机器学习-学习笔记 学习总结归纳(第四周)
引言 学习经验(数据),产生模型,进行判断
机器学习致力于研究如何通过计算的手段,利用经验来改善系统自身的性能。

数据集 - 示例(样本) - 属性 - 特征 - 属性空间(样本空间(输入空间))- 特征向量

训练数据 - 训练集 - 训练样本

预测 - 标记 - 样例 - 标记空间(输出空间)

**分类 - 回归 - 二分类(正类、反类) - 多分类

测试 - 测试样本(测试示例(测试例))

聚类 - 簇

监督学习(有导师学习) | 无监督学习(无导师学习)

泛化 - 强泛化 - 分布 - 独立同分布

![]()
假设空间
归纳
从特殊到一般的“泛化”过程, 即从具体的事实归结出一般性规律。
演绎
从一般到特殊的“特化”过程, 即从基础原理推演出具体状况。
归纳学习(概念学习(概念形成))

记住训练样本, 就是所谓的“机械学习”,或称“死记硬背式学习”。
利用一定的策略对假设空间进行搜索。
版本空间

归纳偏好
需要对假设空间进行搜索学习操作的时候,建立一定的偏好(特征选取偏好),这样的学习还有意义。
即, 建立学习的一定的“价值观”或启发式学习。
偏好的选择, 大多数时候决定了学习算法的性能。
习题
习题1.1

上图中若只包含编号1和4的两个样例,试给出相应的版本空间
版本空间(version space)是概念学习中与已知数据集一致的所有假设(hypothesis)的子集集合
(色泽=青绿)∧(根蒂=∗)∧(敲声=∗)
(色泽=∗)∧(根蒂=蜷缩)∧(敲声=∗)
(色泽=∗)∧(根蒂=∗)∧(敲声=浊响)
(色泽=青绿)∧(根蒂=蜷缩)∧(敲声=∗)
(色泽=青绿)∧(根蒂=∗)∧(敲声=浊响)
(色泽=∗)∧(根蒂=蜷缩)∧(敲声=浊响)
(色泽=青绿)∧(根蒂=蜷缩)∧(敲声=浊响)
(色泽= ∗ )∧(根蒂=∗ )∧(敲声= ∗ )
习题1.2
* 若使用最多包含k个合取式的析合范式来表达1.1西瓜分类问题的假设空间, 试估计有多少种假设。*
255种(28 - 1)个,因为将上题中的版本空间的八个值,每个值取或者不取,有 28 种可能,但是要舍去每个都不取的情况,即 28 -1种。
习题1.3

先了解一下什么是数据噪声(数据噪声指在一组数据中无法解释的数据变动,就是一些不和其他数据相一致的数据)。
即,数据的某个特征,不符合正类的要求。
所以我们的归纳偏好就需要放宽,即,只要极大部分特征满足正类而极小部分不满足,这种样本仍然保存,不删除。
习题1.5

在搜索中, 用户查询为输入,搜索结果为输出, 建立输入和输出之间的联系。
经验误差与过拟合
了解错误率 ,精度 ,误差 ,训练误差(经验误差) ,泛化误差的概念

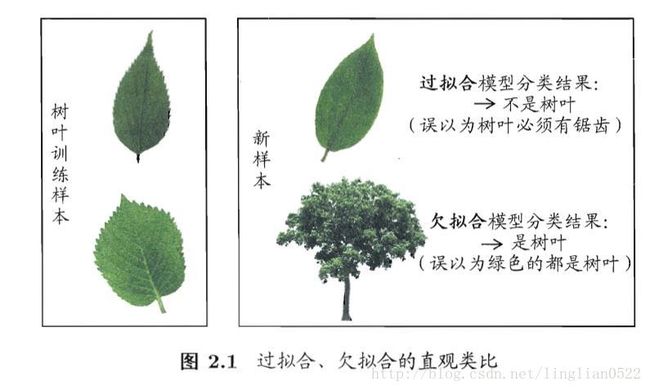
过拟合(过配)和欠拟合(欠配)
过拟合就是过度拟合,即将样本自身的一些特点当做了样本的一般特性, 使得泛化能力降低,注意,过拟合无法避免。
欠拟合则与之相反。
模型选择时,选择泛化误差最小的, 但是我们无法直接获得泛化误差,而训练误差因为过拟合的存在而不适合作为判断标准。
评估方法
留出法
将数据D划分为二个互斥的集合,一个集合训练完,另一个集合用来将第一个集合训练完的模型进行误差测试。
交叉验证法
就是将集合分为k个大小相似的互斥子集, 分为训练集、测试集,进行误差测试。
自助法
采用自主采样法, 自动生成训练和测试集,进行误差测试。
适用于数据集较小的情况,非常有用。
调参和最终模型
进行参数步长的设定,让其自行调参,测试误差。
性能度量
对学习器进行评估,不仅需要科学可行的方法, 还需要有衡量模型泛化能力的评估标准,这就是性能度量。
性能度量反映了任务需求,在预测任务中,进行性能评估,把预测结果与真实标记进行比较即可。

错误度与精度
跟前面说的错误度和精度一样。

查准率、查全率与F1
查准率就是找到的里面,正确的所占的比例。
查全率就是在正确的里面,查出来的多少,所占正确的比例。
往往二者不可得兼。

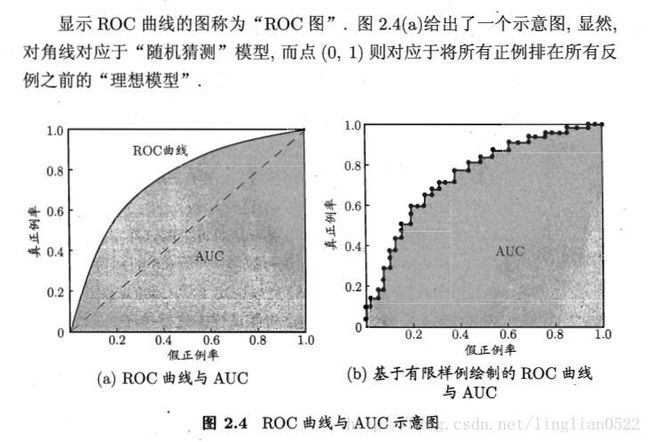
ROC与AUC
用来研究学习器泛化能力的有力工具。
ROC(受试者工作特性), 我们根据学习期的预测结果对样例进行排序,按此顺序逐个把样本作为正例进行预测,每次计算出二个重要的值,分别为他们的横纵轴,就得到ROC图。
AUC 就是比较ROC下面的面积如下图。
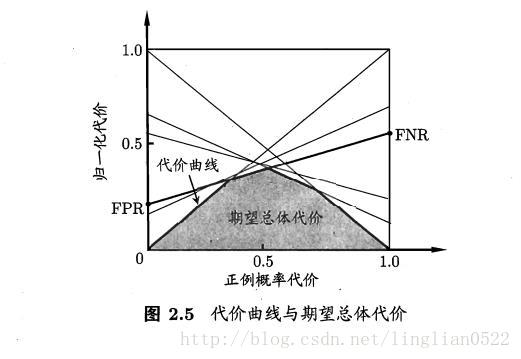
代价敏感错误率与代价曲线
这里引出非均等代价的概念,之前的例子都是均等代价。
在非均等代价下,就不可以用ROC来表示性能,而是用代价曲线来表示。

比较检验
当我们得出了性能度量后,我们应该怎么进行比较呢?
我们引出下面几个比较检验的概念。
假设检验
假设检验就是对错误率(也可以是别的度量或者某种情况)进行假设(通常假设在某个范围内),接着进行二项检验或t检验。

交叉验证t检验
交叉验证在有2个或者多个学习器的情况下,假设多个学习器的性能相同,进行交叉验证,就是将数据集进行多次训练和测试,将多个学习器的性能(在这里是错误率)进行t检验。
McMemar检验
在进行留出法对2个学习器进行性能测试的时候, 我们会得到错误率以及二个学习器的差别,我们假设二个学习器性能一样,那么在进行下述计算后,得到的平均错误率较小的那个学习器性能则更优。

Friedman检验与Nemenyi后续检验
Friedman检验就是将多个算法和多个数据进行交叉多次训练和测试,得到的结果,如果得到的结果有显著的区别,则进行Nemenyi后续检验,计算出平均临界值域, 然后进行,二二比较,如果超出临界值域,则二个算法显著不同,反之,而差距不大。
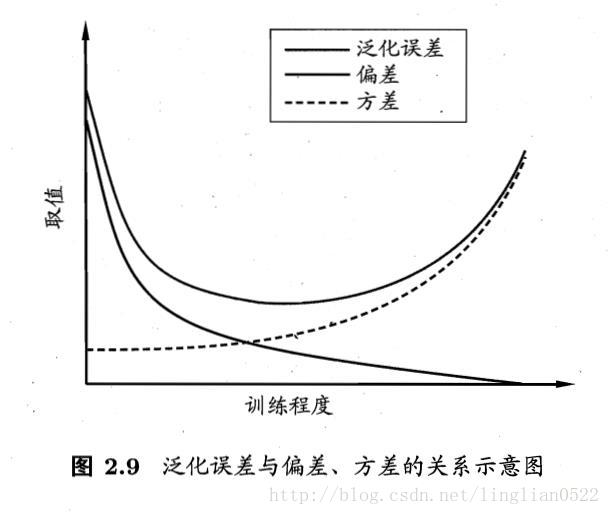
偏差与方差
偏差-方差分解是解释学习算法泛化性能的一种重要工具。
偏差度量了学习算法的期望预测与真实结果的偏离程度(拟合能力)。
方差度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响。
噪声则表达了在当前任务上任何学习算法所能达到的期望泛化误差的下界,即刻画了学习问题本身的难度。