# 左边是 Quality Focal Loss 的 label 形式,是连续型的,取值范围是 [0, 1];
# 右边是普通二元交叉熵损失的 label 形式,是离散型的,取值范围是 {0, 1}。
target = torch.Tensor([0.99, 1.0])
loss = F.binary_cross_entropy_with_logits(input, target, reduction='none')
print(loss)
# api 等同于以下式子
input = torch.sigmoid(input)
loss_1 = -(target[0] * torch.log(input[0]) + (1 - target[0]) * torch.log(1 - input[0]))
loss_2 = -(target[1] * torch.log(input[1]) + (1 - target[1]) * torch.log(1 - input[1]))
print(loss_1, " ", loss_2)
# 结果输出如下,可以看见二者是一致的
# torch.sigmoid(input) = tensor([0.7231, 0.4368])
# loss = tensor([0.3338, 0.8284])
# loss_1, loss_2 = tensor(0.3338), tensor(0.8284)
三、 推理流程简述
推理过程中,api各种调用,不方便阅读代码,整理了一份流程,仅做参考。
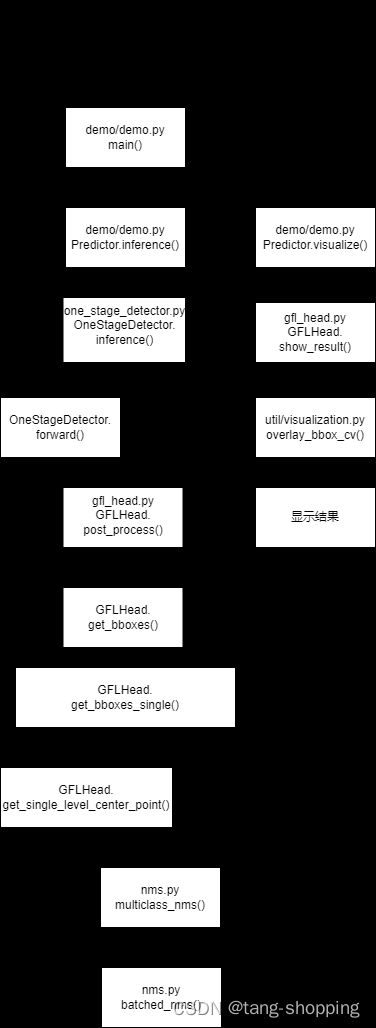
简要描述下后处理的步骤,搞明白模型的原始输出,怎么变成人类需要的bbox的。
① 将原始输出变换至合适shape,并把bbox的输出做一下初步处理,得到anchor中心到bbox四条边的预测距离;
scores = (cls_score.permute(1, 2, 0).reshape(-1, self.cls_out_channels).sigmoid()
) # cls_out_channels 是目标的类别数
bbox_pred = bbox_pred.permute(1, 2, 0)
bbox_pred = self.distribution_project(bbox_pred) * stride # [N, 4]
② 对scores按行求最大值,即求出每个anchor预测的cls_out_channels 个类别概率中,最大的一个值,同时也是质量分数最高的那个值,最后得到max_scores数组,shape = [N, ];
③ 按降序排列max_scores数组,取其前nms_pre个结果,得到topk_inds索引数组。用该索引数组,滤去低质量的bbox_pred与scores预测结果;
# scores是模型的类别输出,同时也是质量分数输出,shape = [N, cls_out_channels]
# N 由三个输出层 feature map 的宽高乘积加和得来,也是 anchor 的总数目
# cls_out_channels 是总类别数,coco 数据集下是 80.
max_scores, _ = scores.max(dim=1) # 按行求最大值,就是返回每个 anchor 预测的类别最大值,同时也是质量分数的最大值
_, topk_inds = max_scores.topk(nms_pre) # 降序,取前 nms_pre 个结果
center_points = center_points[topk_inds, :]
bbox_pred = bbox_pred[topk_inds, :]
scores = scores[topk_inds, :]
④用scores阈值,进一步滤去低质量的预测结果;
# filter out boxes with low scores
valid_mask = scores > score_thr
# We use masked_select for ONNX exporting purpose,
# which is equivalent to bboxes = bboxes[valid_mask]
# we have to use this ugly code
bboxes = torch.masked_select(
bboxes, torch.stack((valid_mask, valid_mask, valid_mask, valid_mask), -1)
).view(-1, 4)
if score_factors is not None:
scores = scores * score_factors[:, None]
scores = torch.masked_select(scores, valid_mask)
labels = valid_mask.nonzero(as_tuple=False)[:, 1]
⑤ 对bbox加一个偏移,将每个类别的bbox拉扯开,免得下面做nms时被不同类的bbox筛选掉,yolo v5也使用了类似的方式;
max_coordinate = boxes.max()
offsets = idxs.to(boxes) * (max_coordinate + 1)
boxes_for_nms = boxes + offsets[:, None]
⑥ nms,最后做一次筛选,然后就输出了。